自从ChatGPT爆火以来,AI大模型迎来爆发式发展,从早期企业尝试落地到国内大厂纷纷布局,再到DeepSeek、OpenClaw相继出圈,AI逐渐渗透生活与工作。伴随普及,「Token」「B」等易混淆概念走红,实则它们与前后端、存储领域的同名术语截然不同,本文将梳理AI的底层逻辑,拆解两大核心概念,让大家更好辨析。 AI的Token和前后端说的Token AI的Token和前后端说的Token,是两回事,只是撞名而已! 1.Token=身份令牌 在代码世界的前后端语境里,Token是前端向后端取数使用的身份令牌,核心是身份、权限、安全。登录APP或者网站,后端会返回一段乱码,比如: eyJhbGciOiJIUzI1NiIsInR5cCI6IkpXVCJ9...
这个乱码就是Token
但在AI时代,Token就是指若干个字数,或者叫文本块。主要是大模型如何对一段话进行“切”词,分成多少个片段,每个片段就是叫Token。(国内给了一个名字:词元)
通常,中文:1个Token=0.7个汉字,1000个Token=700个汉字,英文:1 个 Token ≈ 4 个字母 / 0.75 个单词 。
AI大模型就是用Token来计算 输入长度、输出长度、上下文窗口、计费 。
上下文长度/上下文窗口,就是AI能一次性记住多少个字。这是衡量一个模型的能力。 生成速度,Token/s,表示AI每秒能生成多少Token(多少个字) b. 普通大模型:20~60 token/s,高性能:80+ token/s 计费 a. 费用 = 输入 Token 数 × 输入单价 + 输出 Token 数 × 输出单价 i.输入 Token(Prompt):你发给 AI 的所有内容 (1) 问题 + 历史对话 + 系统提示词(system prompt) (2) 一次性并行处理,成本低、单价便宜 ii.输出 Token(Completion):AI 生成的回复 (1) 逐字串行生成,每 1 个 Token 都要跑一次完整推理 (2) 成本高、单价通常是输入的 2~10 倍 b. Token ≠ 汉字(估算参考) 中文:1 字 ≈ 1.5~2 Token 英文:1 词 ≈ 1.3~1.5 Token 例:“你好”≈3~4 Token;“Hello”≈1 Token c. 避坑 i. 历史对话全算钱 (1) 多轮聊天时,整段历史都会被当作输入 Token 重新计费 例:聊 10 轮,每轮输入 100 字 → 总输入 Token 会线性累积 ii. 思考 Token(推理模型) (1) DeepSeek-R1、GPT-o1 等会先 “思考” 再回答 (2) 思考过程产生的 Token 也会计费(通常算输出),但不显示给你 iii. 缓存优惠(少数平台) (1) 重复输入相同长文本,命中缓存可半价计费 (2) 适合知识库、长文档重复查询 iv. 多模态(图/文/音) (1) 图片、音频会被转成特殊Token,单价远高于纯文本 d. 怎么省钱? i. 少让 AI 写长文:输出 Token 最贵,控制回复长度 ii. 精简 prompt:去掉废话、重复、无关历史 iii. 选对模型:日常用 Turbo/Lite,复杂任务才上 Max/Pro iv. 开启缓存:重复内容用缓存价 v.量化监控:API 返回里会带 prompt_tokens / completion_tokens ,一定要统计
所以,这样你也大约明白为啥OpenClaw等智能体这么废Token了!
AI的「B」和存储的「B」
AI的「B」和存储的单位的「B」是两回事,也只是撞名而已! 1.AI的「B」 通常你会看到很多模型会这样写:Qwen3:8B、Qwen3:30B等等,这里的「B」是什么意思? AI的「B」,是指Billion(十亿), 模型大 小,指 AI 大脑里有多少个 “神经元参数”。 单位有B(Billion十亿)、M(million百亿)、T(trillion万亿)。 大模型AI的核心有三个:底层数学,表层统计,核心概率。 (一)底层数学 普通公式: y=2x+5 y=1.2x+3.4
这里两个公式分别有两个参数,2和5,1.2和3.4
而AI的计算公式: 输出=f(W1,W2,W3,....,W70亿,...,W800亿) 核心原因是AI是通过细微差异进行调节的,会决定它的聪明程度。 比如:“妈妈” 和 “妈妈呀”这两个词关联度很高,但不是 100% 一样。 (1)如果用整数:只有 0、1、2、3… 跳跃太大要么完全绑定,要么完全没关系,太粗糙 (2)如果用小数:可以是 0.92、0.75、0.31能精准表达「有点像、很像、不太像」的微弱区别
这里的小数很重要,进入计算机领域就是看计算器的存储、内存等硬件能保留多少位小数,存储领域就用“精度”去表达。 AI会大量去吸收见过的文本、书本、知识,本质是 统计亿万句话的字词搭配、语序、常识、句式规律 。AI它不 “懂道理”,只 统计见过的所有文本模式 。
一开始AI的参数都是假设的,输出的内容都是无根据,导致AI像个傻子。但之后在不停地喂数据和训练,如果AI猜错就改参数(微调小数),反复训练,循环几百万次,最终“练出”参数。
把以上的参数打磨固化,就是大模型的参数,保存起来,就是我们说的大模型文件。
(三)核心概率 AI将吃透的文本放进公式里,计算下一个字概率,挑出最高概率的字,循环往复,最后变成连贯的一句话。
AI这里并不是穷举,而是利用训练出来的参数做规律预测,不做无效计算,从而快速有效地输出对应的内容。
2.存储的“B” 1Byte=8bit(位)
1KB=1024Byte
1MB=1024KB
1GB=1024MB
1个字母=1个字节(Byte),1个汉字=2个字节(Byte)。
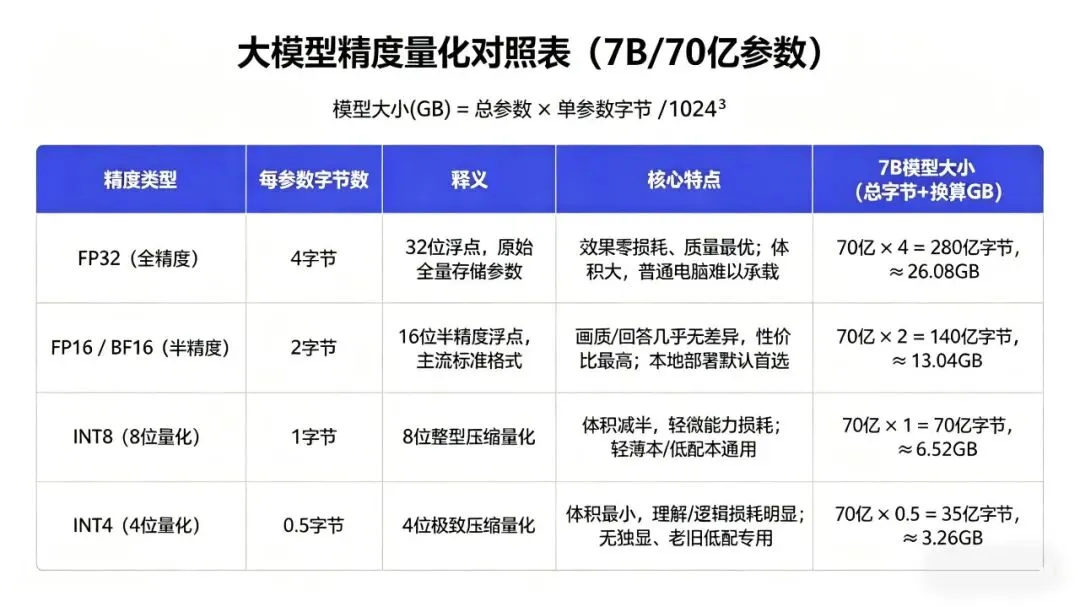
上文说到,大模型的参数是小数,而硬盘存储时需要按 精度 保存小数。 一个大模型要占硬盘多少存储空间,就由 大模型的参数量 和 存储精度 决定。 训练 Checkpoint(断点存档):同模型大小 x 份数 训练大模型不是一次跑完,要跑很多天 / 很多轮。每跑一段时间,就把当前所有几十亿个参数(小数)完整存一份,而这份文件就叫Checkpoint 断点存档。 作用是当中途断电、崩溃、调参数,能从上次存档继续练,不用从头再来。 体量:单份Checkpoint 体积 = 完整模型权重大小,多份Checkpoint=单份大小 X 保存份数
从以上得知,AI大模型需要的电脑硬盘有基本要求,如果遇到checkpoint文件增加,有可能会导致硬盘爆炸。同时不同精度的数据类型也会影响模型存储与性能,合理选择可实现效率与精度的平衡。 这里也说明了,硬件价格陡升的根本情况:大模型的发展让参数规模爆炸(模型从 1B→7B→70B→1000B,算力需求每 18 个月翻 10 倍),叠加checkpoint的“放大效应”,让显存 / 内存 / 存储全吃满, 急需更多显存/内存/存储,但高端芯片 / HBM(高带宽内存)产能有限,供需失衡叠加垄断溢价,导致现在硬件价格陡升。 厘清AI领域「Token」与「B」的核心含义,可以更好地规避使用误区、降低成本,也能更清晰地看懂AI大模型的底层逻辑,助力我们更好地拥抱AI技术。
 夜雨聆风
夜雨聆风