 夜雨聆风
夜雨聆风问得好。
说实话,同样一个 API,参数调得好和调得差,效果天差地别。
就像做菜,同样的食材,火候和调料不同,味道就差远了。调 API 也是一样,temperature、max_tokens、top_p 这几个参数,看着不起眼,实际上决定了 AI 回复的质量。
今天就把这些参数掰开揉碎讲清楚。每个参数配实战示例,看完就能直接上手调。
temperature(温度):控制 AI 的"创造力"
它是干啥的
temperature 控制 AI 输出的随机性。
设成 0,AI 每次回复几乎一样,稳定但死板。设成 1,AI 回复更有创意,但也更不可控。设成 2,AI 就开始"放飞自我"了,可能说出一些莫名其妙的话。
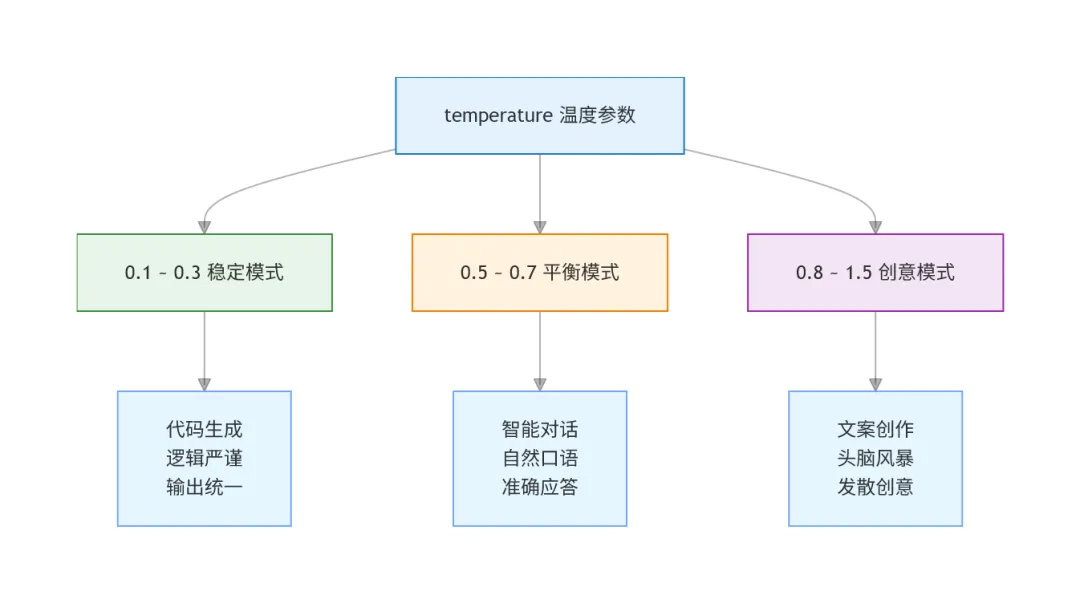
AI前端开发中,不同场景需要不同的 temperature:
代码生成:0.1-0.3,需要稳定、准确 日常对话:0.5-0.7,需要自然、流畅 创意写作:0.8-1.0,需要创意、多样性 头脑风暴:1.0-1.5,需要发散思维
实战对比
用同一个 prompt,不同 temperature 的回复差异很大:
const prompt = "写一个 React 按钮组件";// temperature: 0.1 - 稳定模式// 每次回复几乎一样,代码规范、类型完整// temperature: 0.7 - 平衡模式// 代码有些变化,但核心功能一致// temperature: 1.5 - 创意模式// 可能加了动画效果、渐变背景等创意元素// 但也可能偏离需求,加了不必要的功能
AI生成前端代码时,temperature 设太高是个常见坑。你以为 AI 会给你更"好"的代码,实际上它可能加了一堆你不需要的花里胡哨的东西。
正确做法:代码生成永远用低 temperature(0.1-0.3),对话场景用中等值(0.5-0.7)。
max_tokens(最大输出长度):控制回复的篇幅
它是干啥的
max_tokens 限制 AI 回复的最大 Token 数。一个 Token 大概对应 0.75 个英文单词或 1-2 个中文字。
设太小,回复被截断,话说到一半没了。设太大,浪费钱,还可能让 AI 啰嗦一堆废话。
常见场景的推荐值
实战技巧
技巧一:根据需求动态设置
别死板地用一个固定值,根据用户问题来调:
function getMaxTokens(prompt) {// 简单问题,少给 Tokenif (prompt.length < 20) return 300;// 代码生成需求,多给 Tokenif (prompt.includes('组件') || prompt.includes('代码')) {return 2000;}// 复杂问题,给足够的 Tokenif (prompt.length > 100) return 1500;// 默认值return 800;}
技巧二:检测截断,自动续接
如果 AI 回复被截断了(最后一个字符不是标点符号),可以自动续接:
async function chatWithAutoContinue(prompt, maxRetries = 2) {let fullReply = '';let retries = 0;while (retries <= maxRetries) {const response = await callAI(prompt, { max_tokens: 1000 });fullReply += response;// 检查是否被截断(最后一个字符不是标点)const lastChar = fullReply.trim().slice(-1);const isComplete = /[。!?.;!?]$/.test(lastChar);if (isComplete) break;// 续接:让 AI 继续写完prompt = `请继续:${fullReply}`;retries++;}return fullReply;}
智能前端开发中,这种自动续接逻辑能避免用户看到被截断的回复,体验好很多。
top_p(核采样):控制词汇选择的范围
它是干啥的
top_p 跟 temperature 配合使用,控制 AI 从哪些词里选择下一个词。
设成 1.0,AI 从所有可能的词里选。设成 0.9,AI 只从概率最高的 90% 的词里选。设成 0.5,AI 只从概率最高的 50% 的词里选,回复更保守。
什么时候需要调它
大部分场景,top_p 用默认值(1.0)就行。但有几个场景值得调:
场景一:需要高准确性的回答
比如医疗、金融、法律类问答,设成 0.8-0.9,减少 AI "编造"的概率。
场景二:需要多样化的回复
比如聊天机器人,设成 0.95-1.0,让回复更自然、不重复。
temperature 和 top_p 怎么配合
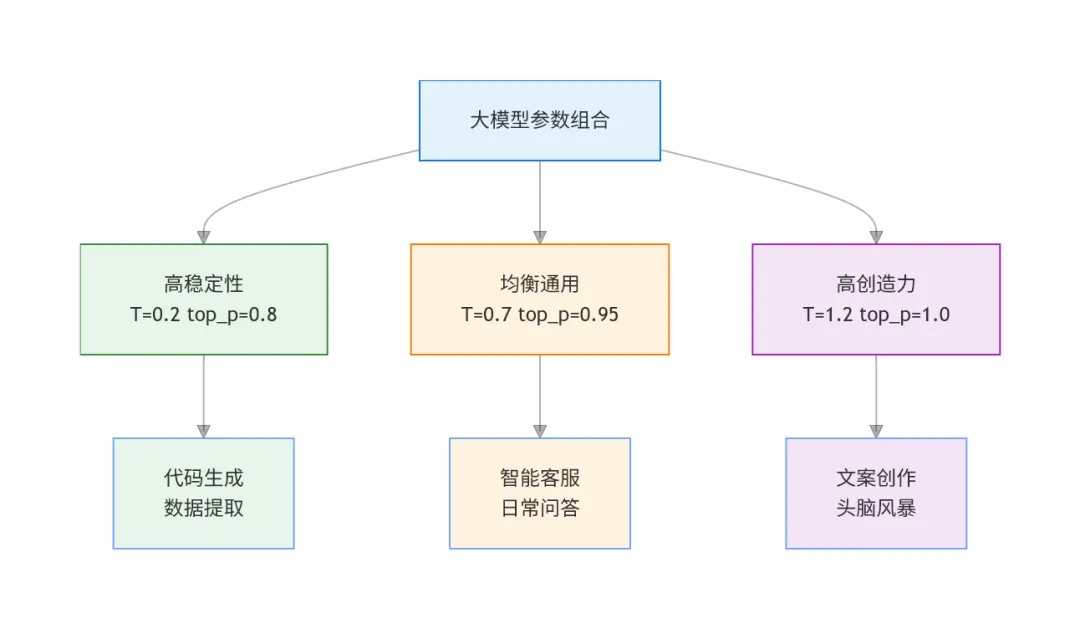
两个参数一起用,效果是叠加的:
// 高稳定性配置(代码生成推荐){temperature: 0.2,top_p: 0.8}// 结果:回复非常稳定,几乎每次都一样// 平衡配置(日常对话推荐){temperature: 0.7,top_p: 0.95}// 结果:回复自然流畅,有一定变化// 高创意配置(头脑风暴推荐){temperature: 1.2,top_p: 1.0}// 结果:回复多样有创意,但可能偏离主题
前端调用AI接口时,建议把常用的参数组合做成预设模板,别每次都手动调。
回复格式控制:让 AI 按你想要的格式输出
JSON 格式
让 AI 返回 JSON 数据,方便前端直接解析:
const prompt = `请以 JSON 格式返回一个按钮组件的配置:{"name": "组件名称","props": { "属性名": "属性类型" },"styles": { "样式属性": "值" }}不要输出其他内容,只输出 JSON。`;async function getComponentConfig(prompt) {const response = await callAI(prompt, {temperature: 0.1, // JSON 需要稳定输出max_tokens: 500});// 提取 JSON(去掉可能的 markdown 标记)const jsonStr = response.replace(/```json\n?/g, '').replace(/```\n?/g, '').trim();try {return JSON.parse(jsonStr);} catch (e) {console.error('JSON 解析失败:', e);return null;}}
Markdown 格式
让 AI 返回格式化的 Markdown 文档:
const prompt = `请生成一份组件使用文档,包含以下内容:1. 组件简介2. Props 说明表格3. 使用示例代码4. 注意事项使用 Markdown 格式。`;
结构化输出
对于复杂场景,可以让 AI 按固定模板输出:
const prompt = `请按以下模板回答:【核心观点】(一句话总结)【详细解释】(2-3段说明)【代码示例】(相关代码)【注意事项】(1-2条提醒)用户问题:${userQuestion}`;
AIGC前端应用里,结构化输出太有用了。PRD 解析、文档生成、API 设计,都能用。
实战:参数调优完整示例
把上面所有参数组合起来,做一个参数调优的工具函数:
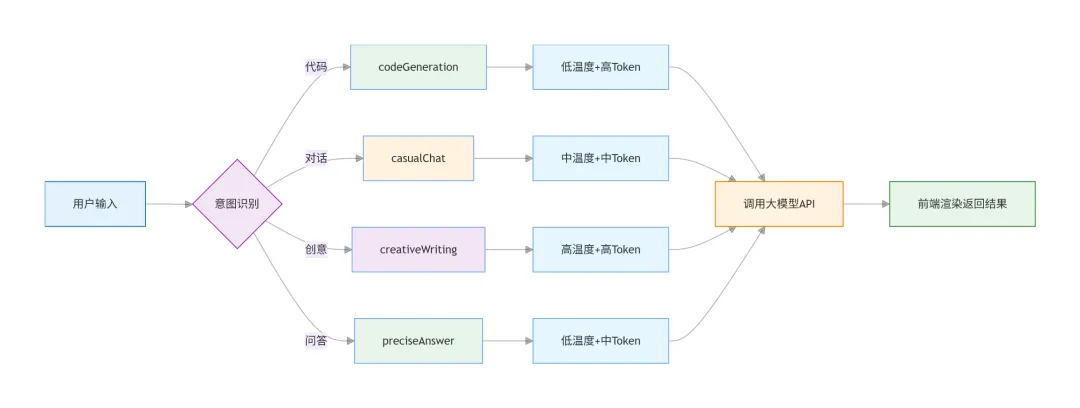
// 参数预设模板const PARAM_PRESETS = {// 代码生成codeGeneration: {temperature: 0.2,max_tokens: 2000,top_p: 0.8,systemPrompt: '你是一个资深前端工程师,只输出代码,不输出解释。'},// 日常对话casualChat: {temperature: 0.7,max_tokens: 800,top_p: 0.95,systemPrompt: '你是一个友好的AI助手,用简洁的语言回答问题。'},// 创意写作creativeWriting: {temperature: 1.0,max_tokens: 1500,top_p: 1.0,systemPrompt: '你是一个有创意的写作助手。'},// 高精度回答preciseAnswer: {temperature: 0.3,max_tokens: 1000,top_p: 0.85,systemPrompt: '你是一个专业的技术顾问,回答要准确、简洁。'},// JSON 数据生成jsonOutput: {temperature: 0.1,max_tokens: 500,top_p: 0.7,systemPrompt: '你是一个数据生成助手,只输出合法的JSON,不输出其他内容。'}};// 智能参数选择function getParamsByIntent(intent) {return PARAM_PRESETS[intent] || PARAM_PRESETS.casualChat;}// 使用示例async function smartChat(message, intent = 'casualChat') {const params = getParamsByIntent(intent);return callAI(message, {temperature: params.temperature,max_tokens: params.max_tokens,top_p: params.top_p,systemPrompt: params.systemPrompt});}// 调用smartChat('帮我写一个按钮组件', 'codeGeneration');smartChat('今天天气怎么样', 'casualChat');smartChat('写一首关于编程的诗', 'creativeWriting');
这套参数预设模板,覆盖了 前端AI工具 开发中最常见的场景。直接拿去用,不用每次都纠结参数怎么设。
避坑指南:参数配置的 3 个常见错误
分享几个我踩过的坑。
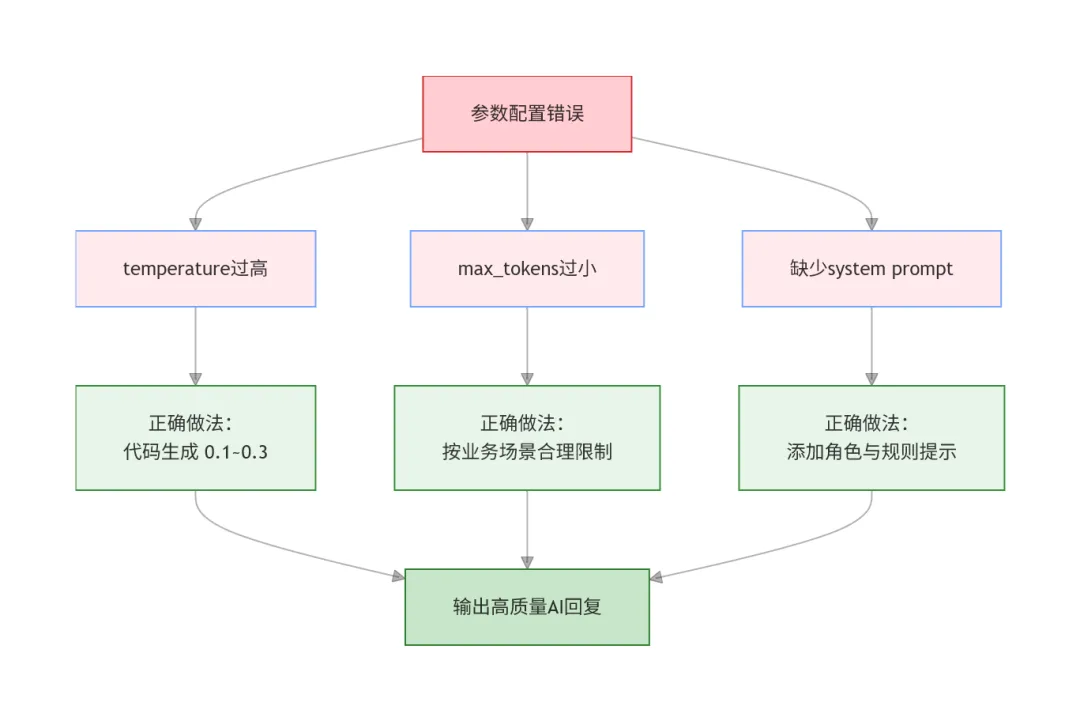
第一个坑:temperature 设太高,代码全是 Bug
一开始觉得"高 temperature 是不是代码更有创意",结果 AI 生成了一堆编译不过的代码。
正确做法:代码生成永远用低 temperature(0.1-0.3)。创意留给对话场景。
第二个坑:max_tokens 设太小,回复被截断
设了 200,AI 说到一半就停了。用户以为出 Bug 了。
正确做法:根据场景设合适的值,宁可设大一点,也别设太小。
第三个坑:忘记 system prompt
不设置 system prompt,AI 回复的风格飘忽不定。今天叫你"亲",明天叫你"您好"。
正确做法:每个场景都设置合适的 system prompt,让 AI 保持一致的角色和语气。
// 错误示范:没有 system promptcallAI('帮我写代码');// 正确做法:设置 system promptcallAI('帮我写代码', {systemPrompt: '你是一个资深前端工程师,使用 TypeScript,代码要规范、有注释。'});
总结
API 参数调优,看着是细节,实际上直接决定了 AI 回复的质量。
temperature 控制创造力,max_tokens 控制篇幅,top_p 控制词汇选择,system prompt 控制角色设定。
把这四个参数调好了,AI前端应用的质量能上一个台阶。
下一篇,我会讲怎么把聊天界面做得更完善:移动端适配、响应式设计、消息气泡优化。从"能用"到"好用",就差这一步了。
互动时间:
你平时调 API 用的是什么参数组合?评论区分享下经验~
点赞收藏,系列更新不迷路!也可关注我,进群交流!
本文关键词:AI前端、前端AI、AI生成前端代码、前端调用AI接口、智能前端、AIGC前端、前端AI集成方案、React AI组件实战、Vue结合AI开发、AI优化前端性能、低代码AI前端页面、ChatGPT前端开发、AI前端源码

