 夜雨聆风
夜雨聆风点击下方卡片关注"东哥说AI",持续分享大模型应用实战经验和好玩AI项目。
说实话,每次遇到几十上百页的PDF要整理,我都头大。
扫描版的论文、带表格的财报、混排公式的技术手册,传统OCR处理起来不是慢得像老牛拉车,就是把公式认成乱码。更烦的是,前面一页识别错了,后面几页跟着全跑偏,跟小时候抄作业抄串行一模一样。
那问题到底出在哪?
一直以来,AI识别文档都像在"打字":从左到右,一个字一个字往外吐。这叫自回归解码,稳妥是稳妥,但天生带着两个毛病。一是慢,文档越长等得越久;二是容易错上加错,前面一个字认错,后面一串都跟着歪。
还有个更隐蔽的问题:这种"逐字念"的方式,让AI太依赖自己学过的语言规律去"猜"后面的内容,而不是老老实实看图说话。遇到排版复杂或者语义不通的表格数据,它就开始"脑补",结果往往离谱。
上个月,上海人工智能实验室和北大联合团队扔出了一个新观点:文档识别,本质上不是"念课文",而是"逆渲染"。
什么意思?一张PDF页面就像一幅已经画好的画。传统做法是一笔一笔去描摹,而新思路是——直接看完整幅画,然后倒推画家是怎么画出来的。
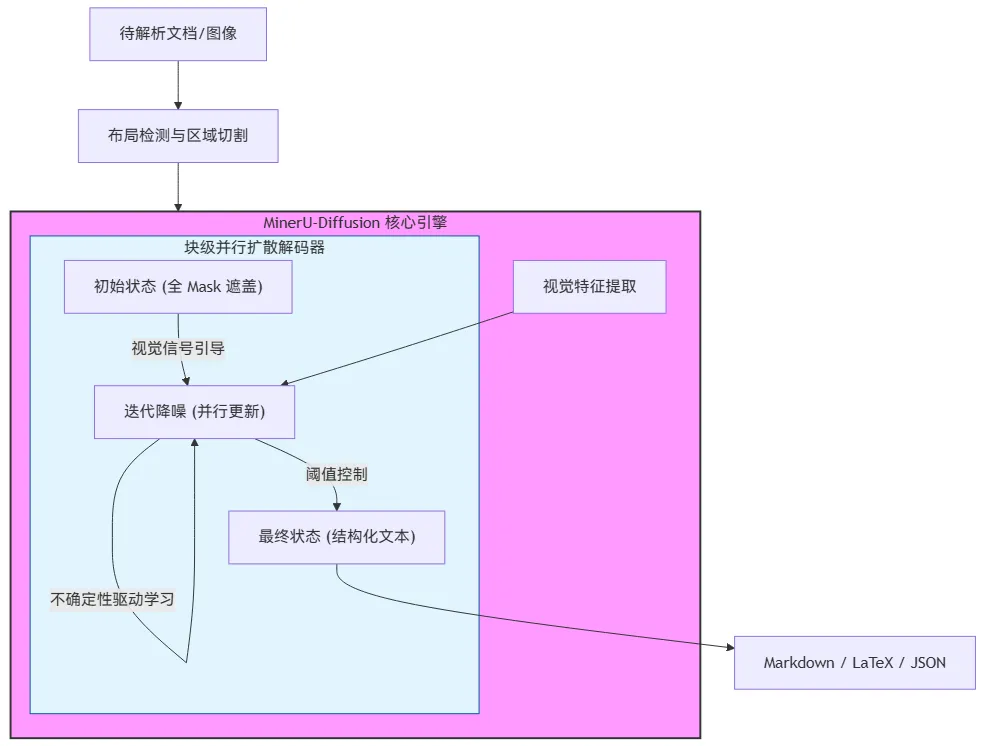
基于这个思路,他们推出了 MinerU-Diffusion。核心改变只有一句话:不再逐字生成,而是整页并行重构。
具体来说,它用的是扩散模型的思路。你可以想象成一种"降噪"过程:一开始页面上的文字全是模糊的马赛克,模型在视觉信息的指引下,一轮一轮地把马赛克擦掉、把文字恢复出来。最关键的是,它不是从左到右挨个恢复,而是整页内容同步推进——哪里看得准就先定下来,哪里还不确定就继续打磨。
这就好比你拼图的时候,不是非得从左上角开始一块一块拼,而是扫一眼整幅图,先把最容易认出的几块放上,再逐步补齐边角。
对于我们这些普通用户来说,这项技术落地后,最直观的感受有三点。
第一,速度快了近3倍。在保持识别精度的前提下,MinerU-Diffusion 的处理速度相比上一代最高提升了3.26倍。以前喝杯咖啡才能处理完的文档,现在可能咖啡还没凉就好了。而且团队还做了很贴心的设计:如果你要精度优先,它能把准确率保持在99.9%的同时提速2倍;如果你要速度优先,3倍加速下准确率也能达到98.8%。这个灵活度在同类工具里并不多见。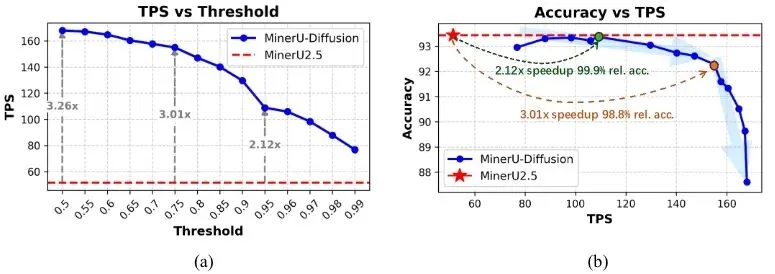
第二,长文档不再"越读越歪"。因为不是逐字依赖前面的结果,前面识别错了也不会像多米诺骨牌一样一路传导。对于动辄几十上百页的学术论文、法律合同来说,这简直是刚需。
第三,更"老实"地看图说话。研发团队专门设计了一个"语义打乱"测试——把文档内容的语义顺序随机打乱,看模型是否还能准确识别。结果传统模型成绩直线下滑,而 MinerU-Diffusion 基本不受影响。这说明它真的是在看图识字,而不是靠"语感"瞎猜。
说到这,可能有朋友会问:那我之前用的 MinerU 是不是要被淘汰了?
其实不用慌。MinerU-Diffusion 更像是在同一条产品线上新开了一条"高铁",原来的"普快"依然有其价值。目前在一些极端复杂的表格识别场景上,传统自回归模型还有微弱优势。但对于大多数日常场景——尤其是需要快速处理大批量文档的情况——扩散解码这条路的优势已经非常明显了。
另外值得一提的是,这个项目完全开源,模型放在了 HuggingFace 上,个人开发者甚至用单张显卡就能跑起来。做知识库搭建、文档数字化、RAG应用开发的朋友,门槛相当友好。
从"逐字念"到"整页看",MinerU-Diffusion 给文档OCR提供了一个全新的解题思路。它不一定在每个场景下都是最优解,但它证明了:有时候跳出固有的顺序思维,问题反而解决得更漂亮。
下次再遇到一堆PDF要处理,或许可以试试这条新赛道。
