 夜雨聆风
夜雨聆风
很多人聊 OpenClaw,最容易记住的都是那些很炸的演示。但真正值得讲的,不是它看起来有多酷,而是它到底有没有机会从一个「看起来很厉害的 Agent」,变成一个真能进业务、进企业、甚至最后跑出收入的系统。
所以我们今天
从爆火原因讲到具体工作流,再讲到具体的配置隔离。
看看有什么是可以利用龙虾为我们服务的。

OpenClaw 为什么会火
它踩中了这一轮 AI 情绪
OpenClaw 这一波火,首先不是孤立事件。它踩中的,是 DeepSeek 之后这一轮全民关注 AI 的情绪。
以前很多 Agent 项目,其实只在开发者圈子里转。圈内人很兴奋,圈外人基本无感。OpenClaw 不一样,它已经开始被圈外人感知到了。很多平时根本不碰命令行的人,也会因为它去了解 Agent。这件事本身就说明,它已经不只是一个小圈子里的工具。

它第一次让普通人明显感觉到,AI 真在干活
很多人其实不关心底层框架,也不关心你用了多少技术名词。他们只关心一件事,我把任务扔过去,它能不能自己跑,最后把结果交回来。
OpenClaw 在这件事上特别容易给人「它真在干活」的感觉。你把任务丢给它,它会持续往下跑。再加上每次重置以后那种「我已经醒来了」「今天有什么任务」的反馈,用户很容易产生一种专属感。
它不是标准化的软件,更像你自己慢慢养起来的一套工作系统。
它不是一个网页工具,更像一套自己的算力包
很多工具给人的感觉是租来的,用完就走。OpenClaw 给人的感觉不太一样。你会觉得它不是一个随手开关的网页,而是一套会越来越像你自己的东西。
这也是为什么很多人愿意折腾它,愿意给它装 Skills,调模型,改结构。因为你在用它的时候,不像在租一个公共工具,更像是在搭自己的算力包。
它能直接住进你的工作环境
OpenClaw 可以通过 WebSocket 长连接接进飞书、钉钉这类办公 IM。
这件事的意义其实很大。以前很多 AI 工具都是独立存在的,你得专门打开一个页面,专门切过去操作。现在它可以直接住进你每天都在用的工作环境里,AI 就不再是额外工具,而是工作环境的一部分。
本地文件就是工作台
我一直觉得,OpenClaw 最重要的一点,不是某个单独的功能,而是它把「本地文件就是工作台」这件事做得很明显。
像豆包这类产品,你和它交流,很多时候还是在云上。你得不停上传文件、补背景、补上下文。OpenClaw 一旦本地部署以后,你电脑里的文件天然就是它的上下文,这会大幅降低「喂信息」的成本。
说白了,OpenClaw 吸引人的地方,就在于它尽量把这种「喂工具」的感觉压下去了。
它不是突然冒出来的,而是 Agent 路线往前走了一步
再往深一点看,OpenClaw 也不是突然从天上掉下来的。
前面有 Dify 这种偏工作流编排的路线,也有 AutoGPT 这种更强调自主决策的路线,往后才慢慢长出 OpenClaw 这种更接近「能干活」的形态。包括 Manus,也可以看成这条路线继续往前走的一部分。
所以它这次火,不是偶然,只是刚好跑到了一个普通人都能明显感到「这玩意真有用」的阶段。
为什么最适合拿电商来做实战
电商这个场景,最容易测出真假价值
我为什么总喜欢拿电商来讲 Agent,不是因为电商最时髦,而是因为它最容易测出一个 Agent 到底有没有用。
电商的问题都很具体。客服和运营成本高,晚间客服有时候比白天还贵。平台又很碎,Etsy、亚马逊、社媒、表格、飞书来回切。内容供给压力也大,从选题、脚本、图片、视频到投放,整条链都在持续要东西。更麻烦的是,这里面很多活看起来不难,但特别碎,特别耗人。

也正因为电商够具体,所以它非常好验证价值。一个 Agent 如果真能帮你减少切平台、搬数据、做素材、产内容的时间,那它就是有用的。反过来,如果它只能陪你聊天,电商场景会非常快地把它打回原形。
五步链路
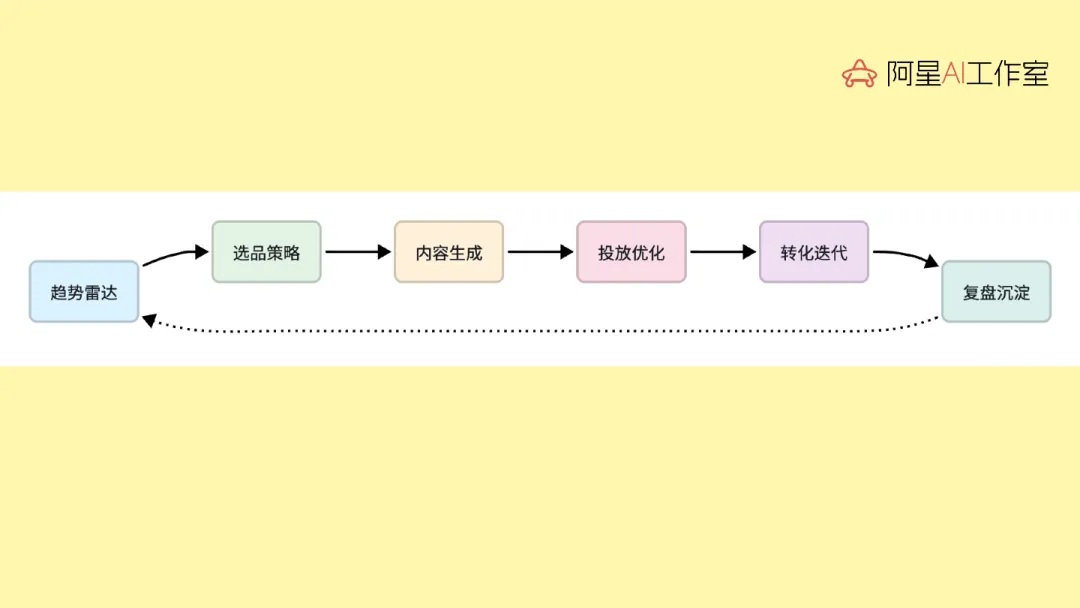
第一步是监控爆款。
这里可以用 Apify 下面的 TikTok Research。做法其实没有很多人想得那么复杂,你找到对应文档以后,直接发给 OpenClaw,告诉它你要实现 Apify 下面的 TikTok Research 功能,它就能开始去抓 TikTok 上的热点数据。以前做爬虫是一个很明确的技术活,现在这道门槛已经被压低很多了。哪怕你没系统学过编程,也可以先把这一环试着跑起来。

第二步是脚本生成。
抓到爆款以后,不是原样照搬,而是把爆款视频拆出来,拿去仿写自己的口播文案。这一步最容易被忽略的,不是提示词,而是模型分层。不同 Agent 完全可以配不同价位的模型,写脚本、跑轻任务的地方没必要全程高配。模型分层,不只是技术问题,更是成本问题。

第三步是商品图处理。这里有两个特别容易被忽略,但非常关键的动作。一个是抠图和风格化处理,可以用 Kie、remove.bg 这类 API。另一个是把处理后的图片传到图床,拿到稳定链接。这个细节如果不提前说,很多人跑到一半就会断。因为后面很多 API 认的是图片链接,不是你在飞书里随手发过去的一张图。像 ImageBB 这类免费图床,对前期试跑已经够用了。
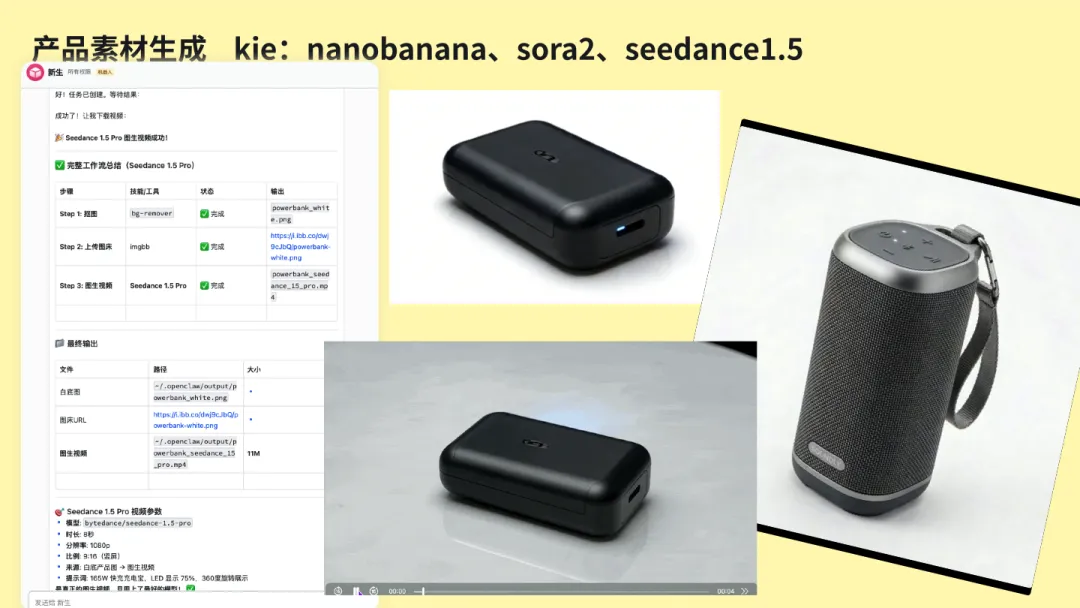
第四步是图生视频。常见模型会提到 Kling、Veo 这些。重点不在于某个模型名字,而在于这条链路现在真的已经能串起来了。你先抠图,再上传图床,再图生视频,整个过程 OpenClaw 还可以在飞书里实时播报进度。也就是说,你在手机上拍完图,往飞书里一扔,后面的很多步骤可以在后台继续跑。这种体验和以前必须守着网页、盯着进度条完全不是一回事。
第五步是发布。但这一步一定不要一上来就搞全自动发布,最好先保存到草稿箱,最后一步留给人工收口。原因非常现实,尤其是小红书这种平台,现在对自动化动作很敏感。有人内容还没正式发出去,就已经因为自动化行为被判违规了。所以真正成熟的链路,不是把所有步骤都自动化,而是自动化跑到草稿箱,把最敏感的一步留给人。
Skills 生态到底值钱在哪
真正的价值,不只是生成内容
很多人看 OpenClaw,只盯着它会不会写文案、会不会生成内容。其实这只是最表面的一层。
OpenClaw 真正有意思的地方,是它能插进很多具体业务环节。也正因为这样,很多单独拿出来就能卖钱的小工具、小服务,正在被 Skills 生态一点点吃掉。

Amazon Search、Listing 优化和竞品情报
先说 Amazon Search。这部分可以用 Decode Scrape 下面的 Amazon Search。它能抓商品价格、评论、差评关键词和性能反馈,直接帮你做竞品情报。
这里有个很现实的信息,很多链路并不需要先大投入。像这类工具,前期免费额度往往已经够试很多次了。也就是说,你完全可以先低成本把第一圈验证跑通,再决定要不要继续往里砸钱。
再往下就是 Listing 优化。这里绕不开 A9、Cosmo 和 Rufus。提这些名字,不是为了堆术语,而是想说明一件事,亚马逊站内优化不是随便找个提示词模板就能解决的。你得理解平台自己的算法逻辑,理解用户意图,再把这些规则揉进 Skills 里。这样跑出来的东西,和那种「复制一个万能提示词」的做法,差别会很大。

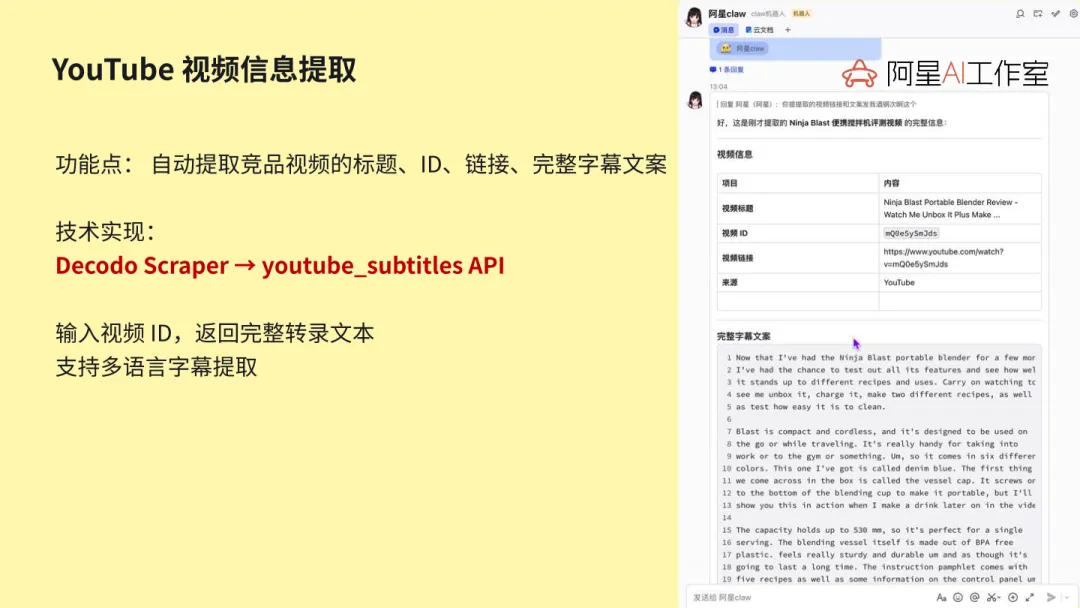
YouTube 字幕、Reddit 社区和邮箱获取
YouTube 字幕提取也是特别实用的一块。通过 Decode Scrape 里的 YouTube Subtitles,可以直接把视频字幕拉出来。对做跨境内容、拆口播结构、模仿爆款的人来说,这一步非常有用。更重要的是,它比本地折腾 Whisper 友好得多。很多人不是不会用,而是死在环境上。
Reddit 社区营销更有意思。它不是只帮你写一篇种草帖,而是会给你一整套社区运营输出。它能帮你做舆情分析,给你回复模板,推荐你该去哪些社区发,还会给你人设和养号建议。
比如你卖充电宝,正常人第一反应都是去 3C 社区,但 AI 完全有可能给你发散到旅行社区,因为充电宝本来就是旅游场景的刚需。这种发散能力,才是 AI 真正开始进入运营环节的地方。
客户邮箱获取也很现实。这里可以用 Apify 下面的 Google Map Email Extract。它能搜谷歌商家,抓商家网站,再把邮箱、电话和社交媒体提出来。这个东西以前单独做成小工具,拿出去卖一两千块,并不夸张。
现在越来越多这样的价值,正在被免费 Skills 吃掉。所以 AI 带来的变化,不只是多了几个新工具,而是在改写很多小工具和小服务原本的商业逻辑。
套娃包、剪辑工具和信息沉淀
另外还有一些偏搜索和内容优化的 Skills,比如 GEO、SEO 相关能力,还有 seo-geo-claude-skills 这种明显的套娃包。套娃包真正的价值,不是一次装很多东西,而是初学者不用上来就自己拼积木,可以先把一整套能力装进去,先跑,再慢慢拆。
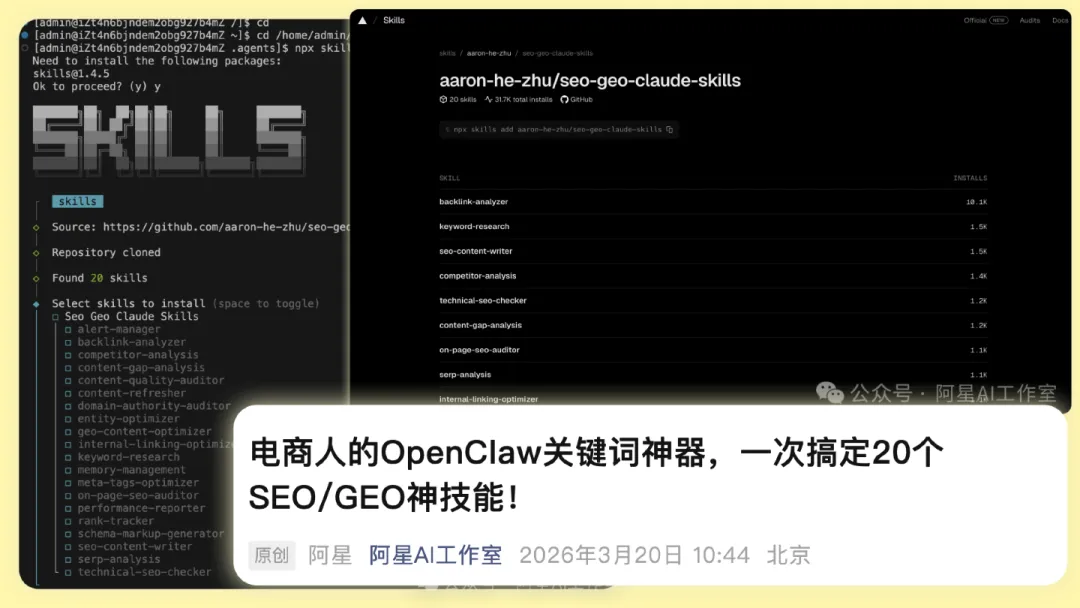
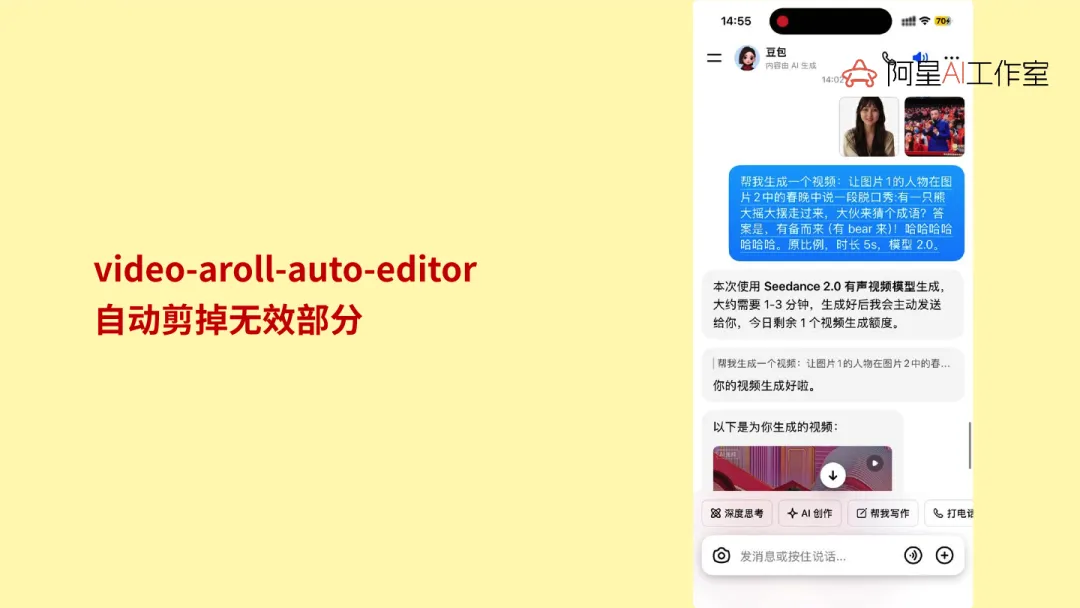
还有一个很容易被忽略,但其实很值钱的工具,叫 Video Error Auto Editor。它做的事情不花哨,就是把录屏里的白边、口水话剪掉。但这种东西一旦接进工作流,能省掉大量重复拖拽。对口播类视频来说,这种能力特别实用。
最后还有一个特别值得记住的,叫 AI Daily Digest Skill。它不是做电商链路本身的,而是做信息抓取和内容沉淀的。它每天可以抓很多顶级博客,再汇总成飞书文档。这个例子说明一件事,OpenClaw 不只适合做发布型工作流,它也很适合做研究型、沉淀型工作流。
真正决定上限的,是多 Agent 和权限结构
多 Agent 不是花活,它决定系统会不会乱
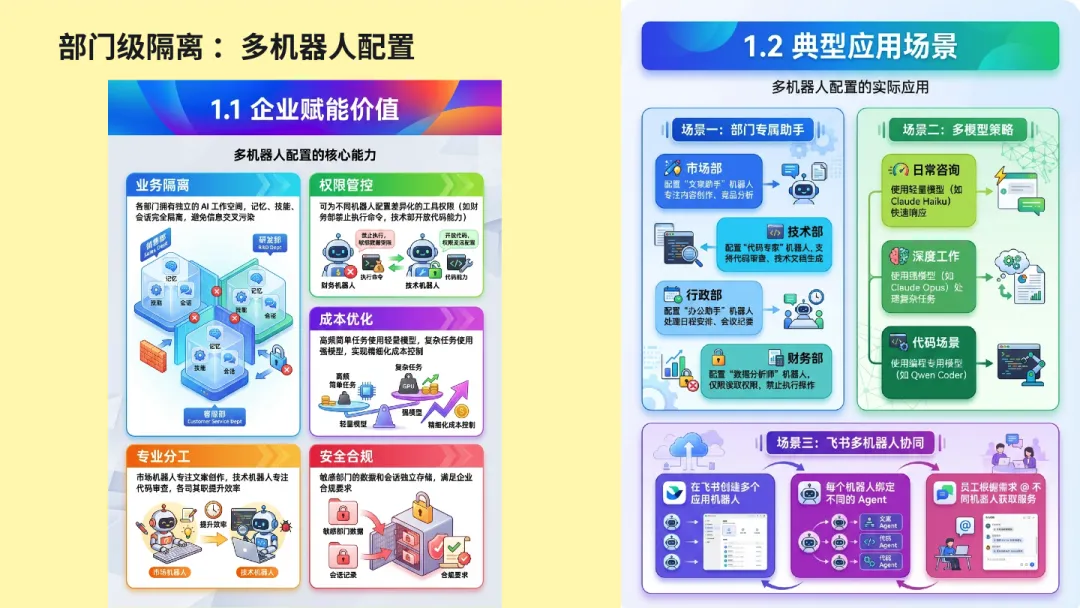
很多人一听多 Agent,会先觉得酷。但真实情况不是越多越好,也不是一个机器人什么都能干就最强。

更合理的做法,是主 Agent 加子 Agent。主 Agent 负责总入口,下面挂 marketing、admin、finance 这类子 Agent。每个 Agent 最好都有自己的 agent.md、自己的 workspace、自己的 Skills、自己的模型配置。可以把它理解成,每个 Agent 都有自己的房间,规则、资料、产出都放在自己房间里。
这样拆的好处很直接。职责清楚,不容易打架。成本也更容易控制。因为不同 Agent 完全可以配不同价位的模型,低复杂度、低风险的任务,不需要一直跑最贵的模型。很多人聊 Agent 只聊能力,不聊成本,但真落地的时候,成本从来绕不过去。
真进企业,关键不是能不能用,而是怎么隔
如果只是个人玩家,权限这一层可以先不用想太复杂。但只要开始往企业里走,这一层马上就会变成重点。
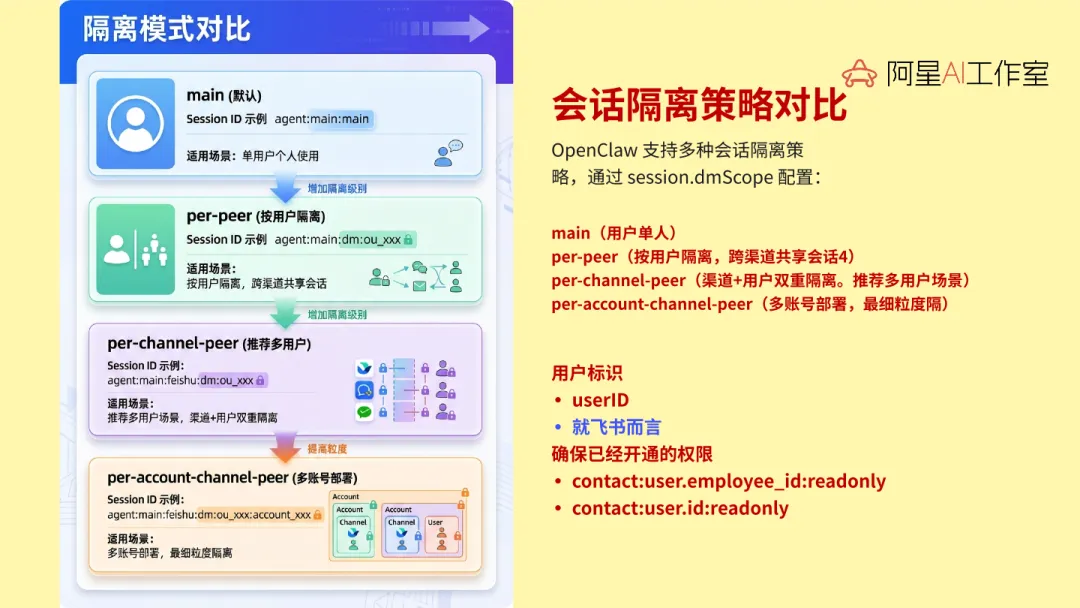
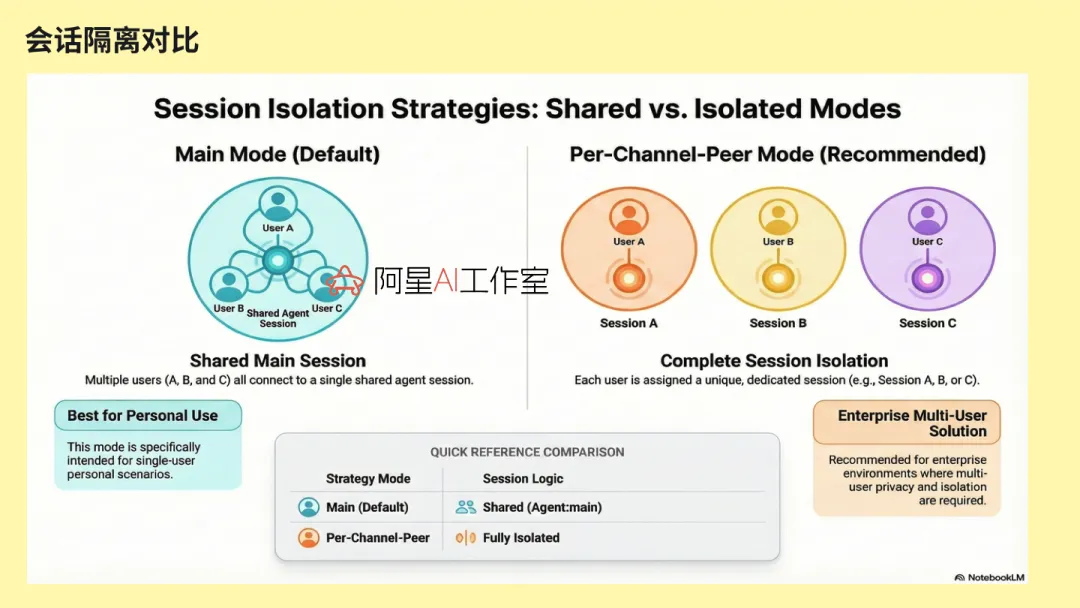
第一层是会话隔离。像 per_channel_per_peer 这种模式,用户和用户渠道之间会不会串,渠道和渠道之间会不会串。这个问题如果不先想清楚,企业里一上来就很容易出事。
第二层是角色权限。为什么要拆行政 Agent、技术 Agent、财务 Agent?因为企业本来就不是所有人看同一套东西,也不是所有人都该用同一套能力。你在给企业做 Agent,本质上是在模仿企业自己的组织架构,而不是单纯给 AI 配几个开关。
第三层就是 RBAC 和资源权限。谁能看哪些 Skills,谁能读哪些文件,谁能动哪些资源,说到底都在回答同一个问题,谁能访问什么。也正因为 OpenClaw 具备这层资源读写和权限控制能力,它才真的有机会往企业场景里走,而不只是停留在个人玩具阶段。
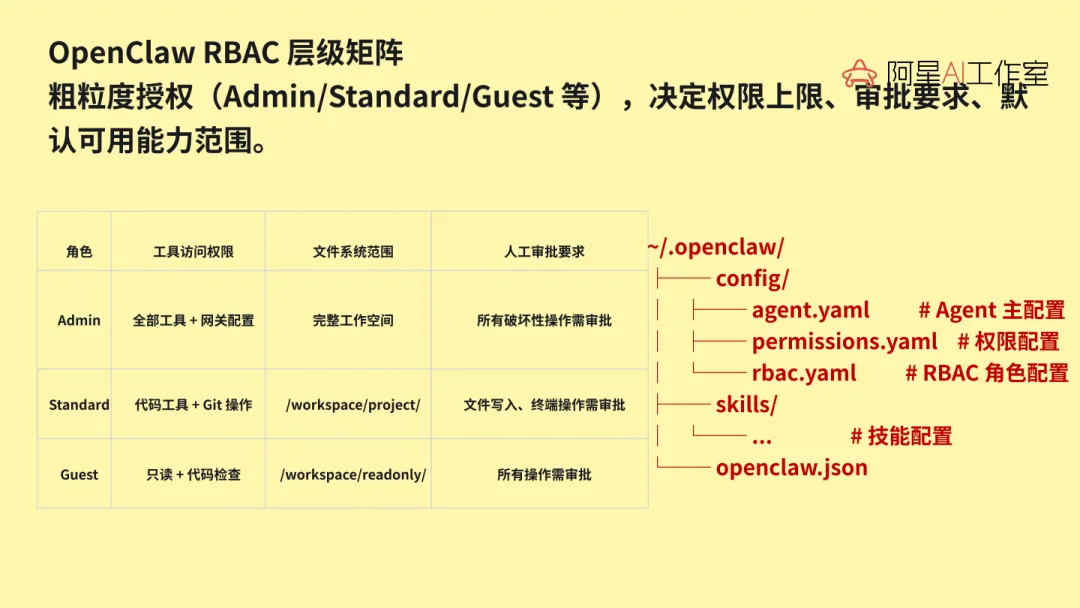
再往上就是运维层。这里一定要把 Hooks 和 Heartbeat 分清楚。Hooks 更像事件钩子,适合做通知、异常提醒、事件触发。Heartbeat 更像定期任务,适合做备份、巡检这类事情。个人用户短期可能还不太用得上,但企业一旦真的跑起来,这一层很快就会变得很重要。

最后
本地还是云上,关键看你在哪个阶段
如果你是为了学习,优先本地。如果你是为了稳定运行,可以考虑云上。
本地的好处很明显,文件都在眼前,素材拖进去就能用,图片、视频、文档都更好处理,整个系统也更容易建立结构感。尤其你要做抠图、剪视频、看输出结果的时候,本地体验会顺很多。
云上的好处是更稳,或者说更不怕折腾坏。玩坏了还能重开,也更适合长期服务。但云上也有明显的问题,文件上传下载麻烦,一些本地模型和本地素材工作流也没那么顺手。
不是会不会养虾,而是虾能不能养你
聊到最后,还是要回到 OPC,回到现实。
OPC 不是头衔,不是姿态,也不是你会多少技术,而是你能不能把东西卖出去,能不能跑出自己的商业闭环。
所以判断一套 OpenClaw 系统有没有价值,不是看它演示的时候多酷,也不是看你装了多少 Skills,而是看它最后能不能变成工作流、服务、内容和结果,能不能真的给你带来收入。
你可以靠它做教程,做插件讲解,做短视频,做部署服务,做内容流量,甚至哪怕只是帮别人搭一套环境搞点零花,这都比谈「我在养虾」更接近真实世界。

真正值得追的,不是概念,
而是你能不能把业务拆开、接上、落地,
最后变成自己的收益。

