 夜雨聆风
夜雨聆风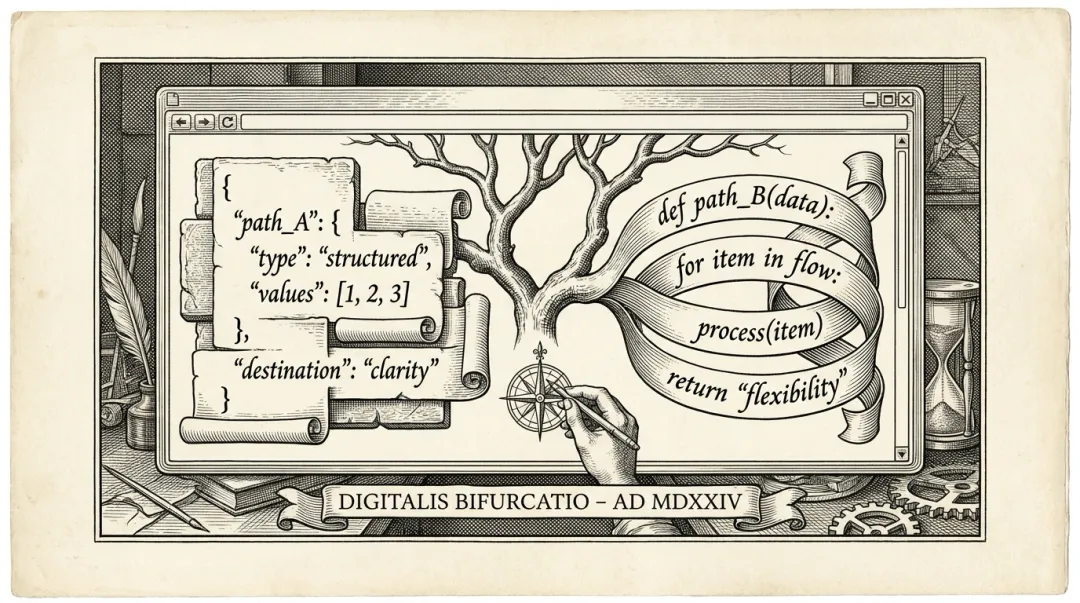
上周我在看 HF 那门 AI Agents 课程的 Unit 2,讲框架的那一章。翻到 smolagents 的部分时,我愣了一下。
课程里一段示例代码,让模型写了一段 Python,里面连着调了三个工具:先查天气,把结果存进变量,再基于这个变量查航班价格,最后根据航班价格决定要不要查酒店。
一段代码。三个工具。变量共享。
我想了半天——等等,我每天用的 Claude 不是这么工作的啊?
Claude 调工具,是一次一个 JSON:「我要调 get_weather,参数是这些。」然后等结果回来,下一轮再「我要调 get_flights,参数是那些。」一轮一个,明明白白。不是一段代码里"连着来"。
这两种模式差了多远?差的不是写法,是范式。
你每天用的几乎所有主流 AI 助手——Claude、GPT、Gemini——都在用同一种模式:JSON Tool-calling。模型输出一段结构化的 JSON,说"我要调哪个工具、参数是什么",后端拿这段 JSON 去执行,把结果塞回来,下一轮继续。
HF 在 smolagents 里推的是另一种:Code Agent。模型直接输出一段代码(通常是 Python),框架在沙箱里执行,把执行结果作为新的 observation 返回。
差别在哪?
JSON 是一问一答式:每次只能调一个工具,每轮只做一件事,状态全靠上下文窗口维系。像是你站在柜台外,递一张纸条进去,店员看完给你一样东西,你再递下一张纸条。
Code 可以一次操作一组:变量可以在代码里复用,循环、判断、中间处理都能写进同一段代码,一次执行出来的中间结果,直接就能被后面的代码用上。像是你直接走进厨房,可以连续做五件事,锅里的东西出来了就能装盘。

第一次看到这种差别时我脑子里蹦出来一个问题——这么基础的范式分叉,为什么我在中文的 Agent 讨论里从来没见过?
这不是 HF 一家在推
如果只是 HF 自己推出来的东西,还可以说它是小众实验。但我后来发现——学术圈已经有人在严肃地做这两种范式的对比测试了。
一个叫 DPAB-α(Dria Pythonic Agent Benchmark)的评测,专门用 100 个问题,量化对比"Pythonic function calling"(也就是 Code Agent)和"traditional JSON-based methods"的性能差异。这是一个正经的 benchmark,收录在 Philipp Schmid(前 Hugging Face 员工,现在在 Google DeepMind)汇编的那份 49 个 Agent benchmark 清单里。
换句话说,在英文圈,这条分叉不是"有人提了一嘴的小想法",是已经有独立 benchmark 在帮两种范式打分的研究方向。
但我在国内的 Agent 讨论里,从来没见过有人提 DPAB-α。
也很少有人把 Code Agent 作为一个独立话题讲。
我特意去扫了一遍 Datawhale 最新的 Hello-Agents 教程,16 章的系统教程,覆盖了 ReAct、LangGraph、AutoGen、MCP 协议、Agentic-RL 训练。相当全了。但是 Code Agent 没有独立章节,smolagents 也没单独提。
问题不在这些教程不好。问题是:为什么这条分叉在中文圈是"隐形"的?
为什么中文圈看不到这条分叉
我的一个假设是——不是水平问题,是生态路径依赖。
你想想,在中国做 Agent 的开发者,大部分接触 Agent 是通过什么?要么是 Claude Code / Cursor 这种工具,要么是 OpenAI / Anthropic 的 API。这些入口全都用 JSON tool-calling。你从一开始学 Agent,就被默认装配了 JSON 范式的世界观。
Code Agent 的主要推动者是谁?HF 生态+开源小模型社区。在中国,这个圈子相对小、相对边缘。大家默认对标的是大厂 API,不是 HF Spaces 上的开源实验。
不是我们选择了 JSON,是 JSON 被生态选择给了我们。
这让我想起一件事——二十年前学英语的人很少会意识到,你学的是"英式"还是"美式",取决于你一开始接触的课本是谁出版的。不是你挑了哪种口音,是哪种口音挑了你。你能不能说 fair enough 或 no worries,是由你童年的第一本教材决定的。
AI Agent 范式也差不多是这个逻辑。
被遮蔽比选错更可怕
到这里有个更扎人的问题——在不知情的情况下默认用某个范式,和在看清两种选项后选了其中一个,是完全不一样的事。
前者是被生态定义的结果。后者是独立判断力的结果。
如果你看过 JSON 和 Code 两种范式,权衡了表达力、稳定性、审计难度、生态大小之后选择了 JSON——那这个选择是你的。你知道 Code 是一种可能,你只是这次不选。
如果你从头到尾只见过 JSON,根本不知道 Code Agent 存在——那你连选择都没发生。
这两种状态在日常 coding 里看起来没差别,你照样写代码,一样能让 Agent 跑起来。但在遇到真正复杂的工具链任务时——需要多个工具串起来、中间结果要复用、逻辑判断要穿插——不知道 Code Agent 的人,会在 JSON 里拼命 hacking,想办法把一个原本适合用 Code 表达的问题拆成一串 JSON 调用。
不是选错,是被遮蔽,这才是最可怕的地方。
美中不足:Code Agent 不是银弹
说了这么多 Code Agent,也得把缺点摊开说清楚,不然就变成推销了。
Code Agent 最明显的问题是安全。让模型生成任意 Python 代码+沙箱执行,攻击面比 JSON schema 大得多。JSON 的好处就在于——字段是预定义的,参数是有类型的,每一次调用都是白盒,审计起来简单。生产环境里,尤其是涉及金融、医疗、法律这种高风险领域,JSON 的可预测性几乎是刚需。
而且 Code Agent 对模型的要求也更高——它要能生成正确的代码,还要知道什么时候不该 import 危险模块。小模型跑这种模式很容易翻车。DPAB-α 那 100 个问题也不是大样本,学术界对"哪种范式更好"其实还没打出结论。
所以如果你真要在生产系统里选——Code Agent 目前更适合"你自己控"的场景:个人工具、研究流程、开源 hacky 项目。JSON 在跨团队协作、合规审计、长生命周期的系统里更稳。
这不是非此即彼,是两条路都要知道的工程判断题。
那我到底该怎么办
如果你已经在用 Claude、GPT 或 Gemini 写东西——什么都不用改。你的代码继续跑。
但下次你看到一个新的 Agent 框架、新的工具、新的范式时,可以多问一个问题:
这东西用的是 JSON tool-calling 还是 Code Agent?
光是多问这一句,就把你从"被生态默认定义"的状态,挪到了"我在清醒地选"的状态。
真的只是一句话的事。
然后有机会扫一眼 smolagents 的文档。不一定要用,看一眼就行。看一眼之后你再回去看你天天用的 Claude,你会发现同一个 Agent 问题,原来可以有两种完全不同的写法。
知道有第二条路,比走上哪条路重要。
写在最后
我写这篇文章不是让你倒向 Code Agent,也不是让你怀疑 JSON。
是想把中文 Agent 讨论里那条没被提起过的分叉,摆到桌面上。
一个范式被讨论过,它就是一个"选项";一个范式没被讨论过,它就只是"没发生"。中文圈的 Agent 讨论如果要继续往深里走,这种"没发生"的选项迟早要被挖出来。
希望这篇是一个开头。
如果你在自己的项目里试过 smolagents / Pythonic function calling,或者你有更好的理解,欢迎留言告诉我。我想听听你那边的版本是什么样的。
专业劈叉式跨界选手:🧬 医学出身,🎭 文化口饭碗,🤖 AI 是我的野路子。不卷参数,不追新模型,只关心一个问题:AI 啥时候能装进我脑子,替我不开心?欢迎围观我和 AI 相爱相杀的日常。——AI不会取代你,但会用AI的人会。所以我先学了,你随意。🔧踩坑副产品已开源 → recallnest,telegram-ai-bridge,claude-code-studio,content-alchemy,openclaw-tunnel,content-publisher,digital-clone-skill,telegram-cli-bridge参与组织 → CortexReach(memory-lancedb-pro 贡献者,setup-memory.sh 一键脚本作者)本文由 Content Alchemy 自动生成,由 Claude Code 发布。
