 夜雨聆风
夜雨聆风转载公众号 | 老刘说NLP
今天看Skill结合RAG思路进展,毕竟现在openclaw 这波的skill是越来越多,但不是越多越好,还是会涉及到怎么检索的问题,还是会用到RAG。
所以,先看一个故事,给定用户任务查询,从大规模技能库中检索完成任务所需技能,方案叫做SkillRouter,涉及到怎么检索、怎么微调、并且对比了一些技术选型,具体增益,是个有一定借鉴意义的技术试验报告。
另外,看看科学图标转可编辑代码的思路,这也是文档的一个大方向,其中涉及到数据合成和强化的思路,也是很有趣的点,读下来会很有逻辑,也值得一看。
一、Skill结合RAG思路:SkillRouter
技术在《SkillRouter: Skill Routing for LLM Agents at Scale》,https://arxiv.org/pdf/2603.22455,核心几个点:
1、检索基准
构建8万级大规模技能路由基准,实证完整技能实现体是核心路由信号【细节:基于SkillsBench构建约8万技能候选池,每个技能包含名称(name)、描述(description)、完整实现体(body)三部分。
其中:实现体里包含具体执行逻辑、函数/接口定义、参数约束、输入输出格式、处理流程、依赖项、功能边界、示例代码等元数据完全不具备的细节信息,功能差异由实现体决定,名称和描述本身区分能力有限。
例如,简化版本的例子:


具体的,设计75条专家标注查询(24单技能/51多技能),分Easy(78361候选)、Hard(新增780个高相似干扰技能)两难度;
先拉基线,实验上,在BM25稀疏检索、Qwen3-Emb-8B稠密检索、Qwen3-Emb-8B×Qwen3-Rank-8B检索-重排三组强基线做对照实验
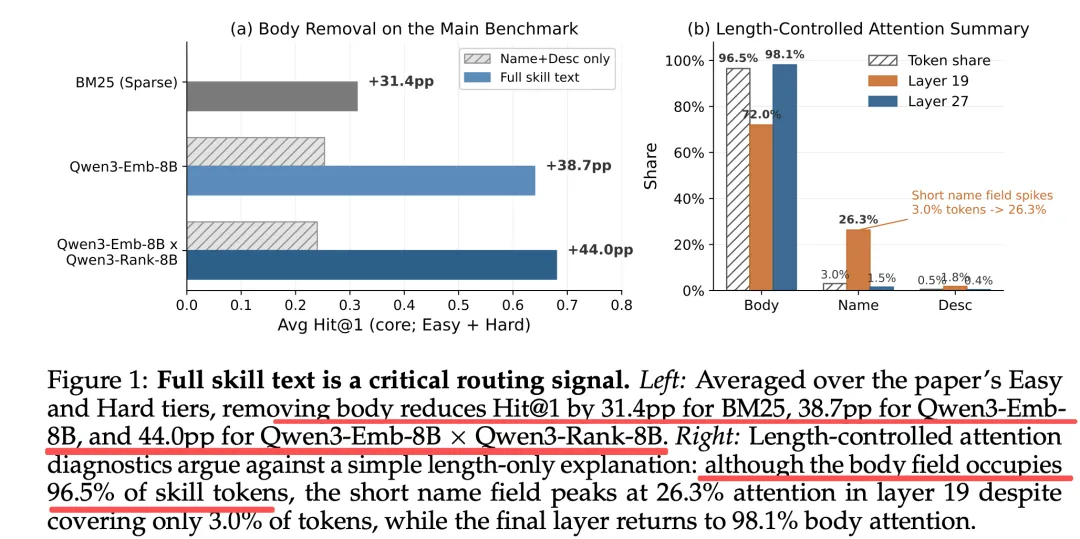
发现,仅输入name+description时,三组模型Hit@1分别从31.4%→0%、64.0%→25.3%、68.0%→24.0%,下降31.4pp、38.7pp、44.0pp。
通过长度控制注意力分析、描述长度分层检验,这是一个结论:下降不是因为body更长、描述更差,而是实现体里的执行逻辑、参数、接口、处理流程、功能边界才是精准路由的关键信息。
2、检索模型微调
做了个SkillRouter,基于Qwen3系列搭建1.2B全文本检索-重排Pipeline,检索器采用Qwen3-Emb-0.6B双编码器,重排器采用Qwen3-Rank-0.6B交叉编码器,然后做特定微调。
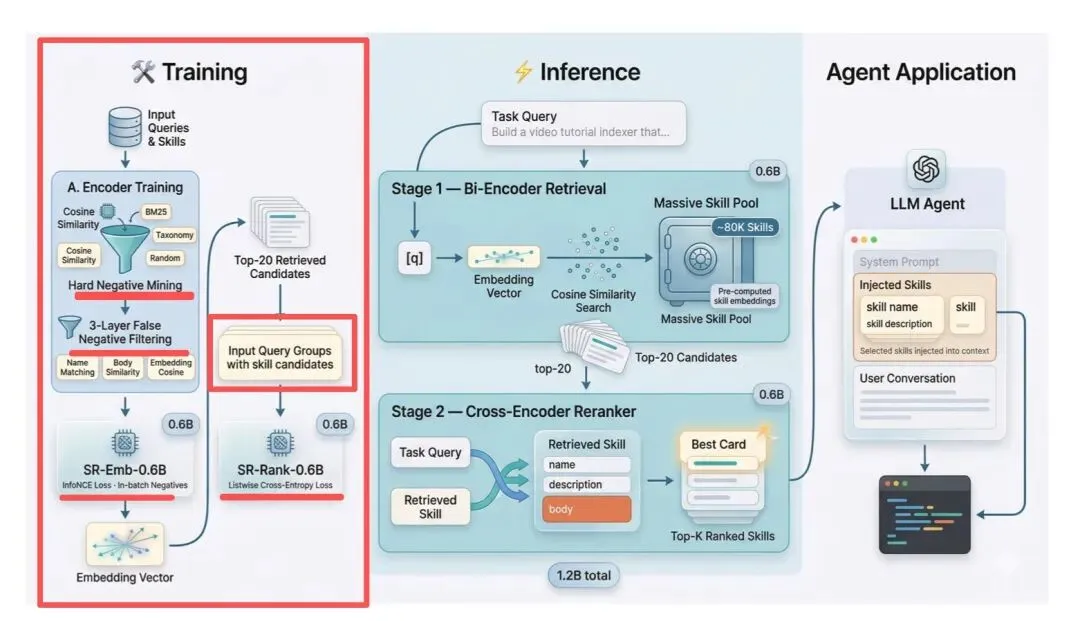
检索与重排全程输入完整技能文本:name+description+body,实现体按规则截断(描述≤300字符、实现体≤2500字符);
分开看:
首先,检索器微调,思路是对基座Qwen3-Emb-0.6B进行对比学习微调,损失函数为InfoNCE,使用37979条(查询-技能)微调样本,由GPT-4o-mini基于技能全文本合成,不泄露技能名,核心是难负样本挖掘+假阴性过滤,这是数据侧的常用策略【这个是重点】,具体看下:
四类难负样本挖掘,包括语义近邻负样本(4个)【基座编码器embedding最相似但功能不同的技能】、词汇匹配负样本(3个)【BM25关键词相似但功能不同的技能】、同分类负样本(2个)【同大类、不同功能的技能】、随机负样本(1个)【跨类别无关技能】、三层假阴性过滤(微调前清洗数据)】。
三类过滤,也是一些具体做法,包括:名称完全重复→过滤、三元组Jaccard>0.6→文本高度重叠→过滤、嵌入相似度>0.92→语义几乎一样→过滤,共过滤约10%伪负样本,让微调不被错误标签带偏。
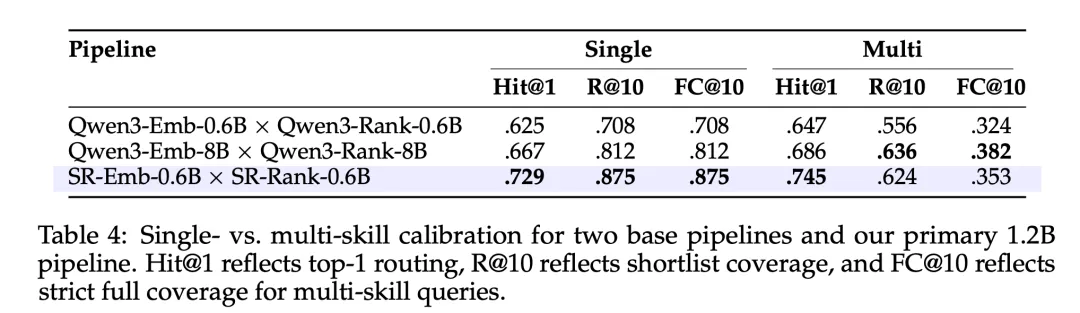
其次,重排器微调,对基座Qwen3-Rank-0.6B 做交叉编码器微调,采用listwise损失【强制模型在相似技能之间做细粒度比较】,以检索器输出的Top20 候选列表作为微调数据,共32283条列表样本,这一微调让 Hit@1从43.3%→74.0%。
3、检索增强Agent执行
这个是很典型的RAG,按经典RAG范式执行技能路由,并将检索结果注入Agent形成闭环,所以是个很工程化的应用。
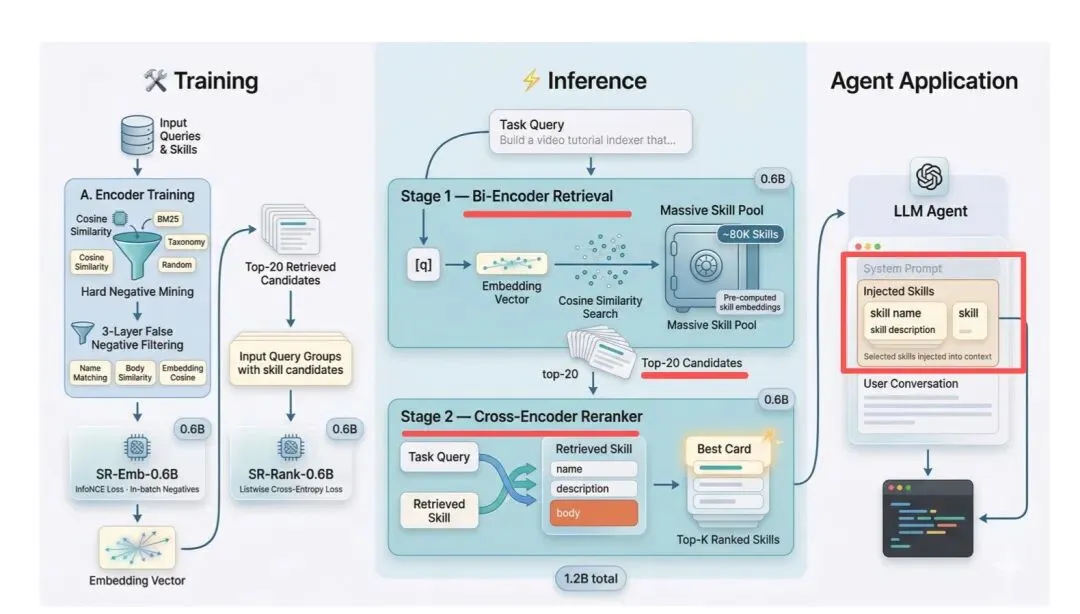
可以再回顾下这个步骤:
step1.离线构建向量库,把8万技能的完整文本(name+desc+body)通过SR-Emb-0.6B编码成向量,存入检索库;
step2.在线检索(Retrieve),用户任务输入→用同样编码器生成查询向量→从8万技能库中召回Top20最相关技能;
step3.精细重排(Rerank),把Top20候选连同完整实现体送入SR-Rank-0.6B交叉编码器,按任务相关性重新排序,得到最终Top1/Top10;
step4.注入Agent(Generate),重排后的结果只把name+description暴露给LLMAgent,实现体不暴露给下游,仅在路由阶段使用;
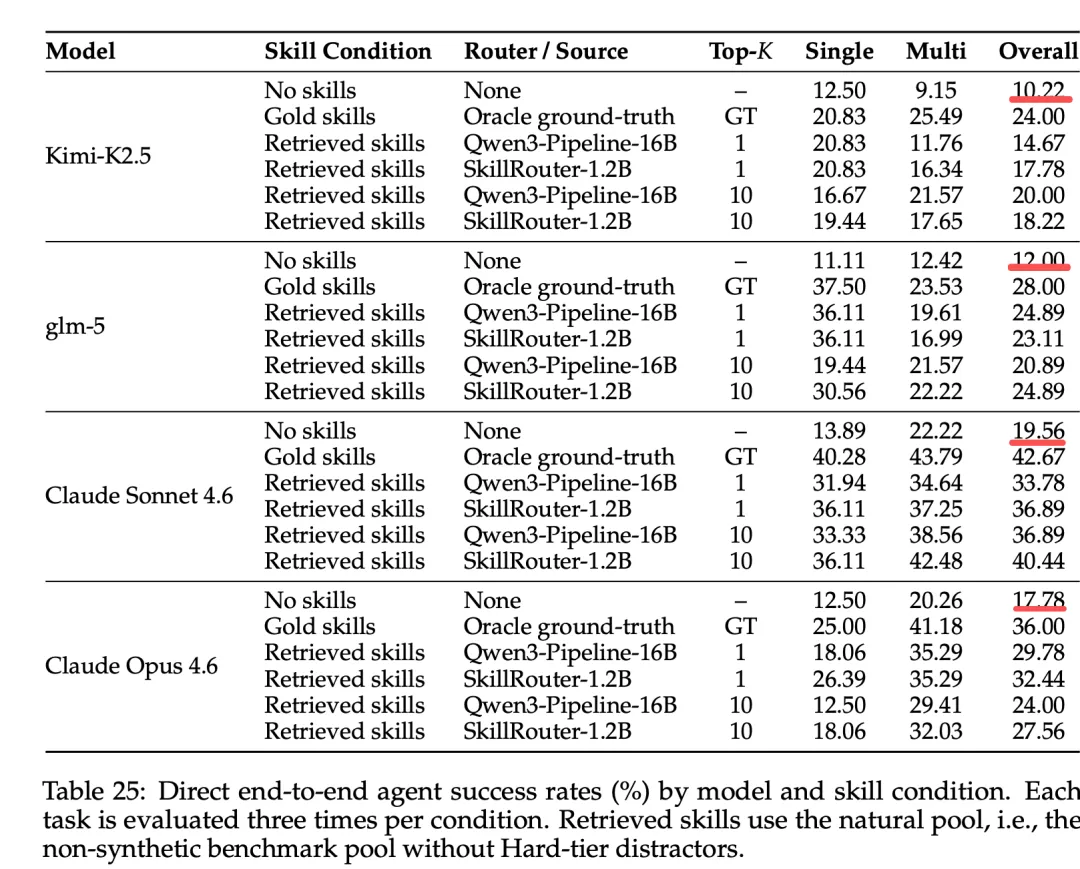
最终看结果,接入Kimi-K2.5、glm-5、ClaudeSonnet4.6、ClaudeOpus4.6四个编码Agent后,Top-1成功率提升1.78pp,Top-10提升2.33pp,强Agent增益达3.22pp。
二、学科图表转LaTeXcode的数据合成及强化思路
继续看数据合成方向,解决的问题是把一张科学图 → 自动合成出可运行的TikZ代码,也就是LaTeX里画科学矢量图,搞了个合成数据引擎构建,23万条覆盖11大学科的TikZ样本。
工作在《Scientific Graphics Program Synthesis via Dual Self-Consistency Reinforcement Learning》,https://arxiv.org/pdf/2604.06079, https://github.com/JackieLin0123/SciTikZ,主要看两点。
1、看数据合成思路
数据也就是最重要的点,步骤如下:
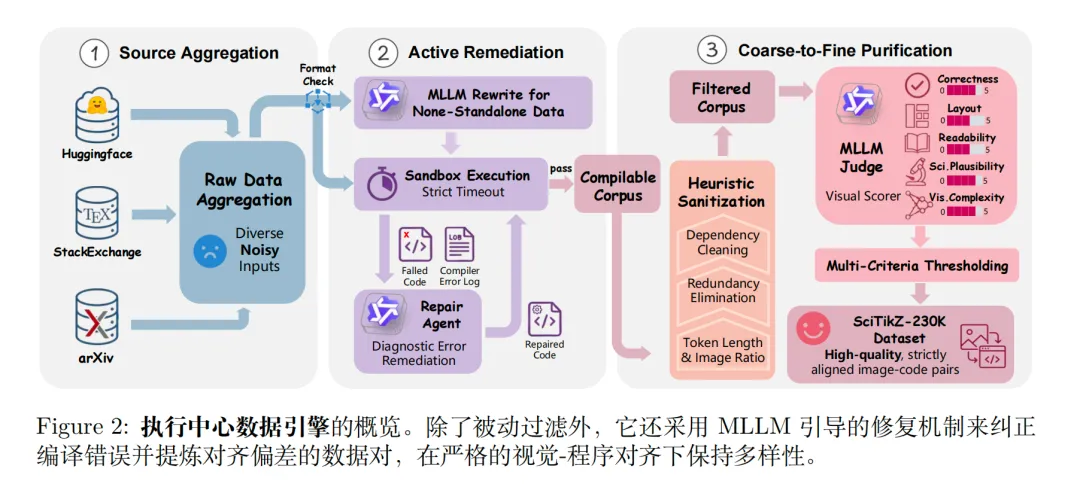
step1.来源聚合【HuggingFace、arXiv、TeX论坛,抓31万条原始TikZ】;
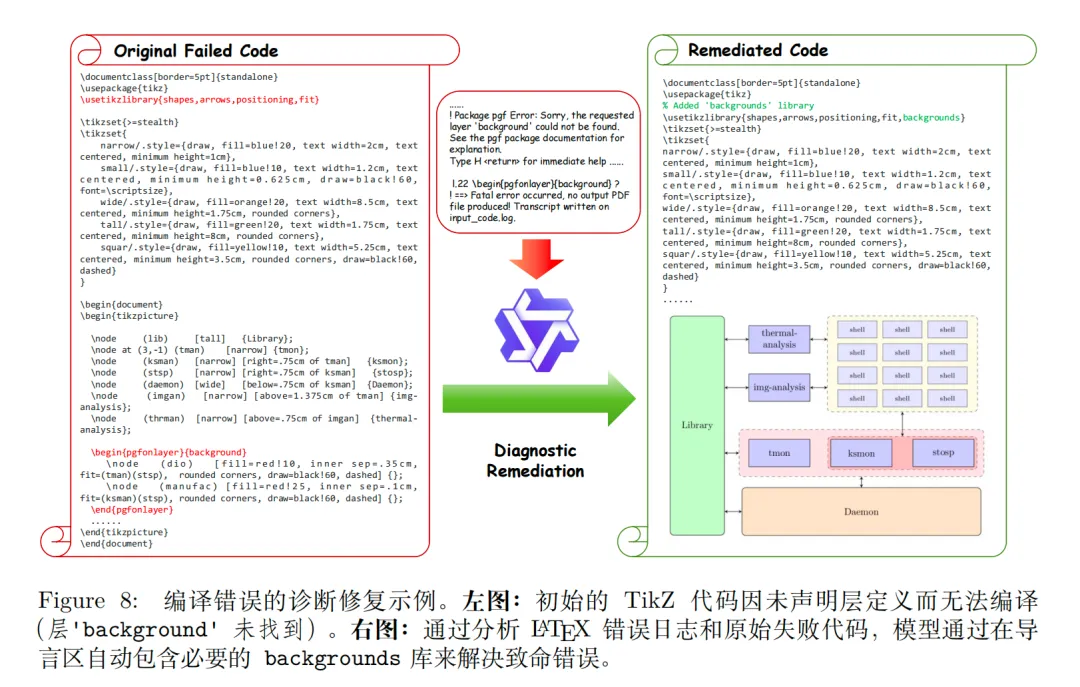
step2.主动修复。把残缺代码补成独立可编译的LaTeX文件【编译报错→把错误日志丢给大模型自动修,修复率≈60%,捞回废数据】;
step3.粗过滤及细粒度质量裁判【太长的删掉,比例太怪的删掉,重复太多的删掉,带外部文件的删掉(保证自包含),细粒度质量裁判截断,用Qwen3-VL-235B打分,5个维度加权:正确性(scorr),布局(slay),可读性(sread),科学合理性(ssci),以及视觉复杂度(scomp)。】,形成SciTikZ-230K。
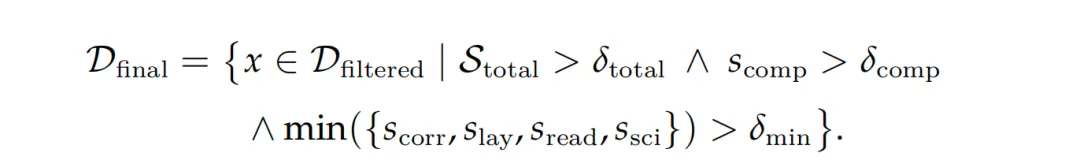
2、看训练方式
典型的sft+rl阶段,前者进行预热,后者进行奖励强化,核心在于这个强化数据的构造【很常规的用到课程学习】以及奖励函数,很套路的设计任务,合数据,微调强化刷指标闭环的做法,这个可以再看下:
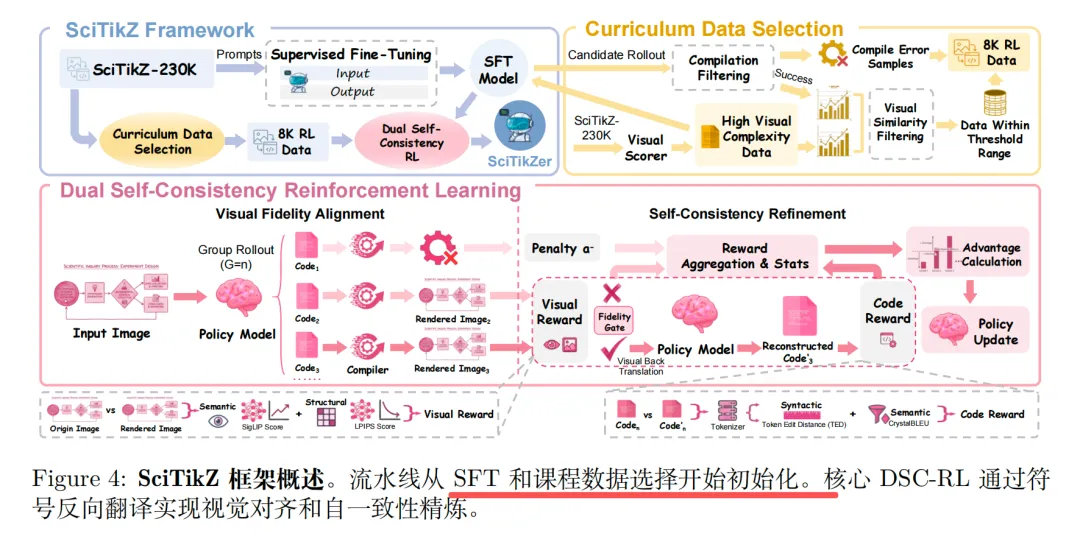
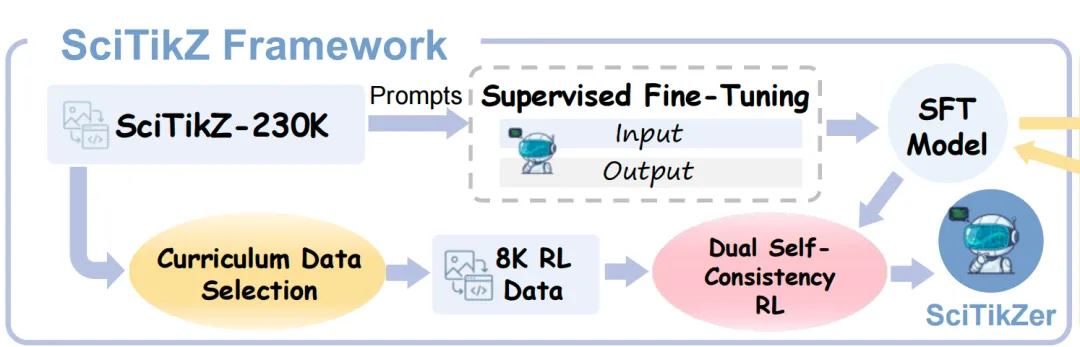
stage1.监督微调SFT,先学会语法、格式、包、结构【基座Qwen3-VL-4B/8B,输入:科学图,输出:标准TikZ代码,损失:最大化正确代码概率】;
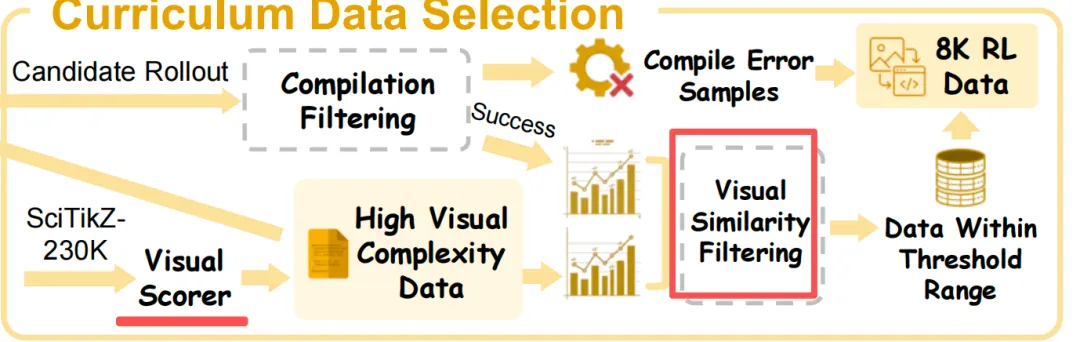
stage2.课程数据筛选,从23万条里挑8K条最有价值的给RL用【按照视觉复杂度筛选,然后再使用SigLIP编码器计算视觉相似度,选择视觉相似度中等(不是太简单也不是太难),这是现有模型数据工程主要手段】;
stage3.DSC-RL双自一致性强化阶段
两个阶段,通过GRPO 进行最优化:
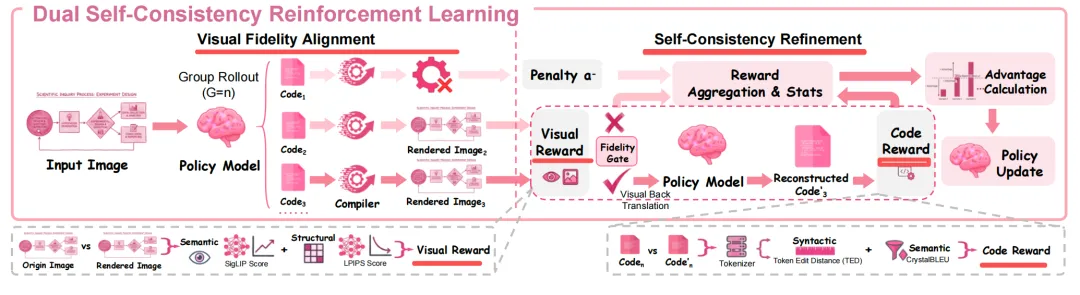
首先是视觉对齐Visual Fidelity Alignment,步骤是输入图I→模型生成代码ŷ→编译→渲染出图Î→计算奖励,这里两个奖励。
组合做:
先做奖励1:执行0/1奖励(硬约束,编译成功→给正奖励,编译失败→大惩罚),这是准入:
然后,执行奖励2:多粒度视觉奖励(语义对齐SigLIP计算相似度,看整体像不像+结构精度LPIPS:使用AlexNet为骨干网络的LPIPS计算看坐标、线条、布局准不准,为骨干网络的 LPIPS);

其次是一致性强化Self-Consistency Refinemen,步骤是:原图I→代码ŷ→渲染图Î→模型再从Î生成代码ŷ′,往返验证。

奖励是代码一致性奖励,两个指标:
一个是Token编辑距离TED:不同于字符级别的匹配,采用领域特定的词法分析器L将LATEX源码解析为语法token,然后计算token流之间的扩展编辑距离(EED),看语法结构像不像;
一个是CrystalBLEU:为减轻由LATEX语法引起的模板文本膨胀【普通BLEU会被LaTeX的模板代码(比如\documentclass{standalone}、\usepackage{tikz}这类重复语法)“作弊”,两段代码哪怕核心逻辑不一样,只要模板部分高度重合,BLEU分就会虚高】,所以,从语料库中抑制一组预先计算好的高频N元组,只统计非模板n元组的匹配次数和只统计非模板n元组的总出现次数,这样把把模板代码的贡献完全删掉,只衡量真实业务逻辑代码的匹配度,完全不受LaTeX模板的干扰,精准反映语义一致性。
这些其实都是算法规则的设计trick【算法应该关注的东西】
因此,整体看下来,其中的数据思路看起来下是很舒服。
参考文献
1、https://arxiv.org/pdf/2603.22455
2、https://arxiv.org/pdf/2604.06079
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。
