 夜雨聆风
夜雨聆风本文讲的是下Qwen3VL-8B的GGUF版本下载和安装 你不一定按着我的版本下,我只是用来举例罢了。 如图这个版本
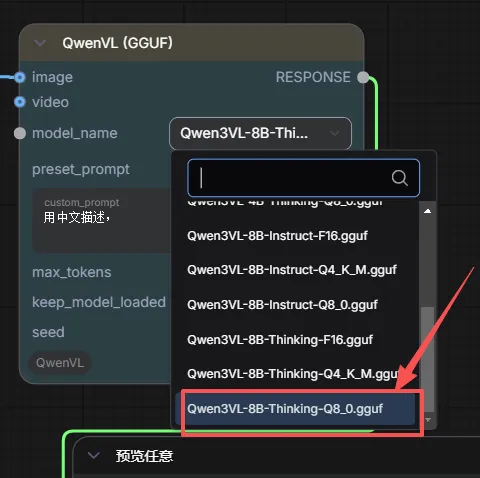
博主电脑是rtx2000ada 16g 运行一次 差不多用23秒
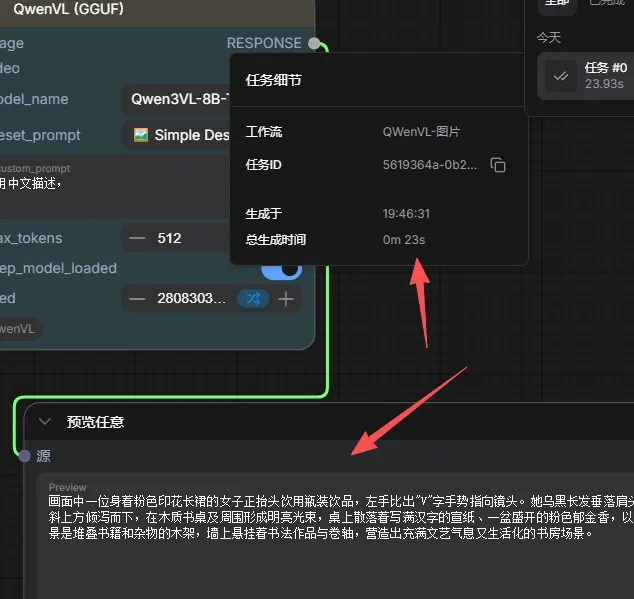
确认前置条件:已成功运行基础版 qwenVL 工作流(若未安装,先参考作者上一篇教程)。
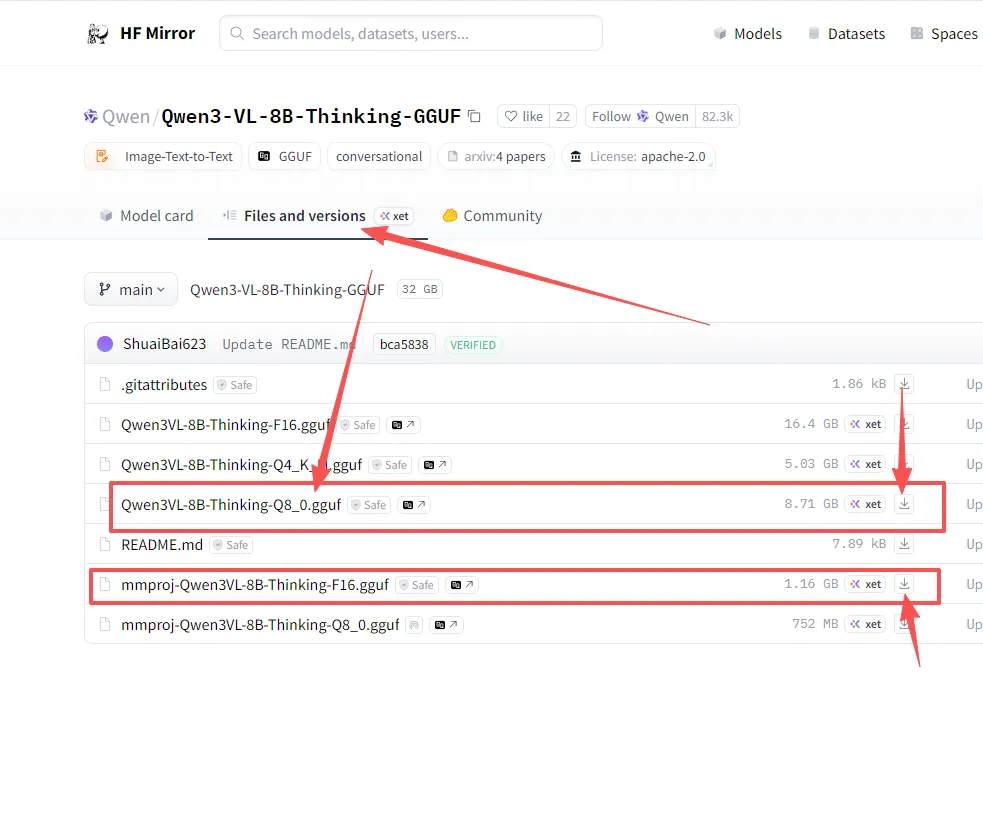
下载 GGUF 模型文件:访问
https://hf-mirror.com/Qwen/Qwen3-VL-8B-Thinking-GGUF→ 进入Files and versions页面 → 下载 所有文件(包括主.gguf和mmproj-*.gguf,后者极易遗漏)。放置到正确目录:在 ComfyUI 的
models文件夹下依次创建LLM\GGUF\Qwen\Qwen3-VL-8B-Thinking-GGUF\→ 将下载的两个文件放入该文件夹(若下载其他版本,最后一层文件夹名对应改为版本名)→ 重启 ComfyUI。替换节点并运行:在空白处右键 →
AILab→QwenVL→QwenVL(gguf)拖入工作流 → 连接好上下游节点 → 选择刚下载的模型版本 → 输入中文提示词(如“请用中文描述”)→ 点击运行。若报错,查看左侧控制台日志,常见原因:遗漏mmproj文件或目录放错。
一下表格是博主从网上收集整理得来, 不能保证内容的100%准确性, 你需要自己去核实
| 4B vs 8B | ||
| Instruct vs Thinking | ||
| F16 vs Q8_0 vs Q4_K_M |
| Qwen3VL-4B-Instruct-F16.gguf | |
| Qwen3VL-4B-Instruct-Q4_K_M.gguf | |
| Qwen3VL-4B-Instruct-Q8_0.gguf | |
| Qwen3VL-4B-Thinking-F16.gguf | |
| Qwen3VL-4B-Thinking-Q4_K_M.gguf | |
| Qwen3VL-4B-Thinking-Q8_0.gguf | |
| Qwen3VL-8B-Instruct-F16.gguf | |
| Qwen3VL-8B-Instruct-Q4_K_M.gguf | |
| Qwen3VL-8B-Instruct-Q8_0.gguf | |
| Qwen3VL-8B-Thinking-F16.gguf | |
| Qwen3VL-8B-Thinking-Q4_K_M.gguf | |
| Qwen3VL-8B-Thinking-Q8_0.gguf |
8B对应我们之前的4b版本反推能力就上不止几个台阶
越高当然越好,对于个人而言,你显卡刚好跑的动的是刚刚好
拿Qwen3-VL-8B-Thinking-GGUF来举例
点开下面网址
https://hf-mirror.com/Qwen/Qwen3-VL-8B-Thinking-GGUF
然后你会看到右边目前有3个版本
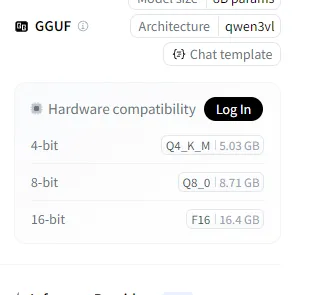
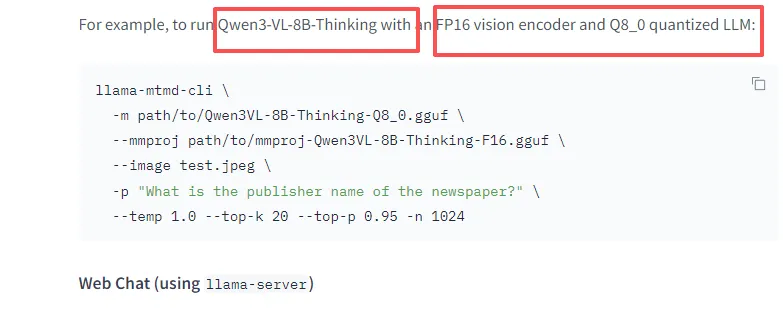
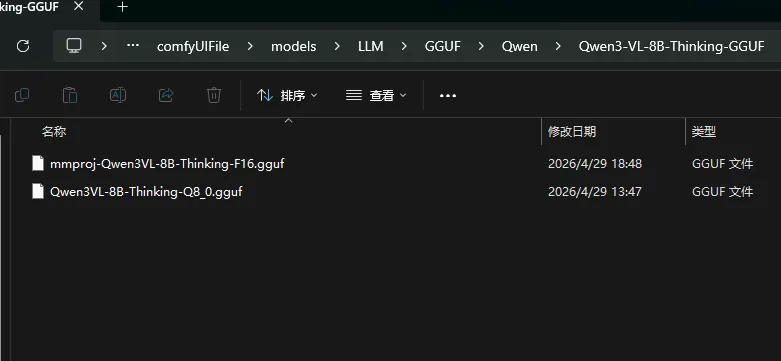
本地存放路径是这样的, \models\LLM\GGUF\Qwen\Qwen3-VL-8B-Thinking-GGUF\
是在comfyui安装路径往下看找到models文件夹
看看里面有没有LLM文件,没有你就新建LLM文件夹,
在点进去新建GGUF文件夹
在点进去新建Qwen文件夹
在点进去新建跟你下载的gguf版本一样的名字的文件夹Qwen3-VL-8B-Thinking-GGUF
你下的如果是Qwen3-VL-8B-Instruct-GGUF版本你最后那个文件夹记得改名字
然后把2个文件放进去
重启comfyUI记得哈!!!!
至于这个文件夹是在
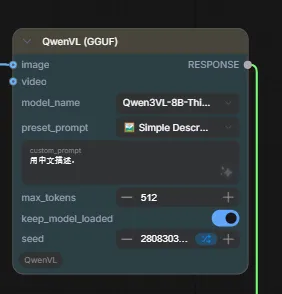
鼠标右键添加节点
AILab
QwenVL
QwenVL(gguf)
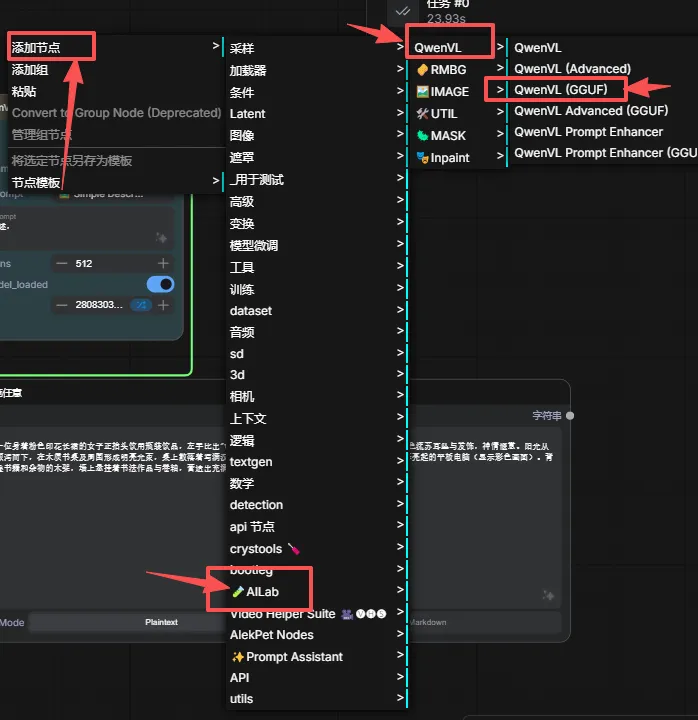
你拖进来后连下线
选下版本就可以了
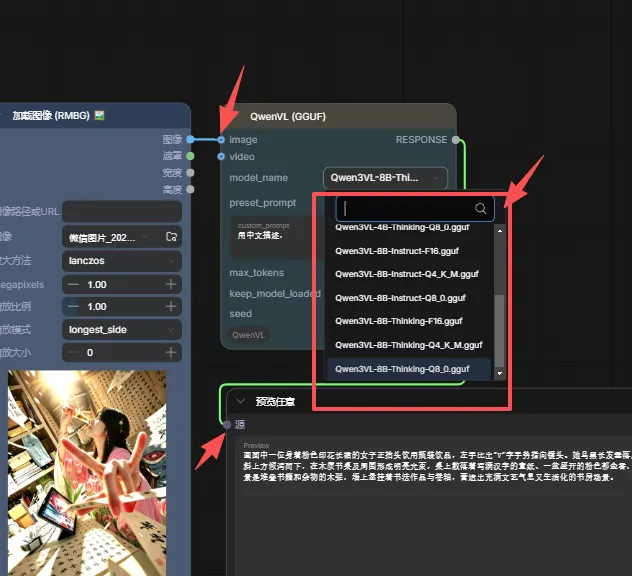
点击运行就可以了,
他是支持中文提示词的,
所以你可以提示框那边打“请用中文描述”
你运行的时候记得打开左侧控制台 他日志里面会显示你啥东西没下载 或者你模型位置是不是放错了
你看的可能这篇没多长, 单单放错目录和还要下一个mmproj-Qwen3VL-8B-Thinking-F16.gguf 关这两条,就已经是卡了我一天 网上写关于安装教程的博主又少 都是写使用教程的 所以且看且珍惜。
雪狼之夜ps:既然都看到这行了,不如给个3连,亲~~~
☟
