 夜雨聆风
夜雨聆风当所有人都在讨论哪个 AI 模型更聪明的时候,真正懂行的人已经把目光转向了另一个战场——Agent Harness。
如果你还在纠结 GPT-4 和 Claude 谁更强,那你可能错过了 AI Agent 革命中最关键的一环。
什么是 Agent Harness?模型只是大脑,Harness 才是身体
想象一下,你有一个天才的大脑,但没有手、没有眼睛、没有记忆系统,也没有行动的能力。这就是没有 Harness 的 AI 模型的真实写照。
Agent Harness 是包裹在大语言模型(LLM)外围的完整基础设施,它负责管理除了模型推理之外的所有事情。模型提供智能,而 Harness 提供手、眼睛、记忆和安全边界。
简单来说,Harness 就是让 AI 从"聊天机器人"变成"自主操作员"的那套系统。
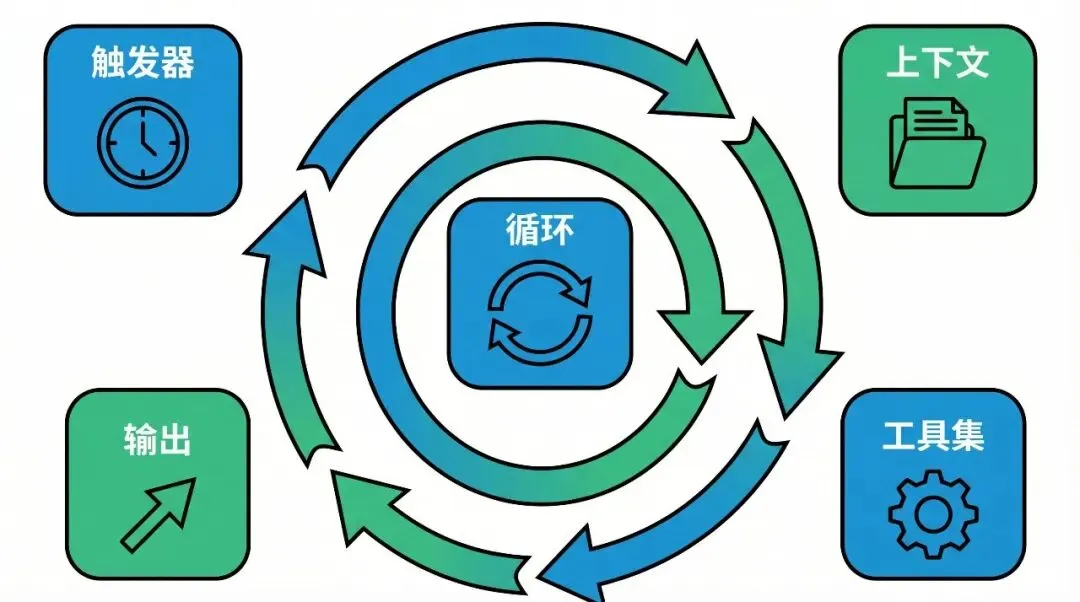
一个完整的 Agent Harness 包含的核心组件
• 触发器(Triggers):什么时候 AI 应该开始工作?是收到消息时、定时任务、还是系统事件触发? • 上下文管理(Context):AI 需要知道什么?如何管理对话历史、项目文档、用户偏好? • 工具集(Tools):AI 能做什么?文件操作、代码执行、API 调用、浏览器控制? • 输出处理(Outputs):AI 的结果如何呈现?是发送消息、修改文件、还是触发其他系统? • 循环机制(Loop):如何让这一切持续运行,形成真正的自主代理?
把这些组件串联起来形成一个循环,你就得到了一个 Agent Harness 的基本架构。这就是 OpenClaw 背后的真正秘密——不是某个神秘的黑科技功能,而是将触发器、上下文、工具和输出以一种足够持久的方式整合在一起,让它感觉像是自主的。
OpenClaw 现象:为什么它引爆了整个社区?
OpenClaw 最近成为了 AI 社区的焦点,不仅因为它的功能强大,更因为它让"Agent Harness"这个概念变得具象化。它展示了一个关键洞察:Agent 不只是一个模型,而是模型加上记忆、指令、触发器、工具、输出和循环机制的组合。
OpenClaw 的设计理念是广泛而通用的——它可以在一个框架内完成许多不同的任务。你可以让它通过 Telegram 自动修复测试、管理代码仓库、处理多步骤的研究任务,甚至进行长时间的自主工作循环。这种"个人 AI 助手"的体验让很多用户感受到了类似当年第一次使用 ChatGPT 时的震撼。
但 OpenClaw 的故事也揭示了一个更深层的行业矛盾:它是一个开源框架,却高度依赖 Anthropic 的 Claude 模型。当 Anthropic 宣布将限制第三方 Harness 的访问权限时,整个社区都感受到了震动。更戏剧性的是,OpenClaw 的创始人 Steinberger 随后加入了 OpenAI,这让未来的发展方向变得更加扑朔迷离。
Harness 工程:AI 时代的新兴学科
随着 OpenClaw 事件的发酵,一个新的技术领域正在快速成型——Harness Engineering(Harness 工程)。这是一门位于上下文工程、评估、可观测性、编排、安全自主性和软件架构交叉点上的实践学科。
Harness 工程的核心不是简单地调整提示词或为某个模型微调编排层,而是设计运行时环境、限定上下文窗口、强制执行架构约束、标准化反馈循环,让 AI 能够安全地朝着目标迭代。
目前业界已经出现的多个重要 Harness 项目和框架
• OpenHarness:一个开源的 Python 实现,专为研究人员、开发者和社区设计,帮助人们理解生产级 AI Agent 在底层是如何工作的。它支持包括 OpenClaw、nanobot、Cursor 等多个 CLI Agent 的集成,并且兼容 Claude Code 插件。 • AlphaClaw:OpenClaw 的终极部署 Harness,提供便捷的设置向导、自我修复的监控系统、基于 Git 的回滚功能,以及完整的基于浏览器的可观测性。它还内置了反漂移提示加固机制,确保 Agent 保持纪律性。 • Tinman-OpenClaw-Eval:专门针对 OpenClaw Agent 的安全评估 Harness,包含 280 多个攻击载荷,覆盖提示注入、工具渗透、上下文泄露、权限提升、供应链攻击等多个维度,可直接集成到 CI 流程中。
社区还建立了专门的资源库"Awesome Harness Engineering",汇集了大量关于 Harness 工程的文章、手册、基准测试、规范和开源项目。这个领域正在快速标准化和成熟化。
评估基准:如何衡量 Harness 的质量?
随着 Harness 工程的发展,一系列专门的评估基准也应运而生,用于测试 Harness 在不同场景下的表现:
• WildClawBench:在真实的 OpenClaw 环境中运行 Agent,包含 60 个原创任务,涵盖多模态、长时程和安全关键场景,直接测试 Harness 在真实条件下的鲁棒性。 • ClawBench:评估 AI Agent 在搜索、推理、编码、安全和多轮对话任务中的表现,在单一测试套件中覆盖 Harness 需求的广度。 • ClawWork:一个真实世界的经济基准测试,AI Agent 需要完成跨越 44 个职业的专业任务,在赚取收入的同时管理 Token 成本和经济偿付能力,直接测试资源约束下的 Harness 效率。 • AgentBench:跨环境基准测试,涵盖操作系统、数据库、知识图谱、网页浏览等多个领域,用于检验 Harness 是否能超越单一任务循环实现泛化。 • WebArena-Verified:一个经过验证的 Web Agent 基准测试,包含精心策划的任务和针对 Agent 响应及捕获的网络追踪的确定性评估器,非常适合衡量面向 Web 的 Harness 质量。
这些基准测试的出现标志着 Harness 工程正在从"黑盒艺术"转变为"可测量的工程学科"。
OpenClaw 危机揭示的深层问题:我们需要自优化 Harness
OpenClaw 与 Anthropic 的冲突暴露了当前 Agent Harness 面临的核心挑战:大多数 Harness 都是为特定模型手工优化的,缺乏自适应能力。
当模型提供商改变 API、调整能力边界或限制访问时,依赖单一模型的 Harness 就会陷入困境。OpenClaw 目前高度依赖 Claude 的工具调用能力和长时程推理表现,而开源模型在这些方面仍有明显差距。
解决方案不是简单地修补提示词或为某个模型调整编排层,而是构建真正的 自优化 Harness——能够自动检测模型能力并调整其提示、上下文处理、工具路由和评估逻辑,无需人工干预。
未来的 Harness 应该具备的特征
• 模型无关性:能够无缝切换不同的模型提供商,自动适配各自的能力特征。 • 角色分离:将生成器和评估器角色分开,避免单一模型既当裁判又当运动员。 • 智能上下文管理:不是盲目压缩上下文,而是智能地管理和检索相关信息。 • 自我诊断能力:能够读取自己的执行日志,调试复杂的逻辑失败,并自我改进。
Meta-Harness(元 Harness) 的研究正是朝这个方向发展——一个领导 AI Agent 读取自己的执行日志、调试复杂逻辑失败并自我优化的框架。这代表了 Harness 工程的下一个演进阶段。
企业视角:通用 Harness vs. 专用 Harness
对于企业应用来说,OpenClaw 引发的讨论特别具有现实意义。一个关键问题是:你真的需要一个像 OpenClaw 这样的通用、广泛的 Harness 吗?
在许多企业场景中,答案是否定的。一个邮件分类 Agent、合同审查 Agent、政策助手或支持路由 Agent 通常不需要一个庞大的通用 Harness。它需要的是清晰的提示、受约束的工具集、最小化的记忆和严格定义的操作边界。这往往是优秀演示和生产级系统之间的区别。
对于金融、医疗、政府、国防和关键基础设施等领域的企业 AI,问题不是自主 Agent 是否有趣,而是:
• 它们是否可审计? • 它们是否可以在私有基础设施上运行? • 它们是否符合监管要求? • 它们的故障模式是否可预测和可控?
这就是为什么在评估 Harness 时,企业必须权衡高度自主系统(如 OpenClaw)的生产力收益与严格沙盒化防护栏(如 Codex)的必要性。
关键洞察:Harness 本身就是产品
OpenClaw 事件给整个行业带来的最重要启示是:Harness 本身就是产品。这个洞察超越了任何单一框架。
开发者不应该将自己的工作流永久绑定到 OpenClaw、Hermes、LangChain 或任何其他单一工具上。真正有价值的是理解 Harness 的核心组件——触发器、上下文、工具、输出、循环——以及如何根据具体需求组合它们。
当前关于"哪个 AI 模型更聪明"的辩论是错误的辩论。真正的竞争发生在 Harness 层面:谁能构建更好的触发机制?谁能更智能地管理上下文?谁能提供更安全、更可靠的工具集成?谁能让循环更稳定、更可观测?
我们正在见证"Harness 形态"的形成。就像操作系统、数据库、Web 框架这些基础设施层最终标准化一样,Agent Harness 也将经历从百花齐放到模式收敛的过程。
未来展望:Harness 工程的下一步
OpenClaw 的未来有两条可能的路径:
• 路径一:深度整合 OpenAI 生态。Steinberger 加入 OpenAI 可能会加速这一进程,但这需要重写大量 TypeScript Harness 代码。 • 路径二:全面支持本地和开源模型。这条路需要解决当前工具调用可靠性和推理深度方面的差距。
无论哪条路径,执行窗口都很窄。竞争性的 Agent 框架每周都在发布新能力。
从更广阔的视角看,Harness 工程正在成为 AI 系统开发的核心学科。未来的 AI 工程师不仅需要懂模型调优,更需要懂如何设计、评估和优化 Harness。这包括:
• 如何设计安全的工具边界 • 如何实现高效的上下文管理 • 如何构建可观测和可调试的 Agent 系统 • 如何在自主性和可控性之间找到平衡 • 如何让 Harness 自适应不同的模型能力
OpenClaw 的故事还远未结束,但它已经为整个行业上了宝贵的一课:在 AI Agent 时代,真正的护城河不在模型,而在 Harness。那些能够构建灵活、安全、高效 Harness 的团队,将在下一轮 AI 应用竞争中占据优势。
相关链接
🔗 OpenClaw 官网:https://openclaw.ai/🔗 OpenClaw 测试文档:https://docs.openclaw.ai/help/testing🔗 OpenHarness GitHub 仓库:https://github.com/HKUDS/OpenHarness🔗 AlphaClaw GitHub 仓库:https://github.com/chrysb/alphaclaw🔗 Tinman-OpenClaw-Eval 安全评估工具:https://github.com/oliveskin/tinman-openclaw-eval🔗 Awesome Harness Engineering 资源库:https://github.com/walkinglabs/awesome-harness-engineering
欢迎关注
如果你喜欢这种「AI 行业深度分析」的内容,欢迎关注短裤哥:持续分享 AI 行业动态、技术分析与工具玩法。

