夜雨聆风
夜雨聆风以下将详细解析 MPI(Message Passing Interface)的软件架构和工作流程,该部分是高性能计算领域的核心标准。
一、MPI 软件架构
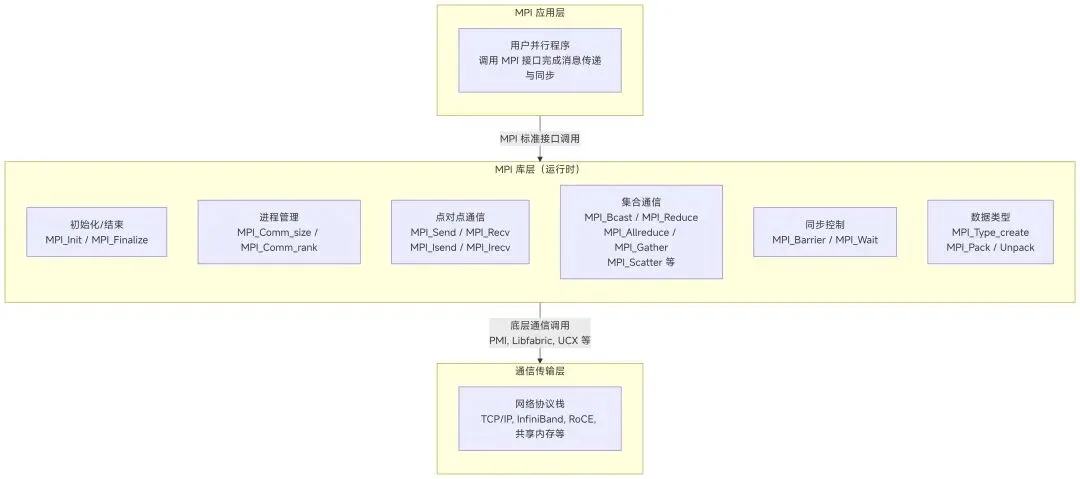
- 1. 分层架构模型
┌─────────────────────────────────────────────────────────┐
│ 用户应用程序层 │
│ (并行算法实现,调用MPI接口) │
├─────────────────────────────────────────────────────────┤
│ MPI标准接口层 │
│ (MPI_Send, MPI_Recv, MPI_Bcast, MPI_Reduce等200+函数) │
├─────────────────────────────────────────────────────────┤
│ MPI实现层(具体实现) │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────┐ │
│ │ OpenMPI │ │ MPICH │ │ Intel MPI │ │
│ │ (开源) │ │ (开源) │ │ (商业) │ │
│ └─────────────┘ └─────────────┘ └─────────────────┘ │
├─────────────────────────────────────────────────────────┤
│ 底层通信支撑层 │
│ ┌─────────────┐ ┌─────────────┐ ┌─────────────────┐ │
│ │ TCP/IP │ │ InfiniBand │ │ Shared Memory │ │
│ │ (以太网) │ │ (RDMA) │ │ (共享内存) │ │
│ └─────────────┘ └─────────────┘ └─────────────────┘ │
├─────────────────────────────────────────────────────────┤
│ 操作系统/硬件层 │
│ (进程管理、内存管理、网络设备驱动) │
└─────────────────────────────────────────────────────────┘- 2. 核心组件架构(以 OpenMPI 为例)
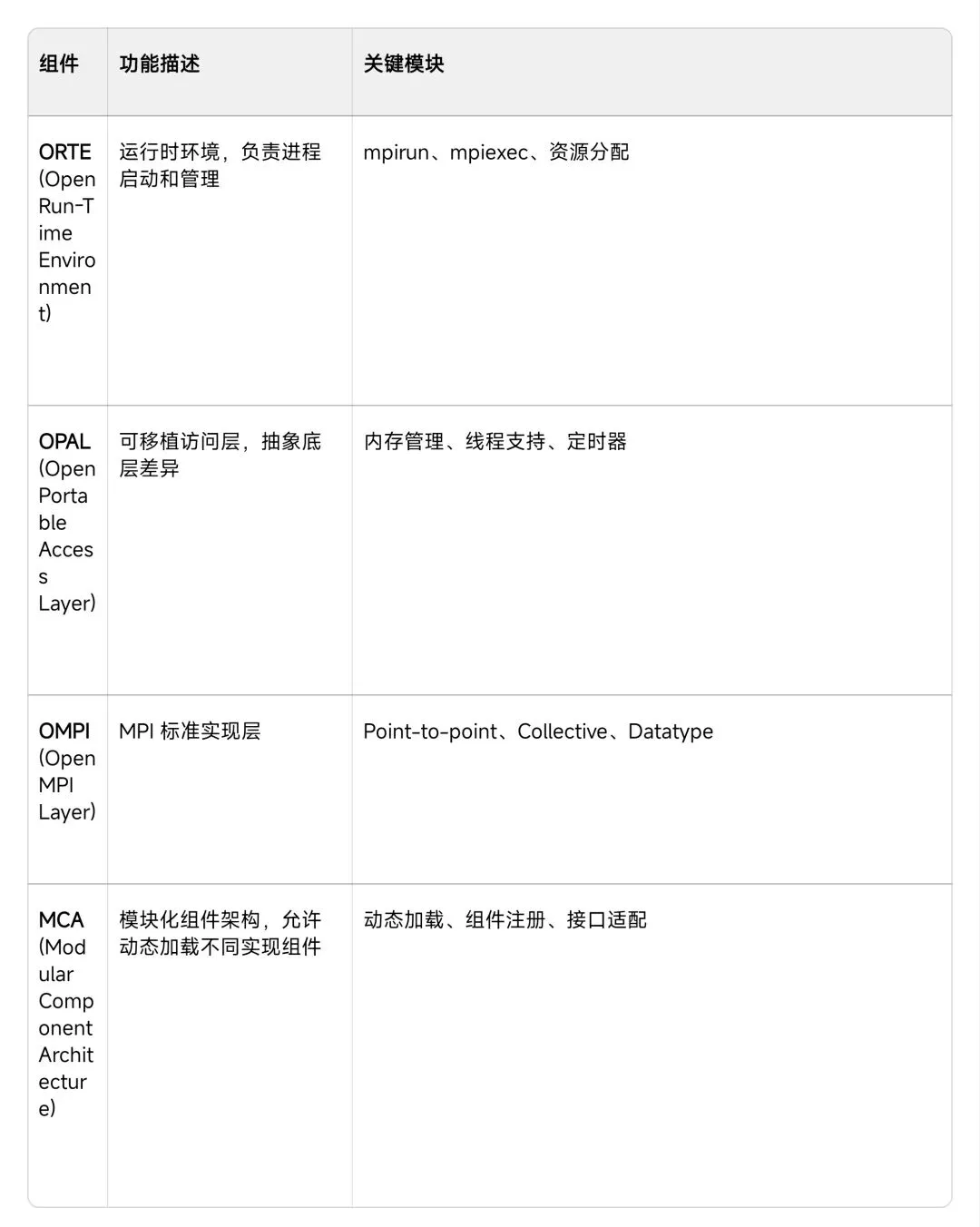
OpenMPI 采用模块化设计,主要包含:
二、MPI 详细工作流程
阶段 1:环境初始化与进程启动
// 典型MPI程序结构
#include <mpi.h>
int main(int argc, char** argv) {
int rank, size;
// 1. 初始化MPI环境
MPI_Init(&argc, &argv);
// 2. 获取进程标识
MPI_Comm_rank(MPI_COMM_WORLD, &rank); // 当前进程ID (0 ~ size-1)
MPI_Comm_size(MPI_COMM_WORLD, &size); // 总进程数
// ... 并行计算逻辑 ...
// 3. 结束MPI环境
MPI_Finalize();
return 0;
}详细启动流程:
- 1. 用户执行启动命令
mpirun -np 4 ./my_program- 2. ORTE 守护进程协调
- •
mpirun解析命令行参数(进程数、主机列表等) - • 通过 SSH/RSH/Slurm 等启动远程节点上的
orted守护进程 - • 建立通信拓扑结构
- 3. MPI 进程创建
- • 每个节点上的
orted创建指定数量的 MPI 进程 - • 进程间建立初始通信通道(通常是 TCP 或共享内存)
- 4. 全局通信域建立
- • 所有进程加入
MPI_COMM_WORLD通信域 - • 分配唯一的 rank 编号(0 到 N-1)

阶段 2:点对点通信流程(以 MPI_Send/MPI_Recv 为例)
发送方 (Rank 0) 接收方 (Rank 1)
┌─────────────────┐ ┌─────────────────┐
│ MPI_Send(buf, │ │ MPI_Recv(buf, │
│ count, dtype, │ │ count, dtype, │
│ dest=1, tag, │ │ src=0, tag, │
│ comm) │ │ comm, status) │
└────────┬────────┘ └────────┬────────┘
│ │
▼ ▼
┌─────────────────┐ ┌─────────────────┐
│ 1. 数据打包 │ │ 1. 检查匹配条件 │
│ (根据datatype)│ │ (src, tag, comm)│
├─────────────────┤ ├─────────────────┤
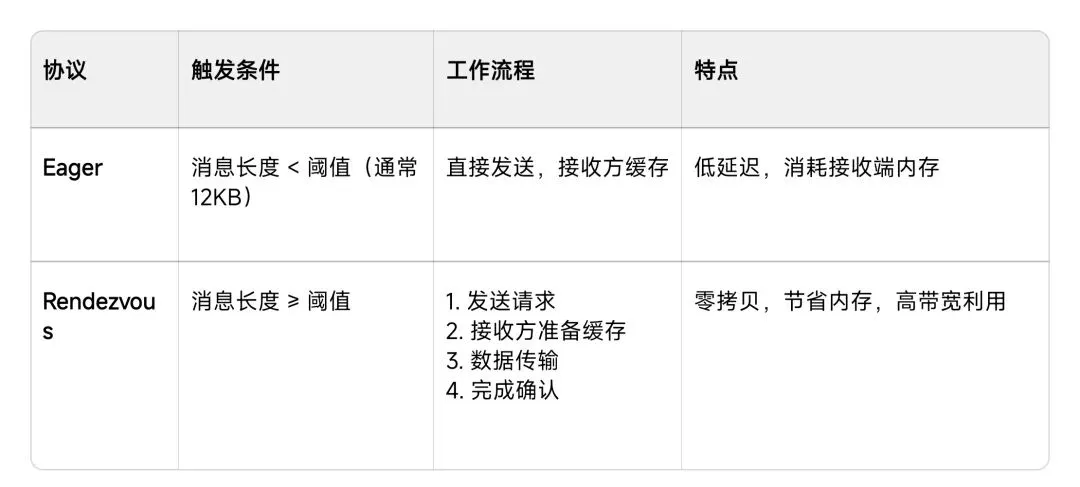
│ 2. 选择通信协议 │ │ 2. 等待匹配消息 │
│ - Eager (小消息<12KB)│ │ (阻塞/非阻塞) │
│ - Rendezvous (大消息)│ ├─────────────────┤
├─────────────────┤ │ 3. 接收数据包 │
│ 3. 网络传输 │◄──────────────────►│ (解包到buf) │
│ (TCP/IB/SHM) │ ├─────────────────┤
├─────────────────┤ │ 4. 返回status │
│ 4. 完成确认 │ │ (count, tag等)│
│ (同步/异步) │ └─────────────────┘
└─────────────────┘通信协议选择:
阶段 3:集合通信流程(以 MPI_Bcast 为例)
根进程 (Rank 0) 其他进程 (Rank 1-3)
┌─────────────────┐ ┌─────────────────┐
│ MPI_Bcast(buf, │ │ MPI_Bcast(buf, │
│ count, dtype, │ │ count, dtype, │
│ root=0, comm) │ │ root=0, comm) │
└────────┬────────┘ └────────┬────────┘
│ │
│ ┌─────────────┐ │
├────────►│ 广播算法 │◄────────┤
│ │ (树形/链式) │ │
│ └──────┬──────┘ │
│ │ │
┌────┴────┐ ┌────┴────┐ ┌───┴────┐
▼ ▼ ▼ ▼ ▼ ▼
Rank0 ──► Rank1 ──► Rank2 ──► Rank3
(根) (接收) (接收) (接收)
│ │
▼ ▼
┌─────────┐ ┌─────────┐
│ 数据分发 │ │ 数据接收 │
│ (发送给1)│ │ (来自父节点)│
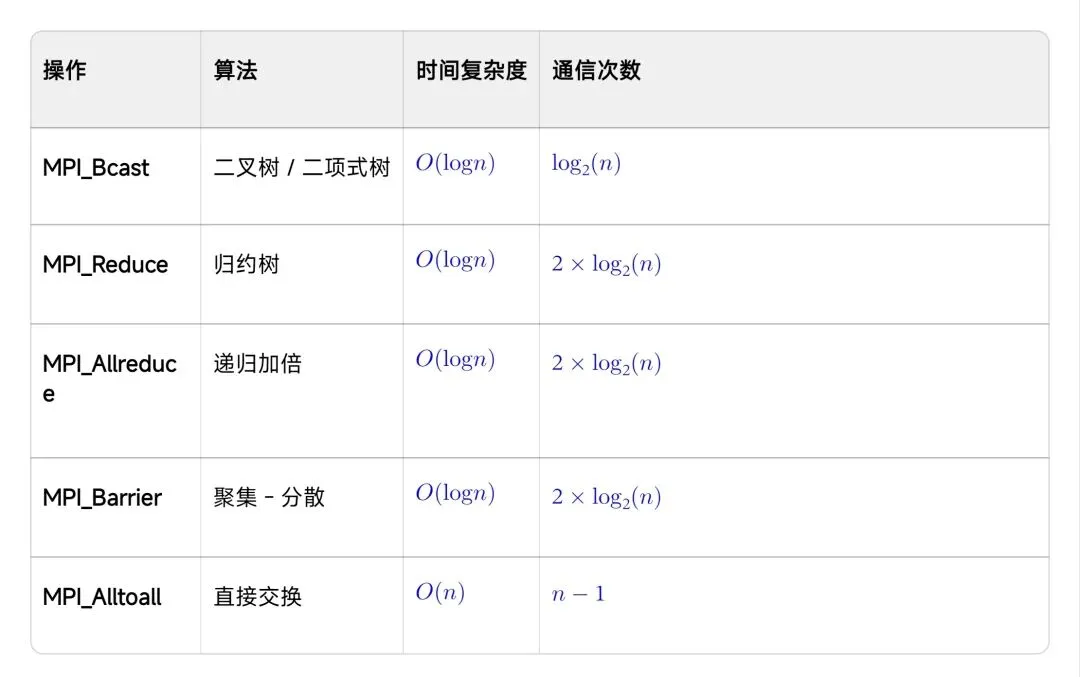
└─────────┘ └─────────┘常用集合通信算法复杂度:
阶段 4:数据类型处理流程
MPI 支持复杂数据类型的打包/解包:
// 定义结构体数据类型
typedef struct {
int id;
double coords[3];
char name[20];
} Particle;
// 创建MPI数据类型
MPI_Datatype particle_type;
int blocklengths[3] = {1, 3, 20};
MPI_Aint displacements[3];
MPI_Datatype types[3] = {MPI_INT, MPI_DOUBLE, MPI_CHAR};
// 计算偏移量
displacements[0] = offsetof(Particle, id);
displacements[1] = offsetof(Particle, coords);
displacements[2] = offsetof(Particle, name);
MPI_Type_create_struct(3, blocklengths, displacements, types, &particle_type);
MPI_Type_commit(&particle_type);
// 使用新类型通信
MPI_Send(&particle, 1, particle_type, dest, tag, comm);数据转换流程:
- 1. 类型映射:将 C 结构体映射为 MPI 类型描述
- 2. 数据打包:根据类型描述将非连续数据收集到连续缓冲区
- 3. 字节序转换:异构系统间进行 Endian 转换
- 4. 网络传输:通过底层网络发送
- 5. 数据解包:接收方按类型描述将数据还原到目标地址
阶段 5:通信与计算重叠(非阻塞通信)
MPI_Request req;
MPI_Status status;
// 非阻塞发送:立即返回,通信在后台进行
MPI_Isend(send_buf, count, MPI_INT, dest, tag, comm, &req);
// 重叠:在等待通信完成时执行计算
do_computation();
// 等待通信完成
MPI_Wait(&req, &status);工作流程:
时间轴 ─────────────────────────────────────────►
┌────────────────────────────────────────────────┐
│ MPI_Isend() │ 计算阶段 │ MPI_Wait() │
│ (立即返回) │ (重叠执行) │ (确保完成) │
└────────────────────────────────────────────────┘
│ │
▼ ▼
后台通信进程/线程 同步点,可能阻塞三、关键内部机制
- 1. 通信上下文管理
- • 通信域 (Communicator):定义进程组及通信上下文
- •
MPI_COMM_WORLD:包含所有进程的默认通信域 - • 支持通过
MPI_Comm_split创建子通信域 - • 标签 (Tag):用于消息匹配,区分不同逻辑流
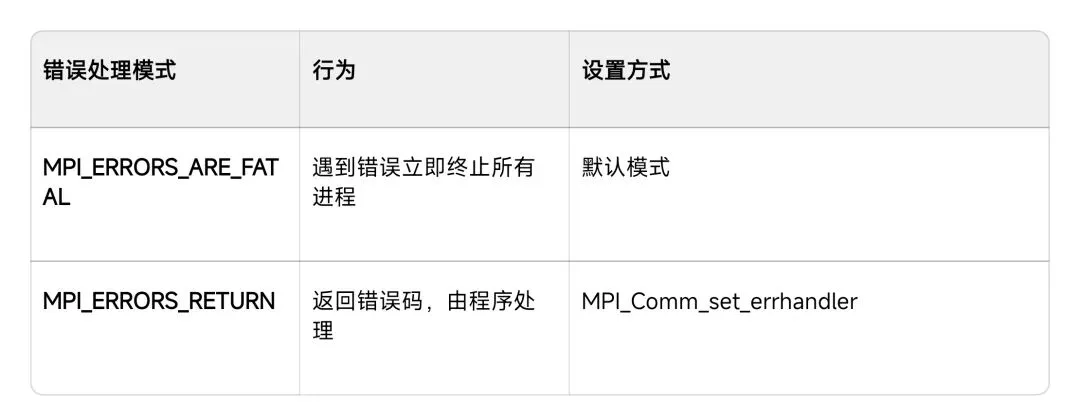
- 2. 错误处理与容错
- 3. 性能优化机制
- • 消息截断 (Message Segmentation):大消息分块传输
- • 流水线 (Pipelining):多消息并发传输
- • 零拷贝 (Zero-Copy):RDMA 技术避免内存复制
- • 共享内存优化:节点内进程通过共享内存通信
四、总结
MPI 通过分层架构实现了高可移植性和高性能:
- 1. 标准化接口确保程序可在不同平台编译运行
- 2. 模块化实现允许针对特定网络优化
- 3. 多种通信模式(点对点/集合/非阻塞)适应不同算法需求
- 4. 丰富的数据类型支持复杂科学计算数据结构
理解这些架构和流程,有助于编写高效、可扩展的并行程序,并优化大规模集群上的应用性能。