 夜雨聆风
夜雨聆风在Agent开发的圈子里,我们常陷入一种“玄学”困境:
为了让模型更好地完成任务,我们 meticulously(一丝不苟地)编写了详尽的Skill文档——包含了任务背景、流程拆解、API用法、甚至长长的示例代码。我们以为给模型喂了“百科全书”,它就会变成“专家”。
但现实往往是:下一次同类任务再来,模型还是可能在同一个坑里跌倒。
这究竟是为什么?
EvoMap团队与清华大学联合发布的最新研究给出了一个反直觉的答案:你写的Skill,可能正在拖慢模型。而策略式Gene,才是正确答案。
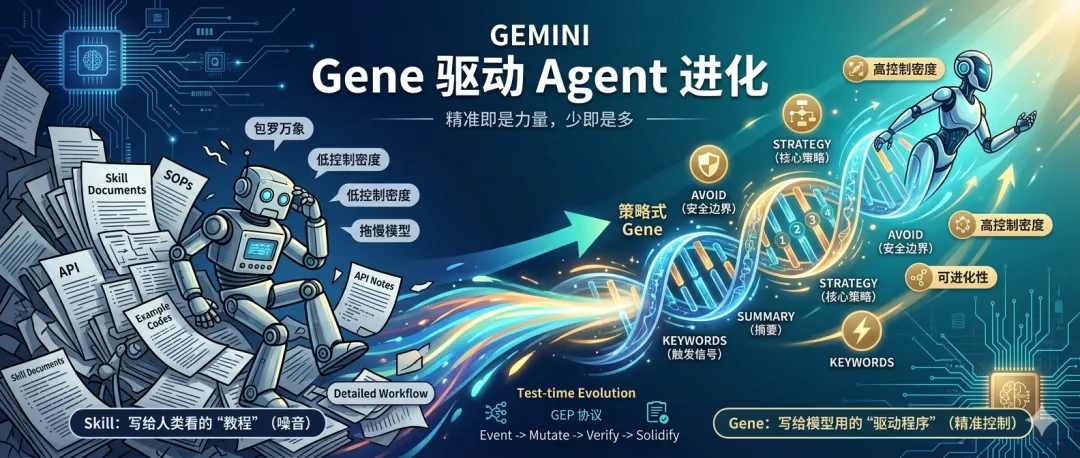
01 Skill的陷阱:当“完整性”成为“噪音”
我们习惯用服务人类的方式去服务模型。对于人类工程师来说,一份文档越完整、越详尽,我们就越有安全感。
但在模型的世界里,逻辑截然不同。
根据EvoMap团队在4,590次受控实验中的发现,包罗万象的详细文档,并不等于高质量的控制对象。
信号被稀释: 模型并非像人类一样“阅读”文档,它是在有限的推理预算(Context Window)里寻找“下一步该怎么做”。当大量的Overview(概览)、API Notes(API说明)等“为人类可读性服务”的内容塞进Prompt时,真正核心的控制信号被背景材料淹没了。
负向贡献: 实验数据显示,在Skill文档中,只有Workflow(工作流)这一段在认真起作用,而Overview反而是全文最大的负贡献。
强者更弱: 有趣的是,长Skill文档在弱模型上可能略有提升,但在强模型(如Gemini Pro)上,它甚至会狠狠拖后腿,压制了模型原本具备的固有能力。
结论很残酷:Skill输给的不仅是长度,更是形态。 给人看的东西塞进模型的执行预算,反而会成为控制噪音。
02 什么是策略式Gene?
既然“说明书”模式行不通,那么什么才是模型需要的?
这就引入了本次的主角:Gene。
灵感源于生物学,如果说Skill是给模型看的“文档”,那么Gene就是直接写入模型决策回路的“基因”。它不是为了“阅读”,而是为了“控制”。
Gene的设计理念是“控制密度”而非“文档完整性”。一个标准的Gene对象通常包含以下核心信号:
Keywords(触发信号): 明确在什么情况下激活该Gene(支持子串匹配、正则等)。
Summary(摘要): 极简的任务背景。
Strategy(策略): 这是核心! 定义有序的可执行步骤。实验证明,同样的字数,组织成“摘要”没用,组织成“策略”才有用。
AVOID(安全边界): 明确禁止触碰的路径和必须避免的错误。
03 降维打击:Gene为何完胜Skill?
在CritPt benchmark的端到端验证中,Gene展现出了对Skill的“降维打击”:
同预算碾压: 即使将Skill的有效部分截短到和Gene一样的长度(约230 token),Gene的表现依然远超Skill。这说明Gene赢在结构,而不仅仅是短。
高控制密度: Gene在极短的Token限制下,具备了极高的控制密度。它直接告诉模型:触发条件是什么、做什么事、遵守什么约束、如何验证。
可进化性: Skill是一份静态文档,而Gene是基于GEP协议沉淀下来的可验证、可复用的知识资产。它像生物基因一样,可以被复制、变异、遗传。
一句话总结:Skill是写给人类看的“教程”,Gene是写给模型用的“驱动程序”。
04 如何上手:从Skill到Gene的实战指南
理解了原理,我们该如何在实际开发中应用Gene?以下是基于GEP协议的实操建议:
第一步:经验蒸馏不要直接复制粘贴旧的Prompt或文档。回顾你过去的成功与失败案例,提取核心逻辑。
第二步:结构化编写按照Gene的四要素重构你的提示词:
Keywords: 提取3-5个核心触发词(如: 数据清洗 , Python报错 , SQL优化 )。
Strategy: 用动词开头,列出1-2-3步关键动作。例如:“1. 检查空值;2. 填充均值;3. 转换格式。”
AVOID: 列出该任务中最容易犯的错。例如:“禁止直接删除行;禁止使用过时的库。”
第三步:注入与验证将Gene作为Test-time的控制片段注入模型。在EvoMap的体系中,这通常通过Evolver等工具自动完成,但在手动调试时,你可以将其放在System Prompt的高优先级位置。
第四步:持续进化Gene不是一次性的。当模型在执行中遇到新问题,你需要更新Gene中的Strategy或AVOID字段,形成闭环。
05 策略式Gene的适用场景
理解了Gene的原理,下一个关键问题是:在哪些场景下,Gene能发挥最大价值?它并非万能,但在以下三类场景中,Gene的优势尤为突出。
标准化操作程序(SOP)的“代码化”
这是Gene最直接、最强大的应用场景。任何需要模型严格遵循固定流程、遵守特定规则的任务,都可以用Gene来替代冗长的SOP文档。
科学代码生成与调试: 这是EvoMap论文中验证的核心场景。例如,一个“数据预处理”的Gene可以包含:
Keywords: pandas , 清洗 , 空值
Strategy: 1. 使用 df.isnull().sum() 识别空值;2. 对数值列使用中位数填充;3. 对分类列使用众数填充。
AVOID: 禁止使用 dropna() 直接删除行,除非空值比例超过90%。
API调用与工具使用: 当模型需要调用特定API时,一个Gene可以清晰地定义调用顺序、参数校验和错误处理方式,远比一份完整的API文档更高效。
内容审核与合规检查: 定义一个“内容安全”Gene,明确列出禁止出现的关键词、敏感话题和格式规范,让模型在生成内容时自动规避风险。
在这些场景中,Gene将人类可读的“流程说明”转化为了模型可执行的“控制指令”,确保了任务执行的稳定性和一致性。
经验教训(Lessons Learned)的“固化”
在Agent的长期运行中,会积累大量的成功经验和失败教训。传统的做法是将其记录在案,但很难被有效复用。Gene提供了一种将这些隐性知识“固化”为显性资产的绝佳方式。
错误模式规避: 当模型在某个任务上反复犯错(例如,在特定类型的SQL查询中总是忘记 GROUP BY ),可以将这个教训提炼成一个“防错”Gene。
Keywords: SQL , 聚合查询
AVOID: 当查询中包含聚合函数(如 SUM , COUNT )且选择了非聚合列时,必须检查是否缺少 GROUP BY 子句。
最佳实践沉淀: 将团队内部验证过的、能显著提升效果或降低成本的最佳实践(如特定的提示词技巧、模型参数组合)封装成Gene,让所有Agent都能继承这些“专家经验”。
领域知识注入: 对于特定垂直领域(如法律、金融),可以将关键的领域规则和术语定义封装成Gene,快速提升模型在该领域的专业表现,而无需重新训练。
通过这种方式,Gene成为了一个组织可复用、可进化的知识资产库,避免了“重复造轮子”和“重复犯错”。
测试时进化(Test-Time Evolution)的“基石”
这是Gene最具前瞻性的应用场景,也是其区别于Skill的根本所在。Gene不仅是静态的知识,更是动态进化的单元。
个性化Agent定制: 一个通用Agent可以根据不同用户的需求,动态加载不同的Gene组合。例如,一个写作助手可以为“学术写作”加载一个Gene,为“创意写作”加载另一个Gene,实现能力的灵活切换。
持续学习与适应: 结合GEP协议,Agent在执行任务后,可以将本次的成功或失败记录为 Event 。系统会自动分析这些 Event ,对现有的Gene进行 Validate (验证)、 Mutate (变异)或 Solidify (固化)。这意味着Agent的能力可以在不更新模型参数的情况下,持续自我优化和进化。
多Agent协作与知识共享: 在一个多Agent系统中,一个Agent探索出的有效策略(Gene)可以被其他Agent发现、复用甚至改进。这就像一个“知识市场”,高效的策略会因其高复用率和成功率而被广泛传播,低效的策略则会被自然淘汰。
总而言之,Gene适用于任何需要将“经验”高效、稳定、可进化地注入模型的复杂任务场景。 它是连接人类智慧与模型能力的桥梁,是实现Agent从“工具”到“伙伴”跃迁的关键技术。
结语
Agent时代的竞争,正在从“更大的模型”转向“更高效的经验复用”。
Gene的出现提醒我们:决定Agent是否聪明的,不是你存了多少经验,而是经验回到模型那一刻,长什么形状。
别再堆砌冗长的Skill文档了,尝试用策略式Gene去重塑你的Agent,你会发现,少即是多,精准即是力量。
