 夜雨聆风
夜雨聆风一、背景
1. 核心问题:Agent交互信号浪费现象
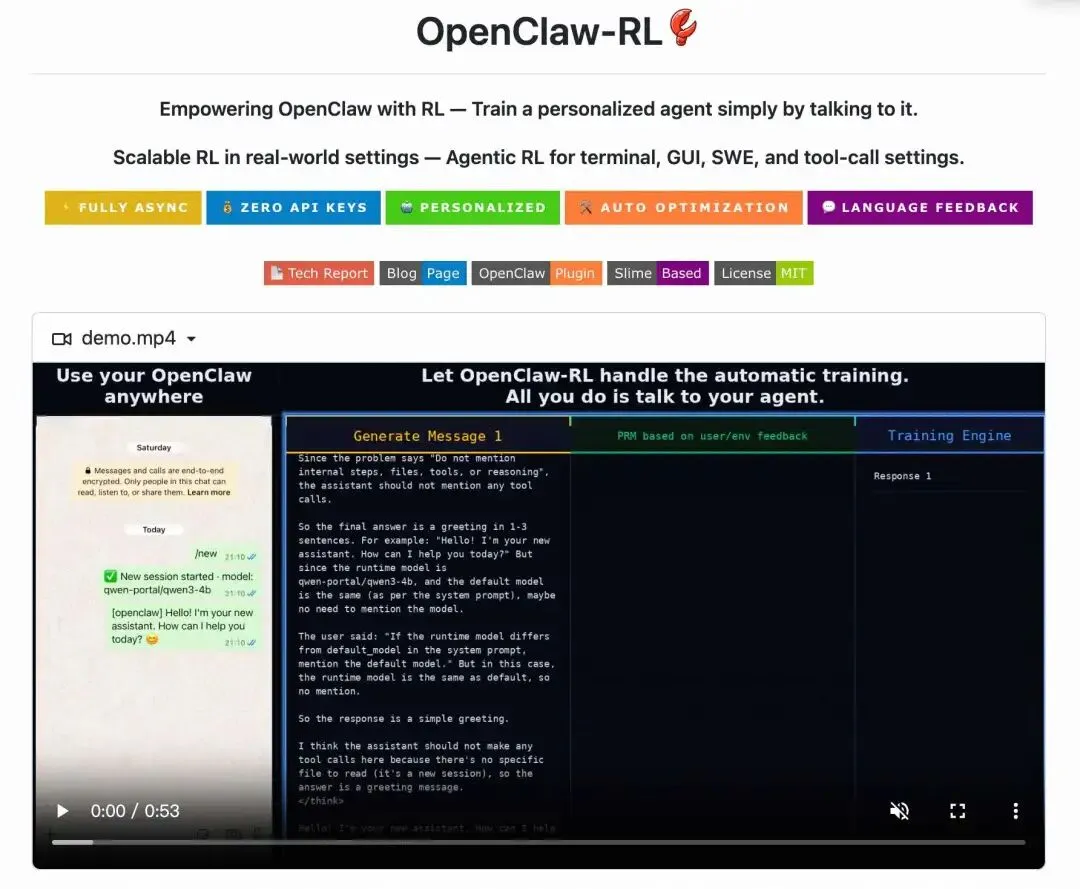
现有智能体(Agent)在每次动作(如回复用户、执行工具指令)后,都会收到下一个状态信号(Next-State Signal)——可能是用户回复、工具输出、GUI界面变化或测试结果。
但传统系统仅将其作为后续动作的上下文,完全忽略了其中的两大核心价值:
评估信号(Evaluative Signals):隐含动作质量评分(如用户重复提问=不满意、测试通过=成功),可构成天然的过程奖励,无需额外标注; 指令信号(Directive Signals):包含动作优化方向(如用户 指出"应先检查文件"、SWE任务的错误日志),能指导具体改进。
这两类信号在个人对话、终端操作、GUI交互、软件工程(SWE)、工具调用等所有场景中普遍存在,却未被现有强化学习(RL)系统作为实时在线学习源利用。
2. 核心贡献
提出OpenClaw-RL,核心洞察是:所有场景的下一个状态信号具有通用性,可通过同一框架训练同一策略(Policy)。其突破点在于:
首次实现个人智能体与通用智能体的训练统一; 异步架构支持"边服务边学习",无服务中断; 标量奖励+token级监督
二、核心架构
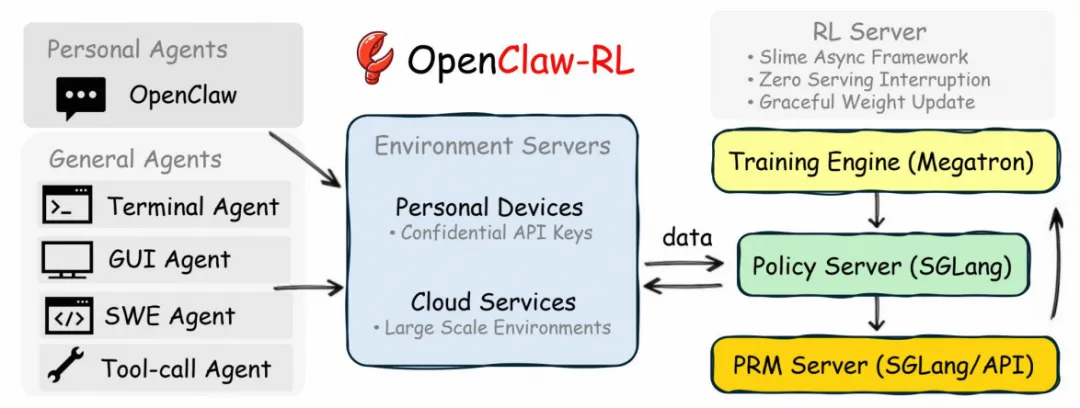
OpenClaw-RL的架构核心:四大解耦组件的异步流水线,确保训练、服务、评估并行无阻塞,支持从个人设备到大规模云环境的全场景部署。
1. 四大核心组件
模型在 PRM 评判上一轮响应、训练器施加梯度更新的同时,继续服务下一个用户请求;三者互不等待

| 环境服务器(Environment Server) | ||
| PRM判断服务器 | ||
| 会话感知多轮跟踪 |
2. 关键特性
会话感知(Session-Aware):区分主交互轮(训练样本)和辅助轮(如内存整理,不参与训练),精准定位训练数据; 无阻塞日志(Non-Blocking Log):实时记录所有交互、奖励、提示信息,日志与策略版本严格对齐; 可扩展性:从单用户 个人智能体(稀疏交互)到千级并行环境的通用智能体(密集信号)无缝切换。
三、核心方法:Binary RL + Hindsight-Guided OPD
前置知识
OpenClaw-RL 作用于策略 同时接收多个交互流,将其与推理pipeline解耦,因此足够灵活以适用于广泛的智能体设置,包括个人智能体对话、终端执行、GUI 交互、SWE 任务和工具调用轨迹。
将每个交互流形式化为 MDP :
状态:截至第 轮的完整对话或环境上下文。 动作:智能体的响应,由 生成的 token 序列。 转移:给定环境时为确定性的; 是跟随 的用户回复、执行结果或工具输出。 奖励:通过 PRM 评判器 从下一状态信号推断得出。
在标准 RLVR 中,结果 作为整个轨迹的奖励。然而,过程奖励 依赖于下一状态 ,包含更丰富的信号。
OpenClaw-RL通过两种方法,分别提取评估信号和指令信号的价值,最终通过加权损失融合
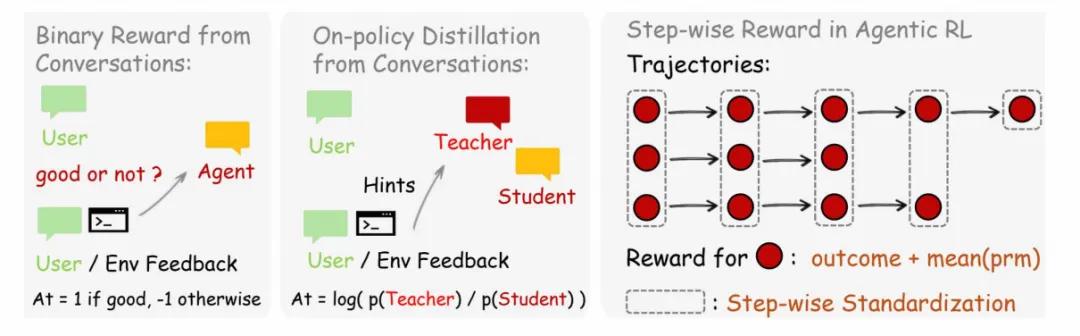

1. 方法一:Binary RL——评估信号→标量过程奖励
针对评估信号,通过过程奖励模型(PRM)将下一个状态信号转化为标量奖励,用于全局策略优化。
PRM判断逻辑:输入智能体动作和下一个状态,输出(好),(差),(中性),通过次独立投票的多数表决确定最终奖励; 训练目标:采用PPO剪枝代理目标(带非对称边界),优势函数,公式如下:其中,,确保更新稳定;
优势:覆盖所有评分交互,适配隐含反馈(如用户重问)和结构化输出(如终端退出码),实现广覆盖粗粒度优化。
2. 方法二:Hindsight-Guided OPD——指令信号→token级监督
针对指令信号,通过事后引导的在线蒸馏(OPD) 提取token级(Token-Level)优化方向,实现细粒度改进。
四步流程
事后提示提取:Judge模型从中蒸馏出简洁可操作的提示(1-3句),过滤噪声和无关信息; 提示筛选:仅保留长度>10字符的有效提示(优先选择最长提示),保证信号质量; 增强教师构建:将提示附加到原始输入,生成增强提示,模拟"用户提前给出修正"的场景; 令牌级优势计算:对比增强提示下教师模型(同一策略)与原始学生模型的token概率分布,优势函数为: :需增强该token权重; :需降低该token权重。
突破标量奖励的局限,实现单响应内的局部优化(如强化自然表达 防止AI味道太重)。
3. 双方法融合
通过加权损失将两者优势结合,总优势函数为:
默认,既保证全局覆盖(Binary RL),又实现精准优化(OPD)。
4. 通用智能体的过程奖励整合
针对长周期任务(如GUI操作、SWE调试),将结果奖励(Outcome Reward) 与过程奖励(Process Reward) 融合:
为任务最终结果,为各步骤PRM奖励,解决长周期任务的梯度稀疏问题。
四、实验
论文在两类智能体上验证效果,核心指标为个性化得分(个人端)和任务准确率(通用端)。
1. 个人智能体:对话信号驱动个性化
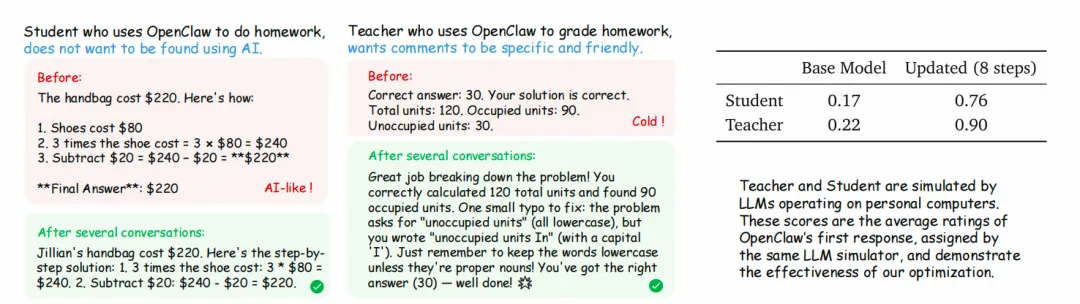
实验设置
场景1:学生使用智能体完成作业(需求:避免AI味太重,自然表达); 场景2:教师使用智能体批改作业(需求:评论具体友好); 基础模型:Qwen3-4B,训练触发条件:每16个样本更新一次。

关键结果
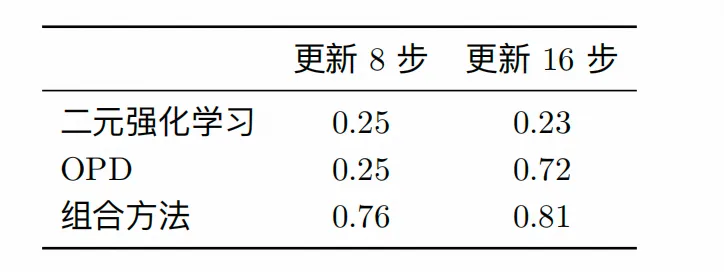
融合方法最优:8步更新后,学生场景得分从0.17提升至0.76,教师场景从0.22提升至0.90(表3); OPD延迟见效但效果显著:16步时OPD单独优化得分达0.72,远超Binary RL的0.23;




2. 通用智能体
实验设置
关键结果
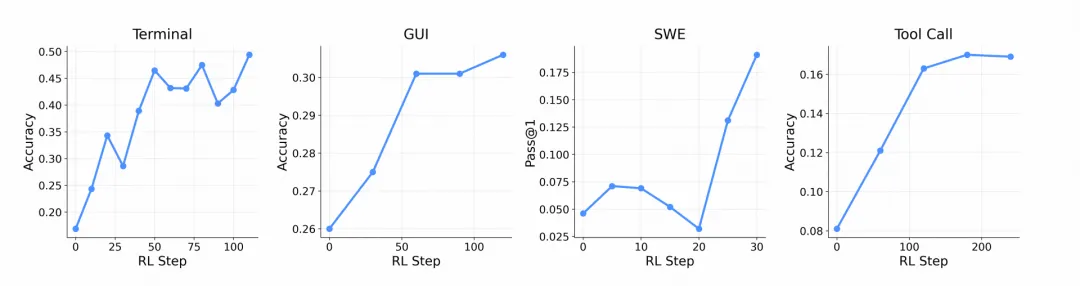
跨场景适配性:同一架构支持所有场景,任务准确率随RL步数稳步提升
步骤级过程奖励是否必要?

在工具调用(250 步)和 GUI(120 步)设置下使用集成奖励进行强化学习训练,发现结合结果奖励和步骤级过程奖励能进一步提升性能
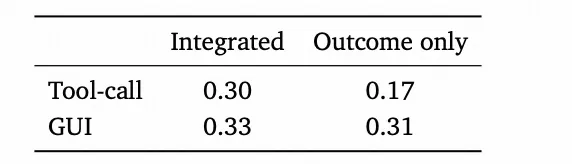
步骤级过程奖励必要性:融合结果+步骤级过程奖励的效果显著优于仅用结果奖励,步骤级过程奖励PRM非常关键
六、写在最后
OpenClaw-RL的核心价值通过异步解耦架构和双信号提取方法,让智能体在真实交互中实时学习,实现Aegnt越用越聪明,越来越懂你的偏好,将Agent的每一次交互都转化为学习机会
感谢论文翻译支持:https://fanyi.qc-ai.cn/
既然看到这里了,如果觉得不错,随手点个赞、在看、转发三连吧,如果想第一时间收到推送,也可以给我个星标⭐~谢谢你看我的文章,下次再见
参考
https://arxiv.org/pdf/2603.10165
