 夜雨聆风
夜雨聆风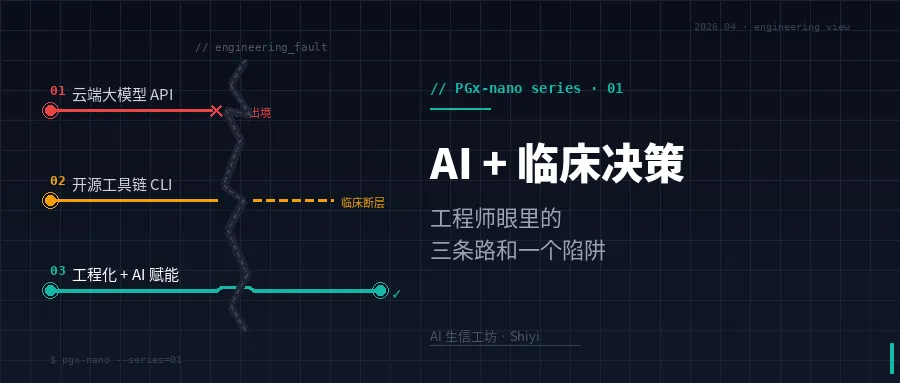
—— 写在 PGx-nano 上线前的一点判断
一份没人看完的 40 页报告
最近团队在打磨一条 PGx(药物基因组学)流程。跑完 PharmCAT 官方 pipeline,出来一份报告——40 页 PDF。
CYP2D6、CYP2C19、SLCO1B1 每一条都写得明明白白,CPIC 原文、FDA 标签、DPWG 建议一样不缺。技术上完全达标,工具也都是国际上最硬的那几个。
然后我们停了下来,问了自己一个问题:
如果我是临床医生,哪一条能让我今天下午改处方?
答不上来。
不是报告不对——工具跑出来的结果是正确的。是这份报告在临床工作流里,根本没有位置。医生不会翻 40 页 PDF,药师没时间啃英文指南,信息科拿不到结构化字段回写 HIS。
报告是交付出来了,但它没被"用"上。
这份 40 页 PDF 是我们反复看到的一个缩影——工程链路跑通了,临床链路没接上。也是接下来这篇文章想聊的起点。
接下来三年,"AI+临床决策"会是医疗 IT 的主战场。我见过的方案大体分三条路,走到今天每条都暴露出自己的问题。更要命的是一个几乎没人认真讨论的陷阱——这个陷阱让大多数"AI+临床"项目死在 Demo 阶段。
这是我做 CellInsight-AI、BioAgent、以及现在做 PGx-nano 这一路走来,最深的一点判断。
第一条路:云端大模型 API 派
把 Claude Opus / GPT-4o / Gemini 的 API 接过来,做一个聊天框,贴上"AI 临床助手"的标签。
这是最快的路。几百行代码就能跑起来一个看上去很像样的 Demo:医生输入症状,AI 给出诊断建议;医生贴进报告,AI 解读。近两年医疗 AI 展会上大半的产品是这条路。
优势:推理能力最强,无需自己训模型,迭代快。
问题也最硬:
- PHI 不能出境,更不能出医院防火墙。
这不是口号,是《医疗机构病历管理规定》和等保三级的硬线。把患者数据发到境外云 API——法律风险和医院声誉风险都无法对冲。即便是国内云,三甲医院信息科的脸色自己体会。 - 断网即废。
医院网络断一小时不是新闻,急诊/ICU 场景容不下"服务暂时不可用"。 - 成本不可控。
按 token 计费,Demo 好看,规模化就是吞金兽。10 家医院每天 100 次调用,一年的 API 账单能吓醒 CFO。 - 审计几乎做不了。
第三方 API 的请求/响应链路在别人那里。出了医疗事故去查证,你能拿到的证据有限。
这条路适合做 C 端问诊科普、药品说明书解释这类不触 PHI 的场景。真正进到医院业务系统里——它走不通。
第二条路:开源工具链 + 传统生信交付派
这条路是生信工程师的本能选择。PharmCAT、Aldy、pangu、HLA-LA、Clair3……工具已经很强,指南(CPIC/DPWG)也是开放的。按部就班跑流程,出结果。
优势:合规、成本低、结果可控,全链路本地。
问题:它从一开始就没想给医生用。
- 交付物是 CLI 或 Jupyter Notebook。
临床医生打开终端的概率趋近于零。 - 结果是表格和 PDF。
没人在看。(回到开头那份 40 页报告。) - 工具链本身需要生信工程师持续维护。
PharmCAT 要装 Java、Aldy 要编译、pangu 要配 Python、HLA-LA 要二十多 G 的索引。医院信息科接手?大概率在第三天放弃。 - 没有 AI 层。
结果还是那份表格,没人帮医生把"CYP2C19 *1/*2, Intermediate Metabolizer"这段英文术语翻译成行动建议。
这条路对"工具"本身是成立的——但工具 ≠ 临床决策系统。把 CLI 工具当成临床交付物,是这条路的根本误区。
第三条路:工程化 + AI 双栈派
第三条路是前两者的融合:
开源工具链在医院内网跑(合规、本地、可控) web 工程把 CLI 封装成医生能点的按钮(Django / Celery / WebSocket / Docker) AI 层加在中间,负责把工具的输出翻译成临床语言——多后端可切换,本地 Ollama、国内云、境外云,按医院合规级别选 全链路审计——每次 AI 调用、每条结果、每个操作都落日志
听上去不复杂——但真正做进去才知道,它要求的是一个几乎没人具备的复合能力栈。这就是下面要说的陷阱。
一个陷阱:工程化断层
我和国内二十多家医院、科研机构打过交道。每一家都说"我们要做 AI+ 临床决策",每一家都卡在同一个地方。
不是算法不够好。不是大模型不够强。不是数据不够多。
是——没人能同时干完三件事:
- 生信
:知道 PharmCAT 和 Aldy 为什么要交叉验证 CYP2D6、知道 Seurat 和 Scanpy 的各种坑、知道哪条 CPIC 建议在中国人群里要打折扣。 - web 工程
:Django 的 ORM、Celery 的任务队列、WebSocket 的断线重连、Docker 的离线打包、PostgreSQL 的索引、前端的流式渲染。 - AI 工程
:多模型路由、Prompt 工程、流式输出、Function Calling、审计日志、Token 预算、上下文窗口管理。
生信同行有第 1 点,缺第 2 和第 3。医院信息科有第 2 点,缺第 1 和第 3。AI 创业团队有第 3 点,但九成人连 VCF 文件长什么样都没见过。
这就是工程化断层。
断层的结果是:
- 生信交付完就走人。
脚本跑完、PDF 发出,觉得任务完成。留给医院的是一堆没人能按的按钮。 - 信息科接不住。
拿到开源工具包,编译半个月装不上,Celery 任务跑崩了没人会看日志。 - AI 团队做 Demo 完美。
舞台上惊艳,一上生产环境 PHI 就违规、断网就瘫痪、token 预算一周烧光。
每一段都觉得自己做完了。每一段中间都有裂缝。最后裂缝里掉下去的是医生和患者——回到开头那份 40 页没人看完的报告。
怎么跨过这个断层
过去一年我们在连续走这条复合路线。三个产品,同一个方法论:
CellInsight-AI(scRNA-seq 自动分析平台)。Django + Celery + WebSocket 做主干,Agent SDK 做 AI 大脑,双路径 Router 分发 QUESTION / SINGLE_STEP / MULTI_STEP。用户上传数据,一句话完成 QC + 细胞注释 + 差异分析 + 可视化。目前 Agent 架构已端到端打通,UI pipeline 还在补。
BioAgent(生信 Agent 平台)。@register_agent 装饰器注册多个生信 Agent,多轮追问通过动态生成 CLAUDE.md 实现,把"多个生信 Agent 协同"这件事做成一个平台。
PGx-nano(药物基因组学 web 平台,即将上线)。本系列的主角。把 PharmCAT + Aldy + pangu + HLA-LA + Clair3 + CPIC/DPWG 十几个工具全部工程化进一个 web 平台,AI 层支持七种后端自由切换——医院要全离线就切 Ollama + Qwen2.5,要最强推理就切 Claude Opus。4 小时从 FASTQ 到医生能看懂的临床级报告。
三件事讲的是同一件事:web 工程化 + AI 赋能 + 生信领域知识,必须是同一批人端到端打通。任何一环外包出去,都会掉入断层里。
陆陆续续我们会把所有产品补齐 AI 功能。
如果你在做 AI+ 临床决策、卡在某一环想聊聊,欢迎公众号后台留言或加我微信。
