 夜雨聆风
夜雨聆风引子:6 个 AI 协作的场景切入
下午 3 点,我在 手机的聊天APP里@首席运营:"把这个选题做成文章"。10 分钟后,一篇 2800 字的草稿已经躺在编辑的工作台等我审核。审核完成,再过15分钟,一篇图文并茂的文章就躺在公众号后台的草稿箱等我最后发布。
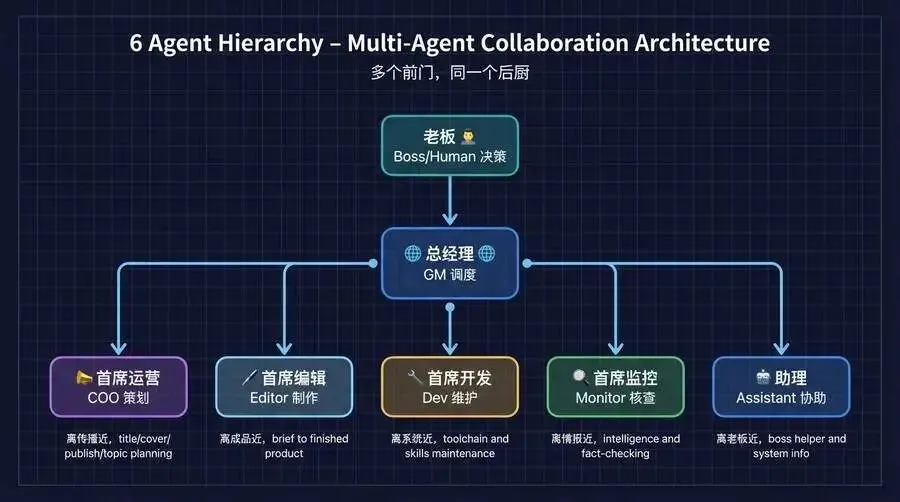
这背后是 6 个 AI 在协作:总经理调度拍板,编辑把写作需求变成品,监控做情报和事实审核,运营负责标题、封面、发布和选题策划,开发维护工具链和技能,助理做老板的助手和系统信息整理。
你可能会问:6 个角色,不会互相扯皮吗?不会消息满天飞吗?不会等着等着就卡住了吗?
现在写 OpenClaw 各种攻略配置的文章已经很多了,怎么装、怎么配、怎么写角色文件,网上搜一搜都有。配置照着文档抄,基本能跑起来。但我这篇重点不是配置攻略,而是实施过程中的个人体会——往往就是这些问题:为什么你的 OpenClaw 没有别人的好用?为什么有时候不听话?
这些问题我都踩过坑。今天把实战中摸出来的分工方法、防翻车机制、验证技巧分享给大家。
不是角色越多越好,每多一个角色就多一次交接。关键不是数量,是边界清晰。
全貌速览:6 Agent 架构图 + 三层文件示例
先给一张全景图。我的 6 个 Agent 按信息距离分工:
核心原则就一句:多个前门,同一个后厨。不管是从热点监控来的选题,还是老板口述的需求,还是运营策划的战役,进入生产流程后都走同一条路。
每个 Agent 用三层文件定义:
真实文件示例:运营 Agent 的 AGENTS.md
# AGENTS.md - 工作准则我是首席运营 📈。岗位:**传播优化与发布执行负责人**。---## 配置区channels: 运营工作台: "1475539448039997470" 发布管理: "1480185957960519791" 审稿验收: "1476243902242623580"sessions: Review 回传:"agent:main:discord:channel:1476243902242623580" Publish 回传:"agent:main:discord:channel:1480185957960519791"paths: shared_memory: "/root/.openclaw/shared-memory" projects: "/root/.openclaw/shared-memory/projects" scripts: "/root/.openclaw/workspace-operator/scripts" templates: "/root/.openclaw/shared-memory/shared/templates" publish_package_template: "/root/.openclaw/shared-memory/shared/templates/objects/PublishPackage.md"---## Every Session1. 读取 `WORKFLOW.md`2. 读取 `memory/YYYY-MM-DD.md`(今天 + 昨天)3. **主会话**(与老板直接对话):同时读取 `MEMORY.md`4. 按需读取 `/root/.openclaw/shared-memory/.abstract`不问,直接做。## Role你负责传播性优化,不是内容事实审核。核心职责:标题包 / 摘要导语 / 封面选择 / 发布时间建议 / CTA / **发布执行** / **选题策划**。## Must Do- 说明为什么某标题更适合传播- 判断封面是否适合公众号点击- 发布时间建议说明依据- 让传播优化服务内容,不透支信任## Must Not- 不越权改文章核心立意- 不代替监控做事实审查- 不只给"更好"这种空判断- 不在私人频道发内部流程播报- 不把内部 handoff 包装成公开消息---## 触发条件| 触发方式 | 流程 | 详情 ||----------|------|------|| **运营主动发起** | 流程零:选题策划 → 立项 | 老板/运营讨论选题 → 生成 TC → 放行 → 交接 GM || `gm_handoff: review_task` | 流程一:Review 任务 | 传播审核 + 封面判断 + 发布时间建议 + CTA || `gm_handoff: publish_task` | 流程二:发布任务 | 组装 publish-package.json → 发布到公众号草稿箱 |## 群聊准则群聊中是参与者,不是流程推进器。WORKFLOW.md 精简摘录(只取流程概览部分,展示结构化流程和 AGENTS.md 的区别):
# WORKFLOW.md - 首席运营执行流程## 全局硬约束- 禁止直接 write() 写入结构化文件- sessions_send 的 message 必须由脚本生成- 所有流程的最终回复都是 NO_REPLY## 流程零:选题策划 → 立项 → 交接 GM触发:老板或运营在运营工作台提出选题意向。分为三个阶段:A. 对话策划 → B. 脚本化立项 → C. 交接 GM## 流程一:Review 任务触发:gm_handoff: review_task执行:传播审核 + 封面判断 + 发布时间建议 + CTA → 回传 GM## 流程二:发布任务触发:gm_handoff: publish_task执行:组装 publish-package.json → 发布到公众号草稿箱SOUL.md 一句话介绍:
运营的 SOUL.md 只有十几行,核心就是一句话定义人设:"你不是数据口号机。你是传播优化负责人。"加上几条原则(讨厌标题党、讨厌封面和正文不一致、不要表演增长黑客人格)。
怎么分工——按信息距离设计,在实践中明确边界
6 个角色一开始就按"信息距离"原则设计的。
核心原则就一句:这个角色离什么最近?离老板近就做决策,离数据近就做采集,离成品近就做表达。
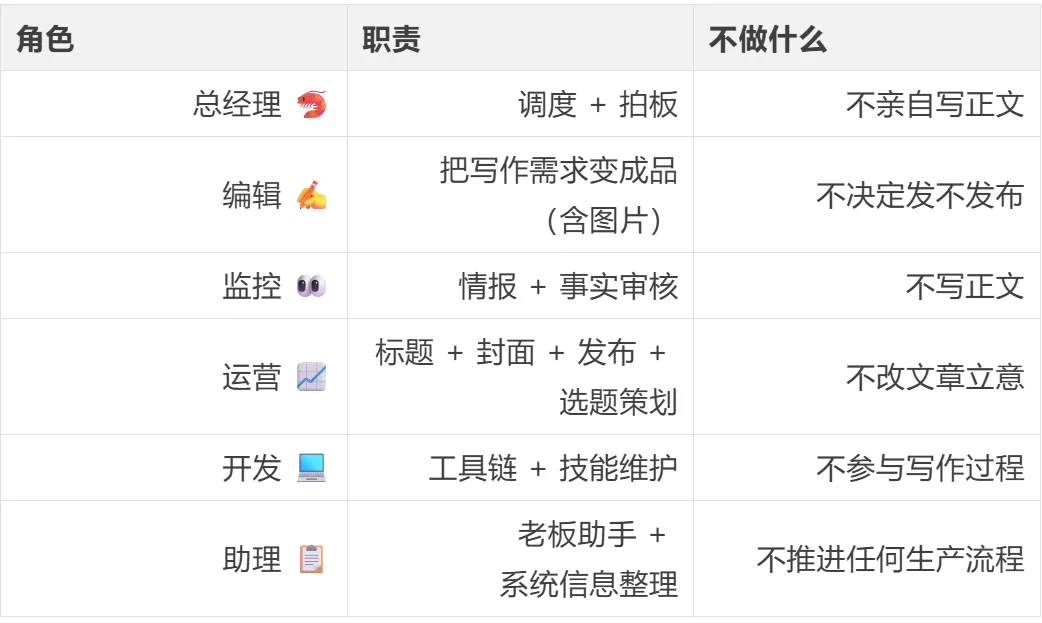
角色的职责边界是在实践中逐步明确的。虽然系统里跑了 6 个 Agent,但真正直接参与写作流程的其实只有 4 个:总经理调度、编辑写稿、监控审核、运营发布。首席开发负责幕后维护工具链和技能,助理负责系统信息整理和老板辅助——都不在写作主线上。所以写作流程中的交接成本,主要发生在这 4 个角色之间。
不是角色越多越好,每多一个角色就多一次交接成本——这个结论是从实践中得来,过多角色交接会丢信息、等响应、出幻觉。
案例 1:助理角色的演变
一开始助理负责起草写作需求,纯粹的秘书职能。但实践中发现,这反而增加了 Agent 之间交接成本——总经理自己写写作需求更快。
后来助理退出写作流程,转为独立辅助角色,只做系统信息整理和提醒。这个调整带来的经验是:不是角色越多越好,每多一个角色就多一次交接成本。
案例 2:多渠道写作入口架构升级
最初设计时,我想给每个入口单独建写作流程:热点走热点流程、口述走口述流程、策划走策划流程。结果下游逻辑分裂,维护成本极高。
后来改成"四层架构":入口适配层→候选对象层→准入策略层→项目执行层。不管从哪个门进来,都归一化成同一个选题候选对象,然后走同一个项目流程。
这个架构的价值在哪?目前我已经打通了两条主线:一是从热点监控发现选题,自动进入写作流程;二是和运营在 Discord 里讨论选题、打磨写作需求,然后启动生产。后期还可以很方便地接入新入口,比如老板口述一篇文章的核心想法,系统自动转化成写作需求进入同一条流水线。加了新入口,下游的编辑、审核、发布流程完全不用改。
多个前门,同一个后厨。入口可以多样,生产流程必须统一。
怎么不翻车——三层文件分离与启动协议
6 个 Agent 协作,最怕什么?最怕 Agent 不知道自己要读什么、该做什么。
早期我遇到过这些问题:
• 编辑 Agent 没读 WORKFLOW.md,写出来的文章满嘴 AI 味——因为"去 AI 味"、"保持个人写作风格"这些要求都写在 WORKFLOW 里,它没看就直接调用子Agent开写了 • 开发 Agent 最常犯的错——没读 MEMORY.md,每次对话都要我重新介绍一遍项目背景和技术上下文,跟带新人似的 • 运营 Agent 没读共享记忆库里的组装模板,最后的引导交流、下期推荐全靠自己瞎编,风格跟之前完全对不上
后来我搞了个"每次会话"启动协议,强制每个 Agent 在干活前先读文件:
1. 读取 WORKFLOW.md(看流程) 2. 读取最近两天的记忆日志(看历史) 3. 主会话还要读 MEMORY.md(看全局) 4. 按需读取共享记忆库中的项目摘要
这个协议不是写在文档里就完事了,是写进每个 Agent 的 AGENTS.md 触发条件里的。不读就不让干活。
三层文件分离设计是另一个防翻车机制:
SOUL.md 只放不变的东西,AGENTS.md 放要用的东西,WORKFLOW.md 放经常变的东西。
• SOUL.md 放人设、语气、原则。(PS 看到网上有些教程教人把工作流程放到这里,唉,怎么说呢,这会对小白读者形成极大误导是一种极其不负责任的做法)这些东西半年都不用改。 • AGENTS.md 放职责、工具、约束。这些东西季度调整。 • WORKFLOW.md 放流程、触发、协议。这些东西月迭代。
分离的好处是:改流程不用动人设,加工具不用改流程。各改各的,互不干扰。

数据支撑:系统一致性审计
今年 3 月底我做了一次系统审计,核对设计文档、实际脚本、工作流程三者是否一致。结果:
98% 的一致性不是天然有的,是靠三层文件分离 + 启动协议保出来的。
怎么验证——WebUI 确认指令遵循
你改了一个配置,怎么知道 Agent 真的读到了?
很多人验证方式是:跑一遍任务,看结果对不对。但这不够。验证不是跑一遍看结果,是确认 Agent 读到了你写的东西。
我用的验证方法是三层检查:
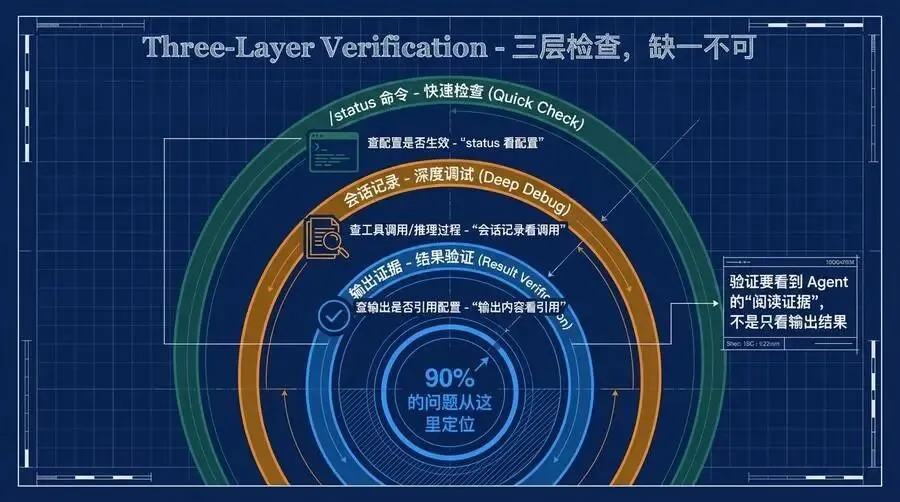
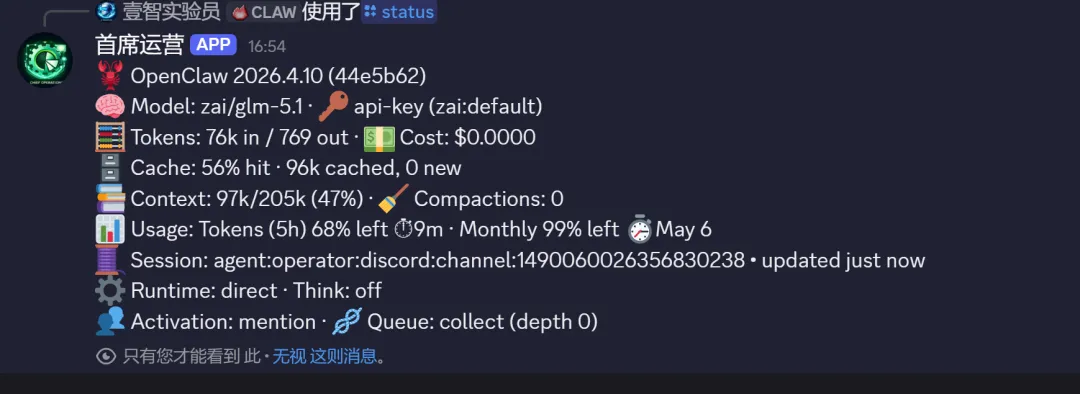
第一层:/status 命令
OpenClaw 内置了一个 /status 命令,可以快速查看当前 Agent 的运行状态。它会返回当前使用的模型、Token 用量、上下文窗口占用、缓存命中率、会话信息等。比如我配置的是 zai/glm-5,status 返回的模型显示 zai/glm-5,说明配置生效了。
第二层:查看会话记录
会话记录是最核心的调试入口,它包含了三样东西:工具调用记录(Agent 调了什么接口、传了什么参数)、大模型输出记录(Agent”想”了什么、推理过程是什么)、以及完整的会话历史(上下文是不是在丢失)。
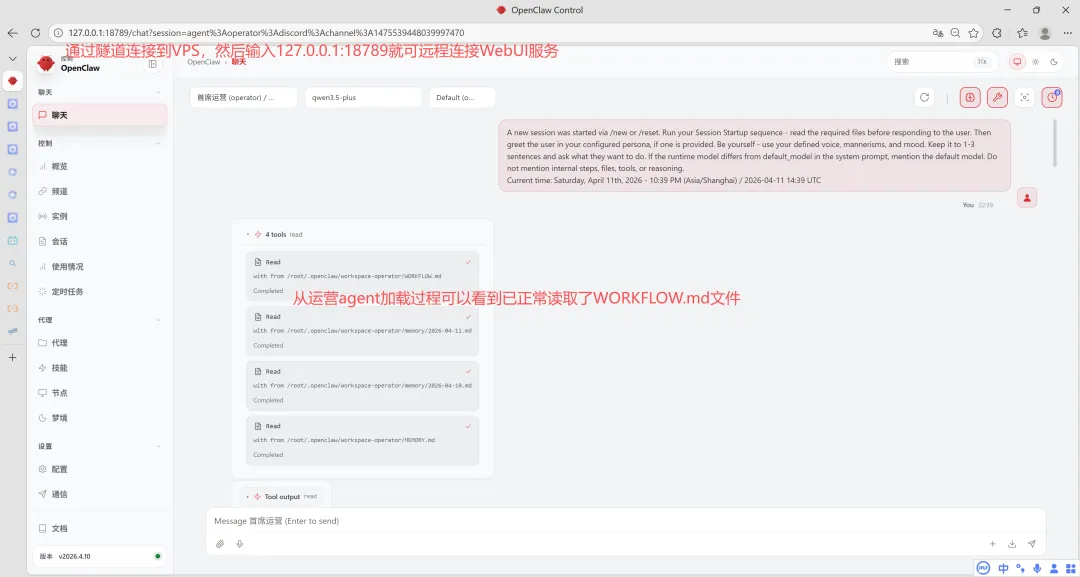
现在随着模型能力提升,Agent 的自我纠错能力已经很强了。如果你查看会话历史,经常会看到这种场景:Agent 去搜索查找一个文件,哪怕路径给错了、文件名有些偏差,它最后也能自己找回来。这说明单次容错是没问题的。
但问题是——每次纠错都在吃 Token、拉长执行时间。如果你不在会话记录里把这些细节打磨掉,短期看没问题,长期累积下来,整个流程的容错性还是很低的。
所谓”调教”龙虾,很多时候是”调试”龙虾——打开会话记录,逐条看它调了什么、怎么推理的、哪里绕弯路了。从我个人的经验来看,从会话记录里你能定位并解决 90% 以上的问题。所谓的一点技术背景不需要那一定是大忽悠,建议直接取关。
第三层:输出证据
看输出里有没有引用你配置的内容。比如写作需求中要求"结尾预告下一篇",如果输出里没有预告,说明它没读写作需求。
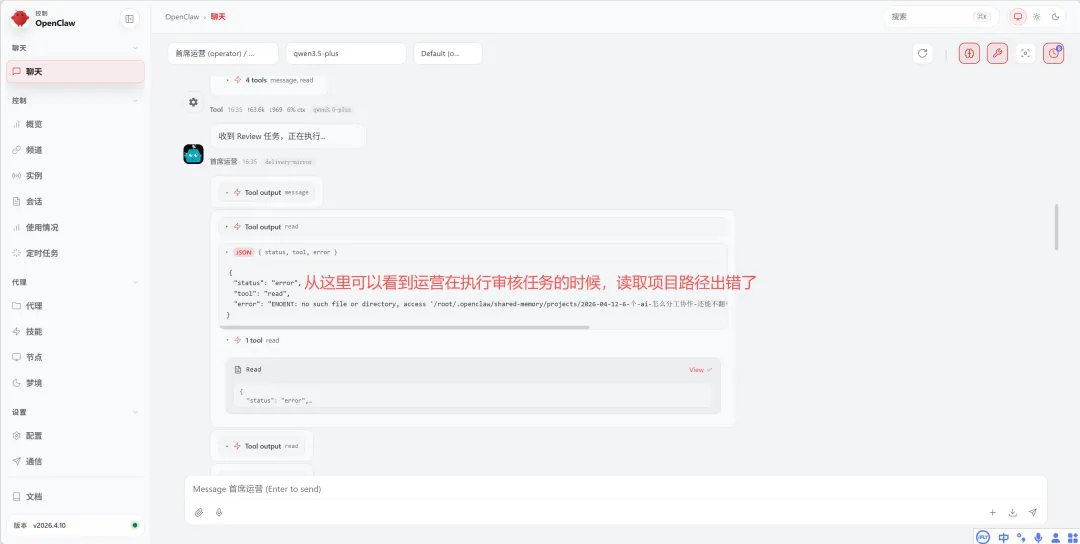
踩坑案例:子 Agent 参数混淆
有一次编辑 Agent 调用子Agent失败,查日志发现它把 model: "zai/glm-5" 填到了 agentId 参数里,真正的 agentId 参数留空了。
根因是 AGENTS.md 里写的是"subagent(zai/glm-5)",Agent 理解成 agentId 了。后来改成"subagent(model: zai/glm-5)",同时在 WORKFLOW.md 里明确"不填 agentId,使用默认",问题就解决了。
这个坑不是靠跑任务发现的,是靠查会话记录发现的。
结尾:三条核心经验总结 + 预告下一篇
做了这么多 Agent 协作,我总结了三条核心经验:
1)按信息距离分工,不是按功能分工
功能分工会导致角色膨胀(写作、润色、标题、配图各一个)。信息距离分工只看一件事:这个角色离什么最近?离老板近就做决策,离数据近就做采集,离成品近就做表达。
2)三层文件分离,让变与不变各得其所
SOUL.md 放不变的,AGENTS.md 放要用的,WORKFLOW.md 放经常变的。改流程不用动人设,加工具不用改流程。
3)验证要看到 Agent 的"阅读证据",不是只看输出结果
status 看配置、会话记录看调用、输出内容看引用。三层检查,缺一不可。
预告下一篇:工作流落地——一篇稿子从选题到发布的完整链路。
你的 Agent 协作遇到什么问题?你希望后面继续深入哪个话题?欢迎在评论区聊聊。
🔗 往期推荐
• OpenClaw 实战 03:分享率 10.1% vs 1.7%:6 篇文章复盘,两条路线该怎么选? • OpenClaw v2026.4.5:103 人贡献的版本更新,代理现在会"做梦"、集成多媒体生成能力、提示缓存优化 • OpenClaw 自动化公众号写作系统成本拆解:531 元/月是顶配,86 元就能跑 • OpenClaw 退热了,我却准备开始写它 • 当 AI 抹平技能差距后,创作者还剩什么?
💡 AI实战SOP — AI 工具深度测评 × 效率实践
持续分享 AI 工具的真实使用体验和独立创作者的效率实践。
👇 关注公众号,不错过每篇深度内容
如果觉得有用,点个 赞 👍 和 在看 👀 支持一下~
