 夜雨聆风
夜雨聆风一、论文信息
很多时候,人们真正关心的不是“预测会不会准”,而是“在不确定的时候怎么做决定”。投资、储能、医疗这类问题里,宁可保守一点,也不能因为判断失误付出太大代价。本文关心的正是这件事:当结果还不知道时,怎样一边把风险控制住,一边别把决策做得过于保守。
本篇推文解读的文章来自 International Conference on Learning Representations,简称 ICLR。它是机器学习与人工智能领域最具影响力的国际会议之一,长期聚焦表征学习、深度学习及相关前沿问题,在全球学界与工业界都有很高关注度。特别值得一提的是,在 2026 年发布的第七版中国计算机学会推荐国际学术会议和期刊目录中,ICLR 已被列入 CCF-A 类会议。
英文题目: Conformal Robustness Control: A New Strategy for Robust Decision
中文题目 :保形鲁棒性控制:鲁棒决策的新策略
作者 :Yang Hu,Jieren Tan,Changliang Zou,Yajie Bao,Haojie Ren
来源 :OpenReview
二、背景及贡献
很多实际决策问题都不是只要求预测准确,还要求在高风险场景中避免代价过大的错误。例如投资组合配置、医疗决策、电池储能控制等,都希望在不确定结果 尚未观测到时,依据协变量 做出决策 ,并让损失 以高概率不超过某个风险 。论文采用的基本鲁棒性目标是
条件鲁棒优化(Conditional Robust Optimization,CRO)的标准做法,是先构造预测集 ,再解一个最小最大问题得到决策。为了保证最终鲁棒性,现有方法通常要求预测集满足覆盖率约束
问题在于,覆盖率约束只是鲁棒性的充分条件,不是必要条件。也就是说,只要真实标签落入预测集,就一定能保证相应的最坏情形损失受控,但反过来并不要求每次都必须覆盖真实标签。因此,把覆盖率硬性设为 往往会让预测集偏大,随后最小最大优化得到的决策也会更保守,风险更高,效率更低。
这篇文章的贡献主要集中在三个方面。
第一 作者提出保形鲁棒性控制(Conformal Robustness Control,CRC)框架,直接在鲁棒性约束下最小化期望风险,而不是先追求覆盖率,再间接获得鲁棒性。
第二 作者给出了经验优化算法。由于鲁棒性约束里有指示函数,不可导,论文用平滑近似替代,并结合可微凸优化层完成梯度更新。
第三 作者给出了理论保证与测试时校准方法。前者说明经验解的鲁棒性缺口和最优性缺口会随样本量缩小,后者给出测试点层面的有限样本鲁棒性保证。
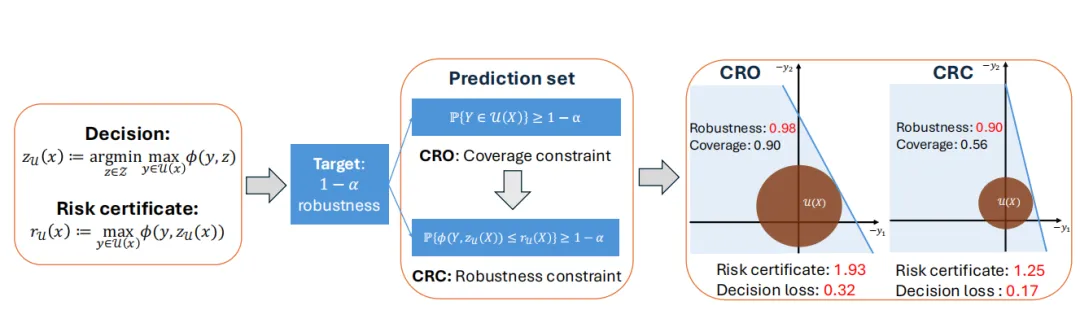
上图说明论文动机:同样是名义上 的目标,传统 CRO 因为盯住覆盖率,最后达到的是更高的实际鲁棒性,于是付出了更大的风险代价;CRC 则把鲁棒性控制在目标附近,因此决策更有效率。
三、主要结论
本文最重要的结论可以概括为以下几点。
首先,在不限制预测集形式时,作者证明了 CRC 与风险厌恶决策优化(Risk Averse Decision Policy Optimization,RA-DPO)在目标上是等价的。也就是说,从优化期望风险这一点看,直接优化决策函数与风险,和优化预测集再诱导决策,本质上可以达到同样的最优值。
其次,当预测集被限制为可计算的参数化家族时,鲁棒性约束比覆盖率约束更合适。文章证明,在参数化设定下,CRC 的理论最优风险不高于覆盖率版本的风险厌恶保形预测优化(Risk Averse Conformal Prediction Optimization,RA-CPO),并且存在严格更优的情形。
再次,在适当的 Lipschitz 条件与有界密度条件下,经验 CRC 解具有非渐近理论保证。其核心结论是,经验解在测试分布上的鲁棒性会接近目标水平,且风险与理论最优值之间的差距会随样本量增加而收敛到零。若参数维数为 ,文中给出的误差量级为
最后,作者提出校准版方法 Cal-CRC。它在训练后只调一个半径参数,就能对单个测试点给出有限样本鲁棒性保证,即
这意味着,CRC 既有样本量足够大时的渐近有效性,也有测试阶段可操作的有限样本控制。
四、论文细节
文章先把鲁棒决策写成一个带约束的优化问题。给定预测集 后,CRO 诱导的决策与风险分别定义为
于是,CRC 的总体目标可写为
为了可计算,作者进一步考虑参数化预测集 。文中重点给了两类结构。
盒形预测集(Box Prediction Set)为
椭球预测集(Ellipsoidal Prediction Set)为
于是参数化 CRC 变成
经验版本则是
难点在于约束中的指示函数不可导。作者用高斯误差函数构造平滑近似
再写出拉格朗日函数
通过交替优化更新 与 。直观地说, 负责让风险更小, 负责把鲁棒性约束推回可行域。这里之所以能用梯度法,是因为最小最大决策问题在盒形集与椭球集下都能改写为可微的凸优化层。
测试阶段,论文没有重新训练全部参数,而是只校准一个半径参数 。若用嵌套预测集族 表示半径扩张后的集合,例如椭球情形为
那么对每个候选标签 ,都可用校准集与测试点联合决定一个最小阈值 ,最后把满足鲁棒性判别条件的 收入 。这一步本质上是把全保形预测(Full Conformal Prediction)的思想用于鲁棒决策,而非直接用于覆盖率推断。
五、模拟结果
实验部分围绕三个任务展开。第一个任务是合成投资组合优化。损失定义为
并令
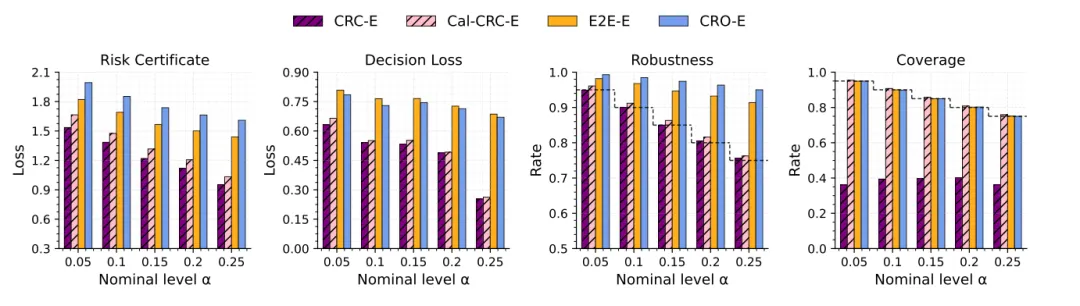
作者在这一任务中主要比较 CRC、CRO 和端到端方法(End-to-end,E2E)。
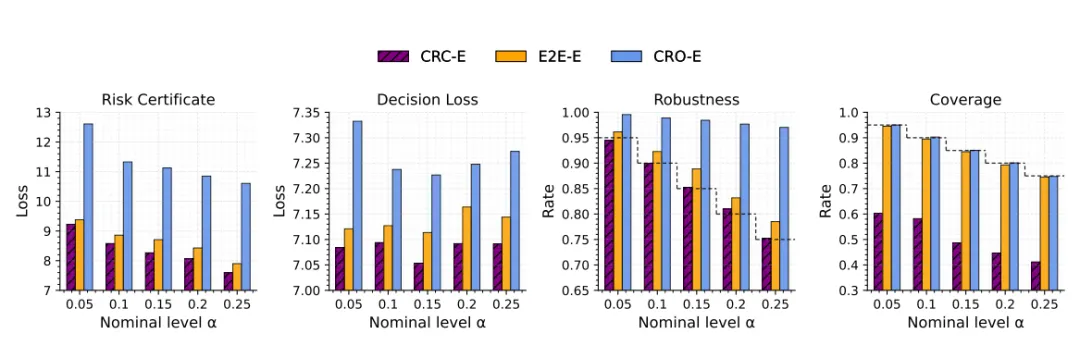
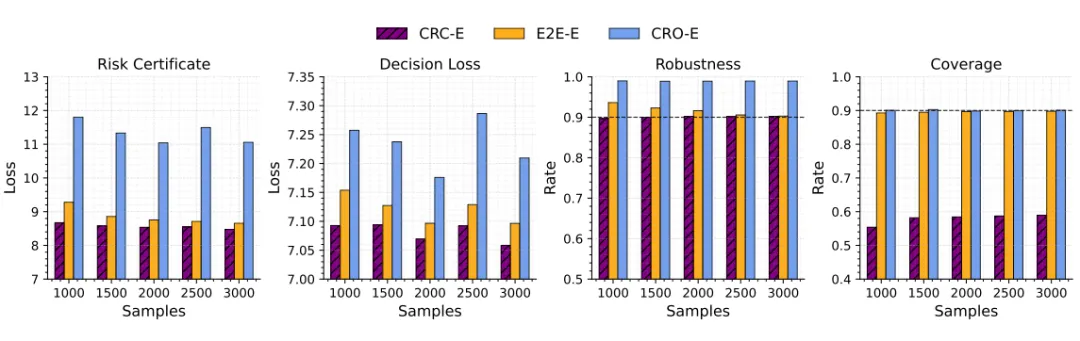
结论是:CRC 的风险与决策损失都更低,鲁棒性贴近目标值,而覆盖率明显低于鲁棒性目标。这一点很关键,因为它表明“较低覆盖率但足够鲁棒”在决策问题里是完全可能的,也正是本文方法的出发点。
第二个任务是真实美国股票数据。数据覆盖 2012 年到 2020 年,共 64 只股票,每次随机选取 15 只作为可投资资产。文中表1如下。
这张表说明得很直接。无论盒形集还是椭球集,CRC 在两种名义水平下都给出更小的风险,同时鲁棒性保持在目标附近。相反,CRO 与 E2E 的鲁棒性普遍高于目标,说明它们采取了更保守的决策。
第三个任务是电池储能控制。该问题同时考虑套利收益、储能状态灵活性和电池健康惩罚,时间跨度为 24 小时。
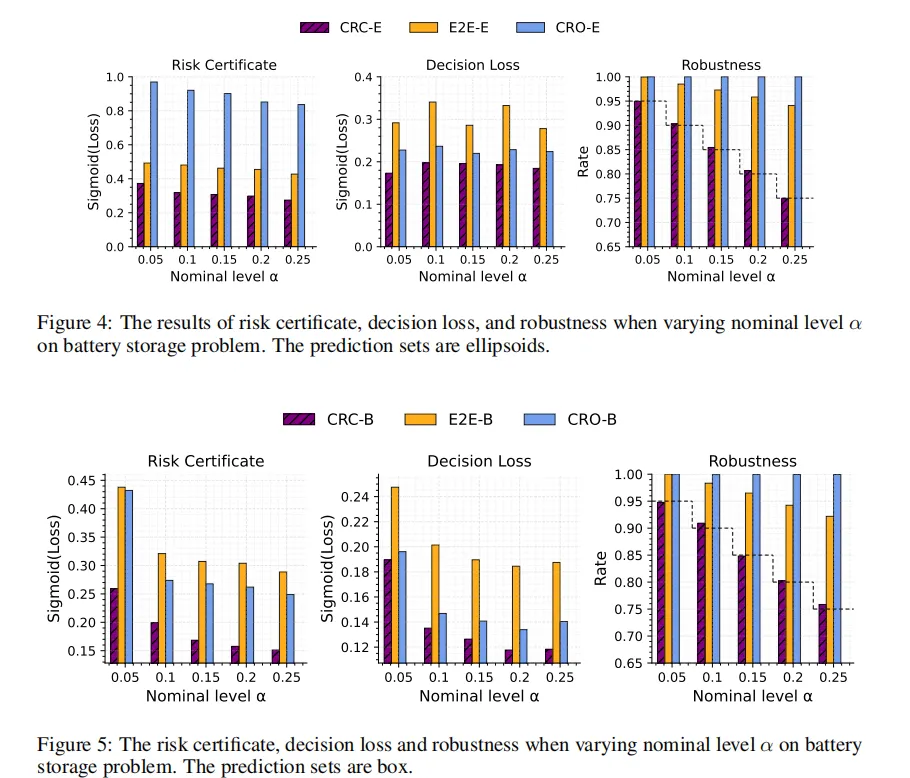
图中无论采用椭球集还是盒形集,CRC 都保持了更低的风险和决策损失,同时鲁棒性更接近名义目标。也就是说,本文方法并不局限于线性投资任务,在带动态约束的优化中也有类似表现。
消融实验方面,作者还比较了 CRC、Cal-CRC 和仅校准预训练模型的 Cal 方法。表6如下。
这张表反映出一个很清楚的现象。校准确实能把覆盖率和鲁棒性推到更高,但代价是风险上升,决策更保守。也就是说,Cal-CRC 的价值主要在于有限样本保证,而不是在平均效率上超过原始 CRC。
附录中的另外两组实验也值得简述。其一,平滑参数 从 0.01 变到 0.20 时,CRC 的主要指标变化很小,说明平滑近似较稳健。其二,改变拉格朗日乘子更新频率后,结果同样较稳定,说明算法训练过程对这两个超参数不算敏感。再进一步,作者把离散化后的 RAC 和多面体预测集也纳入比较,结论仍然是 CRC 更节制地使用覆盖率,更有效地实现目标鲁棒性。
六、我们的思考
我们认为,论文可能可以在下面的方向继续拓展
从统计推断角度看 这篇文章把保形方法的控制对象从覆盖率转向了决策鲁棒性。今后可以继续研究更强的条件型保证,也就是不仅控制总体鲁棒性,还控制局部协变量区域上的鲁棒性。
从高维统计角度看 当响应维度很高时,椭球协方差矩阵的估计会变得困难。可能可以考虑稀疏协方差、低秩结构、因子模型或图模型约束,让预测集更适合高维投资组合和多变量能源调度。
从风险度量角度看 本文关注的是由最坏情形损失诱导的风险。未来可以把约束扩展到条件风险价值(Conditional Value at Risk,CVaR)、谱风险或 expectile 型风险,从而比较不同风险定义下的效率与稳定性。
从因果与决策学习角度看 若协变量与结果之间存在干预结构,CRC 可以与因果效应估计、离线策略评估、个体化治疗规则结合。这样一来,预测集不只是描述不确定性,还可以反映干预后的决策风险。
总体来看,这篇文章把统计不确定性直接嵌入决策目标。对统计学读者而言,它提供了一个可能值得继续展开的问题:在有限样本、模型错设和分布漂移都存在时,如何用尽可能少的保守性换取足够可靠的决策保证。
本篇推文的封面、图片、表格来自论文原文:Conformal Robustness Control: A New Strategy for Robust Decision
