 夜雨聆风
夜雨聆风你知道训练GPT-4用了多少“教材”吗?
约13万亿个Token。
换个说法:如果把维基百科全部内容读一遍算1份教材,GPT-4读完了 125万份。
再换个说法:一个人不吃不喝不睡,每秒读一个Token,要读完这些数据需要 40万年。
而AI只用了几个月。
这就是数据集的威力——AI的“教材”和“考卷”。
但今天我要告诉你一个更惊人的事实:
高质量公开文本数据,可能在2030年前后耗尽。
AI的“燃料”快没了。那接下来怎么办?
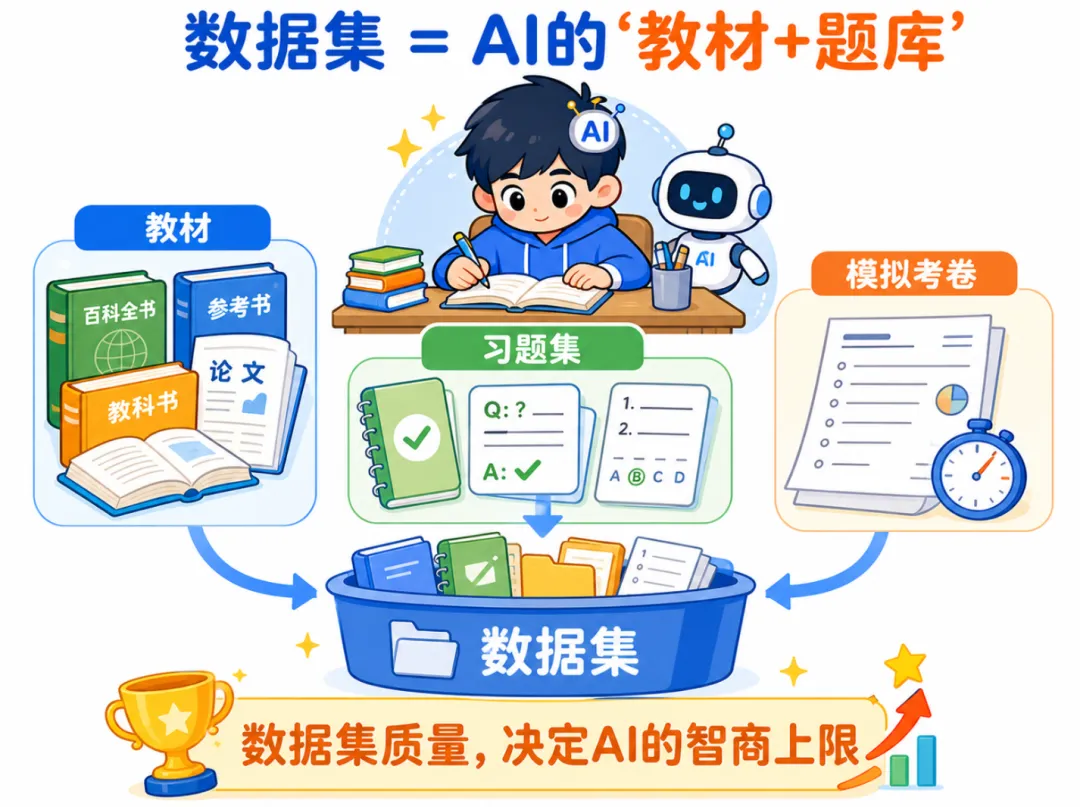
一、一个让你秒懂的比喻:数据集 = AI的“教材+题库”
想象你要培养一个超级学霸。
你需要给他准备:
教材:教科书、参考书、论文、百科全书——让他广泛吸收知识。
习题集:有标准答案的问题,让他练习解题技巧。
模拟考卷:没见过的新题,用来测试他学得怎么样。
数据集就是干这个的。
预训练数据集 = 教材规模最大,来源最杂(网页、书籍、代码、论文)。AI从中学到语言、事实、逻辑、甚至“常识”。
微调数据集 = 习题集高质量、人工标注的问答对。比如“用户问:怎么退订会员?AI答:请进入设置→订阅管理→点击取消”。AI通过模仿这些“标准答案”学会对话格式。
测试集 = 考卷严格保密的样本,绝不混入训练数据。用来评估模型真实能力。如果AI在测试集上表现好,说明它真的学会了,而不是死记硬背了答案。
二、拆本质:数据集为什么是AI的“命根子”?
有一句经典的话:
“No data, no AI. 垃圾进,垃圾出。”
数据集的质量直接决定AI的智商上限。
规模:GPT-3用了3000亿Token,GPT-4用了13万亿Token。规模提升400倍,能力跃升一个台阶。
多样性:如果只用新闻数据训练,AI不懂代码;只用Reddit,AI说话全是梗。
清洁度:垃圾数据(错误、重复、有害内容)会让AI学坏。清洗数据集往往占训练80%的时间。
真实案例:
LLaMA 3 的原始数据量超过100万亿Token,Meta花了几个月写“清洗管道”,过滤掉低质量、重复、有害内容,最终只留下15万亿Token用于训练。去掉的85%,都是“毒教材”。
三、2026年新变化:数据枯竭 + 数据战争
危机一:高质量公开文本数据正在耗尽
研究机构Epoch AI在2024年警告:按照当前AI训练的数据消耗速度,高质量公开文本数据将在2026-2032年间耗尽。
为什么?
互联网虽然大,但高质量内容(维基百科级别)有限。
低质量内容(垃圾邮件、SEO废文、机器生成内容)越来越多。
很多高质量数据是“孤岛”——封存在出版社、企业内部,不公开。
危机二:“数据护城河”正在形成
OpenAI买断《金融时报》的内容许可。
Google与Reddit达成6000万美元/年的数据协议。
国内大厂也在抢购文学网站、学术数据库的独家授权。
就像19世纪抢石油,21世纪抢数据。
应对一:合成数据
让AI自己生成“假数据”来训练自己。微软Phi-3有40%的训练数据是合成的。
应对二:从“多”到“精”
不再盲目堆数据量,而是用更高质量、更精准的数据。比如用“课程学习”思路:先简单数据,后复杂数据。
应对三:多模态数据“捡漏”
文本快用完了,但视频、音频、传感器数据还多得很。用这些数据训练世界模型,可能开辟新天地。
四、那些著名的数据集,背后都是“血汗”
ImageNet:1400万张图,人类手工标注两年
2009年,李飞飞团队从互联网下载了10亿张图片,筛选出1400万张,雇佣了来自167个国家的5万名标注员,一张一张用手画框、贴标签。耗时2年,花费数百万美元。ImageNet开启了深度学习革命,也催生了“数据标注”这个产业。
Common Crawl:800亿网页,但80%是垃圾
这是一个非营利组织定期爬取整个互联网的快照库,免费开放。几乎所有大模型都用过它。但其中大部分是垃圾内容——训练前必须清洗。
**The Pile:高质量“精选集”
EleutherAI(一个开源研究组织)从Common Crawl中筛选出高质量子集,加上学术论文、代码库、法律文书,组成了The Pile(825GB)。很多开源模型(如GPT-J)用它训练。
数据标注的“血汗工厂”
今天,非洲、东南亚、菲律宾有大量数据标注工厂。工人给一张图里的所有物体画框,给一段音频转写文字,给一句话判断情绪……时薪常常不到2美元。
AI吃掉的每一条标注数据,背后都是有人一张一张、一句一句做出来的。
五、数据集和你有什么关系?
帮你识别AI产品的“保质期”如果一个AI产品告诉你用的是“2023年训练的数据”,那它不知道2024年以后的世界——就像拿着过期的地图。
理解AI的偏见来源如果训练数据里90%是英文、70%是男性作者、80%是西方视角,那AI自然会有偏见。不是它“坏”,是教材有问题。
企业应用:你最大的优势是你的私有数据通用模型用公开数据训练,但你的公司内部文档、客户记录、产品手册——这些是AI不可能知道的。用这些数据做微调或RAG,你就有了别人没有的“护城河”。
六、带走的金句 + 下篇预告
“如果说AI是火箭,算力是引擎,那数据集就是燃料。燃料快烧完了,但我们已经学会了造‘合成燃料’。”
下一篇,我们来讲AI的“自己出题自己练”——
合成数据。
当真实数据不够用了,AI能不能“左右互搏”自己造数据?微软Phi-3有40%训练数据是合成的——这背后是永动机还是陷阱?
(如果你觉得这一篇让你重新认识了“数据”的价值,点个“在看”。)
