 夜雨聆风
夜雨聆风"知之者不如好之者,好之者不如乐之者。" — 《论语·雍也》

想把 PDF、音视频字幕等先统一成 Markdown,再丢进大模型里做摘要、检索或出题。之所以盯死 MD,不全是因为「纯文本好传」,更因为 在 AI 场景里 Markdown 几乎成了一种通用中间语,接口文档、系统提示、工具返回、RAG 切块与引用,大家都习惯用「带轻量结构」的文本,而 MD 正好卡在比 HTML 省 token、比裸文本多层级的位置上。我试过微软开源的 markitdown[1],并在自家场景里接成 内网工具服务。这篇整理 实现原理、各格式大致在依赖什么 外部能力,以及 Fork + 同步 Web API + GitHub Actions 镜像 + Nginx 反代、仅 pracmo-server 调用 的落法。
项目介绍
MarkItDown 是微软 AutoGen 团队维护的轻量 Python 库,把多种文件与网页内容转为 Markdown,面向 LLM 与文本分析流水线,而不是面向「人类可印刷级」排版还原。设计上与 textract[2] 类似,但更强调在 Markdown 里保留标题、列表、表格、链接等结构。
• 仓库:https://github.com/microsoft/markitdown • 语言与版本:Python ≥ 3.10 • 包结构:核心在 packages/markitdown;另有官方 markitdown-mcp(MCP 服务)、markitdown-ocr(嵌入图 OCR 插件)、markitdown-sample-plugin(插件示例)
核心依赖(pyproject.toml):beautifulsoup4、requests、markdownify、magika、charset-normalizer、defusedxml。各格式能力通过 可选依赖组 按需安装,例如 pip install 'markitdown[all]' 与旧版行为最接近。
为什么先落到 Markdown(尤其在 AI 场景)
不展开玄学,只记几条工程上常碰到的理由:
• 模型侧:公开语料里 MD 极常见,续写、摘要、按标题切块时,行为往往比「一团 HTML」或「版式复杂的二进制导出」更稳。 • 接口与提示词:很多 API 示例、Agent 工具返回、开发者文档默认就用 Markdown 块;你的内容若是 MD,和上下游拼接时少一层格式扯皮。 • token 与结构:相对 HTML,标签更轻;相对纯文本,又保留了 #标题、表格、列表、链接,方便 RAG 按段引用、做溯源或再加工。• 人眼也可读:同一份 MD 既能给模型吃,也能给人 diff、审阅,调试成本低。
所以 MarkItDown 这类工具的价值,本质是把异构文件尽快对齐到这条「AI 友好」的轴上。
实现原理(源码视角)
1. 整体架构
1. MarkItDown类(src/markitdown/_markitdown.py)是门面:统一入口convert(source),支持本地路径、Path、http(s)/file:/data:URI、requests.Response、以及 二进制流BinaryIO。2. 不写临时文件: convert_stream()要求可 seek 的二进制流;不可 seek 时会读入内存BytesIO。3. 类型推断:结合扩展名、HTTP Content-Type、以及 Magika 对字节内容的识别,生成若干StreamInfo「猜测」;文本类还会用 charset-normalizer 猜编码。4. 转换器链:每个具体格式实现 DocumentConverter(src/markitdown/_base_converter.py)——accepts(stream)判断是否处理,convert(stream, stream_info)返回DocumentConverterResult(字段以markdown为主,text_content为兼容别名)。5. 调度策略:对每种 StreamInfo猜测,按 priority 排序遍历已注册转换器;先接受者先转换。默认可选:PRIORITY_SPECIFIC_FILE_FORMAT = 0(多数专用格式)、PRIORITY_GENERIC_FILE_FORMAT = 10(纯文本、HTML、ZIP 等兜底,数值越大越晚尝试)。register_converter(..., priority=...)可插入插件或覆盖顺序。6. 全局选项:构造或 enable_builtins时可注入llm_client/llm_model/llm_prompt(图片/PPT 等描述)、exiftool_path(元数据)、style_map(mammoth)、以及docintel_*(Azure Document Intelligence,见下文)。7. 插件:通过 setuptools markitdown.plugin入口组懒加载;enable_plugins=True时各插件向MarkItDown.register_converter注册增强型转换器(如markitdown-ocr)。
下图概括从输入到 Markdown 的主路径,以及类型推断、转换器链与可选外部能力的关系。
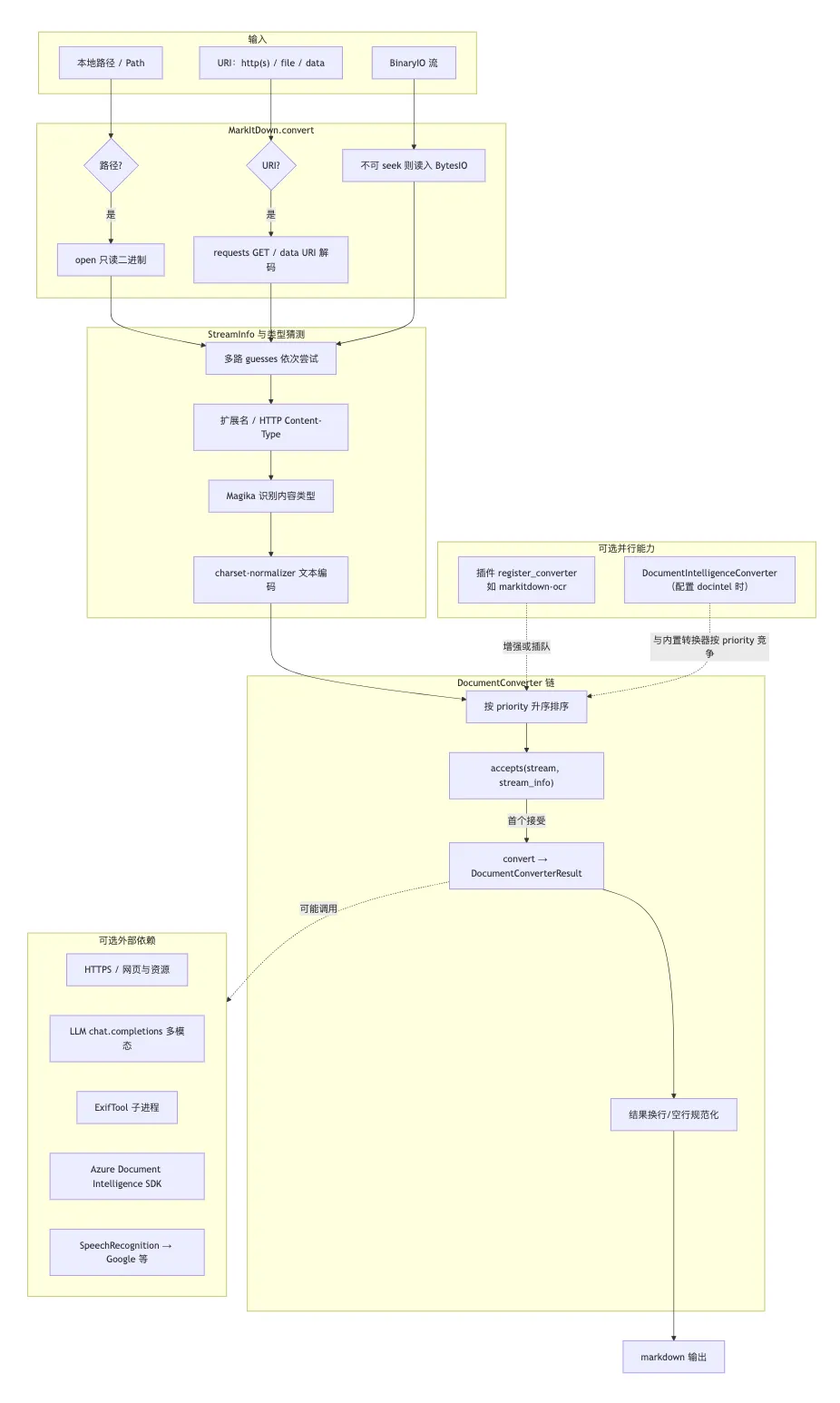
2. 各类型:解析要点与外部依赖
下表只保留 做什么 与 是否/如何依赖外部服务;安装时需哪些 Pip extras 见官方 pyproject.toml 与 README,此处不展开。
| 纯文本 / JSON / Markdown 等 | text/*application/json、.md/.json 等按编码解码;Magika 常能给出 charset | 无 |
| HTML / XHTML(通用网页) | requests),无单独付费接口。 | |
| RSS / Atom(含部分 XML Feed) | ||
| 维基百科页面 | **.wikipedia.org**,抽主内容区 | 无 Wikipedia API |
| Bing 搜索结果页 | 无 Bing API | |
| YouTube 视频页 | ytInitialData,可选字幕 | GET |
| 无 | ||
| Word(DOCX) | 无 | |
| PowerPoint(PPTX) | image_url(data URI)。 | |
| Excel XLSX / XLS | 无 | |
| CSV | 无 | |
| 图片(JPEG/PNG) | 可选exiftool -json -;可选 多模态 Chat Completions。 | |
| 音频 | 可选 ExifTool | |
| ZIP | convert_stream,拼成一篇 MD | |
| EPUB | 无 | |
| Jupyter(IPYNB) | 无 | |
| Outlook(MSG) | 无 | |
| Azure Document Intelligence(可选) | AzureDocumentIntelligenceClient |
关于 XML:无单独的「通用 XML→MD」转换器;RSS/Atom 走 RssConverter;其它 XML 可能被 Magika 判为文本后由 PlainTextConverter 处理,或需改扩展名/类型再转换。
第三方插件(非核心仓库内逻辑,但与生态相关):markitdown-ocr 在 PDF/DOCX/PPTX/XLSX 内对嵌入图做 OCR,依赖与 ImageConverter / PPTX 图相同:OpenAI 兼容 chat.completions 多模态;无 Tesseract 等本地 OCR 依赖。
3. markitdown-ocr 插件(与「图片 OCR」的差异)
• 独立包 markitdown-ocr:在 PDF/DOCX/PPTX/XLSX 中 对嵌入图片做 LLM Vision OCR,与单张图片的 ImageConverter使用同一套llm_client/llm_model约定。• 无需额外安装 Tesseract 等二进制 OCR;未配置 LLM 时插件仍可加载,但会静默退回内置转换器。
使用方法(命令行与 API)
安装
pip install 'markitdown[all]'# 或按需:pip install 'markitdown[pdf,docx,pptx,xlsx]'CLI
markitdown path.pdf -o out.mdcat path.pdf | markitdownmarkitdown --use-plugins path.pdf # 启用插件时需配合插件所需参数(见各插件 README)Python
from markitdown import MarkItDownmd = MarkItDown(enable_plugins=False)result = md.convert("file.xlsx")print(result.markdown) # 或 result.text_content传入 llm_client / llm_model 可启用图片/PPT 等描述;docintel_endpoint 可走 Azure 文档智能。
我的实践:内网 md-server 工具服务
在官方 MarkItDown 之上,我采用 自研同步 Web API 落地,而不是使用官方 markitdown-mcp 对外暴露。流程如下。
1. Fork 上游并拉分支:在微软 markitdown基础上维护自己的分支,增加 同步 HTTP API(例如 FastAPI/Flask):请求侧以 OSS 上的文件 为输入(服务端按 URL 或 SDK 拉取对象到内存/临时文件),再调用MarkItDown.convert_stream/convert,返回 Markdown 正文。API 本身不做排队与限流,只负责「拿到字节 → 转 MD」。2. 镜像构建:用 GitHub Actions 流水线构建 自有 Docker 镜像(包含所选 extras、可选exiftool等),推送到私有镜像仓库。3. 部署与接入:在 独立机器/服务单元 md-server上运行该容器;前面用 Nginx 反代注册为 内网上游(仅监听内网或 VPN,不对外绑定公网)。4. 调用关系:不对外透出;仅 pracmo-server 作为调用方,通过 Nginx 内网地址访问 md-server。排队、限流、重试、超时策略 全部在 pracmo-server 侧统一控制,md-server 保持 无状态、纯工具 角色。
架构关系如下。

说明:若 OSS 拉取发生在 pracmo-server(拿到临时 URL 或字节再 POST 给 md-server),图中「S → O」可改为「Q/API → O」与「pracmo → md-server 带文件体」;核心是 md-server 只转格式,队列与 OSS 策略在 pracmo 收口。
小结
MarkItDown 通过 Magika + 多路 StreamInfo + 可优先级排序的 DocumentConverter 链 实现「一种输入、多种格式、统一 Markdown 输出」。在 AI 应用里,这一步往往是在对齐通用中间表示——Markdown 易与模型、工具链、人机协作同时兼容。我的部署上,md-server 只做同步转换与内网暴露;OSS 编排、排队与风控 放在 pracmo-server,与官方 MCP 公网方案解耦。复杂版式或扫描件如需加强,仍可在镜像中按需启用 Azure Document Intelligence 或 markitdown-ocr + 多模态模型。
璞奇启示
1. 学习/练习类产品里,把材料先收敛到 Markdown,再交给模型生成摘要或出题,等于在「多模态、多来源」和「可编排的文本流水线」之间搭一座桥;优先看 标题、表格、链接 能否保留,而不只是抽成纯文本。 2. 排队与限流 放在业务服务(pracmo-server),转换服务只做 无状态同步,扩容和故障隔离会简单很多;与璞奇里「练习与内容编排」集中在业务层,底层工具只管能力,是同一套思路。
引用链接
[1] markitdown: https://github.com/microsoft/markitdown[2] textract: https://github.com/deanmalmgren/textract

