 夜雨聆风
夜雨聆风大家好,我是James。
上一篇我们把 GraphRAG 拆了个底朝天,搞清楚了知识图谱怎么接进检索链路、多跳推理为什么准确率能翻倍。这篇我们换一个维度——不聊图谱了,聊「图片」。
真实业务的文档里,有多少内容是纯文字的?不多。一份技术报告里大量是架构图;一份财务 PDF 里最关键的是那张趋势表格;一份产品文档里全是截图和流程图。你用纯文本 RAG 去做检索,模型看到的是 OCR 识别后的乱码,或者直接就是空——图片根本没进知识库。
结果就是:用户问「第三页那个流程图怎么理解」,系统返回一大堆不相关的文字段落,或者直接说「没找到相关信息」。
这坑,把太多人坑过了。
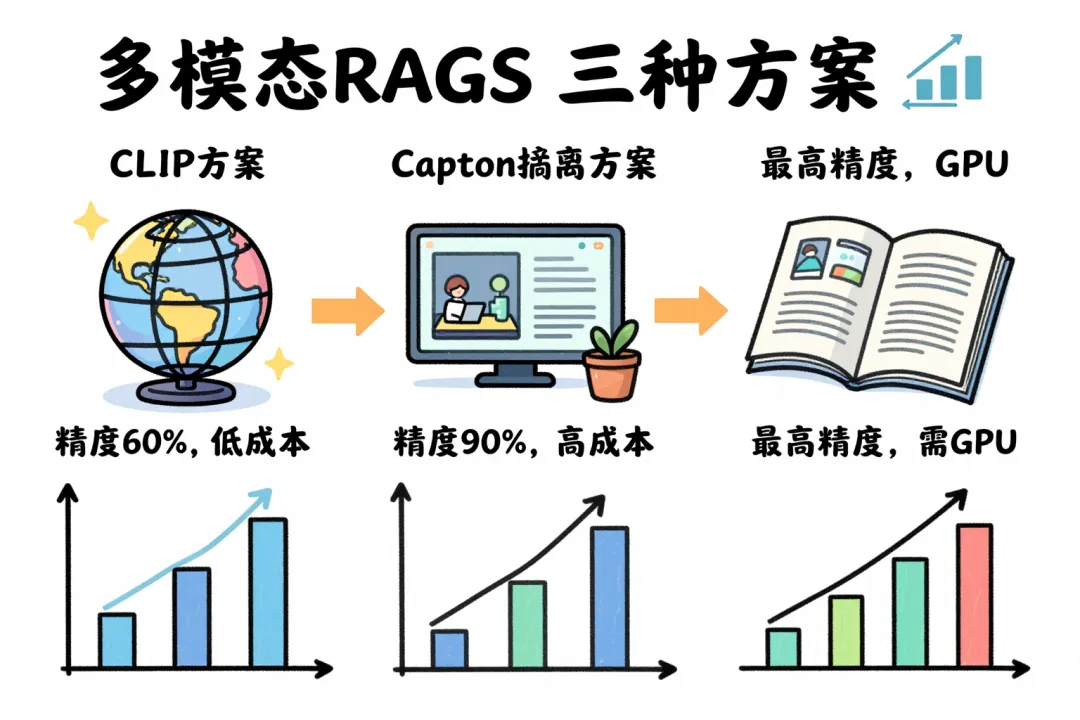
这篇我们从三种主流方案入手,把多模态 RAG 的实现路径一次讲透:图片怎么入库、表格怎么处理、复杂 PDF 怎么解析,以及什么场景用哪种方案。
01 纯文本 RAG 的视觉盲区:信息不处理就丢失
先把问题说清楚,再谈方案。
当你用 UnstructuredLoader 或 PDFLoader 加载一份 PDF 时,底层是这样处理内容的:文字内容直接提取为文本(成功);表格则交给 OCR 识别,结构往往被破坏;图片要么直接丢弃,要么保存为图片文件但没有任何处理——对检索系统来说等于不存在。
丢失的不是装饰,往往是核心信息:架构图里的系统组件关系、财务表格里的季度增长数字、操作手册里的界面截图。我有个客户搭了个内部知识库,工程师反映检索总是答非所问。排查发现:核心系统架构知识全存在 PPT 的图里,文本提取拿到的是「架构设计(详见图2)」这种废话。
解法有三条路,先看一眼对比:
| 方案 | 核心思路 | 精度 | 成本 | 适用场景 |
|---|---|---|---|---|
| 多模态嵌入(CLIP) | 图文映射到同一向量空间 | ~60% | 低 | 图像相似搜索 |
| 图生文摘要(Caption) | VLM 先把图片转为文字描述,再做文本检索 | ~90% | 中-高 | 文档精准问答 |
| ColPali 视觉检索 | 整页 PDF 直接作为图片索引,零 OCR | 最高 | 中 | 复杂排版文档 |
下面逐个拆。
02 方案一:CLIP 多模态嵌入——图文统一向量空间
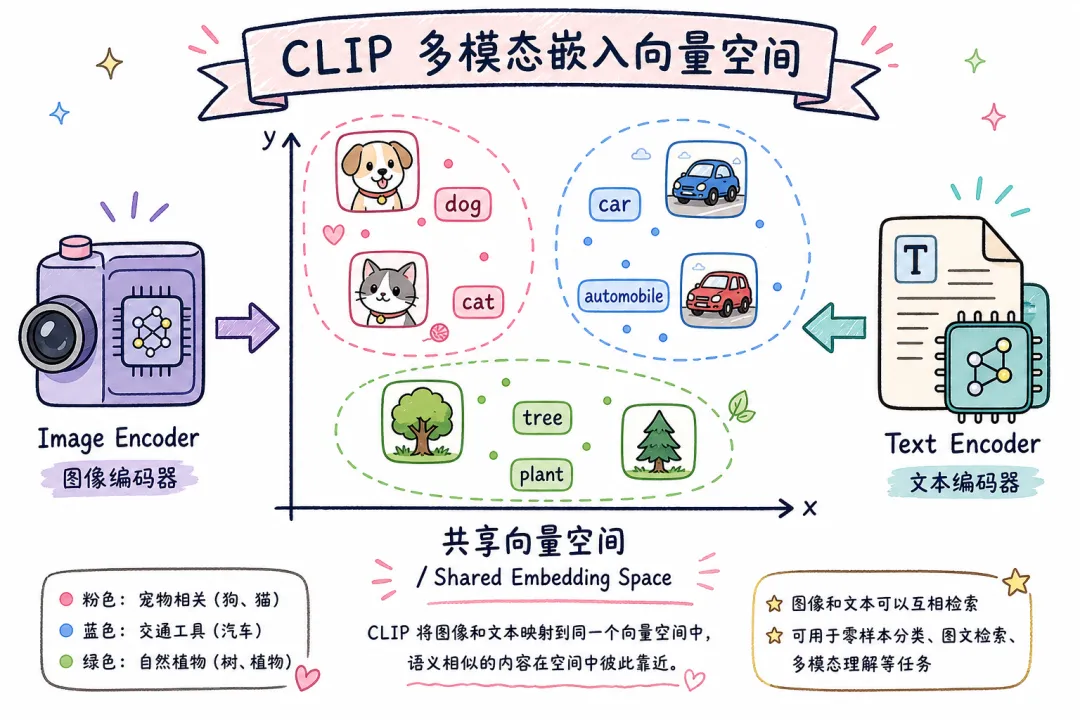
CLIP 是 OpenAI 2021 年发布的对比学习模型,核心能力是:把文字和图片映射到同一个高维向量空间,语义相近的文字和图片,在空间里距离相近。用文字问,它能找到语义最匹配的图片。
TypeScript 实现:LangChain + ChromaDB + OpenCLIP
import { Chroma } from "@langchain/community/vectorstores/chroma";
import { OpenCLIPEmbeddings } from "@langchain/community/embeddings/openclip";
import { ChatOpenAI } from "@langchain/openai";
import * as fs from "fs";
import * as path from "path";
// 1. 初始化多模态向量库
const embeddings = new OpenCLIPEmbeddings();
const vectorStore = await Chroma.fromExistingCollection(embeddings, {
collectionName: "multimodal_docs",
});
// 2. 图片和文字都写入同一向量库
const imageUris = fs
.readdirSync("./docs/images")
.filter((f) => f.endsWith(".png") || f.endsWith(".jpg"))
.map((f) => path.join("./docs/images", f));
await vectorStore.addImages(imageUris); // 图片用 URI 写入
await vectorStore.addDocuments([
{ pageContent: "Q3 企业级销售推动了 15% 的营收增长", metadata: { type: "text" } },
]);
// 3. 文字查询,检索最匹配的图片
const retriever = vectorStore.asRetriever({ k: 3 });
const results = await retriever.invoke("Q3 营收增长趋势");
// 4. 把检索到的图片送给 VLM 回答
const visionModel = new ChatOpenAI({ model: "gpt-4o" });
for (const doc of results) {
if (doc.metadata.type === "image") {
const imageBase64 = fs.readFileSync(doc.metadata.uri, "base64");
const response = await visionModel.invoke([
{
role: "user",
content: [
{ type: "text", text: "分析这张图表,总结核心趋势" },
{ type: "image_url", image_url: { url: `data:image/png;base64,${imageBase64}` } },
],
},
]);
console.log(response.content);
}
}
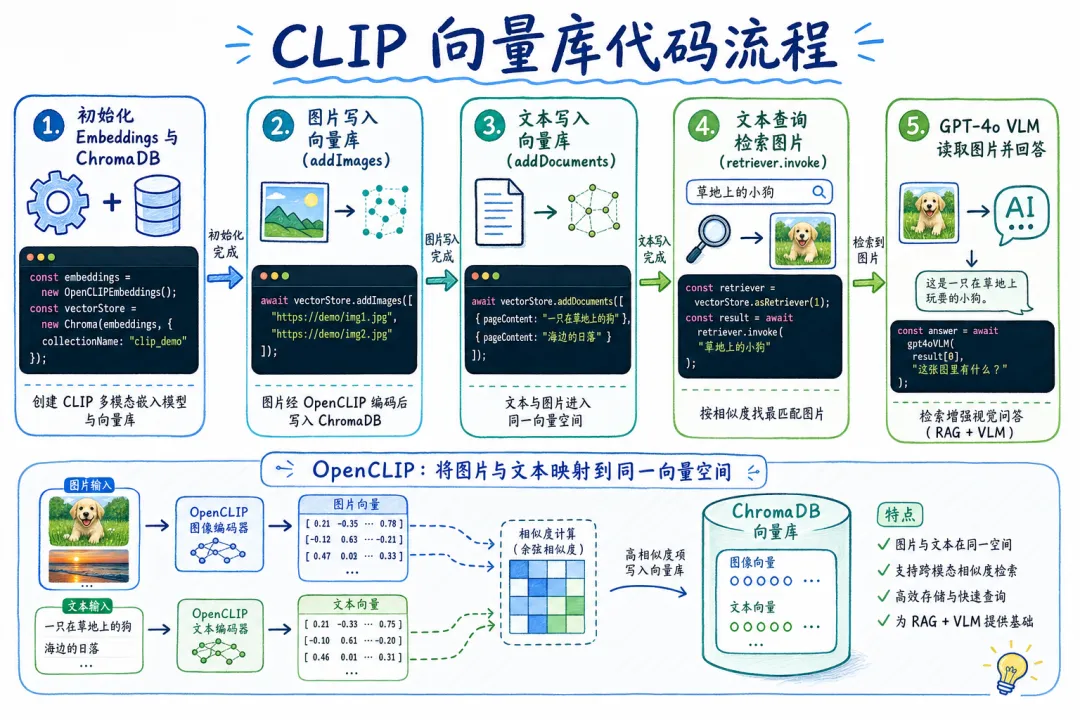
CLIP 的短板在哪?
它给每张图生成的是一个全局向量——一张图里同时有文字、表格、折线图,压缩成一个向量之后细节全没了。你问「表格第三行的数字」,它可能找到一张完全不相关但视觉相似的图。精度 ~60% 的根源就在这里:全局向量必然丢细节,细粒度查询答不上来。
03 方案二:图生文摘要——让 VLM 先把图「翻译」成文字
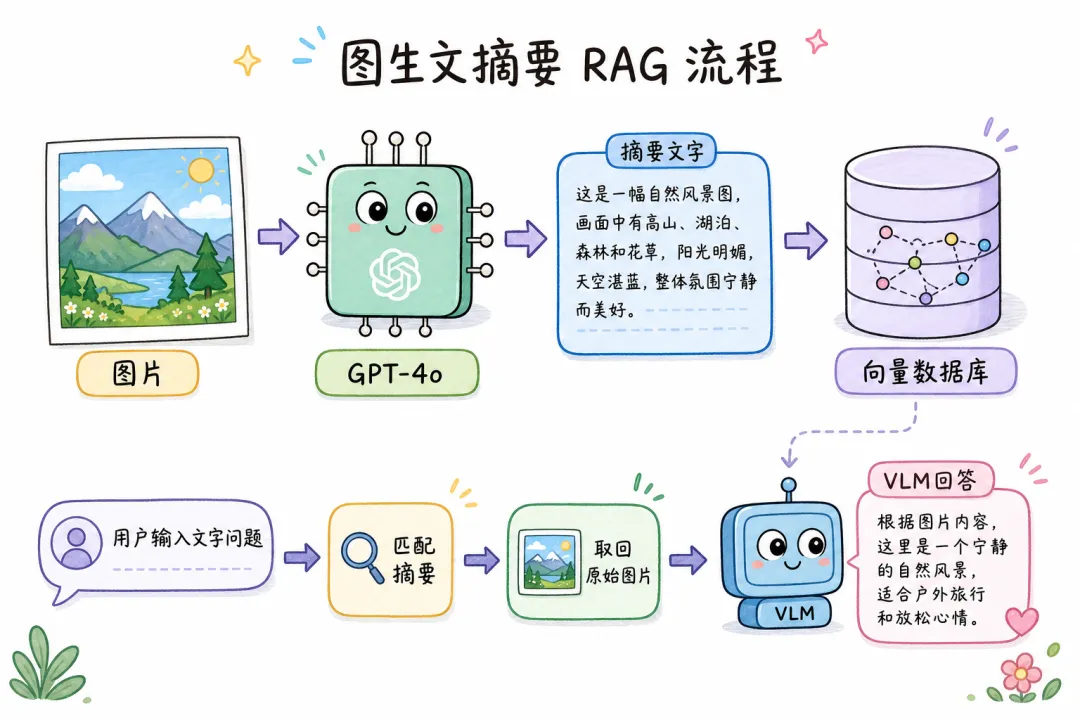
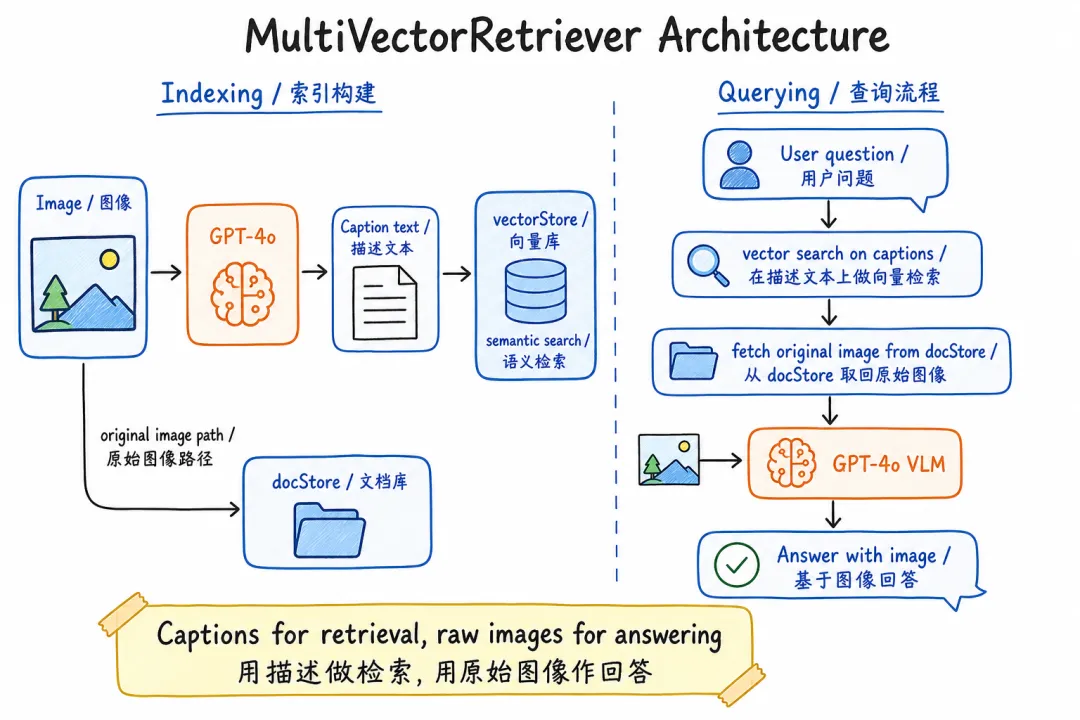
这个方案的逻辑更直接:图片本身不入向量库,让 VLM(GPT-4o / Claude)先把图片「翻译」成详细的文字描述,再把文字描述入库做检索。检索时用文字找文字,找到匹配摘要后,再取回原始图片送给 VLM 作答。
为什么精度能到 90%?Caption 是模型读懂图片后的文字描述,包含了图中所有关键信息:数字、趋势、结构关系。文本检索本来就精度高,配合高质量 Caption,效果自然好。
TypeScript 实现:MultiVectorRetriever 方案
import { MultiVectorRetriever } from "langchain/retrievers/multi_vector";
import { InMemoryStore } from "@langchain/core/stores";
import { OpenAIEmbeddings, ChatOpenAI } from "@langchain/openai";
import { Chroma } from "@langchain/community/vectorstores/chroma";
import { Document } from "@langchain/core/documents";
import { v4 as uuidv4 } from "uuid";
import * as fs from "fs";
const visionModel = new ChatOpenAI({ model: "gpt-4o" });
const embeddings = new OpenAIEmbeddings();
// Step 1: 用 GPT-4o 生成图片摘要(Caption)
async function generateImageCaption(imagePath: string): Promise<string> {
const imageBase64 = fs.readFileSync(imagePath, "base64");
const response = await visionModel.invoke([
{
role: "user",
content: [
{
type: "text",
text: "请详细描述这张图片:图片类型(流程图/表格/折线图等)、主要数据或结论、关键元素之间的关系。100-200字,尽可能具体。",
},
{ type: "image_url", image_url: { url: `data:image/png;base64,${imageBase64}` } },
],
},
]);
return response.content as string;
}
// Step 2: 批量生成摘要
const imageFiles = ["./docs/arch_diagram.png", "./docs/q3_revenue.png"];
const captions = await Promise.all(imageFiles.map(generateImageCaption));
// Step 3: 建立 MultiVectorRetriever(摘要入向量库,原图路径入 docStore)
const vectorStore = await Chroma.fromDocuments([], embeddings, {
collectionName: "image_captions",
});
const docStore = new InMemoryStore();
const retriever = new MultiVectorRetriever({ vectorstore: vectorStore, byteStore: docStore, idKey: "doc_id" });
const ids = imageFiles.map(() => uuidv4());
const captionDocs = captions.map((caption, i) =>
new Document({ pageContent: caption, metadata: { doc_id: ids[i] } })
);
await retriever.vectorstore.addDocuments(captionDocs);
await retriever.byteStore.mset(
ids.map((id, i) => [id, new TextEncoder().encode(imageFiles[i])])
);
// Step 4: 查询时返回的是原始图片路径(不是摘要)
const results = await retriever.invoke("系统架构里的核心组件是什么");
// 拿到图片路径,传给 VLM 作答
成本是真实痛点。 给 1000 张图批量生成 Caption,GPT-4o 的费用可能是 20-50 美元(视图片复杂度)。图片多的知识库,入库成本不小。而且 Caption 质量直接决定检索上限——「这是一张图片,包含一些数字」这种摘要等于没写。
04 方案三:ColPali 视觉检索——把整页 PDF 当图片索引
前两种方案都有一个共同前提:你得先把 PDF 里的图片提取出来。但真实 PDF 排版复杂度超出想象:多栏排版文字和图交错、扫描版 PDF 根本没文字层、表格边界模糊 OCR 识别后乱成一锅粥、公式化学结构式纯文本提取全废。
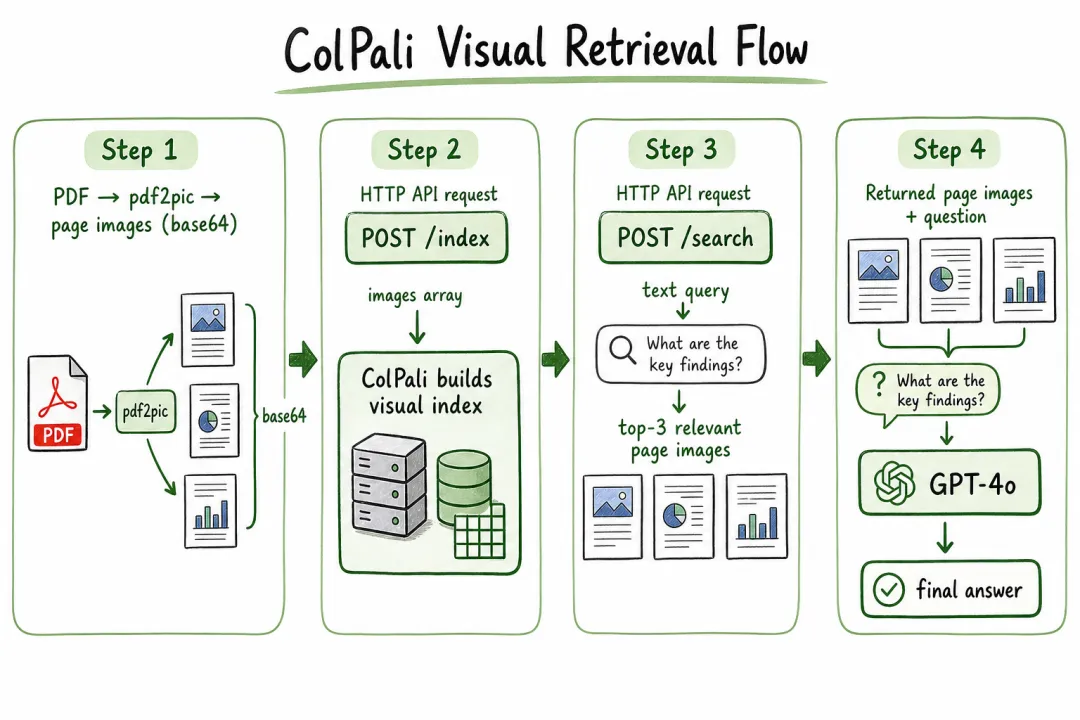
ColPali(PaliGemma + 视觉后期交互)的思路是:不提取,直接把整页 PDF 当图片索引。
传统方案走 PDF → OCR/解析 → 文本块 → 向量化 → 检索,OCR 错误率 5-15%,表格结构常常被破坏。ColPali 走 PDF → 渲染为页面图片 → 视觉 Transformer 编码 → 多向量索引 → 检索,保留原始排版,零 OCR 误差。
它用 Late Interaction 机制(类似 ColBERT),把查询的每个 Token 向量与文档页面的每个视觉 Patch 逐一比对,不是整页压缩成一个全局向量,精度显著高于 CLIP。
TypeScript 集成 ColPali 服务
import { ChatOpenAI } from "@langchain/openai";
import * as fs from "fs";
// ColPali 服务封装(本地或云端部署,需 GPU 16GB+)
async function indexPdfWithColPali(pdfPath: string): Promise<string[]> {
// 1. 把每页 PDF 渲染为图片(用 pdf2pic / pdfjs 等库)
const pageImages: string[] = []; // base64 编码的页面图片数组
// 2. 调用 ColPali 服务批量建索引
const indexResp = await fetch("http://localhost:8000/index", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ images: pageImages, collection_id: "my_docs" }),
});
const { doc_ids } = await indexResp.json();
return doc_ids;
}
async function queryWithColPali(query: string): Promise<string> {
// 3. 文字查询,返回最相关的页面图片
const searchResp = await fetch("http://localhost:8000/search", {
method: "POST",
headers: { "Content-Type": "application/json" },
body: JSON.stringify({ query, collection_id: "my_docs", top_k: 3 }),
});
const { results } = await searchResp.json(); // base64 图片数组
// 4. 把相关页面图片送给 VLM 作答
const visionModel = new ChatOpenAI({ model: "gpt-4o" });
const answer = await visionModel.invoke([
{
role: "user",
content: [
{ type: "text", text: query },
...results.map((img: string) => ({
type: "image_url",
image_url: { url: `data:image/png;base64,${img}` },
})),
],
},
]);
return answer.content as string;
}
await indexPdfWithColPali("./technical_report.pdf");
const answer = await queryWithColPali("第三章架构图里的核心模块有哪些?");
ColPali 的现实限制:需要运行 PaliGemma 模型,至少 16GB 显存,个人项目不一定划算。Vespa、Milvus 已开始原生支持 ColPali 索引,未来部署门槛会降低。
05 表格的特殊处理:结构信息不能丢

表格是最容易被忽视又最重要的内容类型。纯文本提取之后,季度 Q1 Q2 Q3 Q4 / 营收 120 145 178 203 / 增长 - 20.8% 22.8% 14.0% 这样一行行数字的行列关系完全丢失,VLM 根本读不懂。
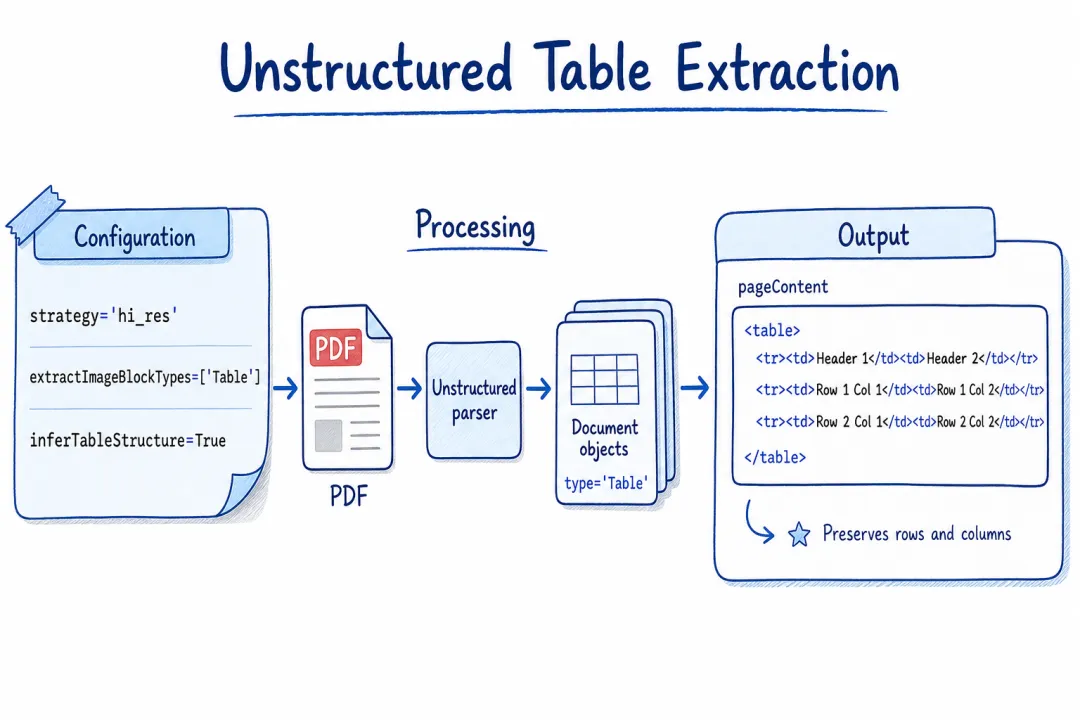
策略一:用 unstructured 提取 HTML 表格(首选)
import { UnstructuredLoader } from "@langchain/community/document_loaders/fs/unstructured";
const loader = new UnstructuredLoader("./financial_report.pdf", {
strategy: "hi_res", // 高精度模式
extractImageBlockTypes: ["Table"], // 专门提取表格
inferTableStructure: true, // 推断表格结构
outputFormat: "application/json",
});
const docs = await loader.load();
// 表格元素有 type: "Table" 标记,pageContent 是保留行列结构的 HTML
const tables = docs.filter(d => d.metadata.type === "Table");
// 单独入库,加上 source_page、table_index 等元数据,检索时按类型过滤
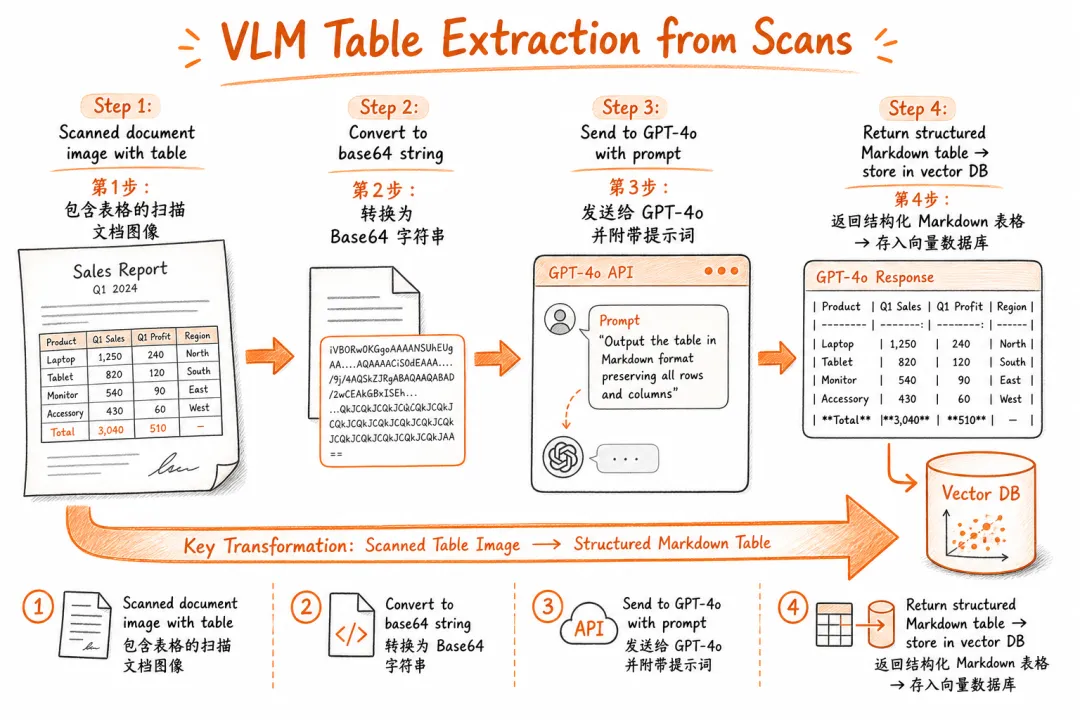
策略二:扫描版表格截图直接送 VLM
async function extractTableFromImage(imagePath: string): Promise<string> {
const visionModel = new ChatOpenAI({ model: "gpt-4o" });
const imageBase64 = fs.readFileSync(imagePath, "base64");
const response = await visionModel.invoke([
{
role: "user",
content: [
{ type: "text", text: "把这张表格以 Markdown 格式输出,保留完整的行列结构和所有数值。" },
{ type: "image_url", image_url: { url: `data:image/png;base64,${imageBase64}` } },
],
},
]);
return response.content as string;
}
表格处理的核心原则:不要和正文文字混在同一个 chunk 里入库。表格单独切分,加结构化元数据,检索时按表格类型过滤,精度更高。
06 完整多模态 RAG 管道:统一处理文字/表格/图片
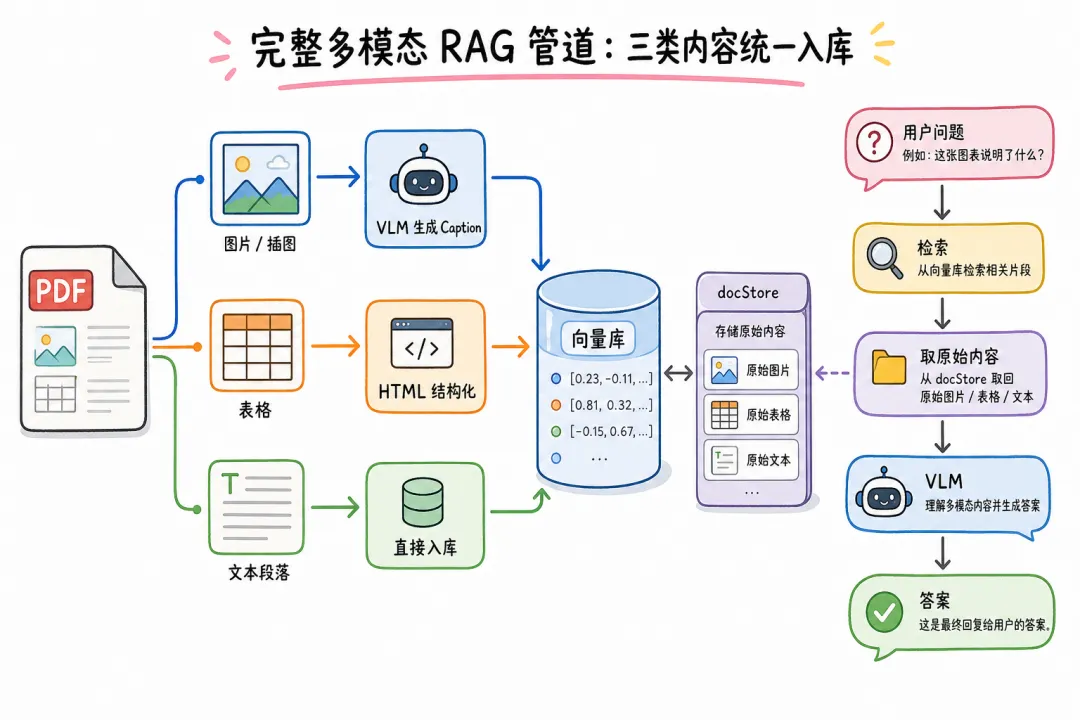
把上面的方案拼在一起,就是一个生产级的文档入库管道。核心设计原则:摘要用于检索,原始内容用于回答。向量库存摘要(检索精度高),docStore 存原始图片路径和原始表格内容(回答质量高)。
import { UnstructuredLoader } from "@langchain/community/document_loaders/fs/unstructured";
import { OpenAIEmbeddings, ChatOpenAI } from "@langchain/openai";
import { Chroma } from "@langchain/community/vectorstores/chroma";
import { MultiVectorRetriever } from "langchain/retrievers/multi_vector";
import { InMemoryStore } from "@langchain/core/stores";
import { Document } from "@langchain/core/documents";
import { v4 as uuidv4 } from "uuid";
import * as fs from "fs";
async function buildMultimodalKB(pdfPath: string) {
const visionModel = new ChatOpenAI({ model: "gpt-4o" });
const embeddings = new OpenAIEmbeddings();
// Step 1: unstructured 提取所有内容类型
const loader = new UnstructuredLoader(pdfPath, {
strategy: "hi_res",
extractImageBlockTypes: ["Image", "Table"],
inferTableStructure: true,
});
const rawDocs = await loader.load();
// Step 2: 按类型分别处理,生成(摘要, 原始内容)对
const pairs: Array<{ summary: string; raw: string; type: string }> = [];
for (const doc of rawDocs) {
if (doc.metadata.type === "Image") {
const imagePath = doc.metadata.image_path as string;
const imageBase64 = fs.readFileSync(imagePath, "base64");
const captionResp = await visionModel.invoke([
{
role: "user",
content: [
{ type: "text", text: "详细描述这张图片:类型、主要内容、关键数据或结论,100-200字。" },
{ type: "image_url", image_url: { url: `data:image/png;base64,${imageBase64}` } },
],
},
]);
pairs.push({ summary: captionResp.content as string, raw: imagePath, type: "image" });
} else if (doc.metadata.type === "Table") {
pairs.push({ summary: doc.pageContent, raw: doc.pageContent, type: "table" });
} else {
pairs.push({ summary: doc.pageContent, raw: doc.pageContent, type: "text" });
}
}
// Step 3: 摘要入向量库,原始内容入 docStore
const vectorStore = new Chroma(embeddings, { collectionName: "multimodal_kb" });
const docStore = new InMemoryStore();
const retriever = new MultiVectorRetriever({ vectorstore: vectorStore, byteStore: docStore, idKey: "doc_id" });
const ids = pairs.map(() => uuidv4());
const summaryDocs = pairs.map((p, i) =>
new Document({ pageContent: p.summary, metadata: { doc_id: ids[i], type: p.type } })
);
await retriever.vectorstore.addDocuments(summaryDocs);
await retriever.byteStore.mset(
ids.map((id, i) => [id, new TextEncoder().encode(JSON.stringify({ type: pairs[i].type, raw: pairs[i].raw }))])
);
return retriever;
}
查询时,根据检索到的内容类型分别处理:图片取路径后 base64 送 VLM,文字和表格直接作为文本上下文,全部打包给 VLM 一次性回答。
07 常见坑:这些问题让多模态 RAG 上线后一塌糊涂
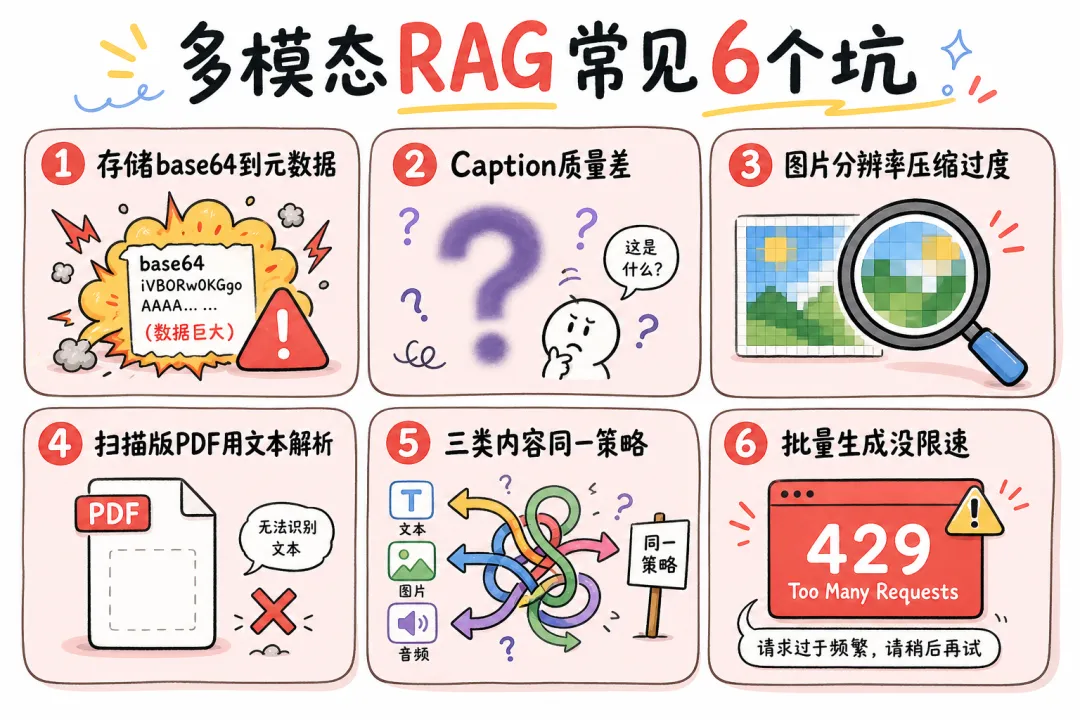
坑 1:把 base64 图片存进向量库元数据
一张 PNG 图 base64 之后轻松 500KB 到 2MB,存进 ChromaDB 元数据里,几百张图之后性能直线下降,还可能触发存储限制。正确做法:图片存磁盘或对象存储(OSS/S3),元数据里只存路径或 URL。
坑 2:Caption 质量太差
「这是一张图片,包含一些数字和图表」这种摘要没有任何用处。Caption 必须包含:图片类型、具体数值、趋势描述、关键结论。Prompt 工程直接决定你的检索天花板。
坑 3:图片分辨率压缩过度
很多人为了省 Token 把图片压缩到 200×200,结果图里的数字全模糊了,GPT-4o 也看不清。合理做法:下采样到 1024×768,清晰度和 Token 消耗取平衡点。
坑 4:扫描版 PDF 直接用文本解析
扫描版 PDF 本质是一张图,没有文字层,PDFLoader 加载得到空文档。必须先跑 OCR(unstructured 高精度模式),或者直接用 ColPali。
坑 5:三种内容用同一检索策略
表格适合精确检索(BM25),图片 Caption 适合语义检索(向量),长文档适合混合检索。混在同一个 collection 里用同一个参数,精度被平均拉低。
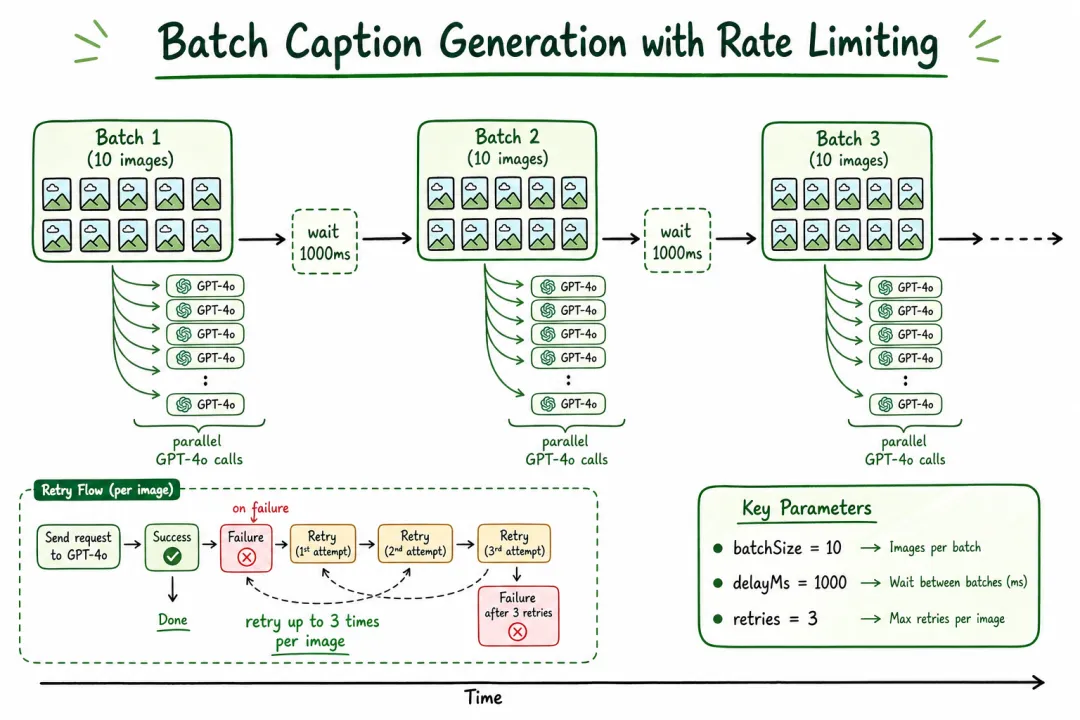
坑 6:Caption 批量生成没有限速
一次性给 GPT-4o 发 200 张图,触发 Rate Limit,任务挂掉。Caption 生成要批次控制(每批 10-20 张)+ 重试机制:,触发 Rate Limit,任务挂掉。Caption 生成要批次控制(每批 10-20 张)+ 重试机制:
async function batchGenerateCaptions(imagePaths: string[], batchSize = 10, delayMs = 1000): Promise<string[]> {
const captions: string[] = [];
for (let i = 0; i < imagePaths.length; i += batchSize) {
const batch = imagePaths.slice(i, i + batchSize);
const batchCaptions = await Promise.all(batch.map(p => generateImageCaptionWithRetry(p, 3)));
captions.push(...batchCaptions);
if (i + batchSize < imagePaths.length) {
await new Promise(resolve => setTimeout(resolve, delayMs));
}
}
return captions;
}
总结
多模态 RAG 的核心矛盾是:你的文档有多少信息在图里,而不是在文字里。 搞清楚这个,选方案就有方向了:
CLIP 多模态嵌入:实现简单、成本低,但全局向量丢细节,精度约 60%,适合图片相似搜索,不适合精准文档问答 图生文摘要(Caption + MultiVectorRetriever):精度最高(~90%),检索走文字、回答走原图,代价是入库成本高,图片多时费用可观 ColPali 视觉检索:整页 PDF 当图片索引,零 OCR 误差,复杂排版文档首选,但需要 GPU 部署(16GB 显存起步) 表格必须单独处理:用 unstructured保留 HTML 结构,或截图给 VLM 提取,绝对不要和正文混在同一个 chunk 里
下一篇进入板块三:路由策略。我们先聊 LLM 语义路由——为什么用关键词做意图分类这条路越来越走不通,以及让模型本身做意图判断是怎么实现的。
关注我,James 的成长日记,持续分享干货,帮你在 AI 时代少走弯路。
