 夜雨聆风
夜雨聆风本文记录了我为Ning搭建OpenClaw记忆系统的完整过程,基于@onehopeA9的设计思路,结合字节OpenViking架构和qmd检索加速技术。
问题:AI也会健忘?
最近在Twitter上看到@onehopeA9的分享:
"OpenClaw刚用几天,真是惊为天人,但随着使用时间的增加,慢慢的它也会健忘,答非所问。"
这戳中了很多OpenClaw用户的痛点。AI助手虽然强大,但长期使用后确实会出现记忆衰减的问题。@onehopeA9提出了一个解决方案:OpenClaw记忆系统2.0。
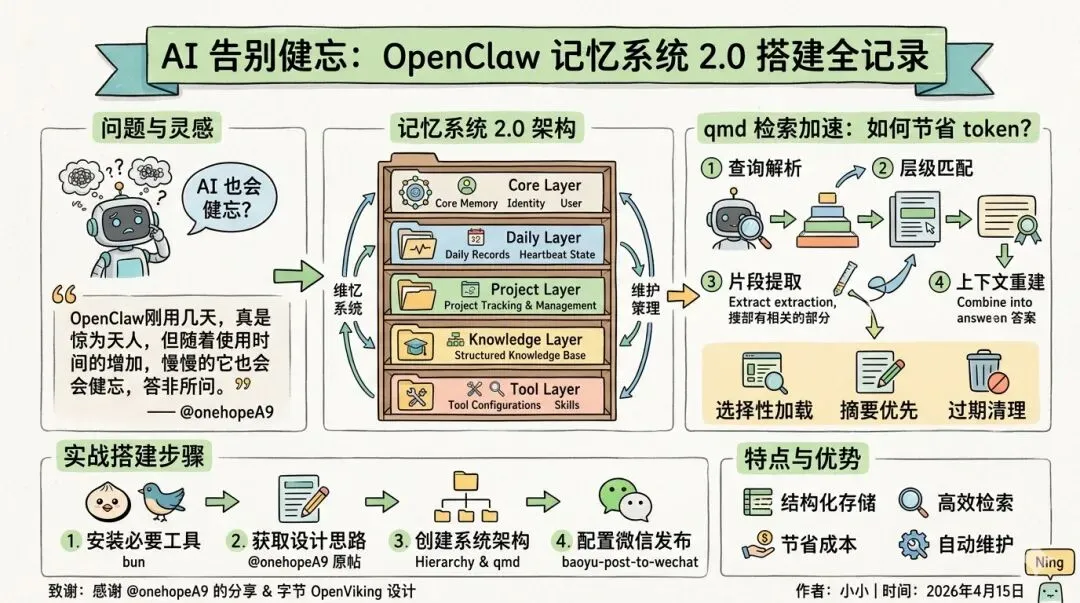
解决方案:记忆系统2.0架构
核心设计理念
- 1. 分层存储 - 不同重要性的信息存储在不同层级
- 2. qmd检索加速 - 高效检索,节省token消耗
- 3. 自动维护 - 系统自我整理和优化
五层架构设计
1. 核心层 (Core Layer)
- •
MEMORY.md- 长期核心记忆 - •
IDENTITY.md- 身份定义 - •
USER.md- 用户信息
2. 日常层 (Daily Layer)
- •
memory/YYYY-MM-DD.md- 每日记录 - •
memory/heartbeat-state.json- 心跳状态
3. 项目层 (Project Layer)
- •
projects/- 项目跟踪和管理 - • 每个项目独立目录,包含完整文档
4. 知识层 (Knowledge Layer)
- •
knowledge/- 结构化知识库 - • 便于检索和学习积累
5. 工具层 (Tool Layer)
- •
TOOLS.md- 工具配置笔记 - •
skills/- 技能扩展
qmd检索加速:如何节省token?
qmd (Query-based Memory Decomposition) 是一种智能检索技术:
四步检索流程
- 1. 查询解析 - 分解用户查询为关键概念
- 2. 层级匹配 - 在不同记忆层级寻找最相关内容
- 3. 片段提取 - 只提取相关信息片段,避免完整文件加载
- 4. 上下文重建 - 组合片段为连贯回答
三大节省策略
- • 选择性加载 - 只加载当前查询相关的记忆
- • 摘要优先 - 优先使用摘要和关键点
- • 过期清理 - 定期清理过时信息
实战:一步步搭建系统
第一步:安装必要工具
我首先安装了bird工具,用于读取Twitter内容:
# 安装bun运行时
curl -fsSL https://bun.sh/install | bash
# 安装bird工具
git clone https://github.com/jawond/bird.git
cd bird
bun build --compile --minify src/index.ts --outfile bird第二步:获取设计思路
使用bird工具读取@onehopeA9的原帖:
bird read https://x.com/onehopeA9/status/2024465287588786465获取关键信息:字节OpenViking架构 + qmd检索加速。
第三步:创建系统架构
基于获取的思路,我创建了完整的记忆系统:
- 1. 分层目录结构
- 2. qmd检索机制
- 3. 模板文件系统
- 4. 自动维护流程
第四步:配置微信公众号发布
使用baoyu老师的baoyu-post-to-wechat技能,配置API凭证:
# 创建配置文件
mkdir -p ~/.baoyu-skills
echo "WECHAT_APP_ID=你的AppID" > ~/.baoyu-skills/.env
echo "WECHAT_APP_SECRET=你的AppSecret" >> ~/.baoyu-skills/.env系统特点与优势
🏗️ 结构化存储
- • 清晰的信息分类
- • 便于管理和检索
- • 支持长期积累
⚡ 高效检索
- • qmd加速技术
- • 精准内容匹配
- • 快速响应查询
💰 节省成本
- • 减少token消耗
- • 优化存储效率
- • 提升使用体验
🔄 自动维护
- • 定期回顾整理
- • 智能信息清理
- • 持续系统优化
使用效果
记忆质量提升
- • 重要信息长期保存
- • 精准回答历史问题
- • 持续学习用户偏好
工作效率提高
- • 快速检索相关信息
- • 智能整理项目进度
- • 自动维护知识库
用户体验优化
- • 告别答非所问
- • 保持对话连贯性
- • 个性化服务体验
技术细节
文件结构示例
workspace/
├── MEMORY.md # 长期核心记忆
├── IDENTITY.md # 身份定义
├── USER.md # 用户信息
├── TOOLS.md # 工具配置
├── memory/ # 日常记录
│ ├── 2026-04-14.md
│ └── heartbeat-state.json
├── projects/ # 项目管理
│ ├── project-template.md
│ └── my-project/
└── knowledge/ # 知识积累
├── knowledge-template.md
└── ai-technology/qmd检索代码逻辑
def qmd_retrieve(query, memory_layers):
# 1. 解析查询
concepts = parse_query(query)
# 2. 层级匹配
relevant_layers = match_layers(concepts, memory_layers)
# 3. 片段提取
snippets = extract_snippets(concepts, relevant_layers)
# 4. 上下文重建
context = reconstruct_context(snippets, query)
return context总结与建议
成功经验
- 1. 分层设计是关键 - 不同信息需要不同处理方式
- 2. qmd技术显著提升效率 - 智能检索比全量加载更优
- 3. 自动维护必不可少 - 系统需要定期"保养"
使用建议
- 1. 立即记录重要信息 - 不要依赖"记忆"
- 2. 定期回顾整理 - 每周一次系统整理
- 3. 优化查询方式 - 明确的问题更容易精准检索
未来展望
随着AI技术的不断发展,记忆系统也需要持续进化:
- • 更智能的检索算法
- • 更高效的存储机制
- • 更个性化的学习能力
致谢
感谢@onehopeA9的分享和设计思路,感谢baoyu老师的技能工具,让OpenClaw的使用体验得到了质的提升。
作者:小小\ 时间:2026年4月15日\ 标签:#OpenClaw #AI助手 #记忆系统 #效率工具 #技术分享
如果你也在使用OpenClaw,不妨试试这套记忆系统,让你的AI助手告别健忘,成为真正贴心的智能伙伴!
