 夜雨聆风
夜雨聆风复杂 PDF 不是因为长才让 RAG 失效,而是表格、公式、图表和版式关系被粗暴切碎了。解决方案是结构感知的解析与检索管线。
别再天真切分 RAG 文档
面向复杂文档的布局解析、视觉描述和重排方法

天真切分的问题
技术 PDF 让 RAG 崩掉,并不是因为它们太长。
真正的问题是:大多数 chunking 系统会把文档中最重要的结构撕碎。
一张表格被切成多个 chunk 后,就不再是一张完整表格。一个公式脱离版式后,只剩下一堆符号。一个图表没有标题和上下文,也不再是证据,只是一张孤立图片。
这就是 naive chunking 的后果。
标准提取器通常按页面长度或字符数切文档,然后把内容当作普通文本,从左到右、从上到下读取。问题是,很多 PDF 从一开始就不是为这种线性阅读方式设计的。
结果是,检索系统建立在破碎部件之上。向量数据库返回的不是完整表格行、关联图示或连贯段落,而是一些碎片:半截图注、错位列、孤立方程、被抽离顺序的段落。

解决办法不是把 chunk size 调大一点,而是在嵌入和检索之前就进行结构感知解析,保留布局、坐标和多模态关系。
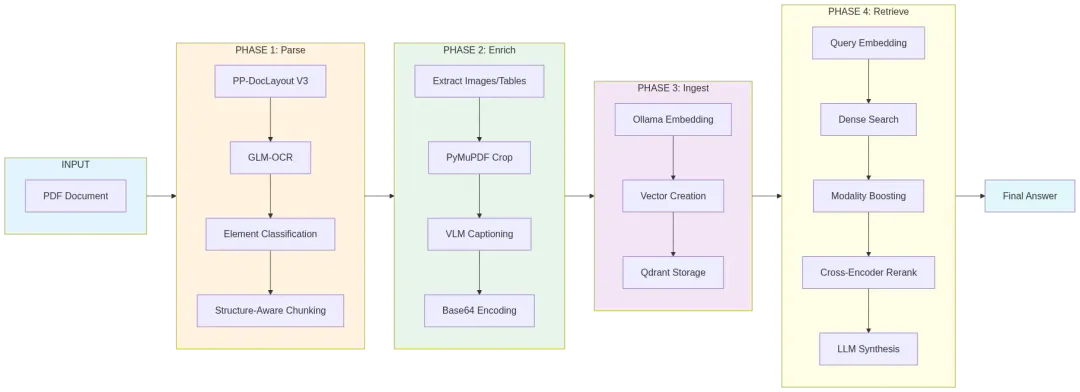
管线概览:从 PDF 到答案的四个阶段
要修复 naive chunking 造成的布局破坏和内容脱节,管线必须从一开始就保留表格、图像和阅读顺序的空间坐标。
这个方案把处理流程分成四个连续阶段:
Parse:解析 Enrich:增强 Ingest:入库 Retrieve:检索
每一步都依赖本地模型处理信息,并把结构化数据或向量记录传递给下一阶段。
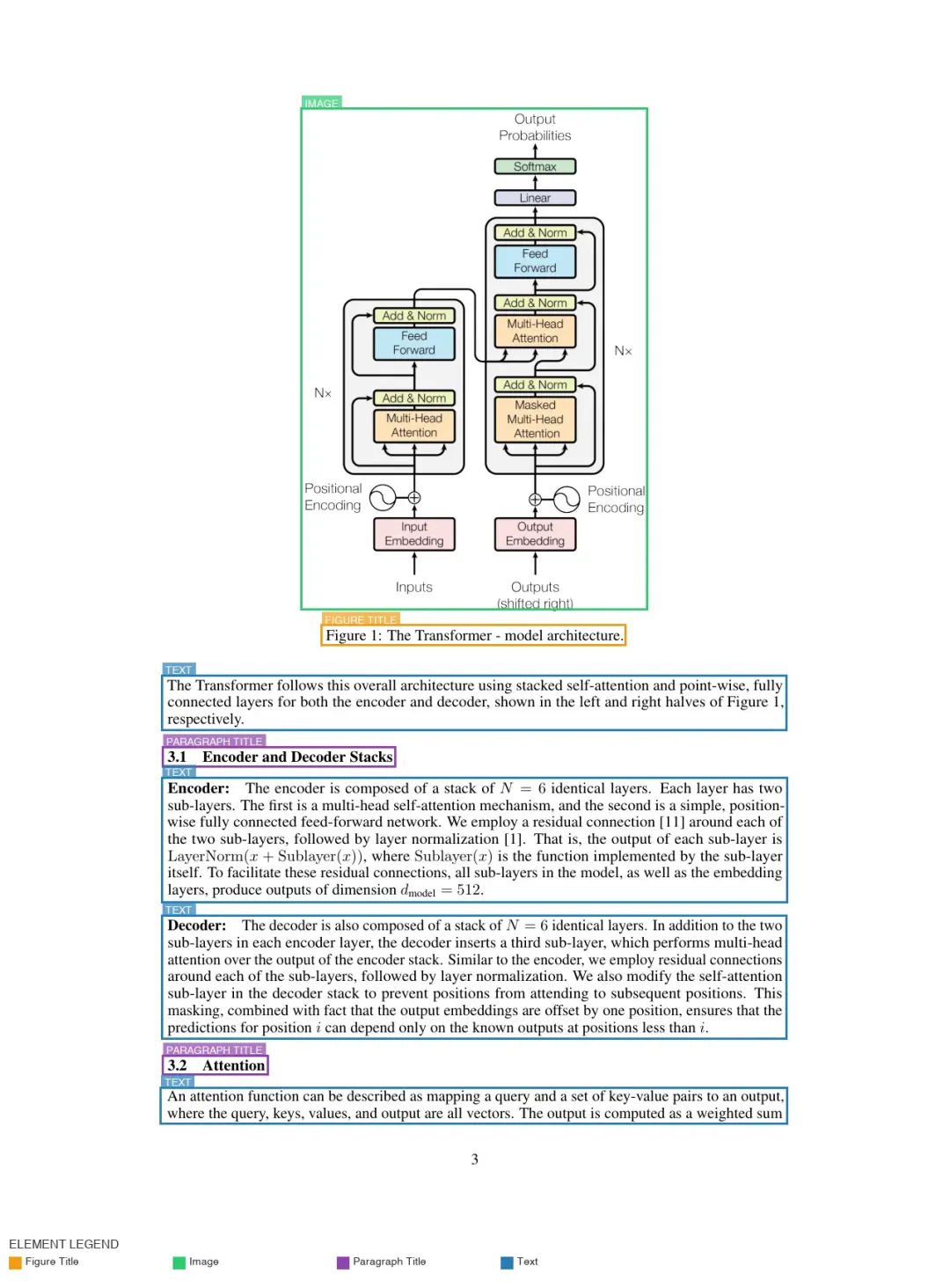
在 Parse 阶段,管线会先识别文档的物理布局,再提取文本。PP-DocLayout-V3 会为表格、图片和段落识别并分配坐标框。确定这些空间区域后,GLM-OCR 再严格从对应坐标内提取文字。
这样可以避免侧边栏文字混入正文段落。这个步骤最终输出一个结构化 JSON 文件,里面包含原始文本,以及每个元素的精确边界框。
Enrich 阶段负责把非文本内容转成可搜索描述。它从结构化 JSON 中提取有边界框的图片、表格和公式,并传给通过 Ollama 本地运行的视觉语言模型 qwen2.5vl:7b。
这个模型会为每个视觉元素生成文本描述。输出结果是增强后的 JSON 文件,包含原始结构坐标、原始文本,以及新生成的图像描述。
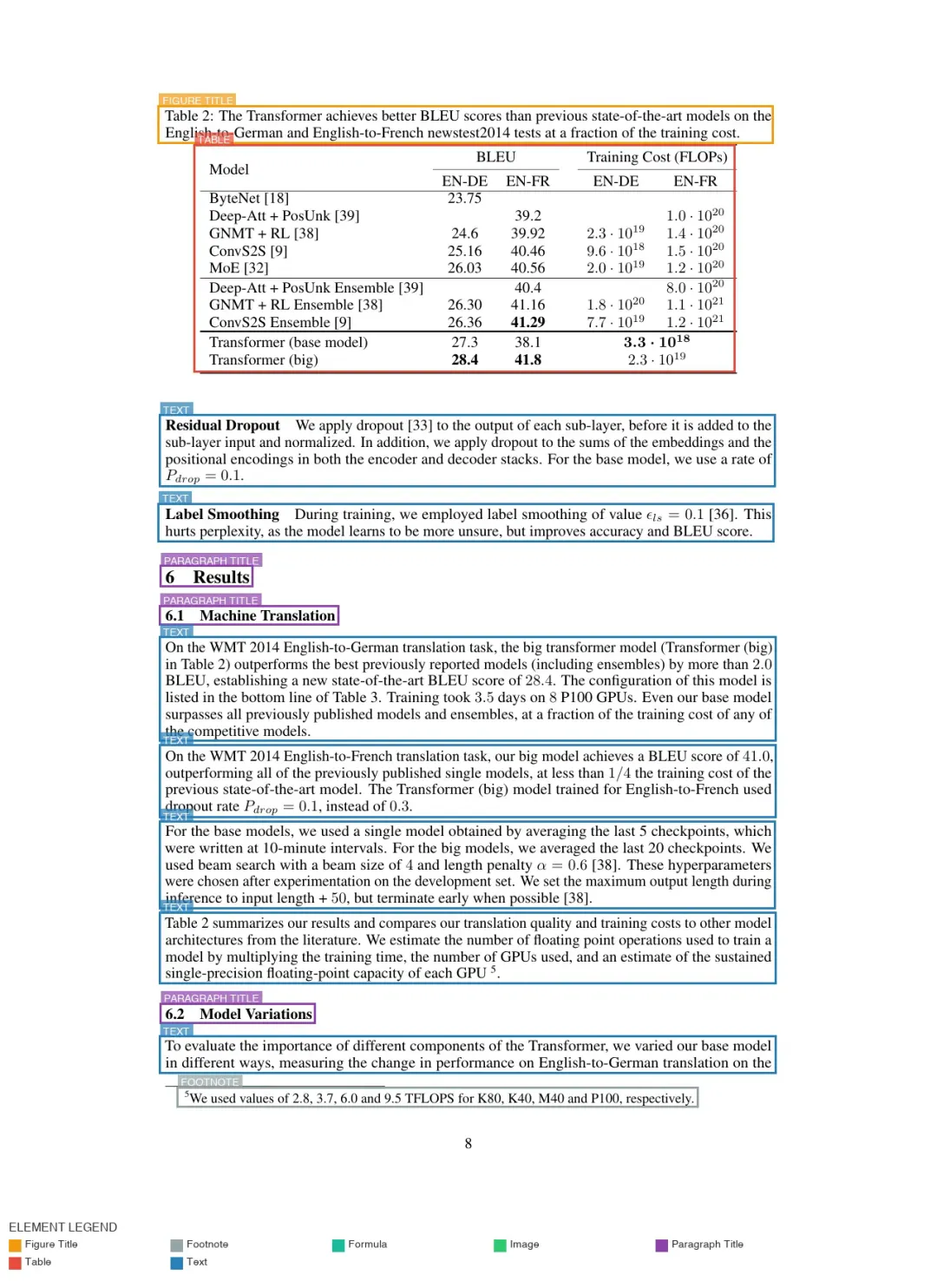
在 Ingest 阶段,增强后的 JSON 文件会被准备入库。qwen3-embedding:4b 模型把文本和图像描述转换为向量嵌入,也就是用于相似度搜索的数值数组。
这些向量会连同原始文本块、边界框坐标一起,作为记录存入 Qdrant。Qdrant 是一个适合本地向量检索的数据库。
当用户提交查询时,Retrieve 阶段开始执行。系统会把问题转换成向量,并在 Qdrant 中搜索相似度最高的匹配项。对非视觉查询,系统会使用 cross-encoder 对初始结果重新评分和排序,过滤弱匹配。
最终,得分最高的文本、图片和表格块会作为排序后的上下文传给后续生成步骤。
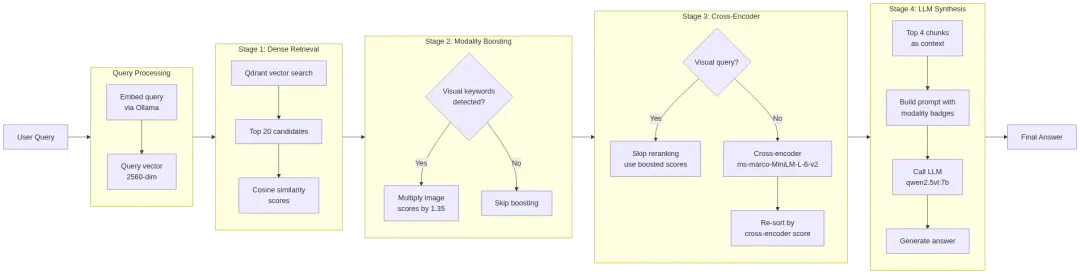
检索机制:模态提升和 cross-encoder 重排
假设用户问:
架构图显示了什么?
或者:
请描述流程图中的 encoder 和 decoder 模块。
标准向量搜索会去找语义相近的文本。但当用户明确要求“图”“图表”“流程图”这类视觉内容时,单纯向量搜索常常失败。
原因是:Enrich 阶段的视觉模型可能把目标图片描述为“一个包含互联节点的系统架构”。用户问的是视觉格式,caption 描述的是内容语义。两者之间存在模态错配。
为了解决这个问题,管线引入了模态提升。
模态提升会在检索时对特定内容类型加分。当管线在查询中检测到 “diagram”“figure”“flowchart” 等视觉关键词时,会自动给数据库中的所有图片块增加 35% 的分数。
在仓库测试中,这个简单调整把正确图片块从第 7 名提升到了第 1 名。


对于文本和表格查询,管线通过 cross-encoder 重排来保证精度。
初始 dense vector search 很快,但只能先取回一个较宽的候选列表,比如前 20 个 chunk。随后系统把这些候选传给 ms-marco-MiniLM-L-12-v2 cross-encoder。
这个模型会直接比较用户查询和每个 chunk 的文本,计算更细粒度的相关性分数。然后系统重新排序,只保留前 4 个 chunk。
在仓库测试里,这个重排机制能稳定处理“model complexities”和“training costs”这类查询,并把原始 TABLE chunk 提升到第 1 名,排在普通文本段落之前。
这个架构有意绕过了视觉查询上的 cross-encoder 步骤。
原因是 cross-encoder 主要训练于密集文本段落。在这个管线的评估里,把它用在视觉查询的短图片 caption 上,反而会降低排序质量。对视觉内容来说,单独使用模态提升效果更好。
评估结果
用测试查询运行这条管线后可以看到:结构感知解析、模态提升和重排组合起来,能够把正确模态稳定推到上下文窗口顶部。

本地运行管线
很多多模态应用默认使用托管 API,但这条管线完全运行在本地硬件上。
这不仅关乎性能,也关乎隐私:敏感文档、嵌入和查询可以留在团队控制的基础设施里,不必流经第三方服务。
本地执行还有另一个好处:系统更容易检查。开发者可以打开 Parse 和 Enrich 阶段产生的中间 JSON 文件,精确查看文档布局、分段方式和图片描述。
结果是,这条管线更容易调试、复现,也更容易被信任。
执行从统一入口 run_all.py 开始。解析和切分逻辑被拆到不同阶段模块中,编排器会按顺序调用 src/phase1_parse.py 到 src/phase4_retrieve.py。
for phase in phases:print(f"\nPHASE {phase}")if phase == 1: run_phase1(pdf_path)elif phase == 2: run_phase2()elif phase == 3: run_phase3()elif phase == 4: run_test_queries()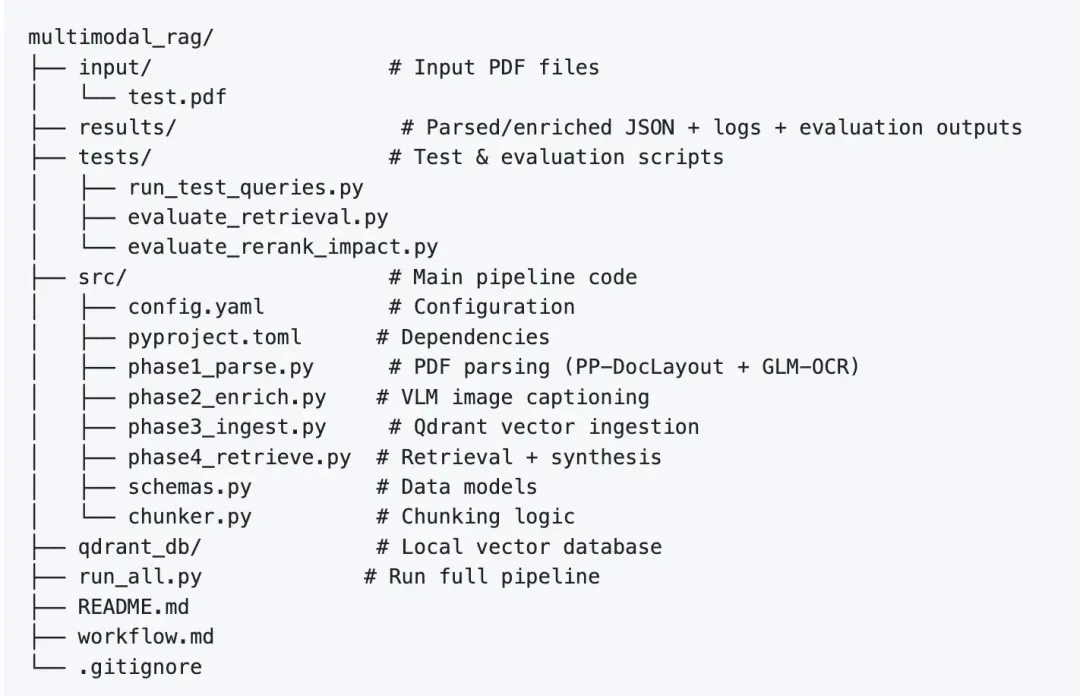
为了支持快速实验,架构把配置和执行逻辑分离。src/config.yaml 保存共享设置。这样,开发者想替换 embedding 模型或指向新的本地数据库目录时,只需要改一个文件。
models:embedding:"qwen3-embedding:4b"llm:"qwen2.5vl:7b"vlm:"qwen2.5vl:7b"cross_encoder:"cross-encoder/ms-marco-MiniLM-L-12-v2"把操作拆到独立文件里,也让修改特定管线行为更安全。例如,检索逻辑集中在 retrieve 阶段模块中。处理查询时,该模块会识别视觉关键词,并以数学方式应用模态提升。
is_vis = bool(set(query.lower().split()) & visual_kw)if is_vis:print("Visual query - boosting image 35%")for hit in results.points:if hit.payload.get("modality") == "image": hit.score *= 1.35这种核心逻辑暴露在普通 Python 里,方便开发者检查和修改。你可以调整视觉关键词列表、修改 35% 的加权幅度,或者尝试新的检索阈值,让系统更贴合自己的文档集。
结论
Native的 PDF 提取丢掉的不只是格式。
它会破坏表格、图像、公式和段落之间的关系,而这些关系正是文档含义的一部分。
结构感知管线会在检索开始前恢复这些关系;再结合视觉描述、模态提升和重排,就能为答案生成提供更准确的上下文。
本地运行则进一步带来可检查、可复现和更适合敏感文件的优势。
自己试试
这个管线的代码已经放在 GitHub 上。你可以克隆仓库,查看执行流程,也可以针对自己的数据集调整模态提升权重。
Explore the Pipeline on GitHub[2]
参考
Sun, X. 等,PP-DocLayout: A Unified Document Layout Detection Model to Accelerate Large Document Understanding (2025), arXiv. https://arxiv.org/abs/2503.17213[3] Zheng, X. 等,GLM-OCR Technical Report (2026), arXiv. https://arxiv.org/abs/2603.10910[4] Bai, S. 等,Qwen2.5-VL Technical Report (2025), arXiv. https://arxiv.org/abs/2502.13923[5] Qwen Team, Qwen3-Embedding: A Text Embedding and Ranking Model Series (2025), GitHub. https://github.com/QwenLM/Qwen3-Embedding[6] Qdrant Team, Qdrant: High-performance, massive-scale Vector Database (2024), Documentation. https://qdrant.tech/[7] Nogueira, R. and Cho, K., Passage Re-ranking with BERT (2019), arXiv. https://arxiv.org/abs/1901.04085[8] Karpukhin, V. 等,Dense Passage Retrieval for Open-Domain Question Answering (2020), arXiv. https://arxiv.org/abs/2004.04906[9] Lewis, P. 等,Retrieval-Augmented Generation for Knowledge-Intensive NLP Tasks (2020), arXiv. https://arxiv.org/abs/2005.11401[10] Ollama Team, Ollama: Run Large Language Models Locally (2024), Documentation. https://ollama.com/[11] PaddlePaddle Team, PP-DocLayoutV3: Layout Analysis for Non-Planar Document Images (2026), Hugging Face. https://huggingface.co/PaddlePaddle/PP-DocLayoutV3[12]
更多内容请参考:
阅读时长:7 min|发布时间:2026-04-27
引用链接: [1] https://ai.gopubby.com/why-naive-chunking-breaks-rag-and-what-to-build-instead-f1cc12e60ecf[13] [2] https://medium.com/@mohitagr18/f1cc12e60ecf?source=friends_link&sk=cbe3c1fca5e196eb8d255b072dcbaac4[14]
引用链接
[1]friend link: https://medium.com/@mohitagr18/f1cc12e60ecf?source=friends_link&sk=cbe3c1fca5e196eb8d255b072dcbaac4
[2]Explore the Pipeline on GitHub: https://github.com/mohitagr18/multimodal_rag_article
[3]https://arxiv.org/abs/2503.17213
[4]https://arxiv.org/abs/2603.10910
[5]https://arxiv.org/abs/2502.13923
[6]https://github.com/QwenLM/Qwen3-Embedding
[7]https://qdrant.tech/
[8]https://arxiv.org/abs/1901.04085
[9]https://arxiv.org/abs/2004.04906
[10]https://arxiv.org/abs/2005.11401
[11]https://ollama.com/
[12]https://huggingface.co/PaddlePaddle/PP-DocLayoutV3
[13]https://ai.gopubby.com/why-naive-chunking-breaks-rag-and-what-to-build-instead-f1cc12e60ecf
[14]https://medium.com/@mohitagr18/f1cc12e60ecf?source=friends_link&sk=cbe3c1fca5e196eb8d255b072dcbaac4
