 夜雨聆风
夜雨聆风自己在设计Agent时,难免遇到不少问题,比如,知识库如何构建,上下文怎么设计,窗口超限时怎么压缩。
与其闷头苦想,不如直接看看当前最优秀的Agent框架之一的codex[1]。
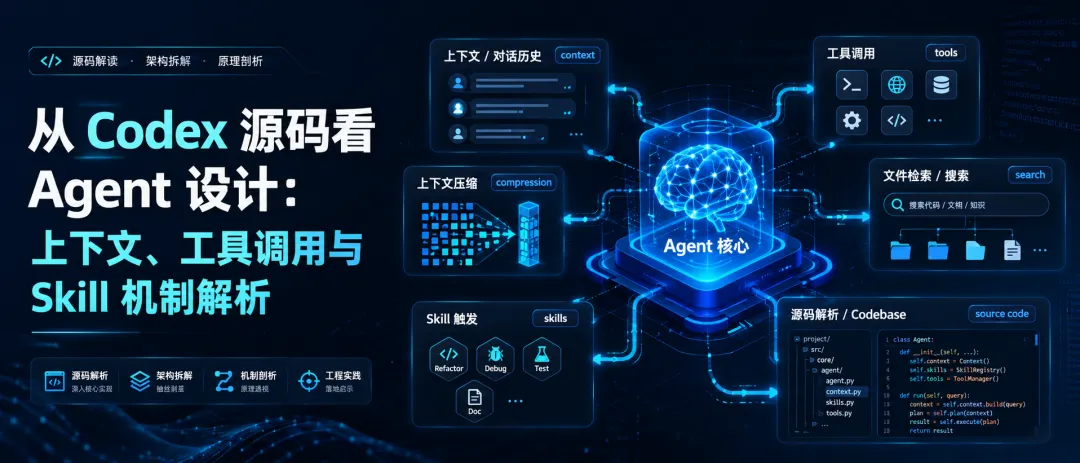
本文将借助 codex 来基于 codex 的源码,回答以下问题:
发送一轮请求,会附带什么内容? 如何去查找相关文件? 上下文超限时,如何压缩? skill是如何触发的?
发送一轮请求,会附带什么内容?
1.底层行为提示词
类似于系统提示词”的部分。它告诉模型自己是 Codex、怎么做代码任务、怎么用工具、怎么回答等。
具体可参见codex/codex-rs/protocol/src/prompts/base_instructions/default.md
它最终作为 Responses API 的 instructions 字段发送,区别于普通聊天历史的一条 message。
2.会话上下文消息
Codex 自己追加的上下文。首次请求时会比较完整,后续请求一般只追加变化项,主要包括:
当前权限:能不能写文件、能不能联网、需不需要审批 当前环境:工作目录、shell、日期、时区 项目说明:AGENTS.md 里的规则 可用能力:skills、plugins、apps/connectors 特殊模式:collaboration mode、personality、realtime 等
3.对话历史
之前发生过的内容,包括:
用户之前说过的话 模型之前的回答 模型请求过哪些工具 工具返回过什么结果
4.当前用户发送的这条消息
用户刚刚输入的内容,它会追加到历史里,然后和前面的所有信息一起发给模型。
后续请求时,这些内容不会每次都重新塞一遍完整初始上下文,基础提示词仍然会作为 instructions 存在,如果环境、权限、模型、realtime、personality 等变化了,会追加一个“变化说明”,如果没变化,就不重复发完整说明。
如何去查找相关文件?
Codex 并不会将工程里的所有文件一次性读入,否则代码量大的仓库将直接把模型上下文塞爆了。
它是让模型自己通过工具来探索哪些文件是需要被读取的。
常见工具大概分几类:
命令执行:exec_command / write_stdin,或者 shell / shell_command / local_shell,用于跑 rg、sed、cat、git grep、cargo test 等命令。 文件修改:apply_patch,用于编辑文件。 目录浏览:list_dir,用于列目录。 MCP 工具:list_mcp_resources、read_mcp_resource,其它 mcp 工具。 工具发现:tool_search,用于搜索“有哪些工具可用”,不是搜索代码文件。 辅助工具:update_plan、view_image、web_search、js_repl、multi-agent 相关工具等。
举个例子,比如当前项目里有很多md文件,用户提问:“xxx是怎么做的?”
xxx会被模型自动提炼成关键词,然后它开始执行一个命令:
rg -n -C 5 "关键词" /path/to/docs -g '*.md'
-n 表示 显示行号,-C 5 表示 显示命中行上下各 5 行,-g '*.md' 表示 只搜 Markdown 文件。
整行命令的意思就是:在 /path/to/docs 目录下,递归查找所有 .md 文件中包含“关键词”的内容,并显示匹配行号,以及匹配位置前后各 5 行内容。
如果匹配的内容很多,比如模型一不小心 cat 了很大的文件,返回的内容直接超过模型上下文的上限怎么办。
Codex 考虑到了这种情况,它有一个截断机制,当调用工具的返回值超过 10000 token 时,会进行截断,截断的策略是:
保留开头 + 省略中间 + 保留结尾
继续引申,如果模型搜出了一段和关键词不相关的内容,是否会被当做“辣鸡”抛弃掉,以免污染上下文呢?
答案是不会,它会一直驻留在模型的上下文中,直到上下文超限后,触发压缩机制。
所以,当你和 AI 聊着聊着发现话题跑偏时,不要试图纠偏,直接重开更快更便捷。
上下文超限时,如何压缩?
模型的上下文窗口是有限制的,而且当上下文长度越长时,模型的输出质量会愈发下降,这个现象也被叫做上下文腐烂(Context Rot)。
因此,不能等上下文窗口满了才去压缩,否则最后几轮回答已经“烂完了”。
Codex 的做法是设定了一个自动压缩阈值,默认是 90%,即当前 token 使用量超过 90% 时,触发上下文压缩。
上下文压缩也是通过模型进行的,提示词如下:
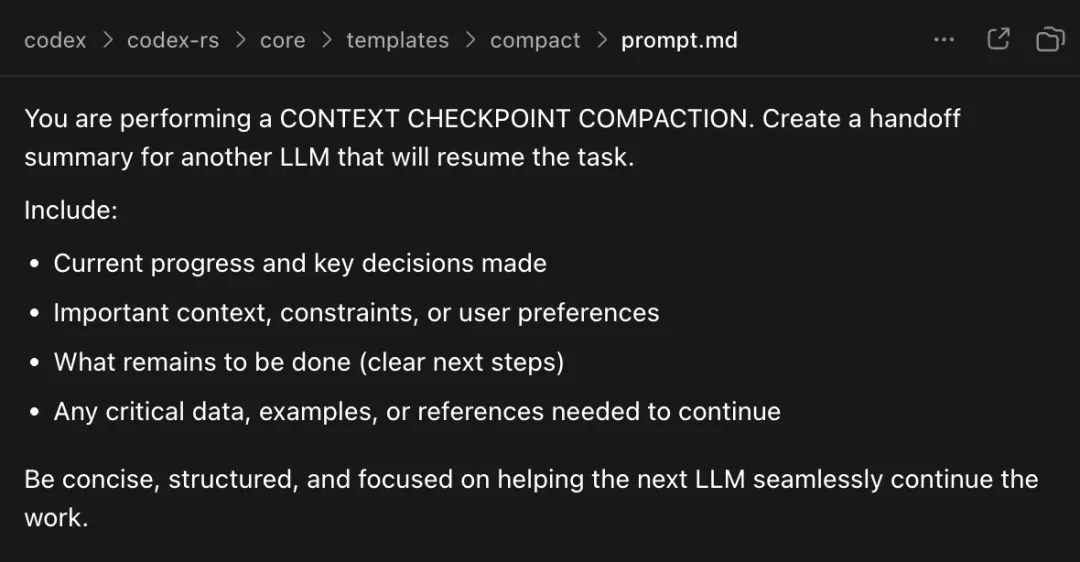
翻译一下,提示词的意思是:
你正在做 context checkpoint compaction。请给另一个将接手任务的 LLM 写交接摘要。包括当前进展、关键决策、约束、用户偏好、剩余步骤、关键数据/引用。保持简洁、结构化、聚焦于让下一个模型继续工作。
压缩之后,它会保留最近用户发送的消息和一条压缩摘要。
最近用户发送的信息也有一个阈值,默认是 20000 tokens,相当于最多保留最近用户输入的 20000 tokens内容。
这样设计也很合理,保留用户最近的输入,可以让用户感觉模型仍有最近的“记忆”,体验更顺滑,而历史的远古设定,则可能会被模型经压缩后,抛在脑后。
skill是如何触发的?
codex 安装完之后,会自动安装一些skills,放在这个文件路径:/Users/%user%/.codex/skills,基础主要包括以下五个skill:
imagegen:用于生成或编辑图片 openai-docs:用于询问 OpenAI API、模型选择、模型迁移、官方文档 plugin-creator:用于创建Codex plugin、生成.codex-plugin/plugin.json skill-creator:用于创建或更新 Codex skill skill-installer:用于安装 skill、列出可安装 skill、从 GitHub 安装 skill
每个skill的触发方式主要有三种:
用户显式点名:比如你说“使用 openai-docs skill”或 OpenAI Docs。这会被识别为明确使用某个 skill
任务语义匹配:比如你说“帮我查 OpenAI 最新模型怎么选”,模型看到 openai-docs 的描述后,会判断这个任务匹配该 skill,然后去读它的 SKILL.md
路径引用:UI 或消息里可以带 skill path,例如指向某个 SKILL.md。代码会按路径精确匹配,避免同名歧义
总结
分析完 codex 设计后,不免发现,它给了模型很多自主性,比如工具的调用、查询命令的编写、内容的压缩均依赖模型自己完成。
如果模型能力不足,再好的 harness 也无济于事,核心竞争力是模型本身,这也就是为什么 openai 直接把 codex 开源了。
如果你想设计一个类似的agent,没必要借助 langchain 之类的繁琐工具,不如直接告诉AI:
请参考“我有一计”的这篇文章(文章链接),设计一个类似的agent。
兴许它就能直接搞定了。
参考
[1] https://github.com/openai/codex
