 夜雨聆风
夜雨聆风nomic-embed-text 是 OpenClaw 实现本地、免费、高性能记忆检索的核心嵌入模型,主要用于将对话历史、文档等文本转为向量,支撑智能体的长期记忆与语义搜索。
ollama pull nomic-embed-text
"memorySearch": {"enabled": true,"provider": "openai","model": "nomic-embed-text","remote": {"baseUrl": "http://10.0.2.2:11434/v1","apiKey": "ollama"}},
openclaw memory index // 通过此命令建立索引通过 openclaw memory status 查看记忆状态
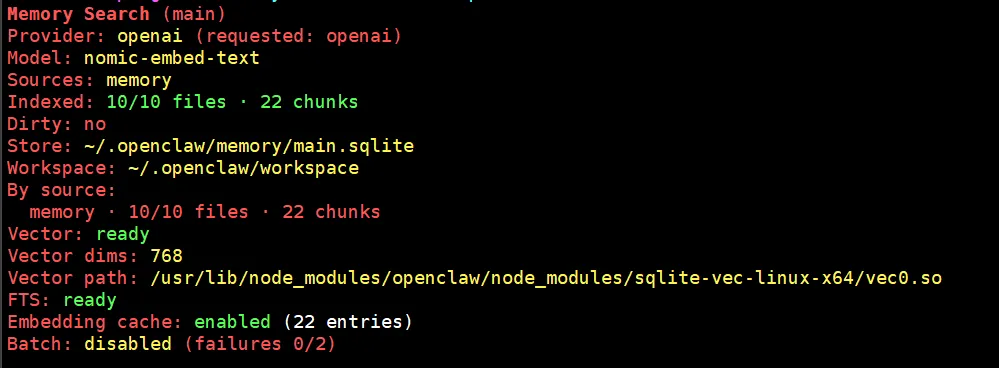
nomic-embed-text 与QMD的区别(AI总结)
在 OpenClaw 中,nomic-embed-text 是嵌入模型(工具),QMD 是完整记忆检索后端(系统),二者是 “嵌入能力” 与 “检索系统” 的关系,而非直接竞品。下面从定位、架构、流程、配置、性能、适用场景做全面对比。
一、核心定位与本质区别
1. nomic-embed-text
- 角色
文本嵌入模型(Embedding Model),负责将文本转为固定维度向量(768 维)。 - 能力边界
仅做向量化,不做存储、检索、重排序、分块、查询扩展。 - 在 OpenClaw 中的位置
作为 memorySearch的嵌入提供方(provider: ollama/openai),为 SQLite 向量库生成向量。
2. QMD 记忆
- 角色
完整记忆检索后端(Memory Backend),替代默认 SQLite 方案。 - 能力边界
全链路检索系统,包含: 嵌入(内置 GGUF 模型,可搭配 nomic) BM25 全文检索 向量检索 查询扩展、RRF 融合、LLM 重排序 语义分块、Markdown 优先、自动索引 - 在 OpenClaw 中的位置
memory.backend = "qmd",接管全部记忆逻辑。
一句话总结:nomic 是 “编码器”,QMD 是 “检索引擎 + 记忆管理系统”。
二、架构与工作流程对比
1. nomic-embed-text 流程(默认 SQLite 方案)
文本 → nomic-embed-text → 768 维向量 向量存入 SQLite 向量表 查询 → nomic 生成查询向量 → 余弦相似度检索 → 返回 Top-K 结果直接注入 Prompt(无重排序 / 分块)
2. QMD 记忆流程(多阶段混合检索)
- 查询扩展
LLM 生成语义相近查询(如 auth → login process) - 并行检索
BM25 全文 + 向量检索(可使用 nomic 嵌入) - RRF 融合
多结果加权排序(Reciprocal Rank Fusion) - LLM 重排序
本地 GGUF 模型二次打分,确保最相关优先 - 语义分块
按标题、代码块、分割线智能切分,避免长文本噪声 - 结果精简
仅返回 2–3 句最相关片段,而非全量记忆
选择 nomic-embed-text(SQLite)的场景
快速原型、轻量级使用 已深度依赖 Ollama 生态 记忆量小(<10k 条)、无需极致速度 / Token 优化 不想额外安装 Bun/QMD 等工具
选择 QMD 记忆的场景
长期运行、记忆量大(>10k 条) 追求极致 Token 节省(90%+)与响应速度(50x+) 需要高精度混合检索(关键词 + 语义 + 重排序) 重视Markdown 原生支持与智能分块 生产环境、需要自动索引与故障降级
资深工程师,业余摄影、吉他爱好者,不定期更新关于人工智能、产品设计、系统架构、管理、生活的思考,关注我一起进步。
