 夜雨聆风
夜雨聆风在 Claude Code、Codex 这类 AI 编程工具里,插件很容易被理解成一种"能力扩展"。
多一个命令,多一个专用角色,多一组执行规则,或者多一套外部工具连接能力,AI 看起来能处理的场景也就越多。
但真正把 Codex 或 Claude Code 放进开发流程里以后,会发现问题并不只是"能不能扩展能力"。
更关键的是:这些能力应该在什么任务里使用,按什么顺序使用,用完以后怎么验证,哪些动作必须停下来等人确认。
有价值的插件体系,不该只是能力堆叠,而应该把工具、角色、规则和输出格式组织成一套可复用流程。
一个好插件不只是告诉 AI"你多了一个能力",还应该把这个能力的使用方式说清楚:什么时候用、用之前检查什么、用完怎么验证、哪些动作必须等人确认、输出按什么格式交付。
今天这篇想聊的就是这个:AI 编程工具的插件,不是装得越多越好,而是要装得有秩序。
Claude Code 官方对插件的定位很明确:它不是只增加一个命令,也不是只接入一个外部工具,而是可以同时包含 slash commands、subagents、MCP servers、hooks 和 Skills。装上一个插件以后,你得到的可能是一组命令、几个专用角色、若干通过 MCP 接入的外部工具,加上一套执行前后的规则。
slash command 负责快速触发流程,subagent 负责把特定任务交给特定角色,MCP server 负责连接外部工具和数据源,hooks 负责在执行过程中做检查和记录,Skills 则可以沉淀某类任务的做法。
单独看,它们只是几类不同的能力组件;组合到一个插件里,就可以变成一套可复用的团队工作流程。
最容易理解的例子是代码审查。真正有用的插件,不应该只是多一个"代码审查工具",而是让 PR 审查有一套固定流程:
/pr-review启动审查code-reviewersubagent 读代码找问题GitHub MCP 读取 PR、diff 和 issue 背景
hooks 审查前检查敏感文件,审查后记录结果
输出固定为风险等级、文件位置、原因、建议、是否阻塞
这时候插件就不只是工具了,而是一个可复用的工作流。
Codex 的组织方式不太一样。它把"连接外部信息"和"沉淀做事方法"分成了两类能力:插件(plugins)和技能(skills)。
OpenAI 对 Codex 插件的定义,更偏向"让 Codex 访问外部工具和信息源"。比如读取 Google Drive 里的文档、查看邮箱里的信息,或者和公司内部系统交互。插件解决的是:Codex 能不能拿到任务需要的信息和上下文。
技能更像工作手册。它不给 Codex 多一个外部工具,而是告诉它"这类任务我们团队通常怎么做"。比如怎么写周报、怎么整理客户简报、怎么把会议纪要转成项目计划、怎么按品牌语气检查对外文案。
换句话说,插件决定 Codex 能访问什么,技能决定 Codex 访问之后应该怎么做事。
做一个真正有用的 AI 编程工作流,通常两边都得有。比如你要让 Codex 做发布前检查:插件让它读取 GitHub PR、Linear issue、设计文档和测试报告;技能写清楚检查顺序、哪些问题算阻塞、报告应该怎么交付。外部上下文和做事方法放在一起,AI 才不只是能访问更多东西,而是能按团队习惯把一件事做完。
下面以最常见的 PR 审查为例。
假设我们要给 Claude Code 做一个 PR 审查插件 team-pr-review,目标是形成一套稳定审查流程,不是让模型临时扫一遍代码。
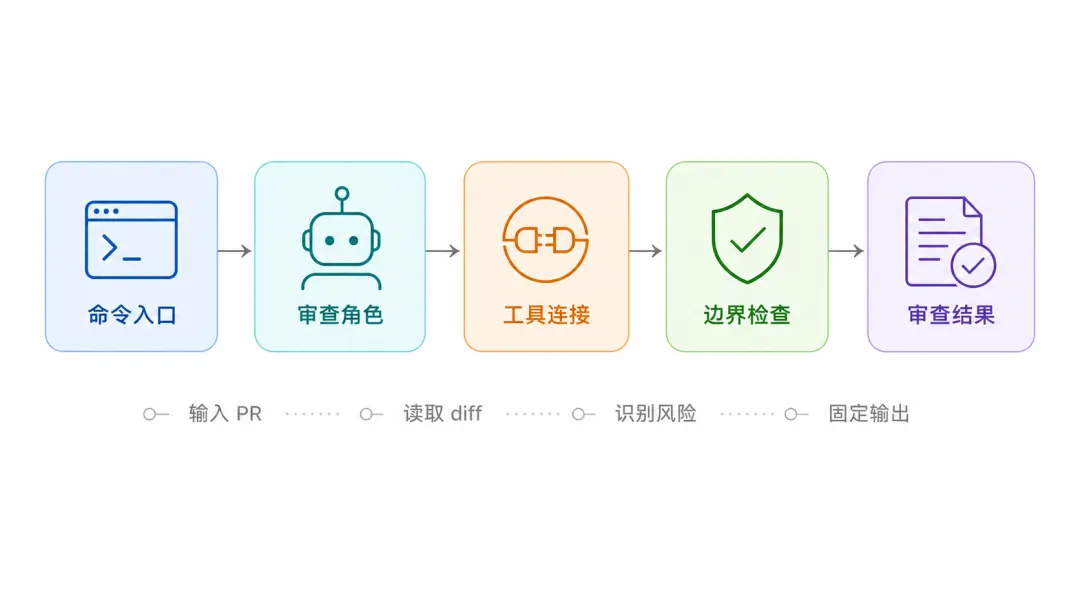
真正落地时,可以先按四层来设计:入口、角色、工具、边界。
触发入口:slash command。
/team-pr-review命令背后不是一句"帮我 review 一下",而是启动一套固定流程:
请审查当前 PR。
审查范围包括:
1. 业务逻辑是否有明显错误;
2. 是否有安全风险;
3. 是否修改了权限、数据库、支付、配置等高风险区域;
4. 测试是否覆盖关键路径;
5. 是否有需要人工确认的改动。
请按以下格式输出:
- 阻塞问题
- 非阻塞建议
- 需要人工确认的点
- 建议补充的测试
- 最终结论:可以合并 / 不建议合并团队每个人用同一个命令,输出格式就不会每次都变。
执行角色:专用 subagent。
比如叫 code-reviewer,职责只有审查,不改代码:
你负责代码审查。
你不负责改代码,只负责审查。
优先关注:
1. 权限控制;
2. 数据库迁移;
3. 外部 API 调用;
4. 错误处理;
5. 测试缺口;
6. 是否存在为了通过测试而修改测试本身的情况。审查角色不该顺手帮你改代码——审查和修复混在一起,两边都做不干净。
工具连接:MCP。
GitHub MCP 让 Claude Code 读取 PR 信息、diff、评论和关联 issue。如果项目还有日志系统、错误监控、设计文档,也可以通过 MCP 接进来。
但 MCP 不是越多越好。PR 审查只需要和审查相关的工具。数据库生产权限、部署权限、支付后台这类高风险工具,不该默认出现在一个审查插件里。
执行规则:hooks。
hooks 做两件事——审查前检查边界,审查后记录结果。
比如发现 PR 改了这些目录,就让审查角色提高风险等级:
src/auth/
src/payments/
src/migrations/
infra/
.github/workflows/审查后把结论写入本地日志,或生成固定格式的 review summary,方便追溯。
四层合在一起,PR 审查流程就变成:
/team-pr-review
-> 读取 PR 和关联上下文
-> 识别高风险文件
-> 调用 code-reviewer 审查
-> 输出固定格式结果
-> 记录审查摘要具体开发时,可以按这个顺序做。
第一步,先写清楚插件边界。team-pr-review 只做审查,不改代码,不提交 commit,不触发合并,也不替用户解决所有问题。它的价值是把风险找出来,把证据列清楚,把需要人工判断的地方摆到台面上。
第二步,定义命令入口。比如 /team-pr-review 默认读取当前分支对应的 PR,也可以允许用户补充参数:
/team-pr-review --focus security
/team-pr-review --focus tests
/team-pr-review --since main这些参数的作用,是让团队在不同场景下复用同一套流程。安全审查、测试审查、合并前总审查,关注点可以不同,但输出结构应该保持一致。
第三步,写角色说明。code-reviewer 不应该是一个什么都管的角色,而应该有明确职责:
职责:
1. 读取 PR diff、关联 issue 和测试结果;
2. 判断改动是否涉及高风险区域;
3. 找出可能导致线上问题的代码路径;
4. 标注证据,尽量给出文件位置;
5. 不直接修改代码。
禁止动作:
1. 不主动提交修复;
2. 不修改测试来适配实现;
3. 不把没有证据的猜测写成确定结论;
4. 不把风格偏好当成阻塞问题。第四步,配置工具权限。PR 审查插件通常只需要读 GitHub、读测试报告、读静态扫描结果。如果还要接设计文档或需求系统,也应该是只读。实际配置时,可以先写一份基础版权限白名单:
允许读取:
- GitHub PR 基本信息
- GitHub PR diff
- GitHub issue / discussion
- CI 测试结果
- 静态扫描结果
- 需求文档或设计文档
禁止执行:
- push commit
- merge PR
- approve PR
- 触发部署
- 修改数据库
- 修改生产配置
- 修改 CI/CD 配置如果接的是 MCP,也可以按这个思路去约束工具能力。比如 PR 审查只允许读取 get_pull_request、list_files、get_diff、list_checks 这类工具,不开放 merge_pull_request、create_deployment、update_secret 这类动作。这个阶段最容易犯的错误,是图方便把太多系统都接进来。权限越多,审查插件越容易偏离原本的职责。
第五步,把 hooks 用在关键节点上。这里不要只写一句"加 hooks",而要明确每个 hook 拦什么。
启动前:
- 检查当前目录是不是 Git 仓库;
- 检查是否能找到对应 PR;
- 检查用户是否给了审查范围;
- 如果缺少必要信息,先追问,不直接开始审查。
读取 diff 后:
- 检查是否命中高风险目录;
- 如果改到 auth、payments、migrations、infra、CI 配置,提高风险等级;
- 如果 diff 过大,提示用户是否拆分审查范围。
输出前:
- 检查每个阻塞问题是否包含文件位置;
- 检查每个结论是否有证据;
- 检查是否明确区分阻塞问题和普通建议;
- 检查是否给出最终合并建议。如果这些检查没有通过,就不要让插件继续生成一段完整但不好用的审查报告。更好的做法是让它停下来补信息,或者直接输出"当前无法完成审查",并说明缺少什么。
第六步,固定输出模板。团队最好约定一份标准格式:
## 阻塞问题
- 位置:
- 问题:
- 证据:
- 建议:
## 非阻塞建议
- 位置:
- 建议:
## 需要人工确认
- 事项:
- 为什么需要确认:
## 测试缺口
- 缺口:
- 建议补充:
## 结论
可以合并 / 建议修改后再合并 / 不建议合并做到这一步,插件就不只是"帮我看一下 PR",而是把团队对 PR 审查的要求写进了流程里。新人可以按统一标准完成审查,老同事也能少做很多重复确认。
PR 审查输入明确、风险可控,很适合入门。但插件体系更有价值的地方,是那些信息分散、风险更高的场景。
比如线上问题排查。
用户反馈"昨天晚上 10 点以后支付成功率下降了",如果每次都从头描述排查流程,很快就成重复劳动。这类场景更适合沉淀成一个固定插件。
做一个 incident-triage 插件,目标不是让 AI 编程工具直接修线上问题,而是帮工程师完成第一轮排查:收集信息、缩小范围、列出可能原因、给下一步建议。
触发入口:
/incident-triage用户提供现象、时间范围、影响范围。命令背后的 prompt 不让 AI 直接猜原因,而是规定排查步骤:
请按以下顺序排查:
1. 先确认影响范围和时间窗口;
2. 再检查这段时间内是否有发布、配置变更、依赖升级;
3. 查看错误日志和监控指标,找出异常集中点;
4. 对比正常时间段和异常时间段的差异;
5. 输出可能原因列表,并标注置信度;
6. 不要直接执行修复动作,只给出下一步建议。执行角色:incident-analyst。
它不写代码,不触发发布,只做故障分析:
你负责线上问题排查。
你不负责直接修复代码,也不触发发布。
你只负责:
1. 汇总现象;
2. 对齐时间线;
3. 查找异常指标;
4. 提出可能原因;
5. 给出下一步验证建议。
如果证据不足,必须明确说明"当前无法判断",不要编造原因。工具连接: 日志系统、监控系统、GitHub/GitLab、CI/CD 记录、只读数据库。
这里权限必须更谨慎——线上排查插件默认只读。可以查日志、查监控、查发布记录,但不该默认拥有改配置、重启服务、回滚发布、改数据库的权限。需要执行高风险动作,必须交给人确认。
边界规则: 插件启动时先检查用户有没有给出时间范围,没有就追问,不直接开始查。排查流程访问生产数据库时,hooks 强制限制为只读查询。建议回滚时必须输出理由、影响范围和验证方式,不能直接执行。
输出格式也应该固定:
## 现象总结
发生了什么,影响哪些用户,时间范围是什么。
## 时间线
列出发布、配置变更、异常指标出现的时间点。
## 可能原因
按置信度排序,每个原因必须附证据。
## 还需要验证什么
列出下一步要查的日志、指标或代码路径。
## 不建议自动执行的动作
列出需要人工确认的高风险操作。这个案例比 PR 审查更能说明插件设计的核心:不是把所有能力都交给 AI 编程工具,而是让它在一个受控流程里使用必要能力。面对不完整的现象、多个外部系统和生产环境的高风险,边界比能力更重要。
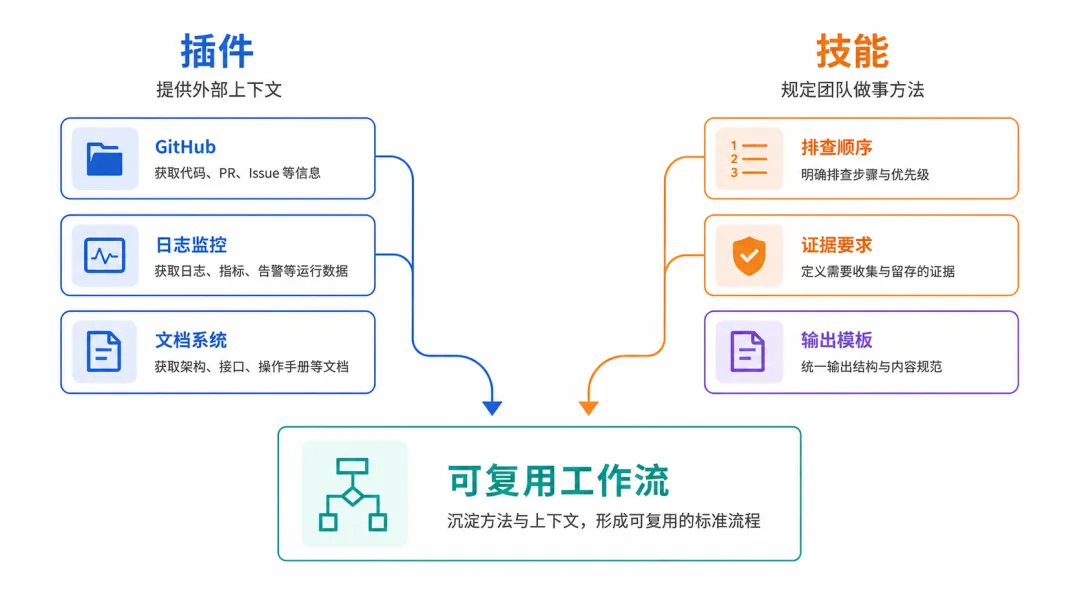
如果用 Codex 做同样的事,落地方式稍有不同,更适合拆成插件和技能两部分。
插件负责让 Codex 访问 GitHub、Linear、文档系统、测试报告这些外部信息源。技能负责把团队的排查方法或审查方法写下来。
还是拿线上问题排查来说。使用 Codex 时,不一定要把所有能力都放进一个插件里,更合理的拆法是:
GitHub 插件负责读取最近发布、PR、commit 和关联 issue
日志或监控插件负责读取异常指标、错误日志和告警记录
文档插件负责读取服务说明、接口文档和历史故障记录
incident-triage-skill负责规定排查顺序、证据要求、禁止动作和输出格式
也就是说,插件解决"信息从哪里来",技能解决"拿到信息以后怎么判断"。
比如 incident-triage-skill 可以这样写:
本团队线上问题排查流程:
1. 先确认现象、时间范围和影响范围;
2. 再读取日志、监控和发布记录;
3. 对齐异常指标和最近变更的时间线;
4. 给出可能原因,并标注证据和置信度;
5. 不直接执行回滚、重启、改配置等动作;
6. 输出下一步验证建议和需要人工确认的操作。实际使用时,可以这样发起:
$incident-triage-skill
请使用日志、监控和 GitHub 插件,排查昨晚 10 点后支付成功率下降的问题。如果要写得更完整,技能里还可以继续补三类内容。
第一类是证据要求。比如所有结论都必须关联到日志、指标、发布记录或代码变更,不能只写"可能是缓存问题"这种空泛判断。
结论必须包含证据来源:
- 日志片段或错误类型;
- 指标变化;
- 关联发布或配置变更;
- 相关代码路径。
如果没有证据,请写"当前证据不足",不要给出确定结论。第二类是动作边界。线上排查最危险的地方,不是模型不会分析,而是它把分析和处置混在一起。
禁止直接执行:
- 回滚发布;
- 重启服务;
- 修改配置;
- 写入数据库;
- 关闭告警;
- 修改 CI/CD 设置。
如需建议这些动作,必须说明理由、影响范围、验证方式,并标注"需要人工确认"。第三类是输出模板。模板越固定,后续越容易接入团队流程。
## 结论摘要
一句话说明当前最可能的问题。
## 证据列表
按日志、指标、发布记录、代码路径分别列出。
## 时间线
按时间排序列出异常出现、发布变更、告警触发。
## 可能原因
按置信度排序,每一项都要有证据。
## 建议下一步
只给验证建议,不直接执行高风险动作。
## 需要人工确认
列出回滚、重启、改配置等需要人判断的动作。这个例子里,插件负责提供外部上下文,技能负责按团队方式做事。只有插件没有技能,Codex 能拿到日志和发布记录,但不知道你们的排查习惯。只有技能没有插件,Codex 知道怎么排查,但还得你手动把所有数据复制给它。两边配合起来,才能形成一套可复用的工作流。
所以 Claude Code 和 Codex 的差别,不是一个能做、另一个不能做,而是组织方式不同。Claude Code 更适合把命令、角色、工具连接和执行规则放在同一个插件流程里。Codex 更适合把外部访问能力交给插件,把团队方法沉淀到技能里。具体落地时,可以不用纠结这些概念该怎么对应,先把"能访问什么"和"应该怎么做"分清楚。
插件越多,边界越重要
插件体系搭起来以后,很容易陷入一个惯性:越装越多。
一开始只是多一个 GitHub 能力,后来又接了数据库、日志、监控、文档、Slack、飞书、设计工具、云平台。看着很强大,但每多一个外部系统,AI 编程工具能影响的范围就大一点。
所以不建议一上来就追求"全连接"。
更合理的做法是按任务类型拆插件:
PR 审查插件只接 GitHub、测试报告、静态扫描结果
文档生成插件只接代码仓库、设计文档、知识库
线上排查插件只接日志、监控、只读数据库
发布检查插件只接 CI、配置文件、变更记录
每个插件都该想清楚四件事:
服务哪类任务? 别做"万能开发插件"。万能往往意味着边界不清。
需要哪些工具? 只接必要的,不要图方便把所有系统都塞进去。
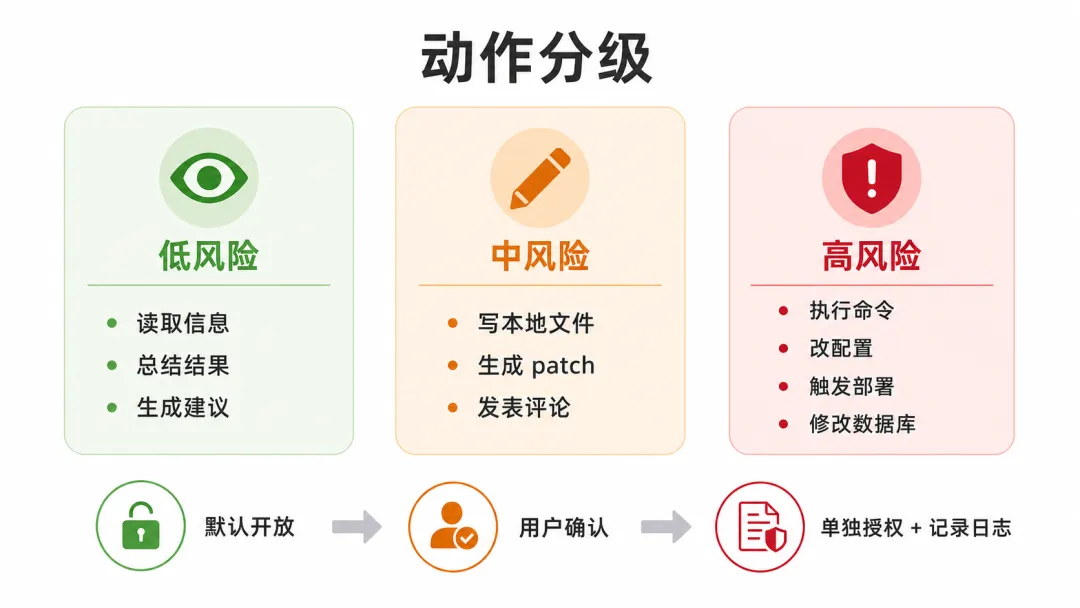
能做哪些动作? 读取、建议、写文件、执行命令、发评论、触发部署,这些动作的风险完全不同,最好分成几档处理。
低风险:读取信息、总结结果、生成建议。
中风险:写本地文件、生成 patch、发表评论。
高风险:执行命令、改配置、触发部署、修改数据库。低风险动作可以默认开放;中风险动作最好让用户确认;高风险动作不要放进普通插件里,至少要单独授权、记录日志,并且能回退。
怎么交付结果? 输出格式必须固定。否则每次插件跑完,用户还得重新判断哪些是重点、哪些需要处理、哪些只是模型临时补充的内容。
如果让我给团队设计一个起步方案,我不会一开始追求覆盖所有场景。更适合作为第一批建设对象的,是下面四类插件:
PR 审查插件。 最容易落地。输入明确,输出明确,风险可控。先只读 PR,不直接改代码。
测试补全插件。 专门检查某次改动有没有测试缺口,生成建议测试。可以生成 patch,但最好不要自动合并。
线上问题排查插件。 处理"现象不清楚、信息分散在多个系统里"的场景。默认只读,不修复、不回滚。
发布前检查插件。 检查配置、权限、数据库迁移、依赖变更、CI 状态、回滚方案。价值不在写代码,在减少上线前漏项。
这四个做好,已经能覆盖大多数团队的高频场景。而且它们各管各的——审查插件看问题,测试插件补验证,排查插件缩小故障范围,发布插件守交付边界——不会互相抢职责,也不会都变成"万能插件"。
如果你看过我前面写的 Harness 系列,会发现这里讲的还是同一类问题。
Harness 不是单纯限制 AI 编程工具,而是把边界、权限、验证和回退放进工程流程里。插件体系也一样——一个好的插件不只是扩展能力,也在规定能力怎么用。它告诉 AI 编程工具这个任务该按什么顺序做、哪些工具可以用、哪些地方要停、结果怎么交付。
所以插件越强,越不能"装上就行"。插件需要设计,需要边界,也需要审计和维护。否则插件越多,AI 编程工具看着越强,系统反而越难控制。
AI 编程工具的插件体系,正从"扩展能力"变成"固化工作流"。
Claude Code 的插件可以同时包含命令、subagents、MCP servers、hooks 和 Skills。Codex 则把"访问外部信息"和"遵循团队流程"分别放在插件和技能里。叫法不同,但方向接近:不是让 AI 拥有更多零散能力,而是让 AI 按更稳定的方式完成任务。
所以如果今天要给 AI 编程工具装插件,我不会先问"有什么插件值得装"。
我会先问:这个插件要替我固化哪一段工作流?
想清楚这个,插件才不会变成新的混乱源,而是团队可以复用、可以管理、也可以不断改进的工程资产。
如果这篇文章对你有启发,欢迎点个关注,也顺手来个一键三连:点赞、转发、点亮小心心。
我会持续追踪 AI 领域的热点变化,AI 编程工具的最新进展,以及背后的技术逻辑和实战经验。也欢迎在评论区留言,一起交流你的看法。
