 夜雨聆风
夜雨聆风
Claude Code 的官方路径给得很短:装上、登录、开任务。但在实际操作中,真正劝退人的往往不是这几步,而是资料太碎。
一搜教程,常见的情况是:不少内容在讲 CLI,不少内容在推 VS Code 插件,还有一些已经开始往 settings.json 里塞各类国产模型。东西都是真的,但层次全混了。
Claude Code 第一次上手,难的不是安装,而是顺序。
1. 别急着配,先定入口
Claude Code 现在已经不只是一个黑框命令。
官方给的入口很全:终端里的 CLI、VS Code 扩展、Desktop 应用,甚至还有 Web 端和 CI/CD 集成。
入口变多是好事,但第一次上手最怕把选择题做得太大。真正需要的不是多,而是减法。
• 习惯待在终端,就选 CLI ( claude)。 它最接近工具的原生逻辑,权限、上下文、配置作用域在这里看得最清楚。• 离不开编辑器,就选 VS Code 扩展。 它把对话面板、代码 diff 审查塞进了熟悉的界面,心理门槛最低。 • Desktop 和 Web 可以先放一边。 它们目前更像辅助,不适合作为主线。
先把第一轮链路跑通,比“全都要”更重要。
2. 安装与登录:最短路径
如果走官方主线,安装动作非常直接。
# macOS / Linux / WSLcurl -fsSL https://claude.ai/install.sh | bash# 或者习惯 Homebrewbrew install --cask claude-code真正会卡住进度的是账户与环境。Claude Code 支持订阅账户、Console 账户,以及通过 Bedrock、Vertex AI 接入。
直接购买官方这条线,现实里往往还要先处理支付方式和网络条件。 这一步卡住的人很多,但它不属于工具配置问题,而是前置条件。
安装后,第一次启动:
claude
跟着提示完成登录即可。更稳的顺序,是先按官方方式把主线跑通,再决定后面要不要接云厂商或社区路由。接入方式一开始混得太多,出了问题往往很难判断到底卡在工具、账号还是路由层。
3. 建立手感:先给小任务
很多人犯的第一个错,是刚装好就扔个大活:
• “帮我重构这个模块” • “把整个项目升级一下”
这类起手式很容易翻车。不是它做不到,而是刚接进工作流时,我们还没摸清它的边界。第一次更适合给 Claude 一个小而完整的闭环。
更稳的起手方式,往往不是一上来就让它接活,而是先让它把项目看明白:先理解上下文,再定位问题,最后只处理一个直接相关的小改动。这样做的价值不在于“步骤更规范”,而在于我们能更快看清它到底会怎么读项目、怎么收边界、怎么解释自己的修改。
第一次真正要建立的不是“它会写代码”的印象,而是观察它的三个能力:
• 它懂不懂上下文? • 它守不守边界? • 它的改动解释得清不清楚?
跑通一个小闭环,比让它接大活有价值得多。
4. 治理逻辑:作用域大于参数
一旦开始改配置,很容易先去抄别人的 JSON。但 Claude Code 配置真正的核心,不是参数怎么填,而是作用域分层。
官方把配置分成了四个维度:
• User ( ~/.claude/):个人全局偏好。• Project (仓库 .claude/):项目组成员共享的规则。• Local (仓库 .claude/settings.local.json):在这个项目里,只对我自己生效的覆盖设置。• Managed:企业级托管配置。
真正的重点不是“配置什么”,而是“这条配置应该活在哪一层”。
• 通用的个人偏好,丢进 User。 • 团队统一的规范,丢进 Project。 • 临时试验或个人私货,丢进 Local。
5. settings.json、CLAUDE.md 与记忆管理,各管各的
这几个东西最容易被一锅炖。
很多人第一次上手时,会把 settings.json、CLAUDE.md、memory 都当成“配置信息”。这也是为什么越配越乱。更实用的理解方式,是先把它们拆成功能分工:
• settings.json管的是工具怎么运行。• CLAUDE.md管的是这个项目希望它怎么做事。• auto memory 管的是它在干活过程中逐渐学到什么。
如果把这三个角色分开,后面很多问题就不容易混。
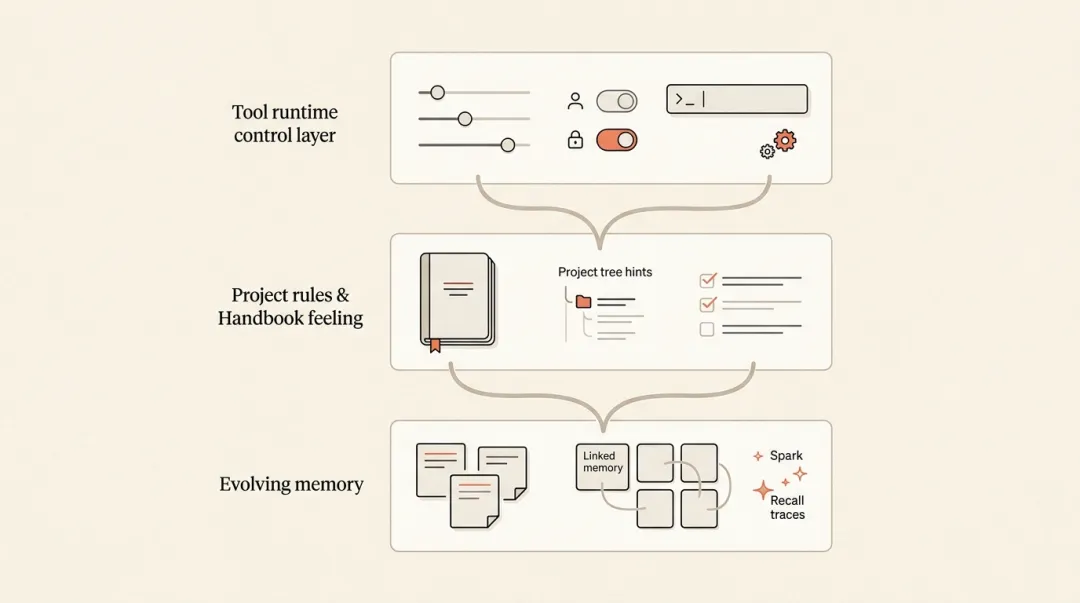
settings.json:工具层
settings.json 更像 Claude Code 的控制台。权限开多少、用哪个模型、环境变量怎么传、hooks 和 MCP 怎么挂,主要都在这里。
比如希望它别碰 .env 文件,这就该在 settings.json 里配置:
{ "permissions": { "deny": ["Read(./.env*)"] }}这一层真正解决的问题,不是“告诉它项目是什么”,而是“工具边界画到哪”。它负责的是权限、环境、运行方式,不是项目语义。
CLAUDE.md:规则层
CLAUDE.md 才是让 Claude Code 越用越顺的分水岭。
官方文档现在把它定义得很清楚:它是 Claude 在每次会话开始时都会读取的持久化说明文件,可以放在用户级、项目级,甚至由组织统一下发。项目里最常用的放法,是仓库根目录的 ./CLAUDE.md 或 ./.claude/CLAUDE.md。
它适合放什么?
• 项目概况:技术栈、目录结构、哪些目录是核心、哪些目录是遗留区 • 常用命令:怎么启动、怎么测、怎么 lint、怎么 build • 代码规范:命名规则、格式规则、提交前检查 • 工作边界:哪些文件不要动、哪些改动必须先问、哪些步骤必须跑完再交
官方还给了一个很实用的起手方式:先跑 /init。Claude Code 会先扫代码库,自动生成一版带构建命令、测试方式和项目约定的起始稿。如果仓库里已经有 CLAUDE.md,它不会直接覆盖,而是给改进建议。
真正好用的 CLAUDE.md,不靠大段抽象原则,而靠这种能直接干活的句子:
# 项目概况- 前端使用 Next.js 15,包管理器统一用 pnpm- `apps/web` 是主应用,`packages/ui` 是共享组件库# 常用命令- 开发:`pnpm dev`- 检查:`pnpm lint`- 测试:`pnpm test`# 代码规则- 修改前先读目标目录下的 README 和现有测试- 不要自动执行 `git commit`- 改完涉及 UI 的代码,先跑 lint 再汇报这种写法的价值,在于 Claude 一进项目就知道“我在哪、该怎么动、哪些不能碰”。如果只是写“写好代码”“保持整洁”,那和没写差别不大。
官方文档还有两个非常重要的细节:
• CLAUDE.md会占用上下文,所以越短越好,官方建议单文件尽量控制在 200 行以内• 大项目不要把所有规则硬塞进一个文件,可以拆到 .claude/rules/,或者用@path引入额外说明文件
这也是为什么它更像“入职手册”,而不是“百科全书”。
记忆管理:别把稳定规则和临时学习混在一起
Claude Code 现在的记忆不是只有 CLAUDE.md 一条线。官方文档把它拆成了两套互补系统:
• CLAUDE.md:我们手动写进去的规则和说明• auto memory:Claude 在工作过程中根据纠正和偏好,自己积累下来的学习记录
这两者最容易混淆的点,在于它们都会跨会话生效,但作用完全不同。
CLAUDE.md 适合放稳定规则。比如:
• 统一用 pnpm• API 测试需要本地 Redis • 这个目录是旧代码,除非明确要求不要碰
auto memory 更适合放在工作里慢慢学出来的经验。比如:
• 这个仓库的报错大多先看 apps/web/src/lib• 某个测试经常依赖特定环境变量 • 团队最近把接口约定改了,Claude 刚在修 bug 时学到
官方文档里,这套自动记忆默认存在 ~/.claude/projects/<project>/memory/。里面会有一个 MEMORY.md 作为索引文件,以及若干按主题拆开的记忆文件。启动时只会先加载 MEMORY.md 的前 200 行,细节文件按需读取。也就是说,memory 适合持续积累,但不适合拿来替代项目主规则。
如果想看它到底记住了什么,可以直接用 /memory。这个命令会列出当前会话加载了哪些 CLAUDE.md 和规则文件,也能打开 memory 目录、开关 auto memory。要是我们在对话里明确说“记住以后统一用 pnpm,不要用 npm”,Claude 也会把这类偏好写进 auto memory。
落到实操上,可以这么分:
• 每次都该生效的规则:写进 CLAUDE.md• 最近干活里学到的经验:交给 auto memory • 只在本机生效的运行偏好:放进 user/local settings
这样一来,记忆系统才不会越用越糊。
6. ccr 与 cc-switch:一个管运行时路由,一个管配置管理
社区里讨论很多的 ccr 和 cc-switch,确实有价值,但一定要先摆正位置:它们都不是 Claude Code 官方主线,而是增强层。
真正容易混的,不是“要不要用”,而是“它们各自到底解决什么问题”。
ccr:运行时路由层
ccr 是 claude-code-router,它更像 Claude Code 前面的一层路由器。
按它的 GitHub README,核心能力主要有这些:
• 按任务类型把请求路由到不同模型 • 支持多个 provider • 对请求和响应做转换 • 在 Claude Code 里配合 /model做动态切换• 用 ccr model直接在终端里管理模型和 provider• 需要更复杂的规则时,还能接自定义 router 脚本
这意味着它最适合的场景,不是“第一次装 Claude Code”,而是这类情况:
• 同一套工作流里,想把不同任务分给不同模型 • 同时在用多家 provider,不想每次手改底层配置 • 希望把 Claude Code 接到更复杂的模型路由策略里
它解决的是运行时到底走哪条模型链路,不是“图形化管理配置”。
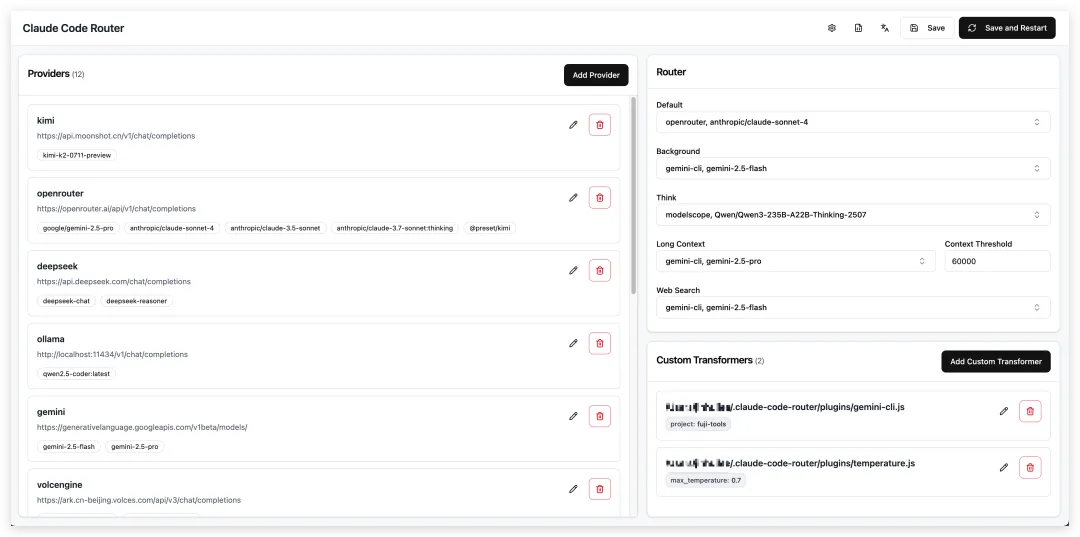
所以如果当前场景只是单账号加官方模型,ccr 基本不在主线上。它真正有价值的时候,是官方主线已经跑顺了,接下来要开始做模型路由、provider 策略和复杂切换。
cc-switch:配置管理层
cc-switch 的定位和 ccr 不一样。它更像一个桌面化的配置中台。
按 GitHub README 的说法,它现在主打的是:
• 用一个桌面应用管理 Claude Code、Codex、Gemini CLI、OpenCode、OpenClaw 等多套 CLI • 50+ provider 预设,避免手改 JSON、TOML、 .env• 统一的 MCP 与 Skills 面板 • CLAUDE.md / AGENTS.md / GEMINI.md这类提示文件的同步编辑• 系统托盘快速切换、云同步、自动备份
换句话说,cc-switch 解决的是多个工具、多套配置、多账号、多 provider 同时存在时,配置怎么别把自己管炸。
它不决定 Claude Code 当前请求到底转给哪个模型,那是路由层的事;它更像是把散在各处的配置文件、provider 列表、MCP、skills 集中起来统一管理。
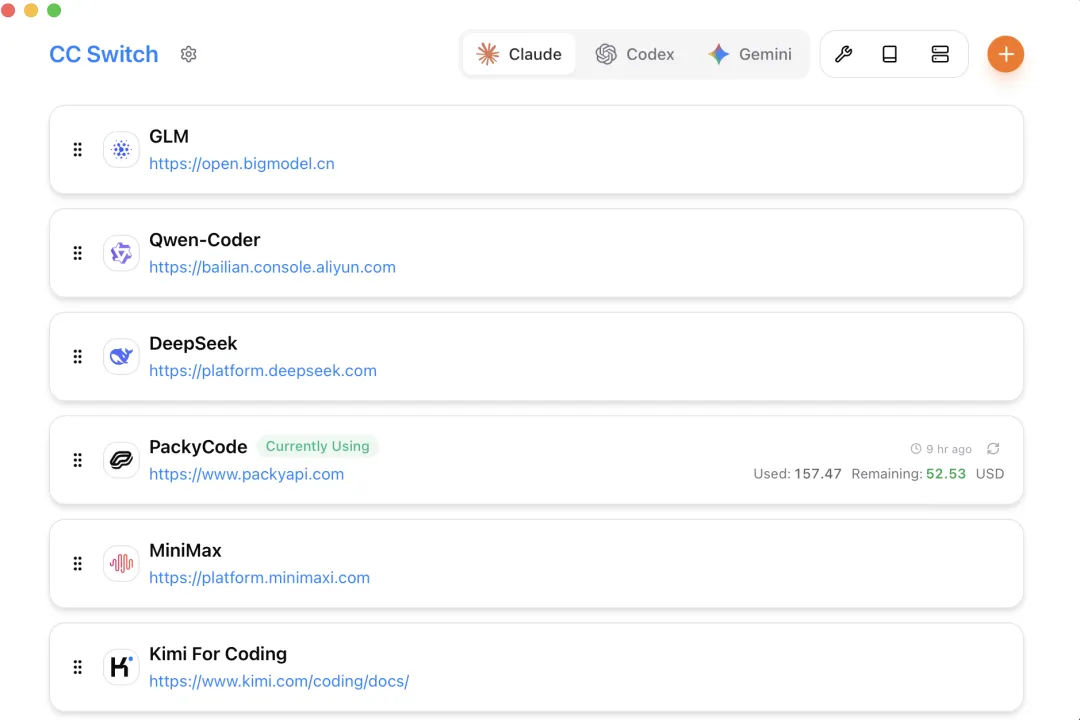
所以这两者最好这么理解:
• ccr决定运行时走哪条路• cc-switch决定这些路平时怎么管
如果只是把 Claude Code 先装起来、跑起来、接进第一个项目,这两层都可以先不碰。等官方主线已经稳定,开始嫌手改配置太烦,或者开始做多 provider / 多工具协同,再看它们才更有价值。
7. 接入第三方模型(Qwen/Gemini 等)
这里有一个常见的误区:Claude Code 官方原生并不支持直接认领 Qwen 或小米模型。
它的逻辑是:先接一层符合要求的网关(Gateway/Router),再由网关把请求转给背后的模型。
这属于扩展路线。第一次上手通常没必要一开始就碰这一层。体验、稳定性和工具原生能力一旦被网关层再包一层,很多问题会立刻变得更难判断,到最后很难分清到底是工具不行,还是网关没调对。
总结:一条更稳的上手顺序
1. 选入口:CLI 或 VS Code 选一个。 2. 跑通主线:完成安装,跟着官方提示登录。 3. 建立信任:找个小任务,看它怎么分析,怎么改代码。 4. 治理配置:理解作用域,别把 User和Project的配置混在一起。5. 补齐上下文:在项目里写好 CLAUDE.md。
真正决定体验的,不是今天记住了多少命令,而是先把一条最短主线跑通:选一个入口,进一个真实项目,完成一次小闭环,然后再把 CLAUDE.md、memory、路由层一点点加进去。
Claude Code 真正值钱的,也不是“装上那一刻”。是它开始读懂项目、记住规矩、接住工作方式的那一刻。前面的安装和登录,只是把门推开;后面的规则、记忆和增强层,才决定它到底能不能长期干活。
