 夜雨聆风
夜雨聆风
之前开发PDF2WordPro时,有粉丝问能不能加个OCR功能。其实刚开始我就想过这事,但OCR识别率不可能百分百,没法保证转换后完全原样,所以打算先把基础功能做好,再研究这个。
五一假期抽了点时间,研究了一下,今天做个学习总结,顺手推荐给大家。
今天的主角是Umi-OCR,开源工具,可以上github直接搜名字,需要科学上网。实在不会的同学评论区留言吧。
先放图:
这工具挺全能的,支持截图OCR、批量OCR、PDF识别、二维码、公式识别。我主要关注PDF OCR,直接上视频展示操作过程。
已关注
关注
重播 分享 赞
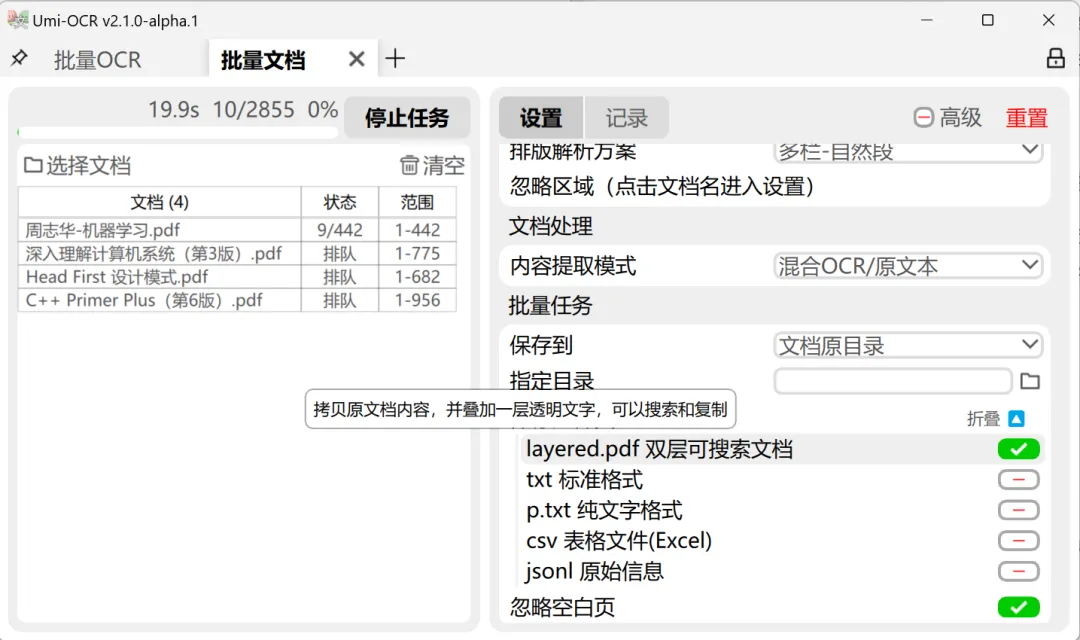
把文件拖入文档列表,然后设置中修改如下配置:
1、内容提取模式:混合OCR/原文本;
2、保存文件类型:layered.pdf双层可搜索文档(图片+文字两层)。
开始任务即可。
源文件是我截图的DeepSeek回答的,转出来的PDF看上去跟原来一模一样,效果不错。
想到之前有些朋友用PDF2WordPro时需要OCR功能,可以先用Umi-OCR把图片PDF转成结构化PDF,再用PDF2WordPro转Word,这样大部分场景的pdf应该也能正常转成可编辑的word了(我可真是个大聪明 )。
)。
注意:如果是到PDF为止,不需要再转word,那么选双层可搜索文档,效果最好。如果还要转word,就选text.pdf 单层纯文文档。
既然研究了Umi-OCR,我也在琢磨怎么把它整合进PDF2WordPro,这样又可以偷懒一步,多点时间摸鱼啦 。
。
往期推荐:
