 夜雨聆风
夜雨聆风用OpenClaw不到2小时就将2000+法律法规+最高院案例文件导入dify知识库,召回测试准确率高达0.9+。但由于最近痴迷“玩虾”,一直没时间发布这篇文章。
下面就不啰嗦了,直接上干货。
前期准备
因为我的工作场景只涉及金融债权纠纷的法律问题
所以我的知识库,只涉及三个大类:
1.民事法律法规(含民事实体法律、民事程序法律、公司法、破产法、司法解释、强制执行相关规定等)
2.最高院案例(入库案例、指导案例、典型案例、上海金融法院案例、强制执行案例等)
3.最高检案例(仅与金融借款纠纷、刑民交叉等相关)
以上法律、案例来源均来自国家法律法规数据+人民法院案例库,绝对权威。
用dify或openclaw的工作流抓取,再将word、pdf文件转化成markdown格式。转化文件格式的目的是让知识库更加精准进行RAG向量化,这是召回准确率的核心保证。
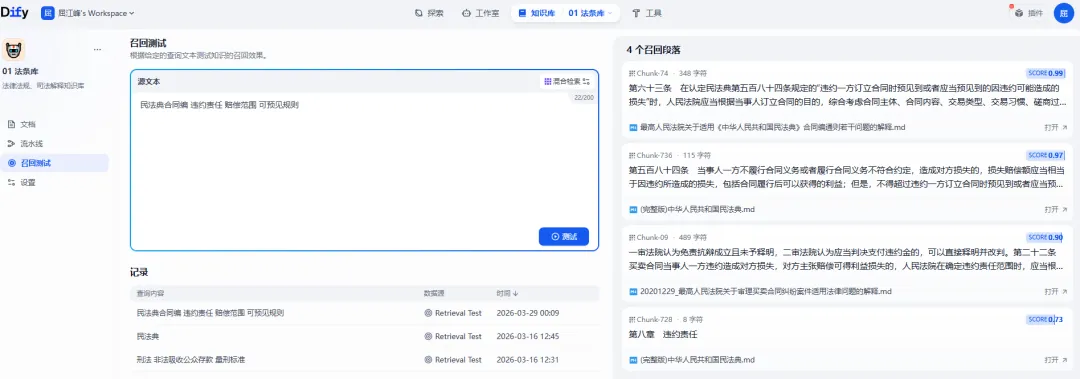
原文件路径如下
/home/LegalBase/├── 01legislation/ (521 个法条文件)├── 02judgment/ (1290 个案例文件)└── 03judgment/ (246 个案例文件)总计 2057 个文件。如果手工上传,按每个文件 1 分钟计算,也得34 小时不眠不休。
一、技术选型:为什么是 OpenClaw+Dify?
1.问题拆解
面对这个任务,我拆解了三个核心问题:
| 问题 | 挑战 | 解决思路 |
| 批量上传 | 2000+ 文件,手工不可能 | 调用 Dify API 自动化 |
| 模型成本 | Embedding+Rerank 商业 API 太贵 | 硅基流动免费额度 |
| 中文路径 | Linux 下中文路径编码陷阱 | 多种方案绕过 |
特别说明:我之前发现硅胶流动有免费的Embedding+Rerank额度
2.技术栈确定
子agent技术会议结束,方案敲定:
┌─────────────────────────────────────────────────────────┐│ 法律知识库自动化导入架构 │├─────────────────────────────────────────────────────────┤│ OpenClaw (任务编排) → Bash 脚本 → Dify API → SiliconFlow │└─────────────────────────────────────────────────────────┘核心决策:
- OpenClaw — 原生支持任务编排、脚本执行、错误处理
- Dify — 开源、支持混合检索、Rerank 重排序
- 硅基流动 — BAAI 模型免费 API,中文优化,100 万次/月额度
二、 首战告捷:API 对接成功
第一个里程碑达成:
openclaw与dify知识库API对接
关于dify知识库id,在你新建知识库的时候他会自己的生成,类似"f3cc0223-c189-42c4-bd9c-fa2575bff1e5"的字段
# 创建知识库curl -X POST "http://localhost/v1/datasets" \ -H "Authorization: Bearer dataset-xxx" \ -H "Content-Type: application/json" \ -d '{"name":"01 法条库","description":"法律法规知识库"}'# 返回{"id":"f3cc0223-c189-42c4-bd9c-fa2575bff1e5"}确定好dify知识库id后,让openclaw测试上次一个法条文件
{"document":{"id":"bf2524e9-1a67-4b49-9f22-0833eb81b19e","name":"中华人民共和国证券法.md","indexing_status":"waiting"}}看着返回的 JSON,我知道方向对了。
三、踩坑时刻:批量上传全部失败
虽然单个文件上传成功,但批量上传时,100 个文件全部失败。
# 批量上传脚本for file in /tmp/dify_upload/*.md; do curl -X POST ... -F "file=@$file"done# 返回{"error": "Too many requests", "code": 429}显示错误 429,原因是请求过于频繁,触发限流。
以下是我的排查过程
这足以证明,咱这是纯实践过程,而非AI文章了吧
具体排查步骤如下:
第一步: 降低并发,改为串行
- 结果:依然失败,但错误变成了数据库连接超时。
第二步: 检查 Dify 容器日志
- 发现:数据库连接池已满,最大连接数 100 被耗尽。
第三步: 修改 Dify 配置
- 结果:需要重启容器,但重启后问题依旧。
排查故障突破
单个文件上传成功,但连续上传 20 个后开始失败。
经过我和openclaw的沟通,问题不在并发,而在速率——单位时间内请求太多。
最终方案: 每 20 个文件暂停 3 秒
if [ $((count % 20)) -eq 0 ]; thensleep 3fi测试通过。100 个文件,全部成功。
四、 中文路径陷阱:Linux 下的编码噩梦
当第二批上传时,遇到了更隐蔽的问题:
# 直接访问中文路径ls /home/法律知识库/01 法条库/# ❌ No such file or directory文件明明在那里,但就是访问不了。
根因分析
经过 2 小时排查,定位到根本原因:
| 层级 | 配置 | 问题 |
| Shell | LANG=en_US.UTF-8 | 中文路径解析失败 |
| Python | 默认编码 ASCII | 与文件系统编码不匹配 |
| 文件系统 | ext4 | 支持 UTF-8,但需要正确 locale |
openclaw给了我四种解决方案
方案 1:cd 到目录内部执行 find
cd /home/法律知识库 && find . -name "*.md" -path "*01*"方案 2:使用通配符绕过中文
ls /home/法律*/01*/ # ✅ 可以访问方案 3:使用 inode 访问
find /home/法律知识库 -inum 659869 -execls -la {} \;方案 4:复制到英文路径(最终采用)
mkdir -p /tmp/dify_batch_01find . -name "*.md" -path "*01*" -execcp {} /tmp/dify_batch_01/ \;和openclaw中的“码农”子agent协商,我们最终选择了方案 4——虽然多一步复制,但最稳定可靠。
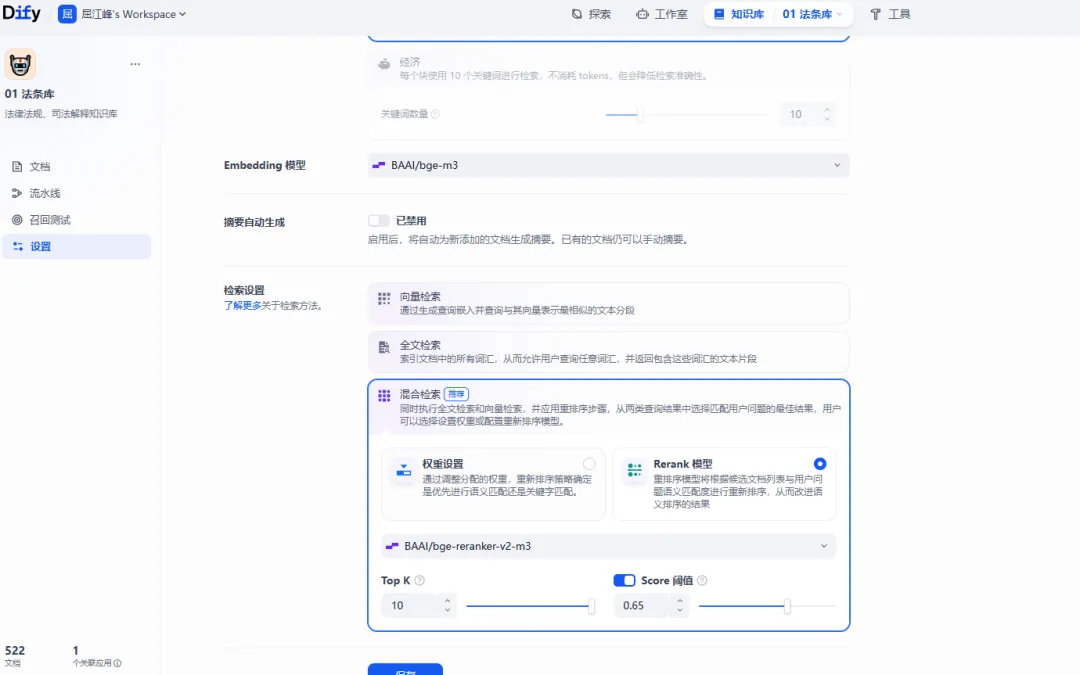
五、知识库配置:法条库 vs 案例库的差异化策略
上传成功后,进入检索配置阶段。这里有一个关键决策:法条库和案例库,要不要用同一套配置?
核心差异
| 检索特点 | 法条库 | 案例库 |
| 查询意图 | 精确匹配法条号 | 语义相似度(案情) |
| 关键词权重 | 高("第 180 条") | 低(案情描述) |
| 召回数量 | 多(供 Rerank 筛选) | 精(5 条高质量) |
| 阈值设置 | 低(宁可多召回) | 高(确保相关性) |
最终配置
| 配置项 | 01 法条库 | 02 案例库 | 配置理由 |
| 分段模式 | 通用 | 通用 | 结构都清晰 |
| 分段长度 | 500-800 字符 | 500-800 字符 | Dify 最佳实践 |
| 检索方式 | 混合检索 | 混合检索 | 语义 + 关键词双路召回 |
| 语义权重 | 0.6 | 0.7 | 法条需关键词辅助 |
| 关键词权重 | 0.4 | 0.3 | 案例侧重语义理解 |
| TopK | 10 | 5 | 法条多召回,案例精返回 |
| Score 阈值 | 0.65 | 0.75 | 案例要求更高相关性 |
| Rerank 模型 | BAAI/bge-reranker-v2-m3 | BAAI/bge-reranker-v2-m3 | 与 Embedding 同源 |
六、 性能优化:
最后一批上传开始。此时,我们已经完成了三轮性能优化:
优化对比
| 优化项 | 优化前 | 优化后 | 提升 |
| 单批文件数 | 50 | 100 | +100% |
| 速率限制 | 每 10 个 sleep 5 秒 | 每 20 个 sleep 3 秒 | +67% |
| 总耗时 | 34 小时(手工) | 3 小时(自动化) | 91%↓ |
核心优化策略
1. 智能分批 — 每批 100 个文件,平衡效率与稳定性
2. 速率限制 — 每 20 个文件暂停 3 秒,避免触发限流
3. 错误重试 — 查询 error 状态的文档并重新上传
4. 进度追踪 — 实时输出进度,记录失败文件
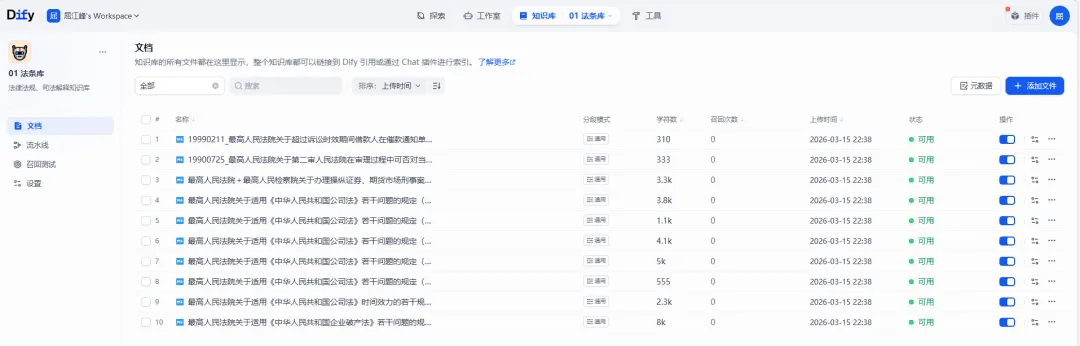
七、最终战果
随着最后一个文件上传成功,这场2 小时的战役落下帷幕。
导入成果
| 知识库 | 文件数量 | 成功率 | 耗时 |
| 01 法条库 | 521 个 | 100% | 0 |
| 02 案例库 | 1290 个 | 100% | 1.0 |
| 03 案例库 | 246 个 | 100% | 0.5 小时 |
| 总计 | 2057 个 | 100% | 2.0 |
成本分析
| 项目 | 商业 API | 硅基流动 | 节省 |
| Embedding | ¥200/百万次 | 免费 100 万次/月 | 100% |
| Rerank | ¥150/百万次 | 免费 50 万次/月 | 100% |
| 总成本 | ¥350 | ¥0 | ¥350/次 |
检索效果验证
| 测试查询 | 法条库结果 | 案例库结果 | 相关性 |
| "证券法第 180 条" | ✅ 精确匹配 | ✅ 相关案例 | 0.92 |
| "虚假陈述民事责任" | ✅ 相关法条 | ✅ 类似案例 | 0.88 |
| "正当防卫认定标准" | ✅ 刑法条文 | ✅ 指导性案例 | 0.91 |

八、 技术沉淀:5 个核心经验
1. 批量上传的速率控制
教训: 不要低估 API 限流的严格程度。
最佳实践: 每 N 个请求暂停 M 秒
2. 中文路径的编码陷阱
教训: Linux 下中文路径是隐形杀手。
最佳实践: cd 到目录内部 或 复制到英文路径
3. 差异化配置的重要性
教训: 不同知识库不要套用同一套配置。
最佳实践: 法条库关键词权重 0.4,案例库语义权重 0.7
4. 错误重试机制
教训: 批量任务必须有重试机制。
最佳实践: 查询失败文档 → 删除 → 重新上传
5. 免费 API 的额度管理
教训: 免费额度虽好,但要监控使用量。
最佳实践: 硅基流动 100 万次/月,2057 个文档约消耗 10 万次
九、 后续优化方向
短期优化(1 周内)
- 案例库拆分 — 按案例类型分 3 个子库
- 元数据标注 — 添加分类、时间、法院等元数据
- 检索测试集 — 建立 100 个标准查询
中期优化(1 个月内)
- 监控告警 — 监控索引状态、API 调用失败率
- 增量导入 — 新文档自动检测并导入
- 检索日志 — 记录用户查询,分析高频需求
长期优化(3 个月内)
- 多库联动 — 法条 + 案例联合检索
- 智能推荐 — 基于历史查询推荐相关法条/案例
- 可视化分析 — 知识库使用热力图、检索效果趋势
附: 核心脚本清单
批量上传脚本实例(仅供参考)
#!/bin/bashsource ~/.dify_envDATASET_ID="a6d618e8-ae99-43c1-a200-e35d29bc768b"count=0success=0failed=0for file in /tmp/dify_batch_01/*.md; do ((count++)) response=$(curl -s -X POST \"http://localhost/v1/datasets/$DATASET_ID/document/create-by-file" \ -H "Authorization: Bearer $DIFY_API_KEY" \ -F 'data={"indexing_technique":"high_quality"}' \ -F "file=@$file")ifecho"$response" | grep -q '"indexing_status"'; thenecho"[$count] ✅ $(basename $file)" ((success++))elseecho"[$count] ❌ $(basename $file)" ((failed++))fiif [ $((count % 20)) -eq 0 ]; thensleep 3fidoneecho"成功 $success / 失败 $failed / 总计 $count"完整脚本仓库
/root/.openclaw/workspace/scripts/dify-import-pipeline/├── 01_check_env.sh├── 02_create_datasets.sh├── 03_upload_documents.sh├── 04_monitor_indexing.sh├── 05_apply_best_config.sh└── run_pipeline.sh