 夜雨聆风
夜雨聆风
上一期我们讲了Zotero PDF安装下载的教程,这期我们来讲一下翻译服务的选择,让你的翻译更加精准!
一、Google翻译
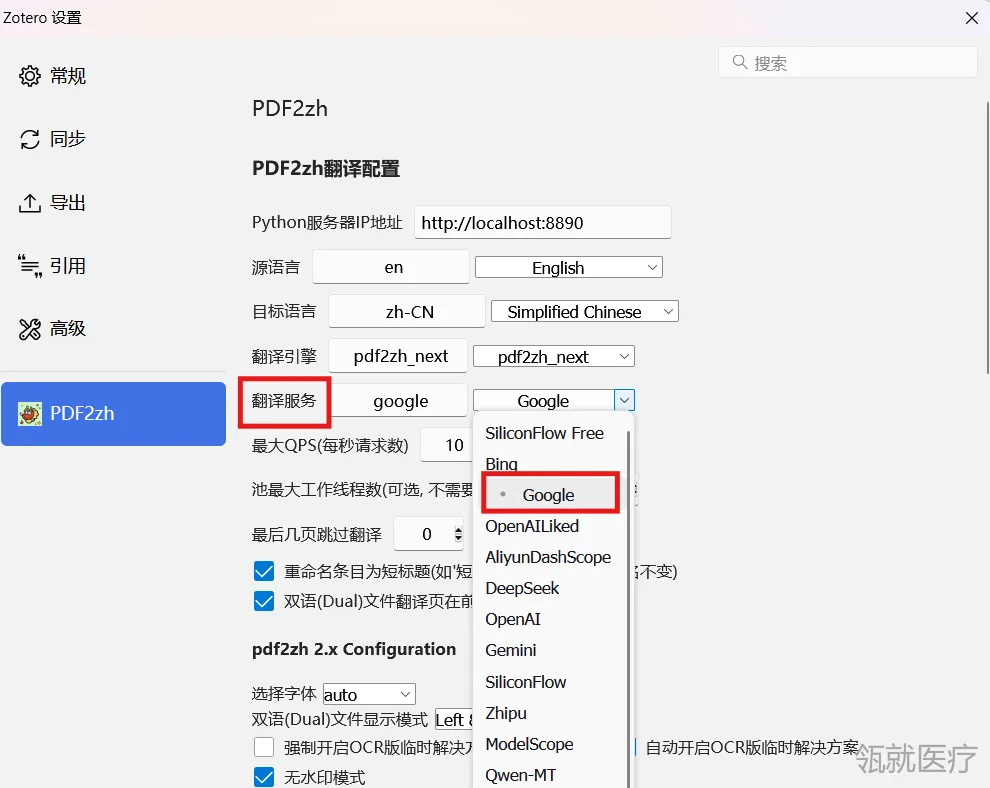
在翻译服务这一块,如果网络好的话,可以使用“Google”翻译。
Zotero设置→“PDF2zh”→“翻译服务”→“Google”。
二、AI翻译
1.点击“翻译服务”→“silicon”→“SiliconFlow。”
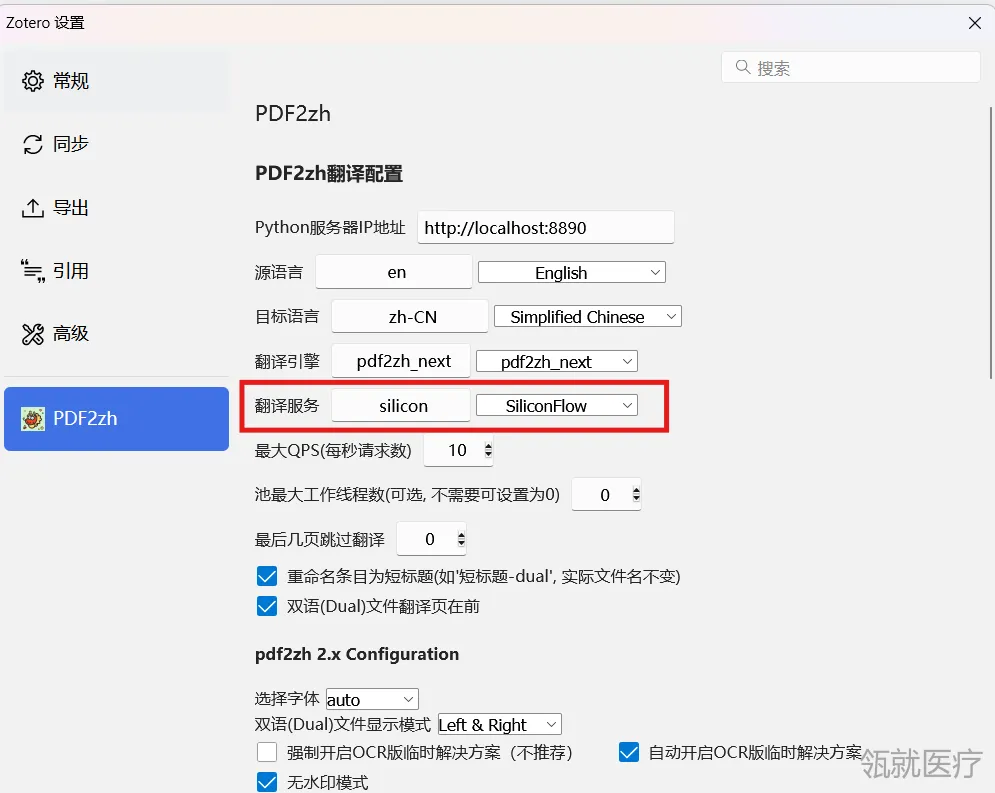
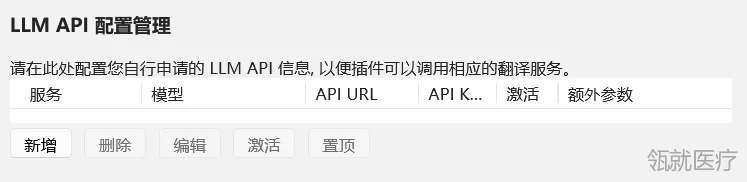
2.使用AI翻译需要配置一些参数。
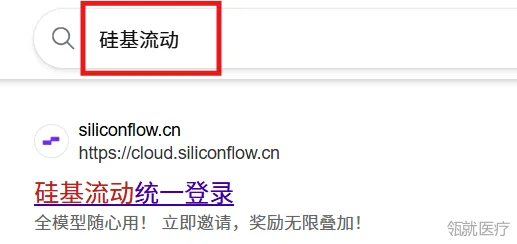
3. 在浏览器里面直接搜索硅基流动,点击进入官网。
4.注册,登录,填写邀请码可以得到一些免费的额度,邀请码在安装包里面附带了。


5. 登录进入之后就是这个界面。
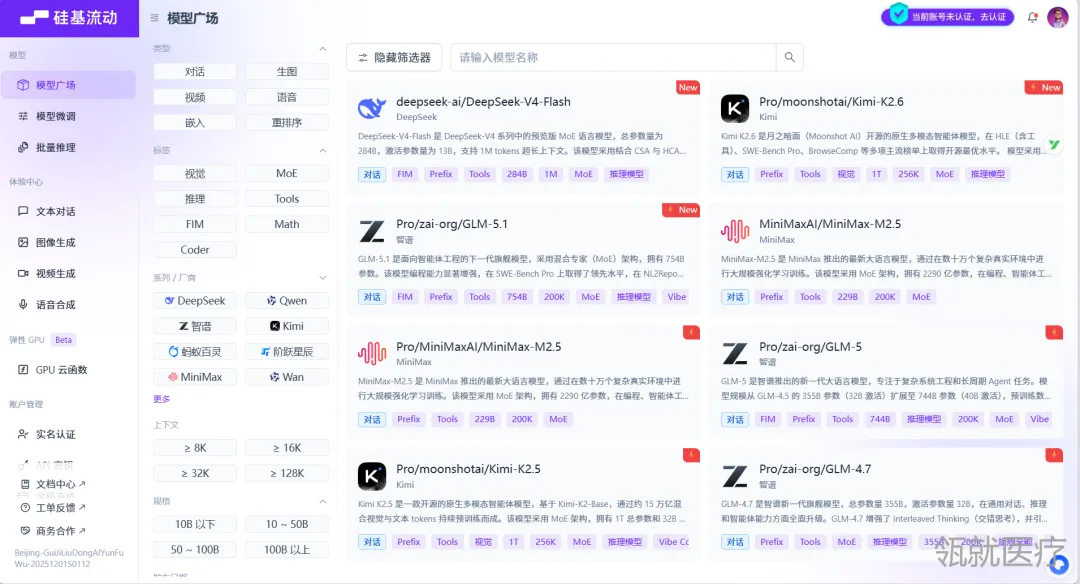
6. 输入“deepseek-v3”查找并选择。
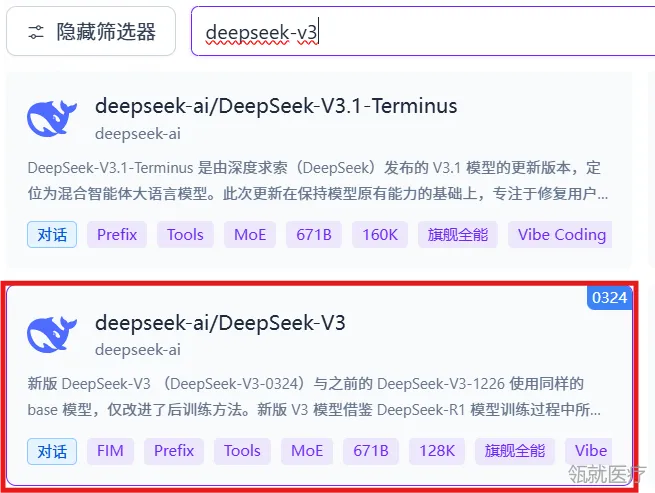
7. 将模型的名字复制一下。
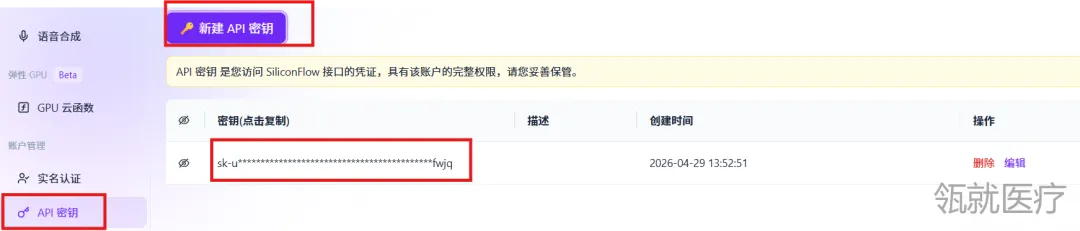
8. 新建一个API密钥。
9. 点击新增。
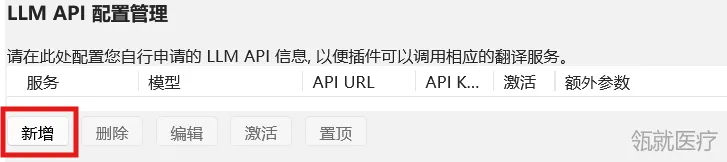
10. LLM服务名称→“SiliconFlow”,模型名称→将第7步复制的模型名称粘贴过来,LLM API KEY→将第8步新建的密码钥复制粘贴过来,保存参数。
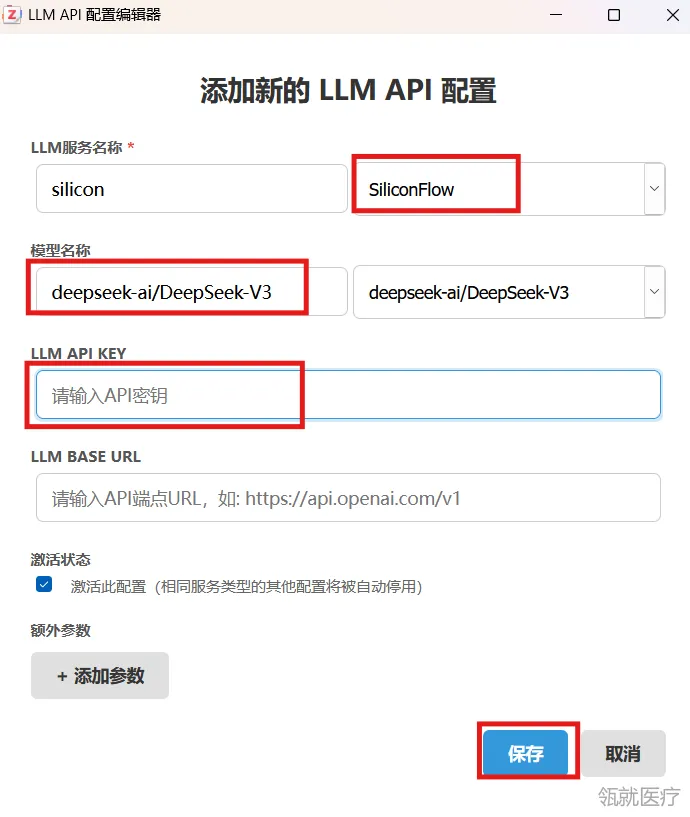
11. 这样在LLM API配置管理里面就添加好了,配置好了之后就可以使用AI翻译了。

常见问题报错及解决办法:
下面是总结的一些情况还有解决办法,希望能对后面的同学有用:
一、 警告:Failed to hardlink files
可能原因:你的插件文件夹和缓存不在同一个硬盘/分区、文件夹权限不足,无法创建快捷链接、文件系统不支持(如移动硬盘、共享文件夹)。
解决方法:把插件文件夹放到纯英文、无中文的路径(如D:\translate),直接忽略,不影响翻译功能;或设置环境变量:UV_LINK_MODE=copy。
二、 报错:RuntimeError: 操作失败 / 500
可能原因:翻译服务连接失败/超时/拥挤、PDF文件损坏、加密、无法读取、插件调用翻译引擎时内部崩溃
解决方法:更换翻译服务、重启服务窗口、重新打印生成新PDF(最有效)、关闭对比翻译,只使用普通翻译PDF
三、 报错:The document contains too many CID chars
可能原因:PDF字体加密/特殊编码、PDF是扫描版+坏字体无法直接提取文字
解决方法:打开OCR强制识别、打开增强兼容性、打印为新PDF彻底解决
四、 报错:The document contains no paragraphs
可能原因:PDF是纯图片扫描件、没有可复制的文字图层、插件识别不到任何文本
解决方法:必须开启OCR、开启自动OCR workaround、重新打印生成新PDF
五、 提示:No config_map found for service: google
可能原因:该服务没有内置默认配置、属于正常提示,不是错误,不影响翻译功能
解决方法:直接忽略、能用就正常用、不用修改任何配置
给大家再推荐一个老牌的在线PDF翻译网站—翻译狗,不需要下载安装,翻译效果也很不错,翻译后的格式排版是保持不变的,PDF图表也可以在不变形的情况下翻译。网站还接入了DeepL、OpenAI翻译引擎,能翻译的文档格式也很多,支持批量翻译,体验下来还挺靠谱的。地址留下边,给大家做个参考,不需要的忽略掉就好。
地址:www.fanyigou.com/trans/totran.html#D01
有什么问题可以留言哦,祝大家科研顺利!咱们下期再见!




