 夜雨聆风
夜雨聆风
进度:4/12,这是让你的 AI 从"文字助手"升级为"视觉助手"的关键一步。
你的 AI 还是"瞎子"吗?
想象一下这些场景:
朋友发来一张风景照问你「这是哪里」,你只能回复「看不到图片,能描述一下吗?」 同事甩过来一张复杂图表让你分析,你只能让他把数据打出来 看到一张搞笑meme图,你想让 AI 解释笑点,它却说「我无法查看图片内容」
尴尬吧?
前几节课,我们给 OpenClaw 装上了大脑、嘴巴、耳朵。但它还缺一双眼睛——看懂图片的能力。
好消息是:给 OpenClaw 开启图片理解,比你想的简单得多。不需要安装额外软件,只需要确认你的模型支持「多模态」即可。
这节课完成后,你的 AI 将能:
👁️ 识别图片内容——「这张图里有几只猫?」 📊 分析图表数据——「这张柱状图显示了什么趋势?」 🖼️ 理解截图信息——「这个报错是什么意思?」 📝 提取文字信息——「这张图里的文字内容是什么?」
准备工作
✅ 已经配置好的 OpenClaw(前三课的内容) ✅ 一个支持多模态的模型 ✅ 一张测试图片 ✅ 大约 5 分钟时间
**不需要:**额外安装 skill、申请 API Key、复杂配置
第一步:确认你的模型支持图片理解
什么是多模态模型?
简单说:能同时处理文字和图片的模型。
在 OpenClaw 的模型配置中,通过 input 字段标识:
text—— 只支持文字image—— 支持图片text+image—— 多模态
**主流多模态模型:**GPT-4o、Gemini 系列、Kimi K2.5、Claude 3.5 等
检查当前配置
打开 openclaw.json,找到模型配置:
{
"input": ["text", "image"] // ← 看这里!
}
有 "image"→ ✅ 已支持,跳到第三步测试只有 "text"→ 📝 继续看第二步
第二步:给模型加上「识图」能力
修改现有模型配置
在 input 数组里添加 "image":
{
"input": [
"text",
"image" // ← 添加这一行!
]
}
或者换一个新的多模态模型
以 Gemini 为例:
{
"models": {
"providers": {
"google": {
"models": [
{
"id": "gemini-3.1-flash-preview",
"input": ["text", "image"]
}
]
}
}
}
}
第三步(进阶):为图片单独配置理解模型
隐藏技巧:如果你的主模型是纯文本的,可以为图片单独配一个多模态模型!
{
"agents": {
"defaults": {
"model": {
"primary": "newapi/cheap-text-model"
}
},
"imageModel": {
"primary": "newapi/kimi-k2.5",
"fallbacks": ["newapi/qwen3.5-plus"]
}
}
}
工作原理:
正常对话 → 用便宜的文本模型 发送图片 → 自动切换到多模态模型 无缝切换,省钱又好用
第四步:重启并测试
openclaw restart
测试方式一:直接发图片
在飞书里直接发一张图给 OpenClaw,看它能不能描述内容。
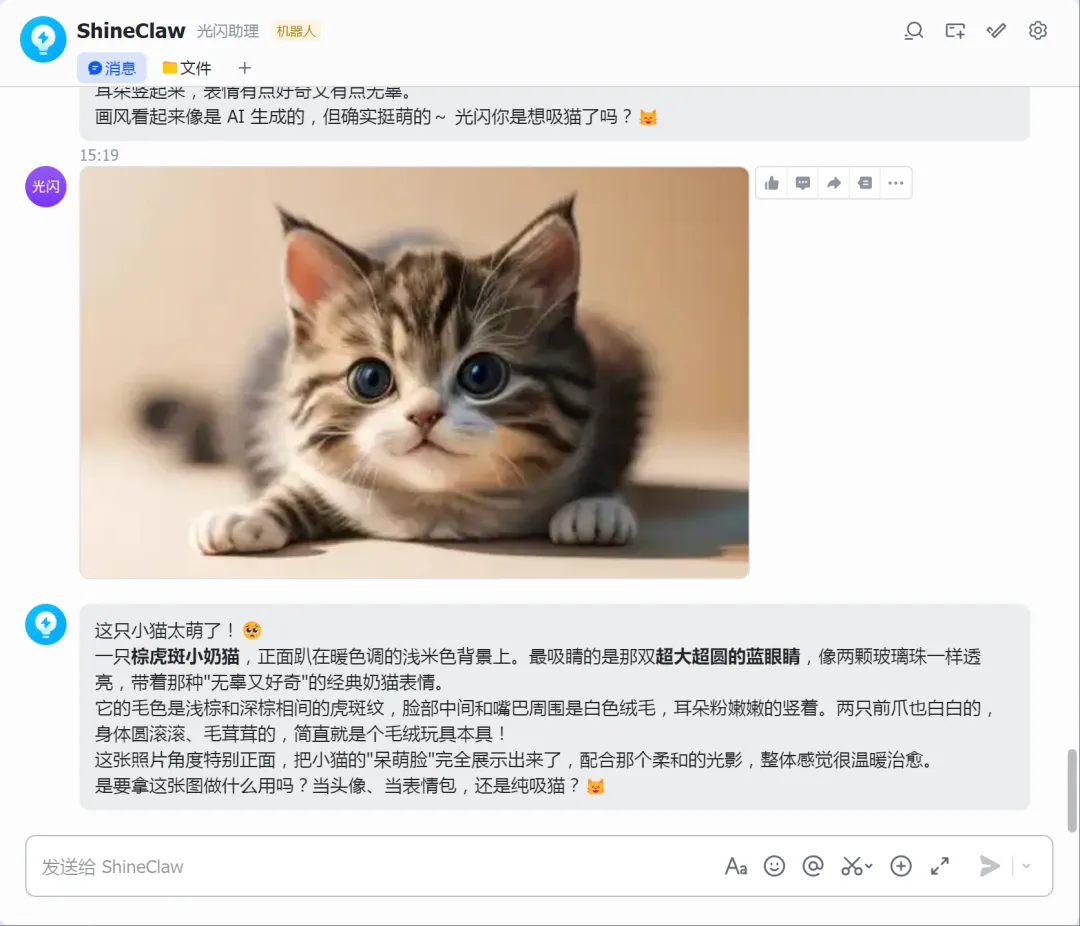
测试方式二:图片+文字提问
发一张图表 + 「这张图显示了什么趋势?」
测试方式三:OCR识别
发一张手写笔记,让它提取文字。
常见问题
Q: 为什么我的 AI 说「无法查看图片」?
检查模型配置里的 input 是否包含 "image",以及 OpenClaw 是否重启。
Q: 图片理解怎么收费?
按 token 计费,一般截图 1000-2000 tokens,高清照片 2000-4000 tokens。
Q: 支持哪些格式?
PNG、JPG、WEBP、GIF(静态),单张不超过 20MB。
进阶技巧
图片+搜索组合拳:识别植物图片 → 搜索养护方法 截图分析报错:直接发 IDE 报错截图,AI 帮你解决 图表数据提取:把 Excel 图表截图发给 AI,输出 Markdown 表格
总结
🎉 你的 OpenClaw 终于「睁眼看世界」了!
回顾 4 节课的成果:
| 课程 | 能力 |
|---|---|
| 第1课 | 大脑(模型配置)✅ |
| 第2课 | 嘴巴(飞书接入)✅ |
| 第3课 | 耳朵(实时搜索)✅ |
| 第4课 | 眼睛(图片理解)✅ |
下节预告: 第5课《不只看得懂,还能画得出——文生图配置指南》,让 AI 从「看图说话」升级到「无中生有」!
进度:4/12 已完成 ✅
