 夜雨聆风
夜雨聆风如果你是 .NET 后端开发,大概率处理过 Excel 导入导出。EPPlus、ClosedXML、NPOI —— 三选一,闭着眼睛都能写出来。直到有一天,用户上传了一个五十万行的文件。
你的服务内存从 200MB 直接冲到 2GB,然后 OOM。
你开始加机器内存,调 GC 参数,拆文件分批处理。折腾半天才发现,问题不在你代码写得烂,而在这些框架的底层假设:它们必须把整个 Excel 文件加载到内存里才能工作。
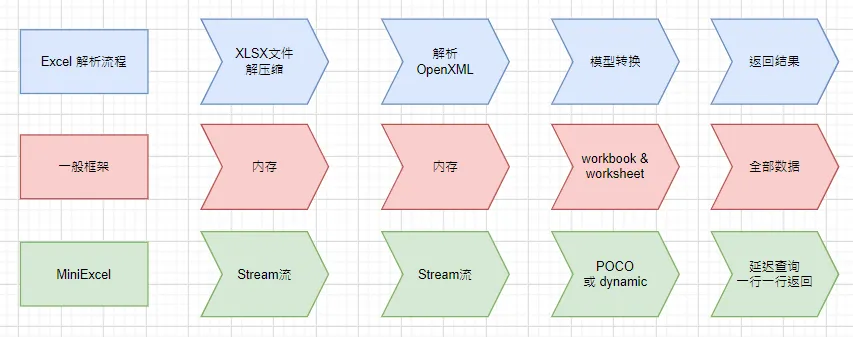
MiniExcel 的解决方式是换个假设——从第一行到最后一行,任何一环都不加载全量数据。
这不是一句口号。从 Zip 解压到 XML 解析,从 SharedString 查找到模板填充,整条链路全部流式化。最终结果:百万行 × 十列的 Excel,传统框架占用 1GB+ 内存,MiniExcel 几 MB。
今天我们从源码层面拆解它是怎么做到的。不是泛泛而谈,是逐行代码级别的拆解。
一、架构全景:三层拆分,各司其职
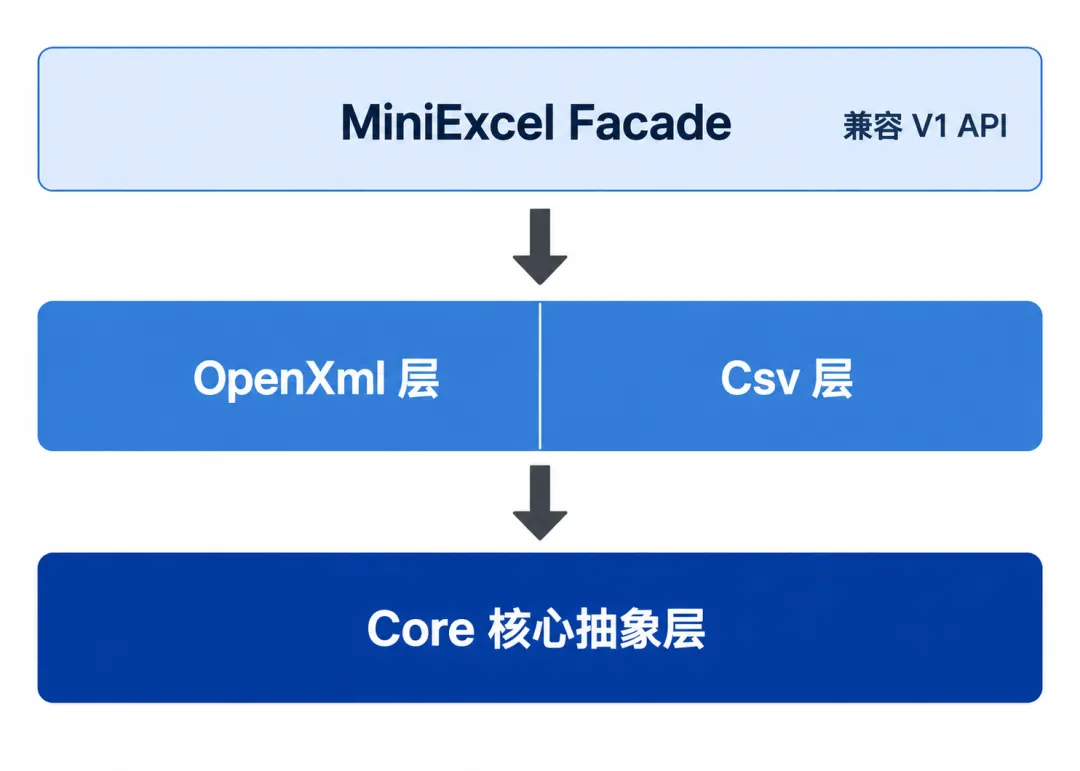
MiniExcel V2 做了彻底的架构重构,从 V1 的单一静态类拆分为三层:
┌─────────────────────────────────────────────┐│ MiniExcel (Facade) │ ← 兼容 V1 API│ MiniExcel.Importers / Exporters / Templaters │├──────────────────┬──────────────────────────┤│ MiniExcel.OpenXml│ MiniExcel.Csv │ ← 格式实现层│ OpenXmlImporter │ CsvImporter ││ OpenXmlExporter │ CsvExporter ││ OpenXmlTemplater│ │├──────────────────────────────────────────────┤│ MiniExcel.Core (Core) │ ← 核心抽象层│ IMiniExcelReader / IMiniExcelWriter ││ MiniExcelDataReader / Configuration ││ Reflection / Helpers / Attributes │└──────────────────────────────────────────────┘Core 层定义所有抽象接口——IMiniExcelReader、IMiniExcelWriter、IMiniExcelDataReader,加上反射工具、属性标注、配置类等基础设施。这一层不依赖任何具体 Excel 格式。
OpenXml 层是真正的重头戏,处理 .xlsx 格式的全部逻辑:流式读取、流式写入、模板引擎、Fluent Mapping 编译系统。
Csv 层独立处理 CSV 格式,代码量最少。
最上层的 MiniExcel 静态类是一个 Facade,内部调用三个 Provider(Importers、Exporters、Templaters),保持 V1 API 的向下兼容。
这种分层的好处显而易见:如果你只需要 CSV 功能,只引用 MiniExcel.Csv 就行,不需要带 OpenXml 的代码。DLL 体积控制在 500KB 以下。
二、流式读取:从 Zip 到 XML 的零全量加载链路
这是 MiniExcel 最核心的技术。我们来看一条完整的读取链路。
2.1 入口:OpenXmlImporter.QueryAsync
// OpenXmlImporter.cspublicasyncIAsyncEnumerable<T> QueryAsync<T>(string path, [EnumeratorCancellation] CancellationToken cancellationToken = default) where T : class, new(){var stream = FileHelper.OpenSharedRead(path); // 只打开文件流,不加载var query = QueryAsync<T>(stream, ..., cancellationToken);awaitforeach (var item in query)yieldreturn item; // 逐行 yield}注意两个关键点:FileHelper.OpenSharedRead 本质是 File.Open(path, FileMode.Open, FileAccess.Read, FileShare.Read),打开的是共享读取流,不是加载整个文件到内存;yield return 实现逐行延迟执行。调 QueryAsync 的那一刻,什么都没发生——只有当你开始 await foreach 的时候,才真正开始读数据。
2.2 OpenXmlReader:真正的流式解析引擎
OpenXmlImporter 只是个门面,实际工作委托给 OpenXmlReader:
// OpenXmlReader.csinternalpartialclassOpenXmlReader : IMiniExcelReader{privatereadonly OpenXmlZip Archive; // 流式 Zip 解压internal IDictionary<int, string> SharedStrings; // 共享字符串表internalstaticasync Task<OpenXmlReader> CreateAsync(Stream stream, ...) {var archive = await OpenXmlZip.CreateAsync(stream); // 打开 zip,不解压全部var reader = new OpenXmlReader(archive, configuration);await reader.SetSharedStringsAsync(cancellationToken); // 处理 sharedStringsreturn reader; }}OpenXmlZip 是对 ZipArchive 的封装——利用 .NET 的 System.IO.Compression.ZipArchive,它是基于流的,不会解压整个 xlsx 到内存。xlsx 本质上就是一个 zip 包,里面包含 xl/worksheets/sheet1.xml、xl/sharedStrings.xml 等文件。
2.3 InternalQueryRangeAsync:逐行遍历 sheetData
核心解析逻辑在 InternalQueryRangeAsync:
privateasync IAsyncEnumerable<IDictionary<string, object?>> InternalQueryRangeAsync(...){var sheetStream = await sheetEntry.OpenAsync(cancellationToken);usingvar reader = XmlReader.Create(sheetStream, xmlSettings); // 流式 XmlReader// 定位到 <sheetData>while (!reader.EOF) {if (reader.IsStartElement("sheetData", Ns)) {while (!reader.EOF) {if (reader.IsStartElement("row", Ns)) {// 跳过 startCell 之前的行if (rowIndex < startRowIndex) { await reader.SkipToNextSiblingAsync(); continue; }if (rowIndex > endRowIndex) break; // 超过范围直接退出// 解析当前行,yield 返回awaitforeach (var row inQueryRowAsync(reader, ...))yieldreturn row; } } } }}关键设计:XmlReader.Create() 是流式读取 XML 的 API,不是 XDocument.Load()。XmlReader 是"前向只读"的游标模式,读到一个 <row> 节点就处理一行,处理完就跳过,不会在内存里构建 DOM 树。
对比传统框架的做法:
EPPlus / ClosedXML:基于 OpenXml SDK 的 SpreadsheetDocument.Open()打开文件,内部将整个 XML 内容加载为 DOM 对象模型 → 遍历 DOM 节点MiniExcel: XmlReader.Create()→ 流式游标逐个节点 → 处理完立即丢弃
这意味着,对于 100 万行的 Excel,传统框架内存里有一棵 100 万行的 DOM 树,MiniExcel 内存里只有当前这一行。
2.4 QueryRowAsync:单元格级流式处理
再往里看一层的 QueryRowAsync,处理每个单元格:
privateasync IAsyncEnumerable<IDictionary<string, object?>> QueryRowAsync(XmlReader reader, ...){var cell = GetCell(...);while (!reader.EOF) {if (reader.IsStartElement("c", Ns)) // <c> 单元格元素 {var aS = reader.GetAttribute("s"); // style indexvar aR = reader.GetAttribute("r"); // cell reference, 如 "A1"var aT = reader.GetAttribute("t"); // cell type, 如 "s" 表示 shared stringvar cellAndColumn = await ReadCellAndSetColumnIndexAsync(reader, ...);var cellValue = cellAndColumn.CellValue;var columnIndex = cellAndColumn.ColumnIndex;// 处理合并单元格if (_config.FillMergedCells) { ... }// 按样式转换值(日期格式、数字格式等)if (!string.IsNullOrEmpty(aS)) { _style ??= new OpenXmlStyles(Archive); // 延迟加载样式 cellValue = _style.ConvertValueByStyleFormat(xfIndex, cellValue); } SetCellsValueAndHeaders(cellValue, useHeaderRow, headRows, ...); } }yieldreturn cell;}每一行里的每一个单元格也是流式读取的。XmlReader 定位到 <c> 节点,读取属性和值,转换类型,存入 dictionary,然后继续下一个。整个过程不构建任何中间集合。
2.5 ConvertCellValue:类型转换的 switch
单元格值的转换逻辑在 ConvertCellValue:
privatevoidConvertCellValue(string rawValue, string aT, outobject? value){switch (aT) {case"s": // shared string → 查 SharedStrings 字典if (int.TryParse(rawValue, outvar sstIndex))value = SharedStrings[sstIndex];break;case"inlineStr": // 内联字符串case"str": // 公式字符串结果value = XmlHelper.DecodeString(rawValue);break;case"b": // booleanvalue = rawValue == "1";break;case"d": // datevalue = DateTime.TryParseExact(rawValue, "yyyy-MM-dd", ...);break;default: // numericvalue = double.TryParse(rawValue, NumberStyles.Any, ...) ? n : rawValue;break; }}Excel 的单元格类型通过 t 属性区分:s 是共享字符串引用(存的是索引),b 是布尔值(“0”/“1”),d 是日期,inlineStr 是内联文本。数值类型不需要 t 属性,直接 parse。
三、SharedStringsDiskCache:把硬盘当哈希表用
如果流式 XML 解析已经够惊艳了,那 SharedStringsDiskCache 就是整个项目最具创意的实现。
3.1 问题背景
Excel 的 xlsx 格式里有一个 sharedStrings.xml 文件。它的作用是集中存储所有不重复的字符串,单元格通过索引引用。比如"销售部"在表格里出现一万次,文件里只存一份,单元格里存索引 0。
这个 sharedStrings 文件可能有几百万条。传统框架的做法:全部读进内存,建一个 Dictionary<int, string>。
MiniExcel V1 也是这样做的。V2 提出了一个问题:为什么一定要放在内存里?
3.2 三文件磁盘哈希表
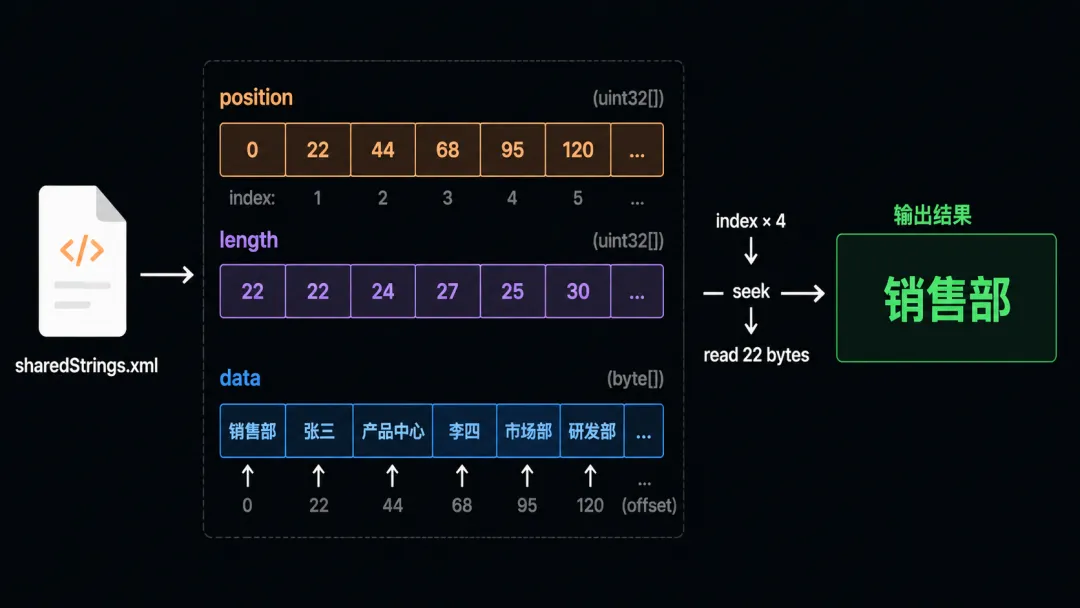
SharedStringsDiskCache 实现了 IDictionary<int, string> 接口,但底层是三个 FileStream:
internalclassSharedStringsDiskCache : IDictionary<int, string>, IDisposable{privatereadonly FileStream _positionFs; // 记录每个字符串的起始偏移privatereadonly FileStream _lengthFs; // 记录每个字符串的字节长度privatereadonly FileStream _valueFs; // 存储实际字符串数据privatevoidAdd(int index, stringvalue) {var valueBs = Encoding.GetBytes(value);// 写入当前值在 valueFs 中的起始位置(4字节) _positionFs.Write(BitConverter.GetBytes(_valueFs.Position), 0, 4);// 写入值的字节长度(4字节) _lengthFs.Write(BitConverter.GetBytes(valueBs.Length), 0, 4);// 写入实际数据 _valueFs.Write(valueBs, 0, valueBs.Length); }privatestringGetValue(int index) {// 从 position 文件读起始偏移 _positionFs.Position = index * 4;var bytes = newbyte[4]; _ = _positionFs.Read(bytes, 0, 4);var position = BitConverter.ToInt32(bytes, 0);// 从 length 文件读长度 _lengthFs.Position = index * 4; _ = _lengthFs.Read(bytes, 0, 4);var length = BitConverter.ToInt32(bytes, 0);// 从 data 文件读实际数据 bytes = newbyte[length]; _valueFs.Position = position; _ = _valueFs.Read(bytes, 0, length);return Encoding.GetString(bytes); }}三个文件协同工作的原理:
_positionFs是一个 int32 数组。索引 0 的字符串偏移量存在位置 0 * 4,索引 1 的存在1 * 4,以此类推。每个 entry 固定 4 字节,所以 O(1) 随机访问。_lengthFs同理,存每个字符串的字节长度。也是固定 4 字节/entry。 _valueFs是变长的,实际字符串数据顺序追加。
读取时:先用 index × 4 定位到 position 文件 → 得到数据在 valueFs 中的偏移 → 再定位到 length 文件得到长度 → 最后在 valueFs 中 seek 到偏移位置读取。
三次 seek,一次读操作,不需要把整个字符串表加载到内存。
3.3 为什么不用真正的内存 Dictionary
因为接口是 IDictionary<int, string>。调用方代码完全不需要知道底层是磁盘还是内存——调用 SharedStrings[index] 就行。
// OpenXmlReader.cs - SetSharedStringsAsyncif (_config.EnableSharedStringCache && sharedStringsEntry.Length >= _config.SharedStringCacheSize){// 大文件 → 用磁盘缓存 SharedStrings = new SharedStringsDiskCache(_config.SharedStringCachePath);}elseif (SharedStrings is { Count: 0 }){// 小文件 → 用内存 Dictionary SharedStrings = list.ToDictionary(_ => idx++, x => x);}小文件走内存路径,大文件走磁盘路径。自动切换,调用方无感知。
这个设计的精妙之处在于:它没有优化数据结构本身,而是换了存储介质。大多数人面对内存问题会想"怎么让 Dictionary 更省内存",MiniExcel 的思路是"为什么一定要用内存"。
四、MappingCompiler:Expression Tree 编译 + 二维网格查找
V1 到 V2 最重要的性能改进之一:用 Expression Tree 预编译属性访问器,消除反射开销。
4.1 问题:反射慢
在 Excel 映射场景中,你需要把 XML 单元格的值映射到 POCO 的属性上。最直接的做法:
propertyInfo.SetValue(obj, cellValue); // 反射设值每次调用 SetValue 都要做元数据查找、类型检查、装箱拆箱。百万行数据下来,这个开销是显著的。
4.2 方案:编译时生成委托
MappingCompiler.Compile<T>() 在启动时把属性映射编译成委托:
// MappingCompiler.csvar parameter = Expression.Parameter(typeof(object), "obj");var cast = Expression.Convert(parameter, typeof(T));var propertyAccess = Expression.Invoke(prop.Expression, cast);var convertToObject = Expression.Convert(propertyAccess, typeof(object));var lambda = Expression.Lambda<Func<object, object>>(convertToObject, parameter);var compiled = lambda.Compile(); // 编译为委托编译后的委托等价于手写的 (obj) => ((T)obj).PropertyName,性能接近直接调用。
4.3 OptimizedCellHandler 二维网格
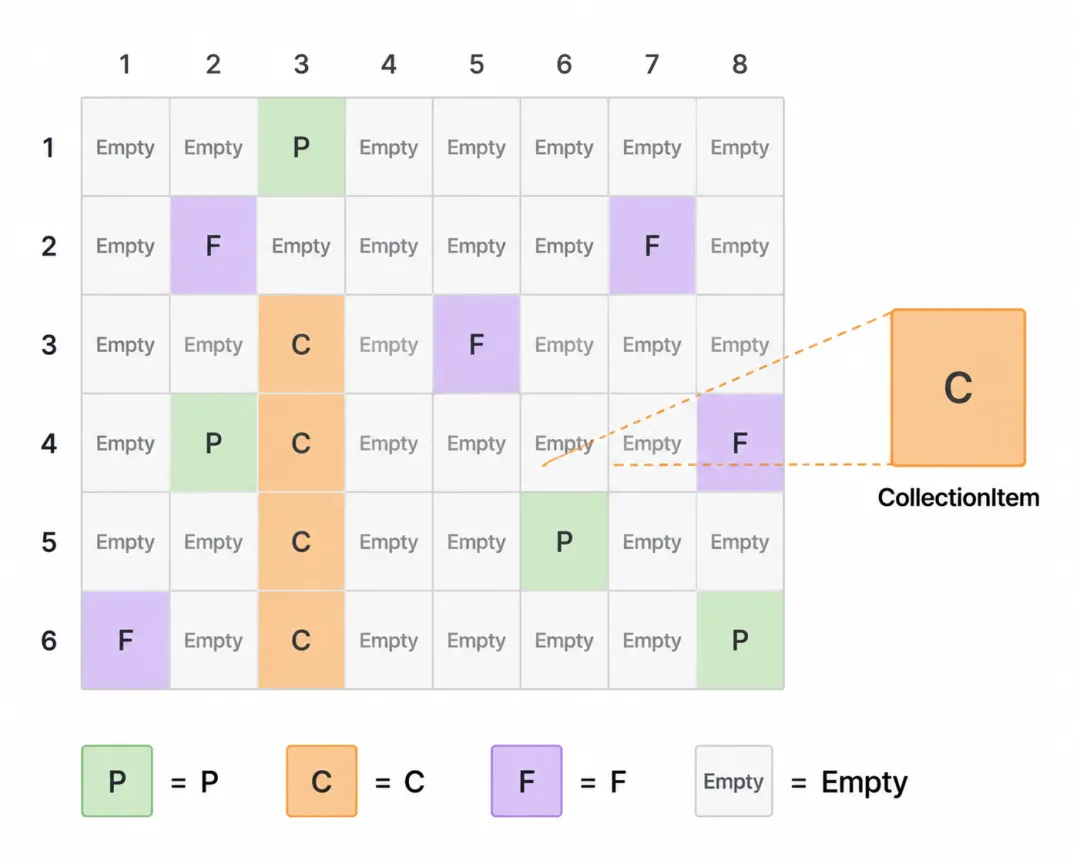
编译完属性映射后,MappingCompiler 构建一个 OptimizedCellHandler[,] 二维网格:
// MappingCompiler.cs - BuildOptimizedCellGridvar grid = new OptimizedCellHandler[height, width];foreach (var prop in mapping.Properties){var relativeRow = prop.CellRow - boundaries.MinRow;var relativeCol = prop.CellColumn - boundaries.MinColumn; grid[relativeRow, relativeCol] = new OptimizedCellHandler { Type = string.IsNullOrEmpty(prop.Formula) ? CellHandlerType.Property : CellHandlerType.Formula, ValueExtractor = CreatePropertyValueExtractor(prop), ValueSetter = prop.Setter, PropertyName = prop.PropertyName, };}网格中每个 cell handler 代表一个 Excel 单元格的处理策略:
Property | |
Formula | |
CollectionItem | |
Empty |
运行时,通过二维数组的 O(1) 索引查找 handler,不需要遍历映射列表。对于模板填充场景,这意味着每个单元格的处理是常数时间的。
4.4 集合映射的编译
对于模板中的集合(比如一个订单包含多个订单项),MappingCompiler 会:
预编译集合工厂函数 Factory = () => CollectionAccessor.CreateTypedList(itemType)预编译元素工厂函数 DefaultItemFactory = CreateItemFactory(itemType)预编译集合终态化函数 Finalizer = list => CollectionAccessor.FinalizeCollection(list, ...)如果是复杂类型(嵌套 POCO),预编译嵌套属性的 getter/setter
// PreCompileCollectionHelpershelper.Factory = () => CollectionAccessor.CreateTypedList(itemType);helper.DefaultItemFactory = CollectionAccessor.CreateItemFactory(itemType);helper.Finalizer = list => CollectionAccessor.FinalizeCollection(list, propertyType, itemType);整个模板处理过程变成了纯委托调用链,没有反射,没有运行时类型查找。
五、IDataReader 适配器:Excel 数据直通数据库
MiniExcelDataReader 是另一个容易被忽视但极其有用的设计。
它将 OpenXmlReader 的流式查询结果包装成 ADO.NET 标准的 IDataReader 接口:
// OpenXmlImporter.cs - GetDataReaderpublic MiniExcelDataReader GetDataReader(string path, ...){var stream = FileHelper.OpenSharedRead(path);var values = Query(stream, ...).Cast<IDictionary<string, object?>>();return MiniExcelDataReader.Create(stream, values);}IDataReader 是 .NET 中数据读取的标准接口,SqlBulkCopy.WriteToServer() 接受的就是 IDataReader。这意味着:
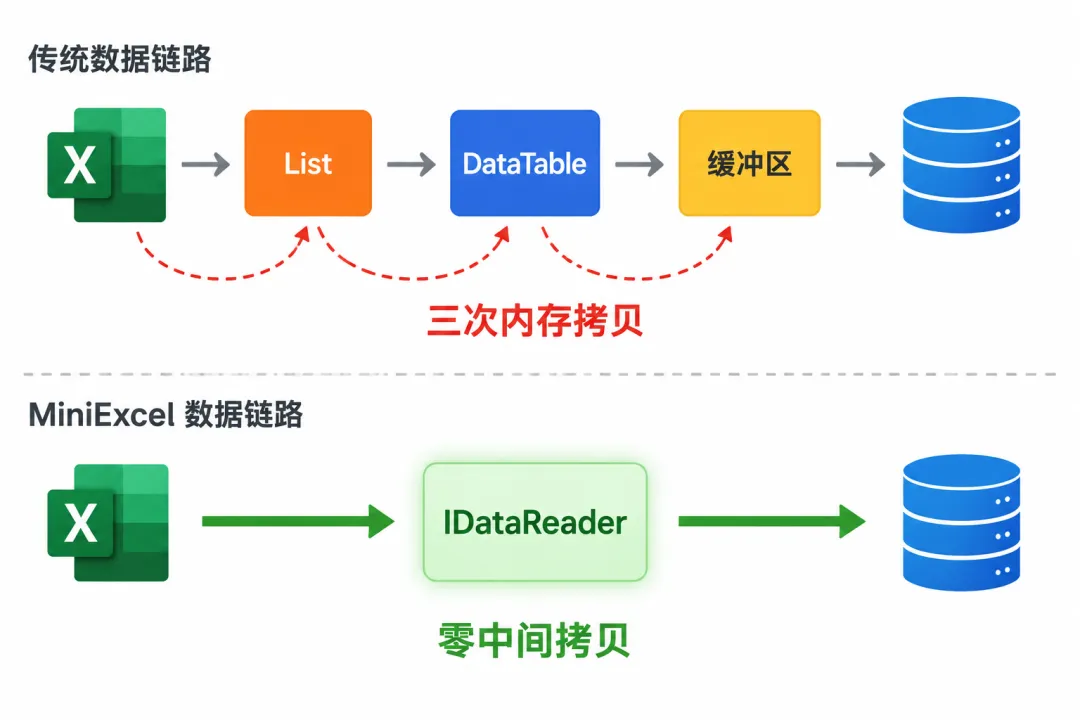
Excel 文件 → MiniExcelDataReader → SqlBulkCopy → 数据库整条链路数据不落地。不需要先把 Excel 读到 List<T>,再转成 DataTable,再批量插入。每一行从 Excel 读出来直接喂给 SqlBulkCopy,处理完就丢弃。
百万行 Excel 导入数据库,传统方案需要三份内存拷贝:Excel 对象 → DataTable → SqlBulkCopy 缓冲区。MiniExcel 只需要一份流式读取的当前行。
六、异步流:IAsyncEnumerable 的真正落地
V2 将 QueryAsync 的返回值从 Task<IEnumerable<T>> 改为 IAsyncEnumerable<T>。这不只是 API 变化,是内存管理方式的根本改变。
// 返回值改为 IAsyncEnumerable<T>publicasyncIAsyncEnumerable<T> QueryAsync<T>(string path, ...) where T : class, new(){var stream = FileHelper.OpenSharedRead(path);var query = QueryAsync<T>(stream, ...);awaitforeach (var item in query)yieldreturn item; // 逐行异步 yield}Task<IEnumerable<T>> 的问题是:虽然方法是 async 的,但返回的 IEnumerable<T> 仍然是同步消费,而且内部可能已经全部加载。IAsyncEnumerable<T> 是真正的逐行异步流——消费者消费一行,生产者读取一行。
配合 [CreateSyncVersion] 源码生成器,同一个异步方法自动生成同步版本,不需要手写两套逻辑:
[CreateSyncVersion] // 这个属性会触发 SyncGenerator 生成同步版本publicasyncIAsyncEnumerable<T> QueryAsync<T>(...)七、写入链路:同样流式
读取是流式的,写入也不是全量构建。XmlCellWriter 基于 XmlWriter 的流式输出:
// XmlCellWriter 使用 XmlWriter// XmlWriter 是前向写入的,不构建中间 DOMawait writer.WriteStartElementAsync(null, "c", null);await writer.WriteAttributeStringAsync(null, "r", null, cellRef);await writer.WriteElementStringAsync(null, "v", null, value);写入也是一行一行输出到流,不等待整个 Excel 构建完成。对于生成百万行报表的场景,你可以边查数据库边写 Excel,不需要等所有数据都准备好再开始写。
八、合并单元格的处理
合并单元格是流式读取的一个难点。因为合并区域的第一个单元格包含值,后续单元格是空的但需要显示同一个值。MiniExcel 的处理方式:
// OpenXmlReader.cs - TryGetMergeCellsAsync// 第一次扫描:解析 <mergeCells> 节点,建立映射关系foreach (var mergeCell in mergeCells){var refs = refAttr.Split(':'); // 如 "A1:C3" CellReferenceConverter.TryParseCellReference(refs[0], outvar x1, outvar y1); CellReferenceConverter.TryParseCellReference(refs[1], outvar x2, outvar y2); mergeCells.MergesValues.Add(refs[0], null); // 第一个单元格存值for (int x = x1; x <= x2; x++)for (int y = y1; y <= y2; y++)if (!isFirst) mergeCells.MergesMap.Add(CellReferenceConverter.GetCellFromCoordinates(x, y), refs[0]);}// 第二次遍历时:如果是合并区域的非首单元格,从 MergesValues 回填值if (mergeCells.MergesMap.TryGetValue(aR, outvar mergeKey)) mergeCells.MergesValues.TryGetValue(mergeKey, out cellValue);先扫描合并单元格定义,建立 MergesMap(坐标 → 合并首单元格引用)和 MergesValues(首单元格引用 → 值)两个字典。遍历时如果当前单元格在合并区域内,从字典回填值。
这个方案虽然需要预先读取合并单元格定义,但不需要加载单元格数据本身——合并区域定义通常很小。
九、性能数据:不只是数字,是架构差异
基准测试环境:100 万行 × 10 列,32MB 文件,.NET 10。
QueryFirst 场景最能体现架构差异:MiniExcel 读到第一行就返回(58ms),其他框架需要先加载整个文件。19 倍的差距不是因为 MiniExcel 算法更优,是因为它根本不做那些不必要的操作。
Query 全部场景也值得注意:即使处理完全部数据,MiniExcel 的内存仍然是最低的。因为数据流过即释放,GC 不需要处理大对象堆。而其他框架需要同时维护完整的对象模型。
十、工程化细节
除了核心技术实现,MiniExcel 在工程化上也值得学习:
.editorconfig + .gitattributes:规范代码风格和行尾处理,多平台协作的基础。
AppVeyor CI:配置文件 appveyor.yml 存在,说明有持续集成流程。
多语言 README:支持 18 种语言,包括中文(README.zh-CN.md)。在 Gitee 的 dotnetchina 组织下有镜像,对中国开发者友好。
.NET Foundation:项目已加入 .NET 基金会,有 miniexcel.publickey 签名密钥。
Samples 项目:提供了 Blazor、Minimal APIs、FileBasedApp 等多种场景的示例代码,方便开发者参考。
十一、一个哲学层面的启示
读 MiniExcel 的源码,最深的感受不是"这个 API 设计得真好"或"这个算法真巧妙",而是一种贯穿始终的思维方式:
面对性能问题,第一反应不是"怎么让它更快",而是"这个操作是不是根本不需要发生"。
不需要加载整个 XML 文件,因为 XmlReader流式读取就够了不需要把 SharedString 存在内存里,因为磁盘哈希表就够了 不需要每次运行时反射,因为 Expression Tree 预编译就够了 不需要中间数据转换,因为 IDataReader直通数据库就够了不需要手写同步异步两套代码,因为源码生成器就够了
每一次"不需要",都是对默认假设的质疑。
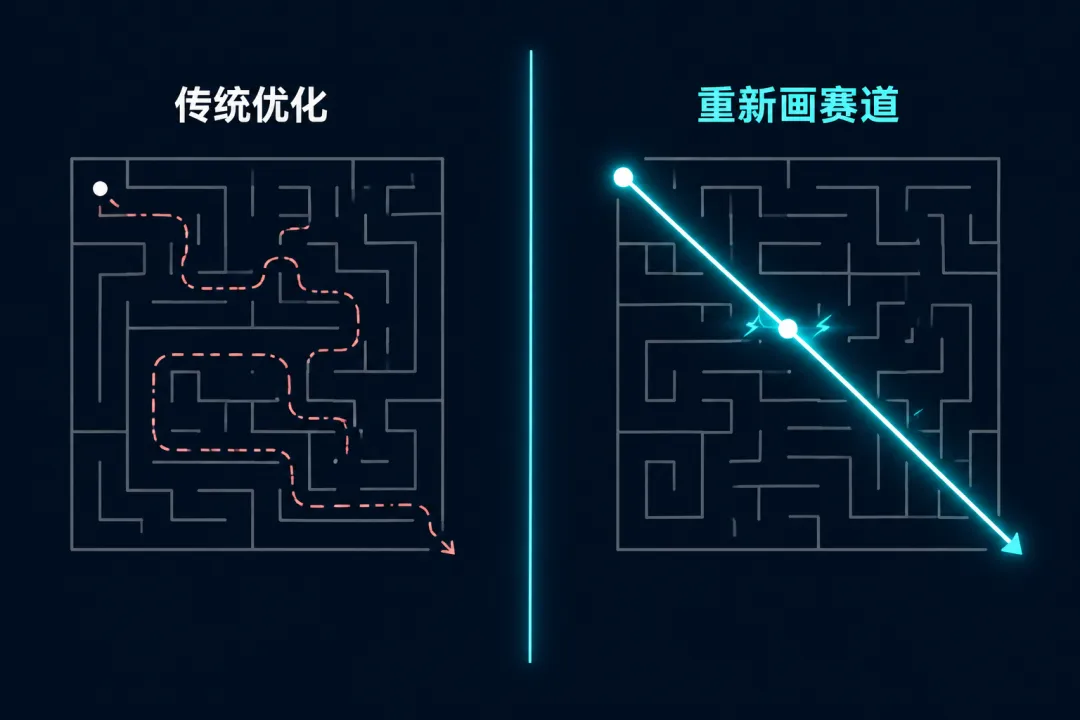
大多数性能优化是在既定框架内做加法——加缓存、加索引、加并发。MiniExcel 做的是减法——去掉不必要的加载、去掉不必要的拷贝、去掉不必要的抽象。
最快的代码,往往是不需要写的那行代码。占用最少内存的方案,往往是不分配内存的那个方案。
这大概就是所有优秀开源项目共有的特质:他们不是在同一条赛道上跑得更快,而是重新画了一条赛道。
项目地址:https://github.com/mini-software/MiniExcel
NuGet:
dotnet add package MiniExcel
