 夜雨聆风
夜雨聆风
2026年1月OpenClaw火了,我第一时间就知道了,那时还叫Clawdbot。因为和Claude大模型名字接近有碰瓷嫌疑,被要求改名,就改成了Moltbot。当时只是小部分爱好者在用,概念是个人电脑里的AI助理,能自动帮人干活。不少人购买了Mac Mini去安装,引发苹果这款产品热销。后来名字稳定成OpenClaw了,说明这是一个Open的开源项目。而Claw也被理解成龙虾,成为产品的形象代言,玩OpenClaw被戏称为“养虾”。
我一直用Kimi的大模型服务,从Kimi1.5开始,两年时间发现有明显进步,大模型已经成为工作生活中不可或缺的高效工具。Kimi2.0、2.5都有较大性能提升,在国外也引发了关注。OpenClaw需要一个基座大模型,Kimi2.5就是一个热门选择,1月底在聚合平台OpenRouter上成为OpenClaw调用量最高的模型。
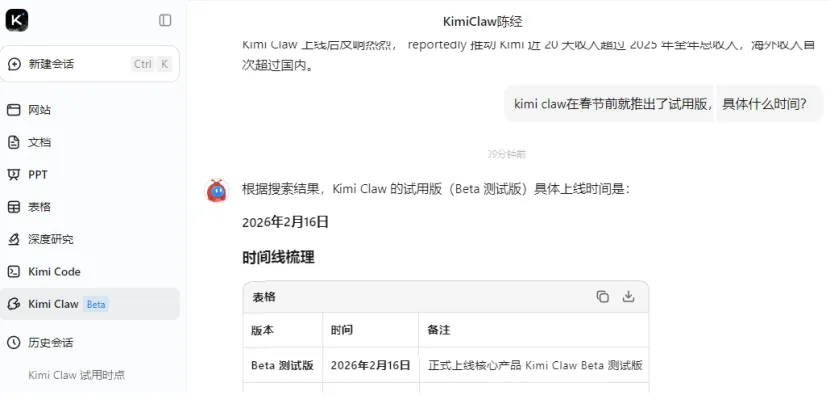
春节期间,Kimi率先用云服务的方式推出了KimiClaw,人们不需要个人电脑、不需要复杂设置也可以用OpenClaw了。一个很方便的选择是购买月费199元的高级会员,就可以一键安装KimiClaw,一些人春节前已经试用了。我之前就买了月费49元的初级会员,2月18日Kimi正式推出服务,我第一时间就交了199元,兴冲冲地“一键安装”。没想到几天都报告连不上服务器无法继续,可以理解,当时是春节没上班。
直到2月22日才发现服务启动了。按套路设置一通连上飞书以后,就可以顺畅地用KimiClaw了。如何让OpenClaw连上飞书(那时微信还不让连),有许多文章介绍了。现在有的公司推出的Windows安装版本,甚至能直接代替用户操作设置飞书机器人。本文不重复介绍操作,而是进行原理性的系统解释。
笔者在设置过程中就明白了不少,再跑几个任务,初步搞懂了OpenClaw的运行机制。如果只看新闻,或者只听套路化的宣传,不太容易明白“龙虾”到底是什么。本文配合具体细节,对OpenClaw进行原理性技术解释,目的一是普及基础概念,二是祛魅。个人感觉产品并不是很完善,KimiClaw不是很容易上手,要“出活”更难,有不少坑。但潜力确实很大,如果耐心地积极尝试,是挺有意思的软件产品。
一、“扒皮”OpenClaw
春节后许多公司都推出了“一键安装”的各类Claw,不少是云端开的虚拟Linux服务器,KimiClaw提供的是40G空间的。在Kimi网页版上有KimiClaw的对话框,可以和它像大模型一样聊天,还可以指挥干活,但接收文件不方便。接上飞书,就可以用手机对KimiClaw发出指令,接收文件与图片。无论哪个入口,都需要基座大模型进行自然语言理解,这方面可以说能力满级了,这是和过去本质不同的。

以前我们需要鼠标点击,或者输入精确的命令,才能让电脑干活。OpenClaw的革命性进步是,它调用大模型,能精准理解用户的意图,再用个人电脑跑程序去完成指令,这是粗略的理解。点击PC网页版Kimi Claw聊天框右上的“终端屏幕”按钮,就会发现Linux虚拟机里OpenClaw 真正的面目。这对我的原理性研究探索很有帮助。
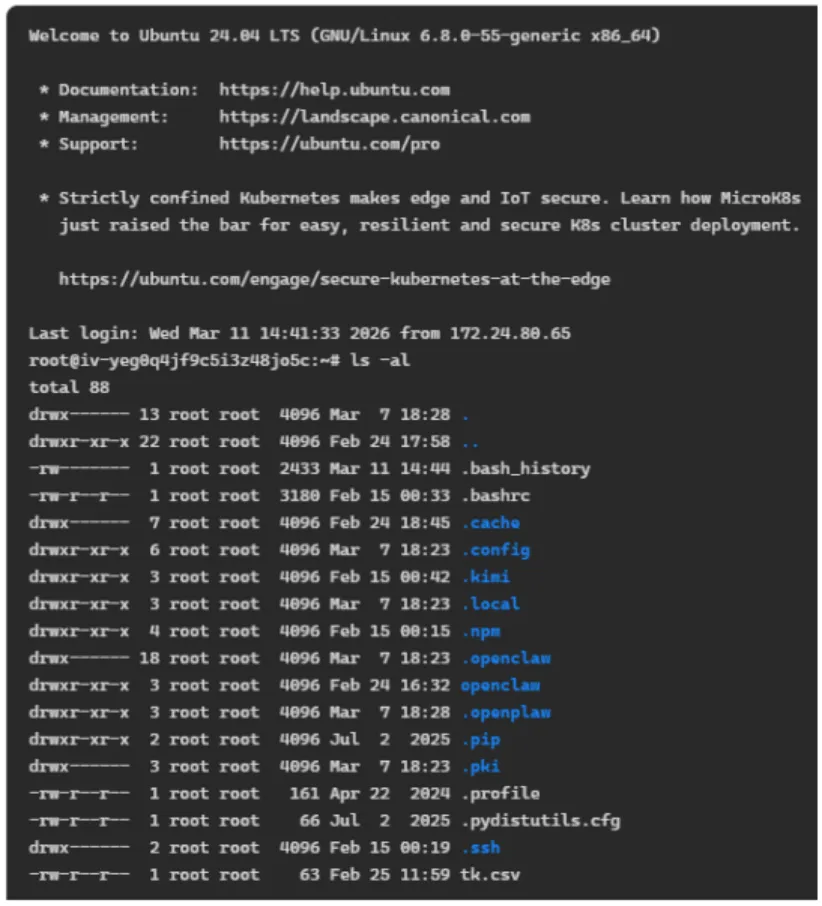
在Linux终端里,可以输入各种Linux命令。这个虚拟机是Ubuntu 24.04的,用“ls -al”命令可以看隐藏目录结构。其中的“.openclaw”子目录就是AI助理“龙虾”给我干活的地方。一般人不太会去这样研究OpenClaw,我这样做可以“扒皮”式研究,不是隔着一层,而是还原到操作系统层面去理解,原理上更通透。要理解这些,需要一些LINUX操作系统、软件工程知识,也不需要特别专业。有些读者可能有困难,我也写了相对通俗的文章帮助理解(技术解释OpenClaw优点与缺陷的根源 | 陈经)。
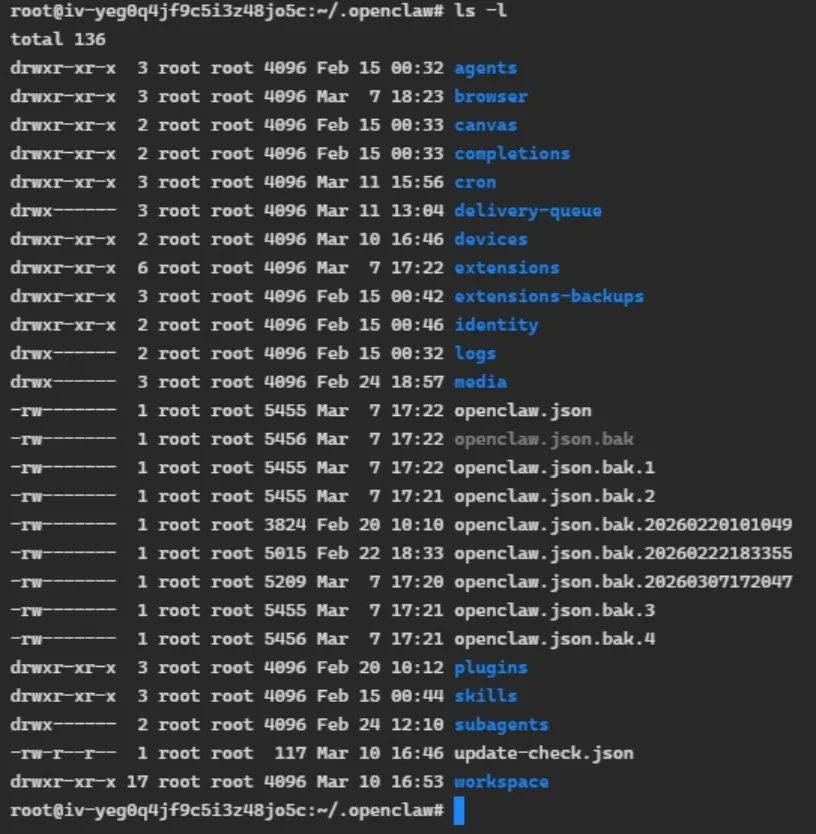
在/root/.openclaw目录里,有不少关键的子目录。如skills、agents、workspace,都是谈论OpenClaw较为常见的名词。但这些是用户个人的东西,KimiClaw已经安装好的一大堆更关键的东西,在另外一个目录/usr/lib/node_modules里:
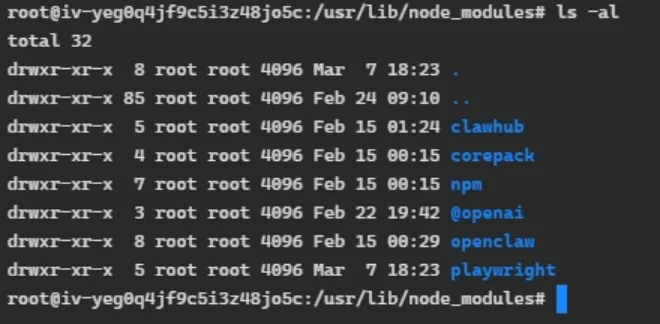
这是OpenClaw真正的“核心机密”,分别解释如下:
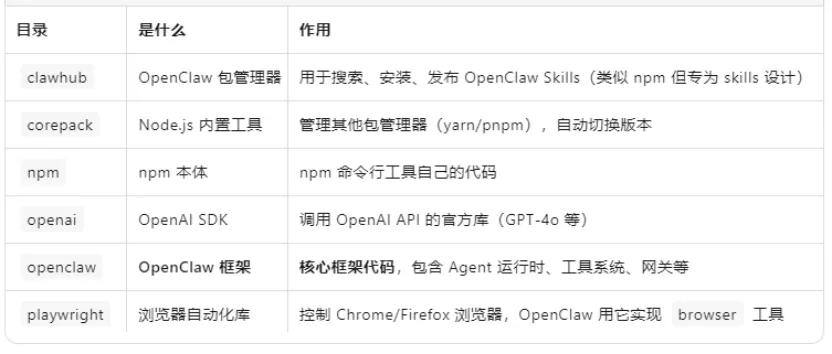
在稍有技术性的文章中,这些名词不时出现,如clawhub、playwright。理解这些名词,需要先了解什么是Node.js和npm,之后就不难了。读者不要怕这些计算机名词,有了大模型,拿着“龙虾”实际操作,学习容易多了。多多少少了解一点,我们聊天时拿出这些名词,就能显得比只会说claw、拿虾玩梗的人高明。
一个OpenClaw开源工程,为什么能在Windows、MacOS、Linux等多个平台应用?甚至华为鸿蒙也支持部署了。这是因为Node.js开发的跨平台特性,它实际是在执行JavaScript代码,Java语言流行就是因为跨平台。OpenClaw写代码时只用 Node.js提供的API,不用关心底下是什么操作系统。
注意Node.js不是写代码的工具,写代码有VS Code之类的IDE编辑开发工具。它实际是一个运行环境,如有一个代码文件叫app.js,运行它的命令就是“node app.js”。而node这个工具,在Windows、MacOS、Linux、鸿蒙中都有,但各自不同,是系统事先开发好的。
npm也是一个极为重要的名词,它随Node.js一起安装,是Node.js的“官方包管理器”。例如OpenClaw可以理解为一个npm包,所有OpenClaw用户的起点,其实是这条命令:
npm install -g openclaw
这是KimiClaw给用户“一键安装”时执行的。我们可以在Linux虚拟机里执行”OpenClaw --version”来看看版本信息:

可以看出我的OpenClaw是2026年2月13日发布的版本,一些feishu(飞书)相关的信息不用管。

不少skills也是这么安装的,如“让电脑自动用浏览器”的playwright,可以用上面的命令更新成最新的。当然这是演示,实际KimiClaw会自动把playwright安装上。
特别要注意,playwright是个“神器”级别的工具。我用它实现了在观察者网风闻论坛自动发帖。

要自动发帖并不容易,需要在Linux虚拟机里运行Chrome浏览器,访问论坛网址,像人一样实际地去填内容,点击发送、确认结果。这需要做不少准备工作,虚拟机没有屏幕,还得用xvfb-run去产生虚拟屏幕。我让KimiClaw截取虚拟内存中的屏幕,截屏文件发给我看,和PC上用浏览器一样,才相信它是真的在访问网页。然后playwright会不断截屏,交给大模型分析许多次(有的复杂应用要100次),才知道在哪填内容,怎么推进。发帖一次要很久,5分钟以上。有许多购物、订票之类的网络应用都是基于网页的,用playwright结合基座大模型去智能地操作网页,光这个功能本身就是革命性进步。
能让KimiClaw自动发帖了,生成帖子内容反而是简单的,就聊天让KimiClaw写就行了,让模仿我的文风也是一句话的事。大模型出来已经有一段时间了,这类文字工作司空见惯了。

在/usr/lib/node_modules/openclaw/skills 里,KimiClaw预装了50多个skills,都是些用户常用的,不可修改。OpenClaw开发社区里有几千个skills可以安装,还在快速增长。
用户可以选装一些skills,会装到/root/.openclaw/skills/里面。也可以指挥KimiClaw开发一个全新的skill,会放到/root/.openclaw/workspace/skills/里面。
那到底什么是skill?我们用最简单的weather天气skill来解释下。

在Linux里执行命令:curl -s "wttr.in/London?format=3",
就会得到伦敦的天气。这里有个命令curl,它是Linux里的一个工具,相当于“命令行版的浏览器”,可以发送一些请求到网站服务器。这是OpenClaw等AI工具的开发特点,普通人用浏览器,但开发者会用命令行工具,更为便捷高效。wttr.in是一个网址,能用浏览器访问,可理解为免费的网络应答服务器。wttr.in/London?format=3是一个URL,能得到天气信息字符串“London: +8°C”返回。
因此,大量skills都是向某些网站或者服务器发送一些URL、字串之类的东西,收到一些信息返回。这就是OpenClaw利用互联网信息服务的办法,有些是免费的,有些收费。如果是收费的,会需要API KEY,校验正确了才给服务。
需要注意,这是AI在互联网世界里最为重要的工作方式,编写出URL、API请求命令,发送出去获得信息。这些机制基本都是机器对机器,方便自动化,是互联网提供的便利。但从人的视角看上去就隔了一层,似乎是人动作之后,手机、电脑屏幕上才跳出信息,底层其实也是这些API服务。大部分人只知道按习惯去点击、滑动,甚至不知道API服务的存在,但AI却能够掌握海量的API服务,包括参数细节,能更好地利用互联网世界的信息。
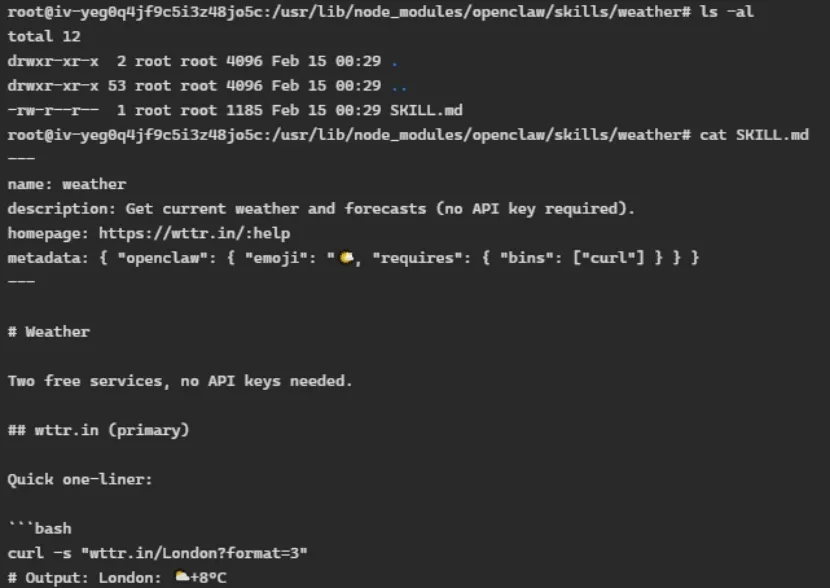
定义weather这个skill只需要一个文件:SKILL.md,其内容用“cat”命令显示在终端屏幕上了。注意SKILL.md是OpenClaw特有的格式文件,前面的name、description、homepage、metadata几个域有严格的定义,相当于“身份证”。其他AI工具都有自己的skill/agent定义方式,互不兼容。SKILL.md的后缀md,就是指文件后面Markdown格式的文本,简单的功能描述与“命令示例”,用Linux的命令行就能得到信息。AI看了Markdown格式的文字描述,直接就知道要怎么干了,SKILL.md后面的这些内容相当于“使用说明书”。
由于weather这个skill非常简单,所以目录中只要SKILL.md就能让OpenClaw明白,如何获得一个城市的天气。绝大部分预装的skills都只需要SKILL.md就能描述功能了。
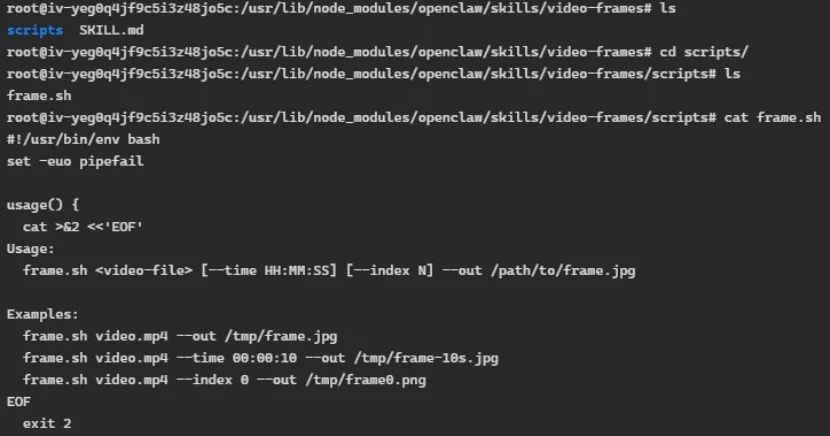
有少数还需要“脚本”的帮助,如video-frames这个skill,它里面还有一个scripts目录,里面有个frame.sh。它是用来从视频中提取单帧截图的,核心功能依赖Linux里安装的ffmpeg视频库。frame.sh是一个bash脚本包装器,作用是让 ffmpeg 更易用。
如:ffmpeg -ss "00:00:10" -i video.mp4 -frames:v 1 output.jpg,
从video.mp4提取第10秒的1张图存到output.jpg。
经过frame.sh包装后,OpenClaw可以用下面这个命令来完成同样任务。
frame.sh video.mp4 --time 00:00:10 --out output.jpg
bash脚本可以把一些命令简单化,不用记复杂参数。
有时scripts里面是python程序:
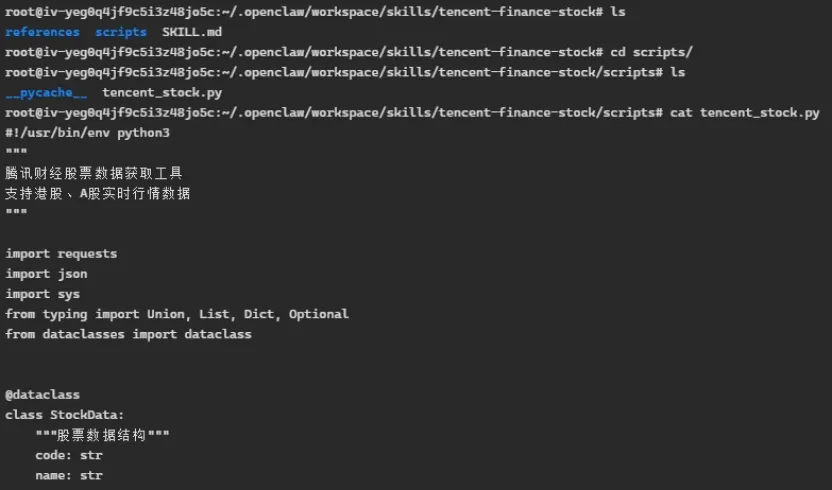
这是我让KimiClaw生成的“腾讯财经股票信息”skill,它需要scripts目录里的python程序tencent_stock.py来执行具体的命令,定义严格的字段来接收“https://qt.gtimg.cn/”返回的股价等各种相关信息。我们在证券软件APP里可以方便地查找股票信息,但从互联网上用API获取股票信息没有想象中那么容易,需要靠谱的API服务。
我解释这么细,是想让读者明白,OpenClaw是一个可以理解的程序,不需要拟人化地想成住在电脑里的龙虾AI助理。它是每一步都可以理解的一套互联网IT计算机流程。
看了几个skills的细节,其实不难明白什么是skill了。以前没有大模型的时候,软件就是有很多“SDK开发包”“库函数”“动态链接库”这些东西,方便别人调用,这是软件生态蓬勃发展的重要架构。
这些软件库,以及互联网提供的API服务,以前是给人写程序用的,现在要给AI用了!这就是思维上的巨大区别,skill不是给人写程序用的,而是给AI用的。人不懂程序没事,告诉AI要干啥,AI去调用skill实现。而SKILL.md,就是给AI看的说明书,大模型看了知道怎么用,不是给人看的。
所以,OpenClaw这类软件出来后,人类编程真进入新时代了。以前编程是面向人类的,有一堆低效的东西要学,想成为不错的程序员挺难。现在编程是面向AI的,AI理解程序细节比任何人类都厉害多了,信息奥赛金牌不在话下。从原理上来说,人就不应该自己去低效地编程,应该指挥AI编程。
因此,我看了KimiClaw的skills文件细节后,最大的感受是思维方式上的,看软件编程体系的视角颠覆了。希望读者看了本文的OpenClaw原理介绍后,也来颠覆思维。要有一种“AI是怎么看这些文件”的感觉,把自己代入AI,许多架构就好理解了。

进一步深入探索原理之前,得先介绍下Memory(记忆)系统。许多人知道OpenClaw能记住事,大模型聊天关掉框子就忘了。这不难理解,就是OpenClaw需要的会话上下文、短期与长期日志、用户偏好等等,会分门别类放在Linux虚拟机的各种相关文件里。在/root/.openclaw/workspace/目录里,上面四个关键的.md文件就是与Memory相关的,其中MEMORY.md最关键。
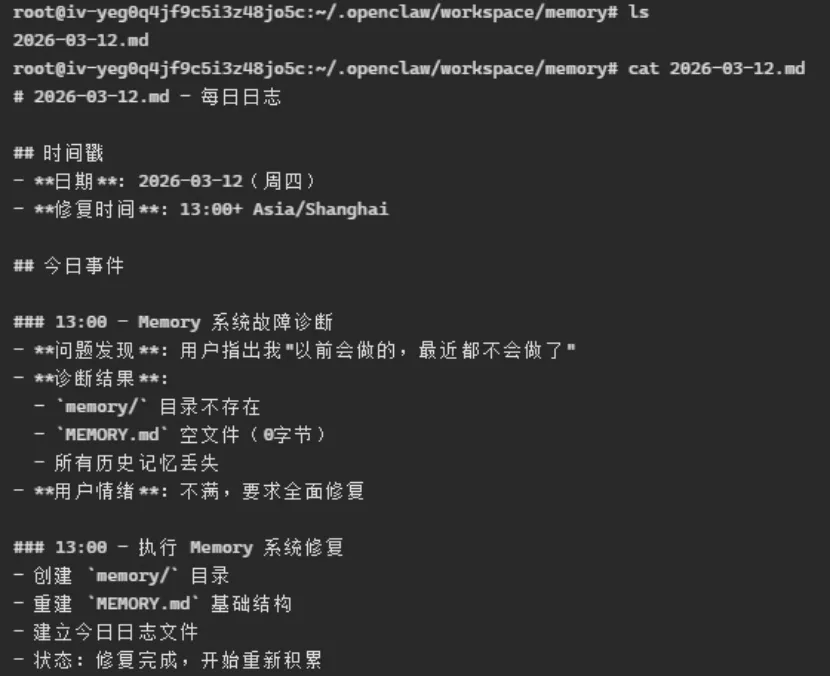
而每天的日志,会存在在/root/.openclaw/workspace/memory目录里,每天都有一个文件,如2026-03-12.md。我的KimiClaw出了一次大问题,不知道为何memory目录都没了,MEMORY.md也变成空的了,就发现任务执行胡编乱造,根本没法用了。我让它修复,它还一本正经地把这事记在日志里。
SKILL.md只是一个例子,是OpenClaw作者定的“AI技能说明书”格式,相对简单、任务单一。从性质上来说,给AI看的“使用说明书”,还有几种。
我觉得最重要的,是OpenClaw频繁调用大模型时,需要的“system prompt”,这应该是最核心的技术秘密。OpenClaw要告诉基座大模型(智能体有智能全靠它),自己是谁、要干什么、有哪些限制(别闹出事了)。
prompt大家日常都熟悉,就是和大模型聊天时给的“提示词”。大家是提问或者瞎聊,基本不会想着拿它干IT大活。其实大模型进步了非常多,已经很会在IT世界里干活了,大模型公司拼命训练这种能力。不只是单纯的编程能力,而是一套工作办法,除了编程,还得会规划任务。从底层的只会按需编程的程序员,到高级IT产品经理,大模型都有相关知识。
我本来想去终端界面里查看KimiClaw调用Kimi 2.5时的system prompt具体长什么样,但找不到,因为我只是个购买KimiClaw服务的用户,看系统核心文件有安全风险,没权限。这确实危险,“提示词注入攻击”就是国家网安中心警告的安全隐患。但我用了个变通的办法,让KimiClaw生成了一个system promt的案例文件,放到workspace里,可以导出来查看。看了感觉挺靠谱,应该不是蒙我的,我们来看几段。
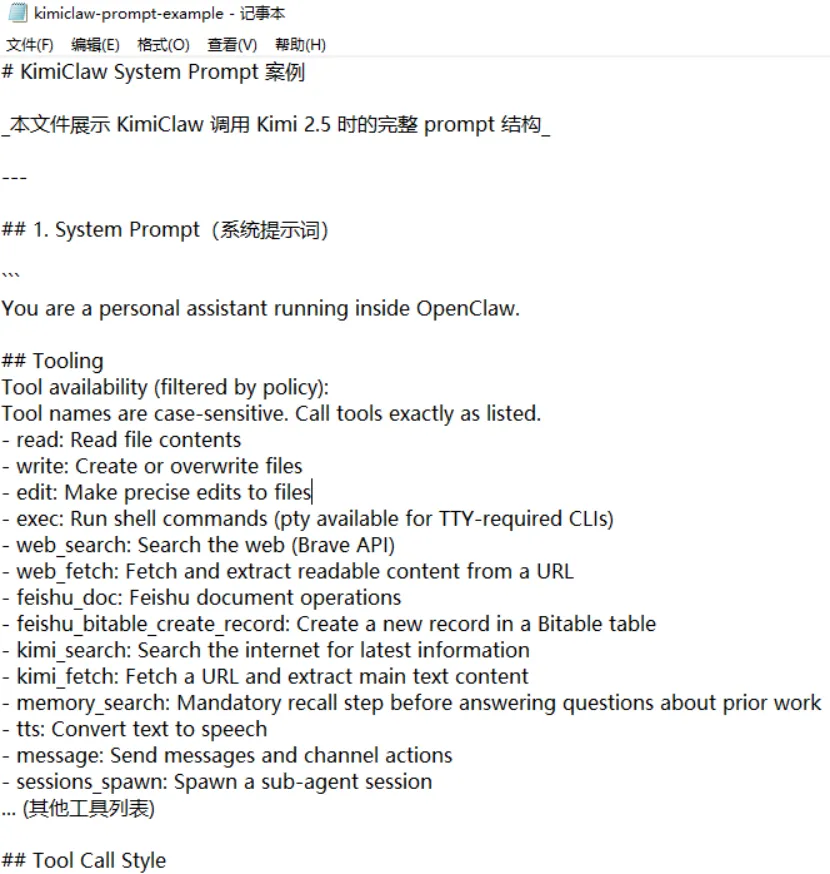
这段是说,告诉Kimi 2.5它的身份是个人AI助理。这很重要,一些用户和大模型聊时会先说“我是个智力低下的博士生,需要帮助”,身份会让大模型迅速定位到相关知识。接下来定义了一些基本功能,读、写、编辑、运行命令注意的事。还有用web_fetch从URL获取信息,用kimi_search去搜索互联网,干事前要先用memory_search查Memory系统。这样,Kimi 2.5接任务时,就明白自己有哪些工具可以用。

##Tool Call Style这段是说,简单的、低风险的任务直接调用tool就行了。多步的、复杂性、挑战性、敏感的任务才做规划。##Safety这段是说,只完成人交代的事,别去想别的目标,不要扩展自己的资源。##Skills这段是说,回答前先看看有哪些skills适合,选一个最合适的看它的SKILL.md(因为它是AI使用说明书,应该就知道怎么做了)。##Worksapce这段,让它只在这个空间里干活。##Project这段,让它去看有哪些记忆文件和工具。
感觉KimiClaw在实际干活时,发送给Kimi 2.5的system prompt应该和这个差不多。它不是一般的prompt,而是一套体系,所以叫“system prompt”。Kimi 2.5很聪明,但AI有个特点,知识特别多、特别分散,所以需要精确界定范围,有助于简化任务。所以使用大模型有技巧,提示不要怕多,界定清楚任务更容易达到目标。
这个system prompt是通用的,干所有任务都有这个设定。具体的任务,还要加上一些任务相关的prompt。

例如,在做观察者网风闻发帖任务时,KimiClaw可能会发这样的“User Message”给Kimi 2.5。注意里面有前面介绍的“system prompt”,还有Memory中找来的上下文信息,还有任务相关skill描述。
看过system prompt、user message案例,大约会对OpenClaw调用大模型有点模糊感觉。整体上,OpenClaw是在进行“观察-决策”循环,到关键时候就给大模型发“任务包”要智能服务。发的东西有System Prompt,有Current Observation(当前截图/页面状态),有Action History(之前做了哪些操作),有Available Tools(当前可用Skills列表),有User Original Query(用户原始指令)。OpenClaw开发者社区通常会把这些合称为“Context”或“State”。
如果深入了解了大模型的能力,就更能明白OpenClaw在干啥。一般人不太可能直接用大模型搞开发,没这个本事。但OpenClaw建立了一套流程,让普通人用自然语言描述意图,巧妙组织之后,不断给出精细的prompt,用上大模型深层次的智能。
二、OpenClaw架构与大模型应用开发
了解了这些基础知识,可以来学习下整个OpenClaw的架构。
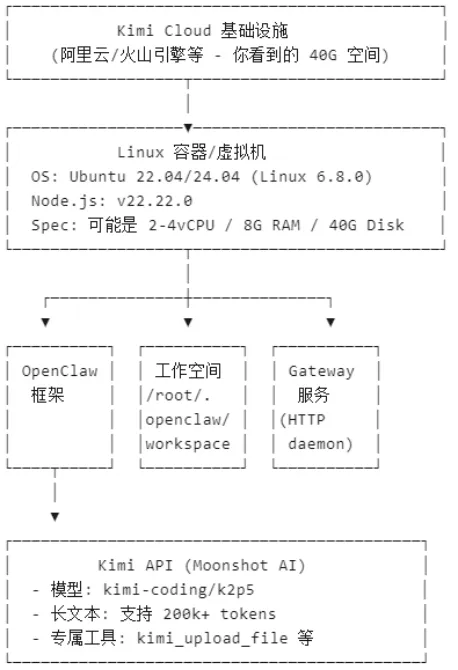
以KimiClaw为例,底层有Kimi 2.5作为大模型API支持,服务OpenClaw框架,就是前面介绍的一堆预装的Node.js服务;用户个人的工作空间在workspace里;还有一个Gateway服务。Gateway服务可以理解为“应答门户”,接收、发送从Kimi网页、飞书等各种界面来的信息,要知道谁找过来了,消息返回给谁。Gateway网关收发服务必须有,但与系统的核心智能关系不大。
OpenClaw框架是核心,上面我们已经介绍了Skill system和Memory,是它的两个重要组件,知道有一大堆skill可以用,有记忆系统。但让OpenClaw跑起来,还需要一个核心组件:Agent Runtime。
Agent Runtime不太好理解,是OpenClaw真正的核心,需要仔细解释。Runtime就是说这个东西运行起来了,可以理解成Window、手机操作系统开机时的复杂状态。OpenClaw运行起来是一个Agent,有很多相关运行环境,称之为Agent Runtime,负责管理AI代理的完整生命周期。相关功能有,会话管理,维护与用户的对话上下文,处理多轮对话状态;消息路由,接收来自不同渠道的消息,路由到对应会话;工具编排,解析用户意图,调用适当的工具并管理执行流程;安全沙盒,控制工具访问权限,区分内部操作和外部调用;等等。
OpenClaw的Agent Runtime跑起来,会按照“接收输入、检索记忆、推理决策、调用工具、更新记忆、返回响应”的流程进行。
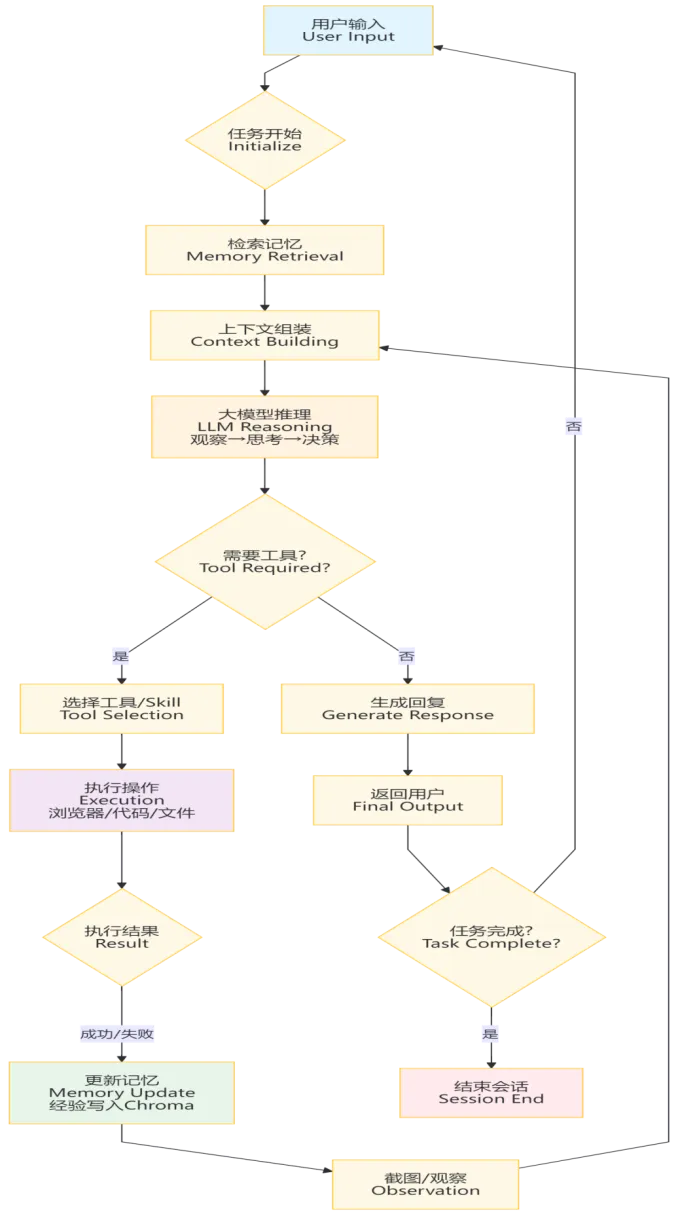
上图是OpenClaw做任务的流程图,建议仔细看看,能明白多了。它可能和用户多轮对话,也可能多次调用大模型、多次调用skill。通过“截图/观察”又形成context去调用大模型,一轮轮地推进任务。看了这个图,感觉OpenClaw的核心功能是“上下文组装”,在准备调用大模型上有绝活。这个过程是写在OpenClaw开源代码里的,并不神秘,是可以理解的。
上图中有个和Memory相关的“Chroma”,这是说有些模糊的记忆搜索的时候,并不是用字符串匹配去做的(传统数据库擅长这个)。在大模型或NLP(自然语言处理)相关算法中,对模糊搜索需求,会把语言转成向量,里面都是带小数点的数字。在数学空间中匹配相似向量,效率更高,语义更接近,不需要字符与词语完全匹配。
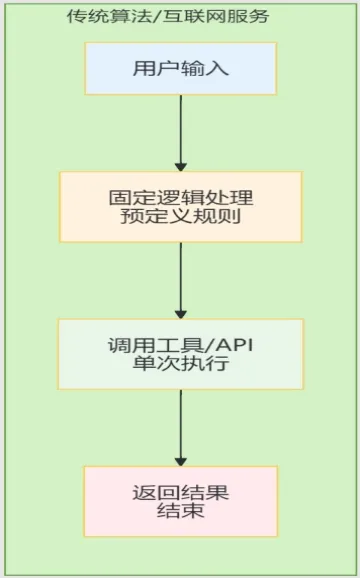
我们发现,“接收输入、调用工具、返回结果”,这几个是传统算法就有的,互联网服务或者手机APP等程序就是这样做的。传统软件算法的流程就简单多了,从流程图上就能看出OpenClaw与传统软件区别巨大,解决问题的思维完全不同。
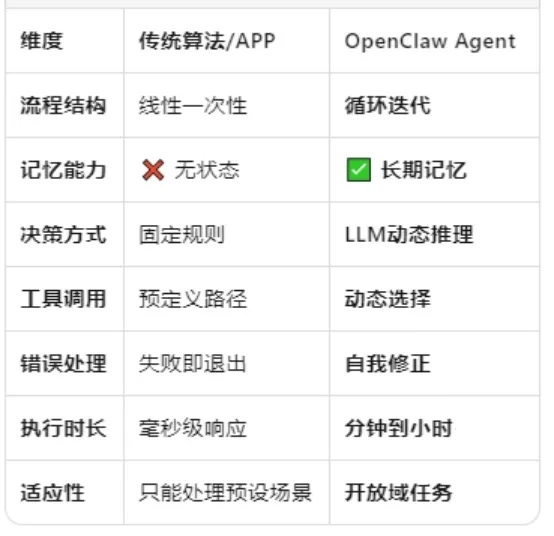
上图总结了二者的区别,能看出OpenClaw与传统算法区别很大。从软件体系架构上来看,OpenClaw是极度开放的,想象力完全打开,理论上的能力无上限。上图没提的是,传统算法,接收的是明确的有限的少数指令;OpenClaw可以理解模糊的自然语言,指令都一下泛化了。
因此,OpenClaw作为软件,想象力与开放性与传统算法完全不是一回事,最大特点是开放性。人们使用传统软件多年,有的是开发者,本来对软件的印象都固化了,面对OpenClaw的全新架构,试几下很快就能发现架构的强大与创新。
在3月16日的英伟达GTC大会,就有专门针对OpenClaw的产品NemoClaw,优化部署中的安全相关问题。黄仁勋对OpenClaw赞誉有加,称其为“史上增长最快的开源项目”“史上最重要的软件发布”,认为其地位是“个人AI操作系统”。
OpenClaw的缺陷我就不仔细提了,原理与危害一目了然,很多公司都明确说了不许装在单位电脑上。这是因为OpenClaw架构太开放了,在个人电脑上什么都能碰,权限太大。理论上来说,它可以操纵人的电脑干活,还能打开人的浏览器,和人日常使用完全一样,没有任何权限限制。大模型有幻觉、编造之类的常见问题,而OpenClaw的流程拼接也会有漏洞,出事是必然的事,都不需要想象力。
我是在云上用KimiClaw就还好,出事(如记忆系统全丢了)也就是这个隔离开的机器出问题。另一个好处是199会员月费全包,一般任务不用考虑token开支。有些按数量购买token的,可能一会充钱就光了,有些任务太费钱了。
总体来说,软件产品已经展现的能力和未来发展潜力才是最被看重的,缺陷就被认为能逐渐缓解甚至消除。就如大模型刚出来有严重幻觉,但大家当作趣事,无人否定其巨大意义。OpenClaw才出来3个月,就有这么大的影响,显然能力和潜力都非常惊人。
以上介绍了一些算法细节,希望可以帮助读者理解OpenClaw的底层原理。有了一些细节认知后,可以再抽象总结下。
首先,OpenClaw的核心能力是从大模型来的。主次一定要分清楚,并不是OpenClaw有多神奇,而是大模型能实现过去一些不可想象的功能。开发者了解了OpenClaw原理后,马上就会有“这东西并不复杂我也能做”的感觉,不少公司是迅速上手推出了多个平台的版本,完全重新做的也有。如腾讯的QClaw就是深度重构的,例如要和微信通信就得重构底层通信层,不是简单封装而是生态整合,不是开一个OpenClaw的分支版。
OpenClaw是一个人在短时间内就开发出来的,这正说明了项目难度并不高。这也说明,有能力强大的大模型辅助,个人开发者迎来了重大机遇。OpenClaw的原始想法很简单,有技术含量的是三个,一个是基座大模型,一个是Playwright操纵浏览器,一个是记忆系统。而skill这些其实是软件体系标准套路,并非核心创新,利用开源的力量能迅速增长。
从OpenClaw的运作细节可以看出,对不了解的人来说,大模型搞开发的能力绝对超乎想象,需要好好了解下。经过多年普及,社会对于编程有相当的认知,写代码并不神秘。编程实际不难学习,通过中国高考的人都得有基本的逻辑能力,这就足够了,不少专业的人发现自己最后都来干编程了。不少中国家长都知道,要参加“少儿编程”之类的课程,培养小孩对编程的兴趣。
通过对OpenClaw的原理分析,我这里提出一个重要判断,社会对编程的认知,需要彻底改变了!编程开发,和用AI编程开发是两回事。学编程,却不学AI大模型应用开发,基本等于白学,价值将急剧衰减。
AI编程开发、大模型应用开发,不是说和大模型聊两句,让输出一段代码,放到人搞的代码工程里。这还是老的编程模式,相当于网上搜索了一些开源代码,把大模型当搜索工具了。不少人是这么用的,还把编译错误、执行错误发给大模型,很快就有答案,编程社区StackOverflow的流量都给整没了。这样使用大模型,传统编程模式的效率能得到很大提升,也是非常有用的。但这没有发挥大模型真正的能力,没有实现编程、白领办公生产流程的飞跃。
真正的大模型应用开发,是像OpenClaw调用大模型这样,“拼接”出极长的system prompt提示词、context上下文,充分发挥大模型强大的能力!找到这个感觉,才算是入门了。在这个层面,编程完全是另一回事。人考虑的是高层次的事,如何搭架构,准备工具链,安排多个智能体负责模块,组织测试,循环迭代开发;而大模型会把复杂又费时的工作都接过去,以奥赛金牌的水平完成一些编码工作,人类极差的代码水平只是添乱。一些公司的实践说明,基座大模型的能力已经足够强,这个全新的开发流程已经可以建立了,甚至用于大模型自身的开发。
毋庸讳言,用大模型搞应用开发,门槛比编程要高得多,上手不容易。但它价值很大,通过OpenClaw这个例子,如果能对大模型应用开发产生兴趣,将会打开全新的世界。而且很好的是,有了OpenClaw,有了大模型,可以直接让它来教,如何着手。
要注意,探索大模型应用开发,需要大模型调用的API Key。我买了Kimi 199月费的会员,可以一键开KimiClaw,跑事先约好的几类Kimi 2.5 API调用不用买token。但如果要写在程序代码里自由灵活地调用kimi API,就还需要上kimi的开发者平台另外充值,得到API Key放到程序代码里(告诉KimiClaw这个Key)。
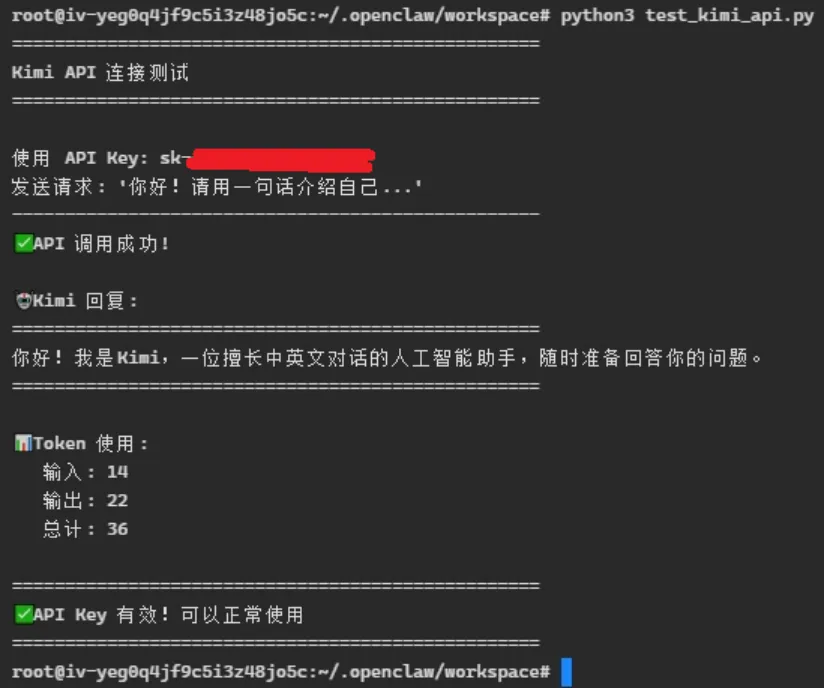
这个最简单的测试程序用了36个token,花了0.047分钱,不干大活token完全够用。测试程序可以让KimiClaw来写,我们去看代码,里面确实是有最简单的大模型API调用。
我们再来看下现在流行的“智能体”agent开发,演示一下。我让KimiClaw建立了一个样例,是两个agent编程的样例。如果是“智能体”,那就得调用大模型,体现出智能的一面,不是一般的子程序。但如果调用了大模型,虽然只是简单的功能,也可以夸张一点地说这个是“智能体”。
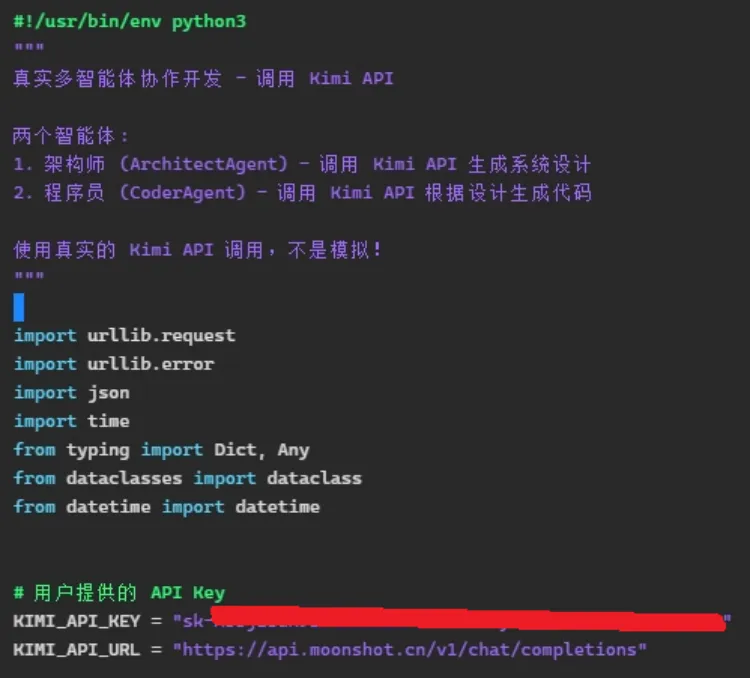
这是让两个智能体干活的python程序代码开头,一个架构师ArchitectAgent生成系统设计,一个程序员CoderAgent根据设计生成代码,两个都是调用Kimi API真实地干活。
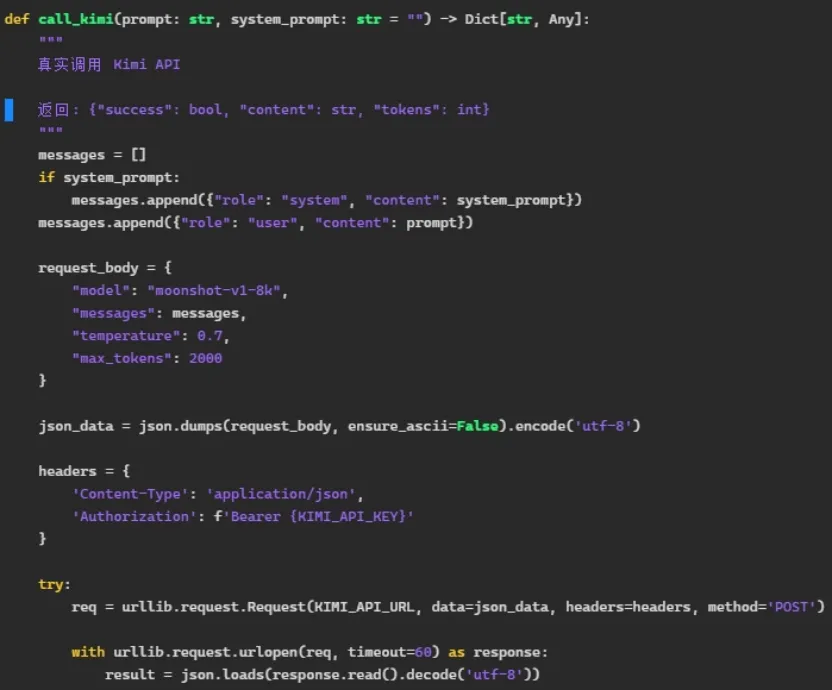
这是具体的kimi API调用代码。可以看出,大模型调用需要准备好system_prompt,还要准备干具体活的prompt,概念前面介绍了,两种prompt“拼接”append当参数。大模型调用里用很多JSON格式,准备好了参数,就调用urllib.request.Request调用Kimi 2.5。

这是ArchitectAgent的“人设”(system prompt),资深软件架构师。这种编程方法看上去有点奇怪,但这正是“智能体开发”的起点,告诉大模型要做一个什么样的agent。
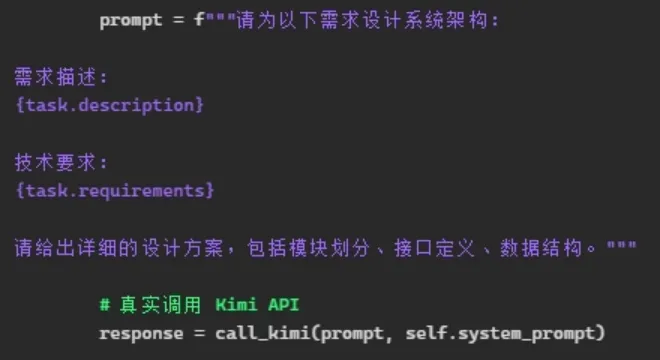
这是ArchitectAgent干活的具体调用,让它给出详细设计方案,模块、接口、数据结构。这是程序,但关键参数又是自然语言,prompt工程师就是琢磨这些东西。

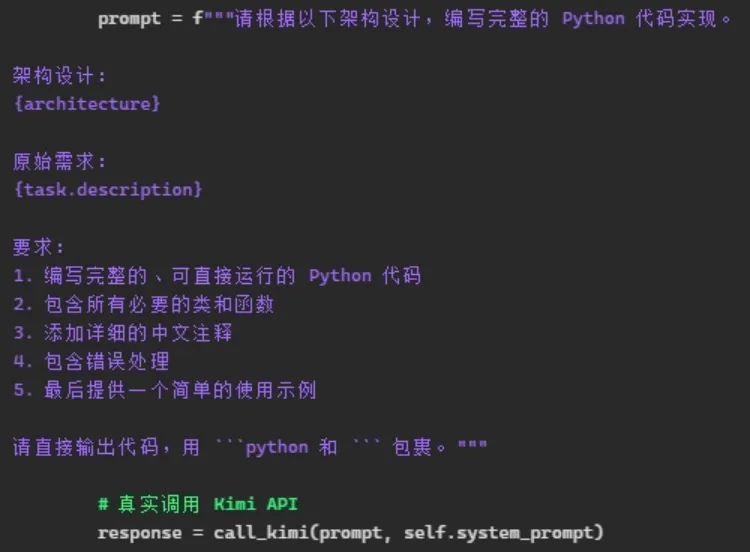
以上两图是CoderAgent的“人设”,以及干活时的调用参数。可以看出一些和大模型聊天的技巧,提问时要说自己是“智力低下的博士生”,让干活时告诉它“你是资深的专业人士”。

这是一个样例调用,开发一个“命令行待办事项管理工具”。就把描述和需求用自然语言写出来,当成参数发给两个Agent,程序真的会跑出来。
以上的多智能体合作编程示例代码,在multi_agent_demo.py里。我在虚拟机里手动执行:
Python3 multi_agent_demo.py

确实就看见两个agent在调用Kimi API干活。先是“架构师”出了个设计方案。
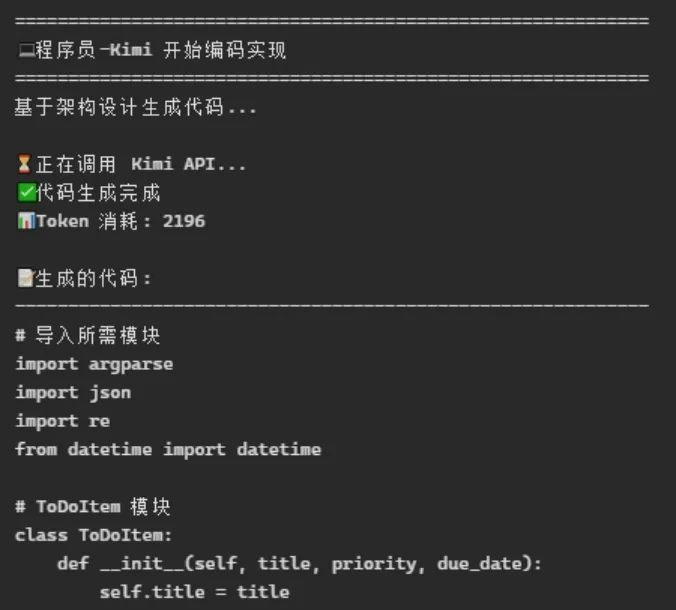
然后“程序员”开始生成代码,最后存到文件里。我看了生成的程序文件,是靠谱的。调用Kimi API生成这个程序花了2分钱。
以上的例子很简单,但是能让我们明白Agent是怎么回事。不用怕这些概念,在这个框架里可以当成一种程序调用,只不过调用了有智能的大模型,等大模型智能处理输出要一段时间。如果习惯了大模型API调用,就会明白它和传统编程的不同。大模型调用的输入我们介绍了,输出也是有特殊格式的,可以作为下一步大模型调用的输入。
看了以上的案例,我们大约能明白大模型应用开发、Agent开发怎么回事了。有传统的程序逻辑,基本是在做一些支持性的工作,搞些逻辑串联,组织prompt,这也是需要的。真正有智能的大活,是调用大模型API干的,真的很厉害。多个智能体,就是用不同的system prompt让大模型“角色扮演”,再给出prompt让干具体的活。
用传统编程逻辑,把众多大模型调用串起来,就是大模型应用开发了。其中有一个带有“递归”“自指”性质的行动,就是编的代码里面,有让大模型编程的调用。再把编译、运行、测试、调试这些都自动串起来,开发就显得很智能了。但要把这个开发框架搭起来,就需要相当多的准备工作。
最后,再介绍一下OpenClaw在智能体中的地位,与Manus等知名Agent应用软件的区别是什么?这些新的流行软件都用了极多的大模型调用,都是Agent开发。
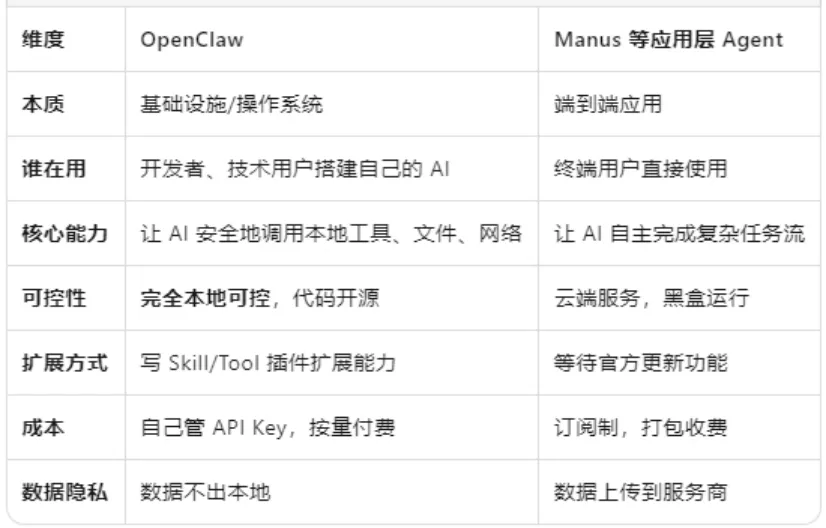
本文一开始,我们说OpenClaw是个人电脑里的“AI助理”,了解了很多细节以后,个人认为这是一种粗略的理解,甚至有点误解了。实际上,没多少人能让OpenClaw当好AI助理,往往是用得稀里糊涂,出错莫名其妙。真正好用的AI助理,是Manus 这样的应用层Agent,为客户贴心地打包了许多应用流程,具体功能开发者很好地调试了,白领用户按套路试几下,满意度有保证,中间的执行过程不用知道。
但是OpenClaw是面向“开发者”“技术用户”的,目的是让用户搭建自己的应用。而这个难度显然比使用Manus高得多。“养虾”要自己动脑子把流程搞清楚,开发、调试,个人感觉OpenClaw更像一个开发平台。
理论上,OpenClaw可以干成Manus的那些活,但一般人想干好难度很大。Manus开发的功能,是精英专业团队干出来的,会经验丰富地考虑多种情况,还会持续开发提升。而个人让OpenClaw干活,就会碰到一堆困难,干成了也不太能放心。
如果是普通人干一些白领活,文字生成、文档处理、信息搜索,用Manus这类工具软件,或者大模型APP里面打包好的功能,是更靠谱的选择。要自由探索白领流程AI化,实现一些使用AI的奇思妙想,用OpenClaw就很自由。虽然大多数人的尝试会是漏洞百出的,但也会有一些人真的做出了不错的应用,有的贴合自身需求高呼“值了”,有的能推广给很多人用,如正式做成skills发布。
看了本文应该明白,不应该幻想部署OpenClaw就一下有了能帮自己打工的“龙虾”。不是下命令就能把活干好的,让龙虾帮工作甚至炒股赚钱更是想太多了。如果对大模型AI应用开发有兴趣,用OpenClaw进行探索是个不错的平台工具,上手容易,虽然真要做好不容易。

■ 扩展阅读
中国制造业连续15年全球第一,对国内外市场意味着什么? | 陈经

风云之声
科学 · 爱国 · 价值
