 夜雨聆风
夜雨聆风当你的团队要招一个新员工,流程大概是这样的:写JD、筛简历、面试、发 offer、配工号、做onboarding、设KPI、定汇报线。
但如果这个"新员工"是AI Agent 呢?
我帮一个团队评估 AI 客服方案,对方的KP说了一句话让我印象深刻:"我们就是想买个Agent,像买SaaS一样,配置一下就能用。——这种"买工具"的心态,可能是 Agent 项目失败的最大原因。
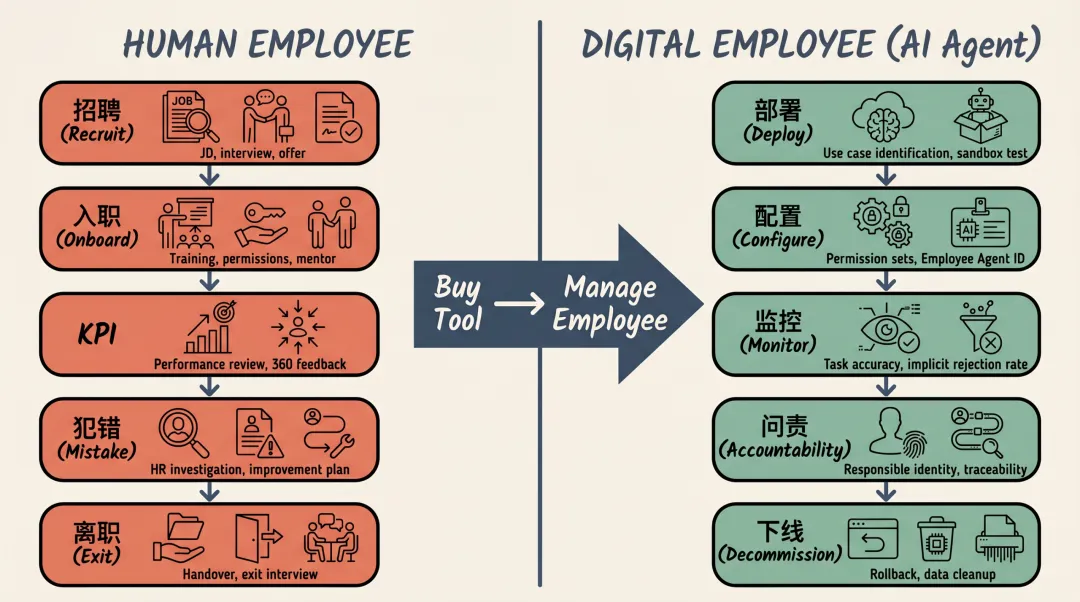
Salesforce 在 2025 年底做了一件很有意思的事:给 Agentforce 的数字员工发了Employee Agent ID。
不是 API key,不是服务账号,是一个正式的、带权限集的、由人类管理者分配任务的员工标识。但你仔细想想,发工号这个动作本身不重要,重要的是发工号之前的那套流程。
Deloitte 帮 Salesforce 内部部署 Agent 时,走的流程是:评估产品路线图→识别用例→优先级排序→上线。这和招一个人有什么区别?
• 写 JD = 定义 Agent 的岗位描述:能处理哪些查询、不能碰哪些数据、什么情况下必须转人工 • 面试 = 沙箱测试:给 Agent 一堆边界 case,看它会不会瞎答、会不会越权操作 • 发 offer = 审批上线:业务方确认 Agent 的能力边界,技术方确认安全策略 • 配权限 = Employee Agent ID + permission sets:能进哪些系统、能看哪些数据、能改哪些东西
但现实中,大多数团队把"面试"环节省了。我见过太多项目,Agent在测试环境里跑了几个标准case就上线,结果遇到真实客户的方言、错别字、情绪化表达,直接崩掉。你招一个客服不会只考他普通话标准题吧?但这就是很多 Agent 项目的实际做法。
Salesforce的Agentforce截至2026 年初处理了3.2万亿 token,83% 的客户服务查询无需人工介入。这些数字不是"配置了一下"跑出来的,是一个被当作员工管理的Agent体系——有岗位边界、有沙箱考核、有逐步放权的试用期。
当你把Agent当工具,你会问"这个功能怎么用"。当你把 Agent 当员工,你会问"这个岗位该招什么样的人、试用期怎么考核、转正标准是什么"。三个问题,答案完全不同。
二、KPI:怎么给 Agent 打绩效
Databricks 内部有一个叫R2DB的Agent,负责IT支持。上线后,NPS 从30提升到了70。他们不是"部署了一个聊天机器人",而是给这个"数字员工"设了一套三层 KPI。
第一层:结果指标(和人类员工一样)
比如解决率、客户满意度、处理时效。这些没什么好说的,人类员工怎么考核,Agent就怎么考核。比如NPS从30跳到70,就是一个结果指标的胜利。
第二层:过程指标(Agent 独有的)
这是最关键的一层,也是大多数团队忽略的。人类员工的过程你看不见——你不知道他解决问题时查了多少资料、走了多少弯路。但Agent的完整执行日志可以被记录:
• 工具选择准确率 — 它调用对 API 了吗?参数填对了吗? • 计划遵从度 — 它按预定步骤执行了吗?有没有跳过关键步骤? • 隐性拒绝率 — 人类很少点"不喜欢",但会默默undo或revert。Google Cloud文档团队把这个叫"隐性拒绝率":如果一个Agent提交的修复被人类改回去了,那就是一次无声的差评。比任何用户调研都真实。
举个例子,假如团队给Agent设的任务完成率是90%,结果Agent确实完成了90%的任务,但剩下10%的失败全是高客单价客户的复杂问题。数字很好看,但也极具欺骗性。如果当时看了"失败分布"这个过程指标,问题早就被发现了。
第三层:健康指标(防止慢性死亡)
Agent不像人类员工会"倦怠"或"离职",但它会"慢性退化"——模型漂移、数据分布变化、API接口更新,都可能让Agent慢慢变笨,而你浑然不觉。
Google团队建议用cost-per-successful-task代替 cost-per-token。如果一个Agent每次运行成本$0.1,但失败率50%,真实成本是$0.2 per successful task。只看token成本,就像考核员工只看考勤卡——他确实每天来了,但产出了吗?
这三层 KPI 的关系是:结果指标告诉你"赢没赢",过程指标告诉你"为什么赢/为什么输",健康指标告诉你"还能赢多久"。缺任何一层,你都是在盲人摸象。
三、管理:犯错了,谁担责
这是我问过最多的问题,也是最难回答的问题。
Salesforce的做法是"责任绑定"——每个Agent必须绑定一个responsible identity,建立一个清晰的责任链条。开发阶段厂商负责,部署阶段集成商负责,运行阶段操作者负责。没有模糊地带,不能推诿。
但比"谁担责"更难的是"怎么避免犯错"。Google Cloud文档团队在这里有一个让我拍案叫绝的发现。
他们试了两种模式:
• 模式 A:人类own任务,Agent辅助(协作模式) • 模式 B:Agent 完全own任务,自动执行(全自动模式)
直觉告诉我们,模式B应该更快、更省人力。但数据说的是另一回事:模式 B 出现了"旁观者效应"(bystander effect)。
当Agent完全own一个bug修复时,团队成员不确定该谁去验证——"Agent做的,应该是对的吧?"验证周期反而变长。当人类own任务、Agent辅助时,验证很快,因为人类感到自己对结果负责。
这不是技术问题,是组织心理问题。
RACI矩阵在传统团队里已经很难跑通了,放到人机协作团队里,失效得更明显。Google最终的结论是:把Agent定位为"协作者"而非"替代者",效率反而更高。
这个发现对我冲击很大。我们总以为"全自动"是终极目标,但组织不是机器,是人与人的协作网络。把Agent塞进去的方式,比Agent本身的能力更重要。
四、离职:40% 的 Agent 会被"裁掉"
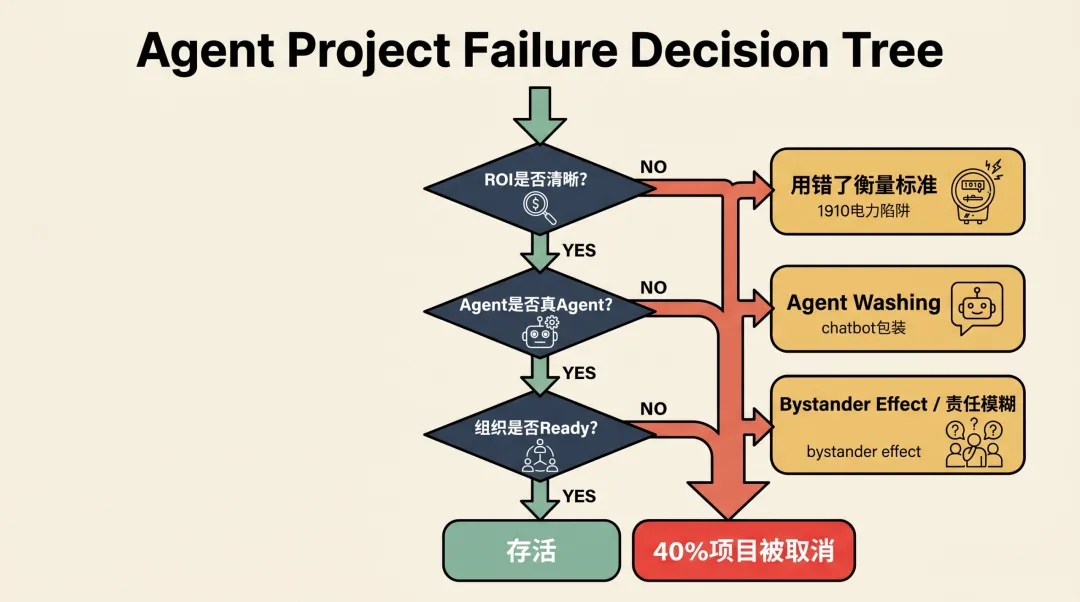
Gartner那个40%的预测,很多人解读为"AI 泡沫要破了"。但我同意 Trullion的分析:失败不是因为 AI 不行,是因为我们用错了衡量标准。
Gartner指出了一个现象叫"Agent washing"——大量所谓 Agent,本质上就是重新包装的chatbot或RPA,没有真正的感知 - 推理 - 行动闭环。企业被"Agent"这个词忽悠了,花大钱买了伪 Agent,然后发现 ROI对不上账。
更深层的问题是ROI衡量方式过时。Trullion 举了一个很妙的类比:1910年代,工厂主争论电力是否比蒸汽"便宜",结论往往是"不便宜",于是错过了整个生产力革命。2000年代,云被说"太贵",现在没人问了。
今天的Agent面临同样的审视:管理层问"能裁掉几个人"、"能省多少钱",但Agent真正的价值不在"替代人力",而在"加速工作流"和"提升决策质量"。这两个东西很难用传统的ROI模型算清楚。
我见过一个团队,他们的Agent项目上线3个月后被砍了。原因?KPI 是"每月节省多少客服工时",但Agent实际做的事是"帮客服更快找到答案"——客服工时没少,但客户满意度上去了。项目因为"没达到降本目标"被砍,团队愤愤不平。
用降本的尺子量提效的事,这就是40%项目会死的原因。
最后
招一个 AI 员工和招一个人,最像的地方不是流程,而是心态。
你得给它工号、设KPI、定汇报线、明确犯错后的责任。你得接受它不是万能的,得持续培训它(A/B 测试、迭代优化),也得在必要的时候"请它离开"。
Agent不是被"使用"的工具,它是被"管理"的员工。这句话听起来像修辞,但2026年的数据正在把它变成现实。
你的团队,准备好"招"第一个Agent了吗?
不是"买",是"招"——这两个字的差别,可能决定了你的 Agent 项目是那 60% 还是那 40%。
