 夜雨聆风
夜雨聆风模型 Provider 层是 Agent Runtime 与各 LLM Provider 之间的翻译与编排层。
它把统一的 chat / stream / countTokens 调用翻译成不同协议格式(Anthropic、OpenAI、本地 Ollama 等),并保证后续扩展仍可控。
在生产环境中,除了“能对接”之外,还需要 Prompt Caching 成本优化、Fallback 容错、Token 预算控制、Vision 多模态与成本可观测性。
Provider 适配层把协议差异封装起来,使 Agent 端尽量保持单一逻辑。
本文聚焦:从实现与工程约束出发,拆解如何构建可扩展的多模型 Provider 层。
本文涵盖:
1. 一套可复用的 Provider 层接口设计(TypeScript) 2. Anthropic 和 OpenAI 两大协议的完整差异对照 3. Prompt Caching 的精确省钱公式——不是"能省钱",是"每月省多少" 4. 三级 Fallback 容错方案(含恢复策略) 5. 流式 Tool Call 拼接的完整逻辑(含并发场景) 6. Token 预算:输入/输出上限与上下文修剪 7. Vision 多模态:能力判断、消息构造与降级 8. Ollama:离线兜底与能力差异处理 9. Provider 注册:配置化管理 + 能力矩阵 10. 性能特征:TTFT/计数/缓存与调优指标
1. 定位
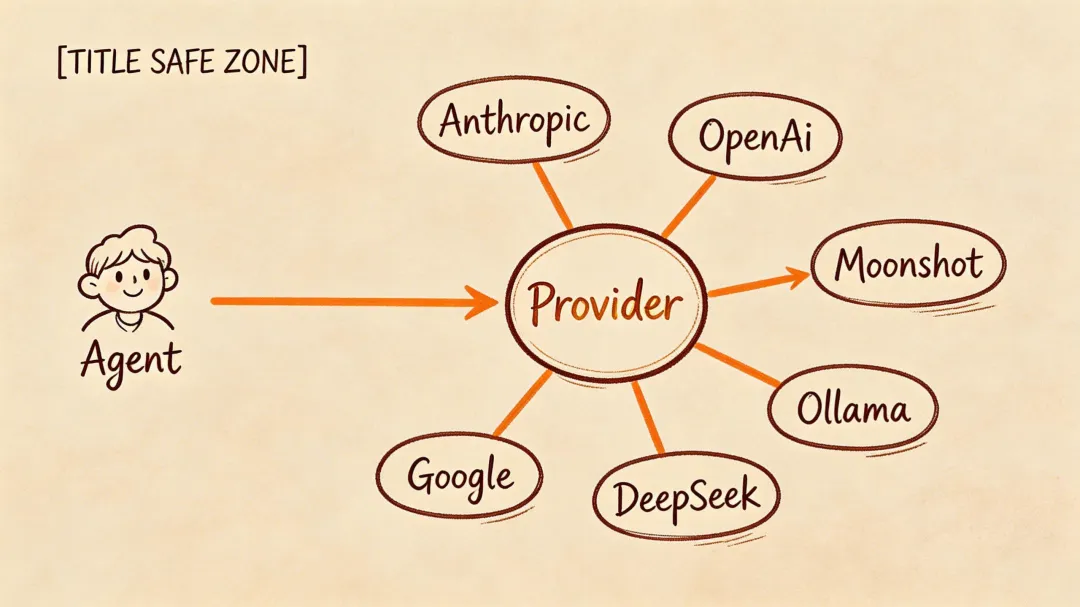
模型 Provider 层是 Agent 和各家 LLM API 之间的翻译官——Agent Runtime 只写一套逻辑,Provider 层负责适配 Anthropic、OpenAI、Moonshot、本地模型等不同协议。
2. 统一接口
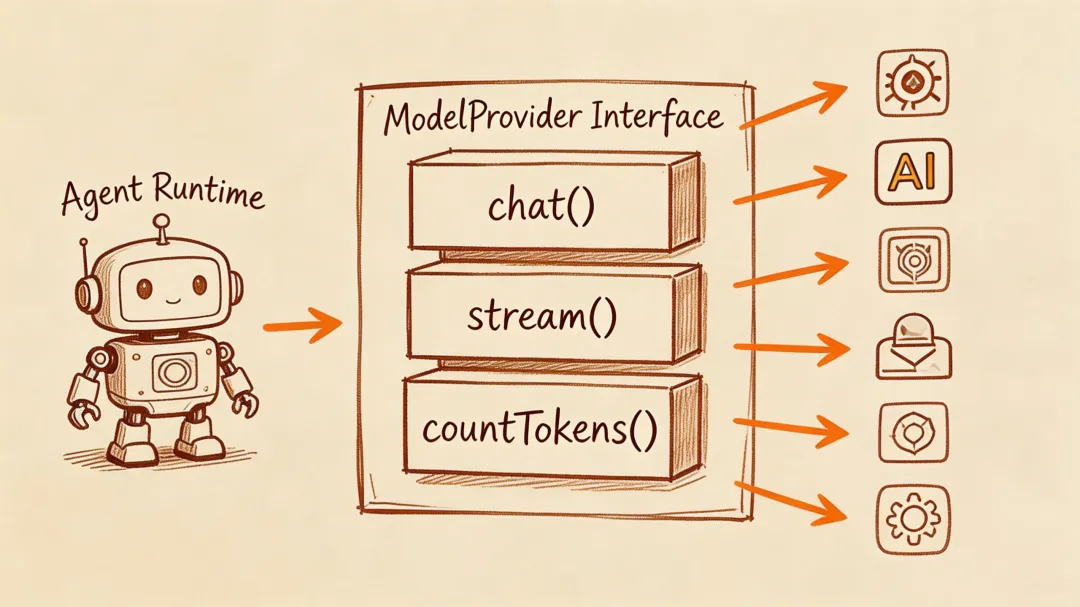
设计思路一句话讲完:Agent 只管思考,Provider 只管翻译。
interface ModelProvider { chat(params: ChatParams): Promise<ChatResponse>; stream(params: ChatParams): AsyncIterable<StreamChunk>; countTokens(messages: Message[], tools?: ToolDefinition[]): Promise<number>;}三个方法就够了。chat 一次性返回结果,stream 流式逐块推送,countTokens 算 Token 做预算控制。
ChatParams 的设计:
interface ChatParams { model: string; // "anthropic/claude-sonnet-4-20250514" messages: Message[]; tools?: ToolDefinition[]; maxTokens?: number; temperature?: number; stopSequences?: string[]; systemPrompt?: string; signal?: AbortSignal;}model 字段用 <provider>/<model-id> 格式,解析一行代码:
const [provider, modelId] = model.split("/", 2);const adapter = providerRegistry.get(provider);adapter.chat({ model: modelId, ...restParams });Agent 端永远是 provider.chat(params)。加新模型?写个 Adapter 注册进去,不碰 Agent 一行代码。
这里有个值得注意的设计选择:OpenAI 兼容协议已经被 DeepSeek、Kimi、Ollama 等跟随,因此只需要实现 Anthropic Adapter 与 OpenAI 兼容 Adapter 两类适配即可;后续新增 OpenAI 兼容 Provider 时可直接复用协议适配逻辑。
你现在可以试一下:如果代码里直接调了某家 API,先把这三个接口定义出来。骨架搭好了,后面的重构会顺很多。
3. 两种 API 协议适配
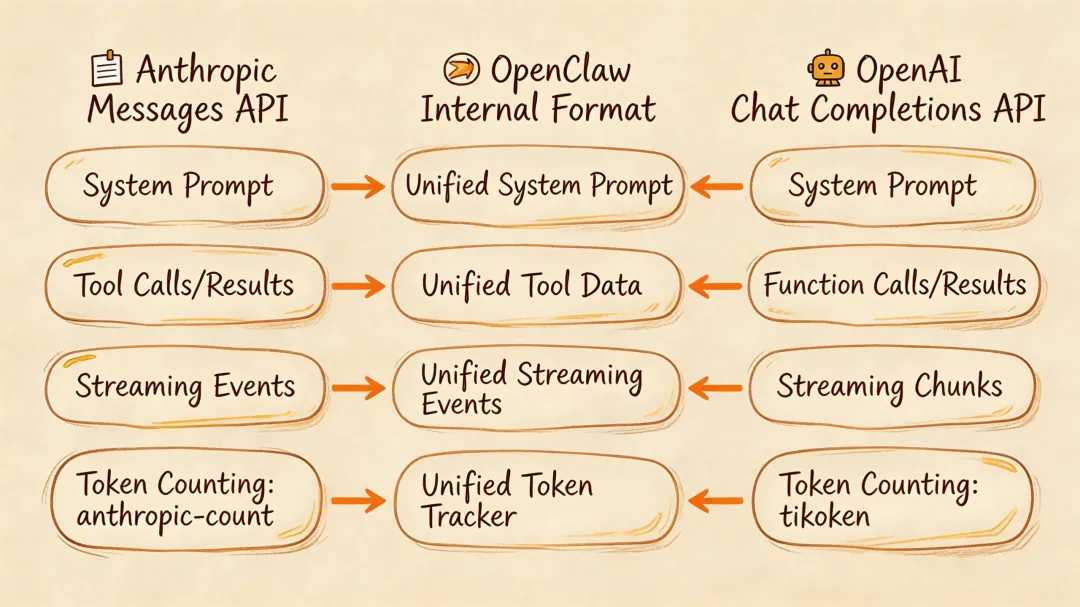
接口定义好了,适配工作需要落地实现。Anthropic 和 OpenAI 的 API 格式看起来像,实际处处不同。
System Prompt 放哪
system 字段 | messages[0]role: "system" |
❌ 拿 OpenAI 的适配代码直接给 Anthropic 用——不行✅ 内部统一用 systemPrompt 字段,各 Adapter 自己放到正确位置
工具调用格式
差异最大的地方:
content 数组,type: "tool_use" | tool_calls 字段 | |
role: "user"type: "tool_result" | role: "tool"tool_call_id | |
{ name, description, input_schema } | { type: "function", function: { name, description, parameters } } |
看工具结果那行——Anthropic 把工具结果塞在 user 消息里用 tool_result 类型区分,OpenAI 专门定义了 tool 角色。消息转换逻辑不能简单映射 role,这里容易踩坑。
Token 计数的两种路线
/v1/messages/count_tokens | tiktoken | |
Anthropic 精确但要走网络,延迟可能是 tiktoken 的 50 倍。怎么办?二级缓存:
• L1 消息粒度: key = sha256(role + content + model),会话生命周期内有效• L2 System + Tools: key = sha256(systemPrompt + toolsJSON),配置变更时失效
这样大多数情况只有最新用户消息需要计数,缓存命中率能到 90% 以上,延迟从几百毫秒降到几毫秒。
其他差异
• 流式事件结构完全不同(下一节讲) • Anthropic 有原生 Prompt Caching,OpenAI 没有 • OpenAI 兼容协议被 DeepSeek、Kimi、Ollama 跟随——写好 OpenAI 兼容 Adapter 后可复用协议适配逻辑
这些差异单独看都不复杂,叠在一起没有适配层的话,Agent 代码会变成 if-else 粥。
4. Prompt Caching

协议搞定了,Agent 跑起来了。然后你发现——Token 费用比预期高得多。
Agent Loop 每一轮都完整发送这些内容:
| 每轮固定开销 | ~5500 |
一轮对话 10 次模型调用不夸张(获取信息 → 调工具 → 分析 → 再调工具……)。5500 × 10 = 55000 Token,按 Claude Sonnet 0.165——全是重复内容。
一天 100 个会话?500,纯粹的"重复税"。
Prompt Caching 做的事:给不变的内容打标记,首次写入缓存加价 1.25x,后续命中只收 0.1x。
怎么标记:
{ "system": [{ "type": "text", "text": "你的 System Prompt...", "cache_control": { "type": "ephemeral" } }], "tools": [ "...工具定义...", { "最后一个工具加 cache_control": { "type": "ephemeral" } } ]}只需标在 system 和最后一个 tool 上。缓存 5 分钟过期,命中自动续。
算账:
| 节省 | 78% | 90%+ |
什么时候不划算
Prompt Caching 不是万能的。三种场景下别盲目开启:
1. 缓存块太小:Anthropic 要求单个缓存块 ≥ 1024 tokens。如果你的 System Prompt 很短,凑不到这个门槛,标记了也不会被缓存。 2. 一次性对话:用户问一句就走,缓存写了就过期(5 分钟 TTL),首次写入的 1.25x 加价反而让你多花钱。 3. 非 Claude 模型:截至发稿,原生 Prompt Caching 仅 Anthropic 支持。OpenAI 的 Predicted Outputs 能覆盖部分场景,其他 Provider 暂时靠 KV Cache 自动优化。
话说回来,只要你的 Agent 是多轮对话场景(大多数 Agent 都是),Prompt Caching 的 ROI 非常可观。按 100 会话/天算,一年在重复 Token 上省下约 $5000。这不是可选优化,是必做项。
5. Fallback 链
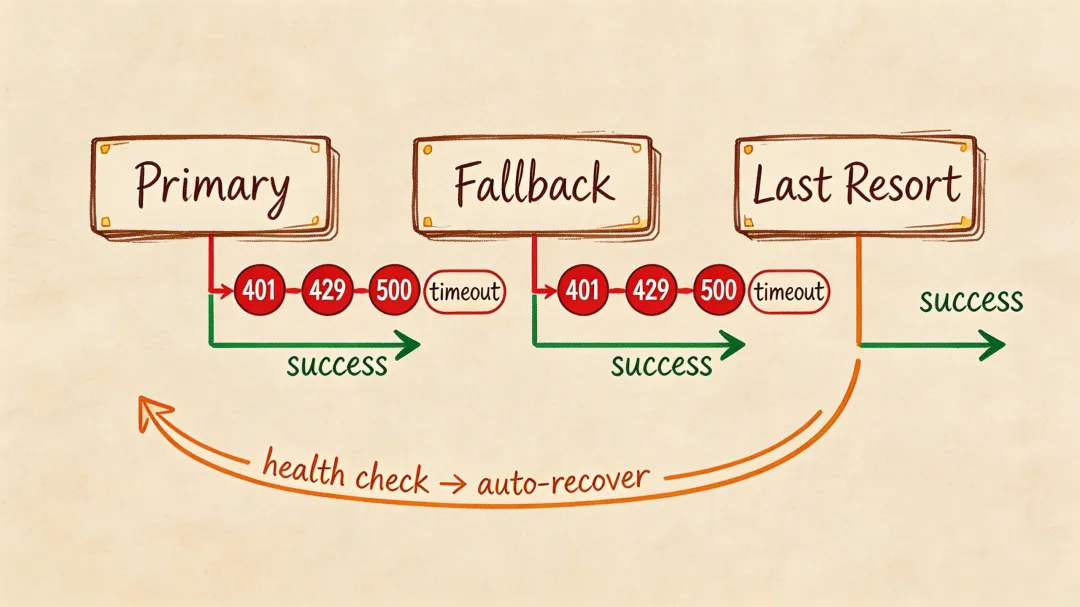
模型 API 在生产环境挂,不是意外,是早晚的事。429 限流、500 服务端错误、网络超时,各种花样都会来。
多模型 Provider 层的一大好处:天然能做 Fallback。
{ "model": { "primary": "moonshot/kimi-k2.5", "fallback": "anthropic/claude-3.5-sonnet", "lastResort": "ollama/qwen2.5:14b" }}但不是"失败了就切下一个"这么粗暴。不同错误需要不同处理:
Retry-After 重试 ×3 | ||
全部重试失败,切 fallback。fallback 也挂,切 lastResort。
两个容易忽略的坑:
坑 1:上下文窗口差异。 primary 是 256K(Kimi K2.5),fallback 只有 200K(Claude Sonnet)。切换前得检查 context 长度,超了就要裁剪——直接截断旧消息或做摘要压缩。
坑 2:能力降级。 Ollama 做 lastResort 时,可能不支持工具调用。降级方案:System Prompt 里追加工具使用说明,然后从输出里解析 JSON 块。可靠性一般,但比直接报错强。
Fallback 后怎么回来
Fallback 不能是永久状态。primary 恢复了,你得切回去——毕竟它可能更便宜或更快。
常见的恢复策略:每个新会话启动时,先尝试 primary。如果 primary 连续 N 次成功(比如 3 次),标记为已恢复。如果你的会话间隔比较长,也可以用定时健康检查——每隔几分钟 ping 一下 primary 的 /models 端点。
每次 Fallback 触发,两件事必做:通知用户("主模型暂时不可用,已切到备用"),记录到 audit.jsonl。日后分析哪家最不稳定,拿数据说话。
6. 流式输出
流式对体验至关重要。没人愿意盯着空白页等 30 秒。不同模型的首 Token 延迟(TTFT)差异明显:Claude 大约 500-2000ms,GPT-4o 快一些在 300-1500ms,Ollama 本地模型则需要 1-5 秒。流式输出让用户在第一个 Token 到达后就能开始阅读。
处理管道:
统一的 StreamChunk:
interface StreamChunk { type: "text_delta" | "tool_call_start" | "tool_call_delta" | "tool_call_end" | "usage" | "done" | "error"; text?: string; toolCall?: Partial<ToolCall>; usage?: TokenUsage;}两家的流式事件差异不小:
content_block_start/delta/stop | choices[0].delta |
message_delta 里 | stream_options) |
适配层把差异吞掉,Agent Runtime 只看统一的 StreamChunk。
Tool Call 拼接:关键细节
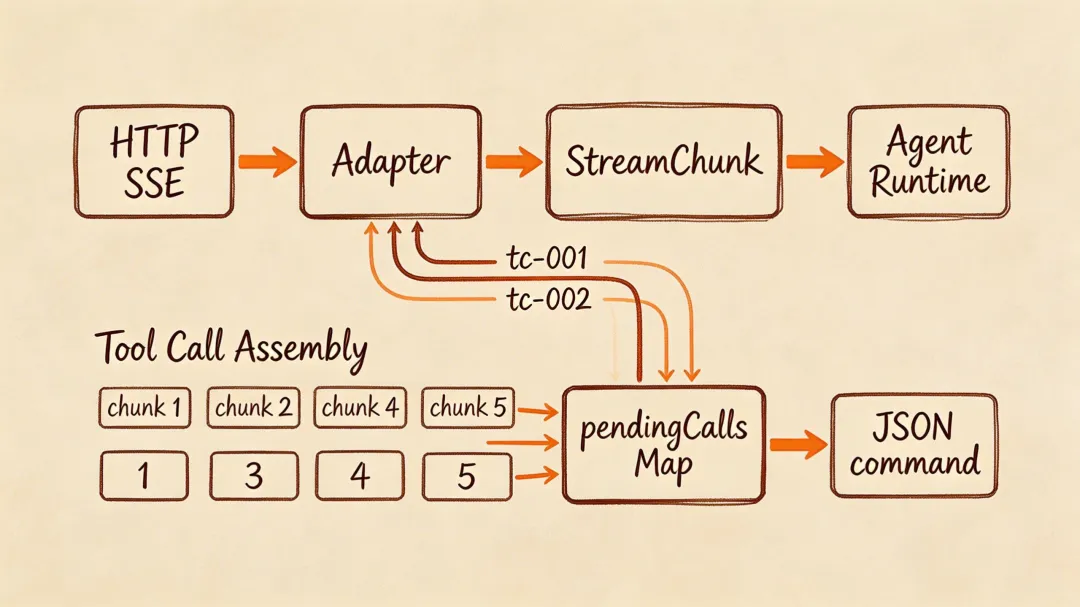
文本流式好办——拼字符串。但工具调用的参数会被劈成碎片:
chunk 1: tool_call_start → { id: "tc-001", name: "exec" }chunk 2: tool_call_delta → { arguments: '{"com' }chunk 3: tool_call_delta → { arguments: 'mand":"ls' }chunk 4: tool_call_delta → { arguments: ' -la"}' }chunk 5: tool_call_end → { id: "tc-001" }{"command":"ls -la"} 被劈成三块。拼接逻辑:
const pendingCalls = new Map<string, { name: string; argBuffer: string }>();// tool_call_start → 建条目pendingCalls.set(id, { name, argBuffer: "" });// tool_call_delta → 追加碎片pendingCalls.get(id).argBuffer += arguments;// tool_call_end → 解析const call = pendingCalls.get(id);const args = JSON.parse(call.argBuffer);这里用 Map 而不是单个变量,是因为模型可能同时发起多个工具调用(parallel tool calls)。比如模型决定同时查天气和查日历,tc-001 和 tc-002 的 delta 会交错到来。Map 按 id 隔离,互不干扰。
JSON.parse 可能失败——模型偶尔输出不合法的 JSON。别让整个流程崩掉。正确做法:记录错误,跳过这个调用,返回 error ToolResult 让模型知道失败了,由它决定下一步。
还有个场景:用户中途取消(signal.abort())。已接收的文本保留,未完成的工具调用直接丢弃。
7. Token 计数与预算
Provider 层跑起来了,最后一件事——确保你知道钱花在哪。
Token 预算控制:每次调模型前,先算一下 context 是否超限。
contextWindow = getModelContextWindow()reservedOutput = agent.config.reservedOutputinputBudget = contextWindow - reservedOutputcurrentTokens = countTokens(context)if (currentTokens > inputBudget): → 触发 Context 修剪:滑动窗口 > 摘要压缩 > 重要性 → 直到 fit within budgetmaxTokens = min(reservedOutput, contextWindow - currentTokens)Token 计数不是总能“本地估算”。为了降低 countTokens 的网络延迟与重复成本,Provider 通常会做二级缓存:
L1:消息粒度缓存(会话生命周期内有效)
• key = sha256(role + content + model)• value = tokenCount
L2:System Prompt + Tools 缓存(配置变更时失效)
• key = sha256(systemPrompt + toolsJSON)• value = tokenCount
把 L1 + L2 命中的 Token 计入预算后,只对“新增/未命中”的消息做精确或估算计数,从而减少网络 round-trip。
在做 budget 控制时,maxTokens 用于保证两点:
1. 输出 Token 不超过 reservedOutput 2. 总上下文不超过 contextWindow
8. 多模态支持
多模态适配的关键在于三件事:能力判断、格式构造、失败降级。
能力判断:Agent Runtime 判断目标模型是否支持视觉:if (model.supportsVision) { ... }
消息构造
Anthropic:图片以 content[] 里的 { type: "image", source: { ... } } 表达,同时可附带文本:
{ role: "user", content: [ { type: "image", source: { type: "base64", media_type: "image/jpeg", data: "<base64>" } }, { type: "text", text: "用户消息" } ]}OpenAI:图片以 type: "image_url" + image_url: { url: "data:..." } 表达:
{ role: "user", content: [ { type: "image_url", image_url: { url: "data:..." } }, { type: "text", text: "用户消息" } ]}降级策略(不支持 Vision 时)
当模型不支持图片理解时,把图片替换为文字描述(例如带一句提示语):"[用户发送了一张图片,当前模型不支持图片理解]" + 文字消息
图片优化(让多模态更稳定)
• 大图自动缩放(例如 > 5MB压缩到1-2MB)• Token 估算:约 ~85 tokens / 512x512 tile• 最大体积:通常限制在 20MB量级• 不支持格式:用 ImageMagick 等工具转码
浏览器截图(browser.screenshot())
当 Agent 获取当前页面截图后,把 PNG base64 以多模态方式传给模型,并提示:"这是当前页面截图, 请分析..."
9. 费用追踪
每次 API 调用后记录到 usage.jsonl。为避免“口径不一致”,以下示例的缓存字段命名与源文 TokenUsage 保持一致:cacheCreationInputTokens(写入)与 cacheReadInputTokens(命中)。cost 为实现层可选扩展字段,用于把 token usage 映射为金额明细。
{ "timestamp": "2026-02-26T10:30:00Z", "sessionId": "s-abc123", "agentId": "main", "model": "moonshot/kimi-k2.5", "provider": "moonshot", "inputTokens": 3200, "outputTokens": 450, "cacheCreationInputTokens": 0, "cacheReadInputTokens": 1800, "latencyMs": 2340, "cost": { "inputCost": 0.0032, "outputCost": 0.0045, "cacheCost": 0.0002, "totalCost": 0.0079 }, "fallbackUsed":false, "stopReason": "end_turn"}费率配置(可自定义更新):
{ "pricing": { "anthropic/claude-3.5-sonnet-20241022": { "inputPerMillion": 3.00, "outputPerMillion": 15.00, "cacheWritePerMillion": 3.75, "cacheReadPerMillion": 0.30 }, "moonshot/kimi-k2.5": { "inputPerMillion": 0.29, "outputPerMillion": 2.57, "currency": "CNY" }, "ollama/*": { "inputPerMillion": 0, "outputPerMillion": 0 } }}汇总查看(openclaw status --usage):
| 合计 | 346,000 | $0.281 |
$ openclaw status --usage --json$ openclaw channels list --json10. 本地模型支持 (Ollama)
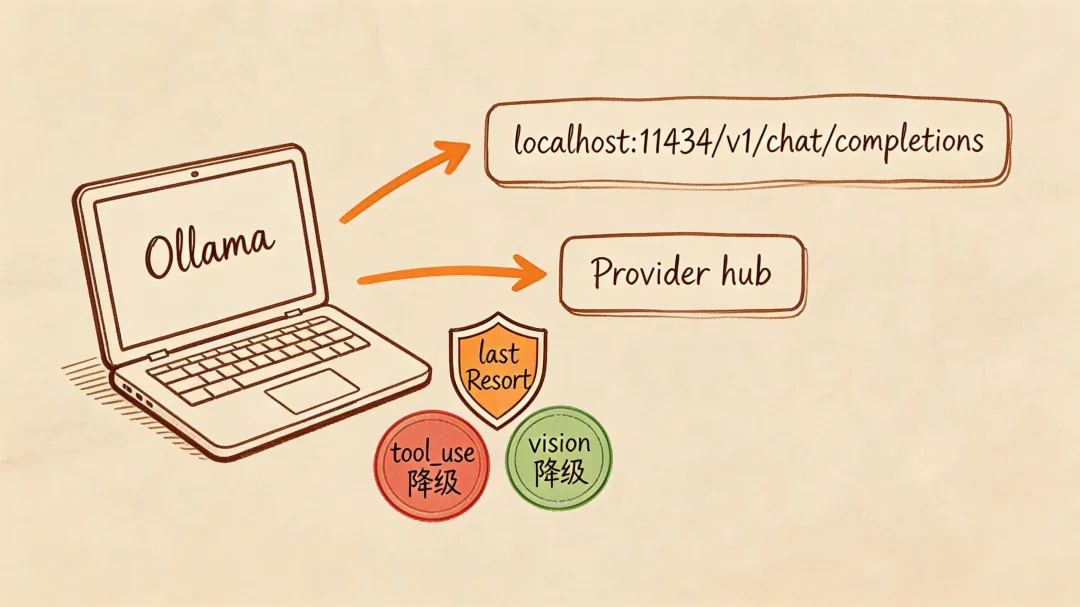
Ollama 适配器用于把本地模型纳入 Provider 体系:零费用 + 完全离线,同时在能力不足时保证“还能用”。
前置条件:本地安装 Ollama,拉取模型(例如 ollama pull qwen2.5:14b),并运行服务(ollama serve → :11434)。
连接:http://localhost:11434/v1/chat/completions(兼容 OpenAI 格式,可复用 OpenAI Adapter)。
启动检测(避免影响其他 Provider):Gateway 启动时探测 GET http://localhost:11434/api/tags;成功则列出可用模型,失败则标记 Ollama 不可用;用户请求 ollama/* 时返回提示信息,但不影响其它 Provider。
能力差异处理:
• 不支持 tool_use:降级为 “manual tool parsing”,System Prompt 追加工具使用说明,并解析模型输出中的 JSON 块作为工具调用(可靠性低,仅作兜底)• 不支持 vision:图片消息降级为文字描述 • 上下文窗口小(4K-32K):更激进裁剪历史、减少 Memory 检索数量
优势与定位:优势是零费用、完全离线、数据不出本机;局限是能力弱、占 GPU/内存、工具调用不稳定。常用于 lastResort / 低成本日常任务 / 离线环境。
11. Provider 注册配置
Provider 注册配置把各 Provider 的鉴权、baseUrl、默认头、超时与重试策略统一到一处:
{ "providers": { "anthropic": { "apiKey": "${ANTHROPIC_API_KEY}", "baseUrl": "https://api.anthropic.com", "defaultHeaders": { "anthropic-version": "2023-06-01" }, "timeout": 120000, "maxRetries": 3, "promptCaching":true }, "openai": { "apiKey": "${OPENAI_API_KEY}", "baseUrl": "https://api.openai.com/v1", "timeout": 120000, "maxRetries": 3 }, "moonshot": { "apiKey": "${MOONSHOT_API_KEY}", "baseUrl": "https://api.moonshot.cn/v1", "timeout": 120000, "maxRetries": 3 }, "deepseek": { "apiKey": "${DEEPSEEK_API_KEY}", "baseUrl": "https://api.deepseek.com", "timeout": 120000, "maxRetries": 3 }, "google": { "apiKey": "${GOOGLE_API_KEY}", "baseUrl": "https://generativelanguage.googleapis.com/v1beta", "timeout": 120000, "maxRetries": 3 }, "ollama": { "baseUrl": "http://localhost:11434/v1", "timeout": 300000 } }}12. 模型能力矩阵

模型能力矩阵用于快速判断:某个模型是否支持工具调用、是否支持流式、是否支持视觉、上下文窗口与成本结构:
成本/M = 每百万 Token(输入/输出);"免费" = 本地运行,无 API 费用;Cache = 是否支持原生 Prompt Caching
13. 性能特征
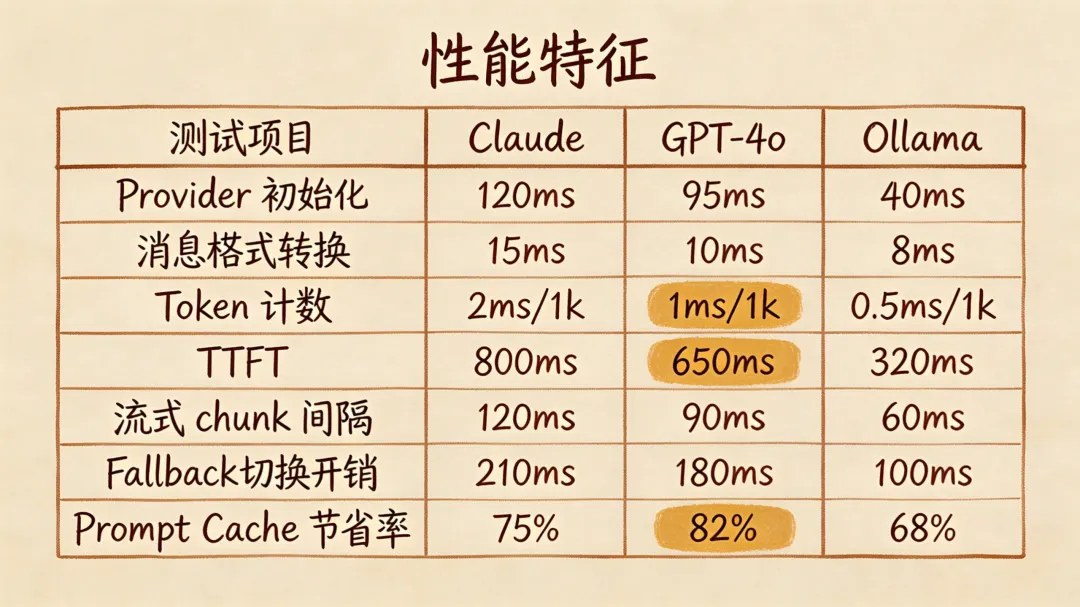
性能数据帮助你把“慢”定位到环节,而不是只盯着端到端耗时:
写在最后
**Agent 只管思考,Provider 只管翻译。**把协议差异(消息/工具/流式)、Token 预算控制、Prompt Caching 成本优化、以及 Fallback 容错都下沉到 Provider/Adapter 层后,Agent Runtime 就能在“加模型/换模型”时保持稳定。
工程落地建议:从统一的 ModelProvider 接口(chat / stream / countTokens)开始,把具体 Provider 协议适配与多段流式事件归一化做成 Adapter;随后再补齐 Vision/Ollama 能力判断、费用追踪与性能可观测性。
