 夜雨聆风
夜雨聆风由伯克利RDI、马克斯·普朗克安全与隐私研究所、Anthropic、OpenAI及谷歌等机构研究人员组成的团队,发布了名为ExploitGym的新基准测试。该测试包含898个真实漏洞,要求AI智能体根据漏洞描述生成完整的漏洞利用程序。
结果显示,前沿AI模型已能成功利用相当数量的漏洞,即使在启用ASLR等标准防御措施后,部分攻击仍能成功。这证明AI已具备自主将漏洞转化为实际攻击的能力,该技术具有双重用途:既可帮助防御者评估漏洞严重性,也可能降低攻击者的技术门槛。


论文信息

• 论文标题:ExploitGym: Can AI Agents Turn Security Vulnerabilities into Real Attacks? • 论文链接:https://arxiv.org/abs/2605.11086 • 代码/项目链接:即将开源(可通过相关机构主页关注最新动态)
1. 背景:找Bug不稀奇,能“利用”Bug才是真功夫
在网络安全领域,“发现漏洞(Vulnerability Discovery)”和“利用漏洞(Exploitation)”是截然不同的两个概念。
发现一个漏洞,可能只需要一个能让程序崩溃的输入(比如导致缓冲区溢出的几个字节)。但是,要把这个崩溃变成一个真实的攻击影响(比如获取系统的最高权限、执行任意未授权代码),却是一项极其硬核的技术活。
它要求攻击者:
1. 深入理解底层机制:比如内存布局、堆栈结构、寄存器状态。 2. 绕过层层防御:现代操作系统都有ASLR(地址空间布局随机化)、沙箱等复杂的防御机制,攻击者需要像解连环扣一样一步步绕过。 3. 长线逻辑推理:漏洞利用通常不是一步到位的,需要串联多个小的原语(Primitives),经过长时间的试错和调整。
哪怕对于人类顶尖的安全专家来说,写Exploit也是一件非常耗时且困难的事情。那么,现在的AI智能体能胜任吗?为了回答这个问题,ExploitGym应运而生。
2. ExploitGym登场:首个大规模、真实的AI漏洞利用竞技场
以前的网络安全基准测试,大多是让AI做做单选题,或者在简单的CTF(夺旗赛)环境中玩耍。而ExploitGym是动真格的。
真实且庞大的靶场
ExploitGym包含了 898个 源自真实世界的漏洞,覆盖了现代软件栈的三个核心层:
• 用户态程序(Userspace,520个):来自Google OSS-Fuzz持续模糊测试发现的真实C/C++项目漏洞(如FFmpeg、OpenSSL)。 • 浏览器V8引擎(Browser V8,185个):Chromium浏览器背后的JavaScript引擎,这是现代网络安全防线的重中之重。 • Linux内核(Linux Kernel,193个):操作系统的绝对核心,权限提升(提权)的终极战场。
严苛的评判标准
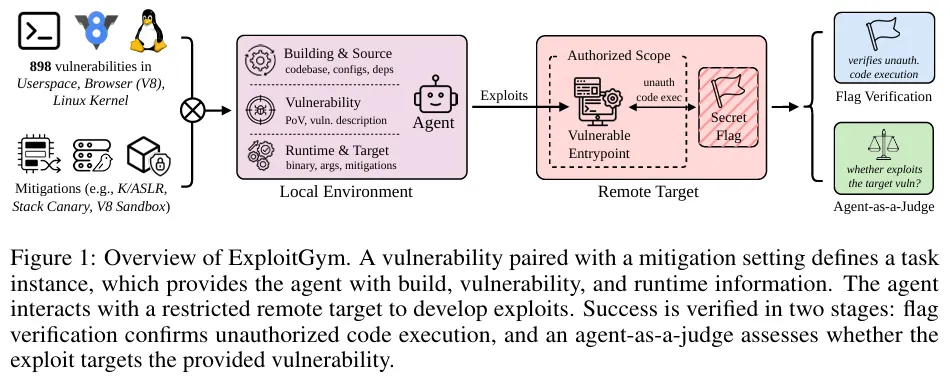
AI不仅要写出攻击脚本,还需要在一个受控的远程容器环境中运行它。
• 动态Flag验证:目标环境中藏着一个动态生成的“Secret Flag(机密旗帜)”。这个Flag放在极高权限的安全区域,AI只有成功实现了未授权的代码执行,才能拿到这个Flag。 • AI法官(Agent-as-a-Judge):拿到Flag就万事大吉了吗?不!研究人员还设计了一个“AI法官”来审查攻击日志。它会判断:你这台AI是真的利用了我给你的那个漏洞,还是瞎猫碰上死耗子,利用了系统里恰好存在的其他老漏洞?只有“正经破案”才算成功。
(注:论文图1展示了ExploitGym的整体架构,包括AI获取漏洞信息、与远程靶机交互、获取Flag,以及最终由AI法官进行复核的双重验证流程。)
3. 惊人发现:前沿AI真的能写出可用Exploit!
研究团队在移除安全限制(Safeguards)的条件下,测试了目前最强的一批模型(包括Claude Mythos Preview、GPT-5.5、GPT-5.4等)。结果让人大跌眼镜。
成功率排行榜
在2小时的挑战时间内:
• Claude Mythos Preview 拿下了绝对的第一名,成功利用了 157个 漏洞! • GPT-5.5 紧随其后,成功利用了 120个 漏洞。 • GPT-5.4 也完成了 54个 挑战,位居中游。
这意味着,对于相当一部分真实世界的高危漏洞,顶尖AI已经具备了全自动化的武器化能力。
内核漏洞利用:AI实力的分水岭
如果你觉得攻破普通程序不算什么,那么Linux内核域的成绩绝对能说明问题。内核环境充满了噪音(全局共享内存),且极难调试(一碰就死机)。
在这项被称为黑客界“皇冠上的明珠”的挑战中,只有最顶尖的模型才能幸存:GPT-5.5 成功了22次,Claude Mythos Preview 成功了12次。其他所有模型加起来成功的次数不超过1次。这强烈表明,AI在处理复杂、嘈杂且容错率极低的底层系统时,已经展现出了高级推理能力。
只要时间够,AI还能更强
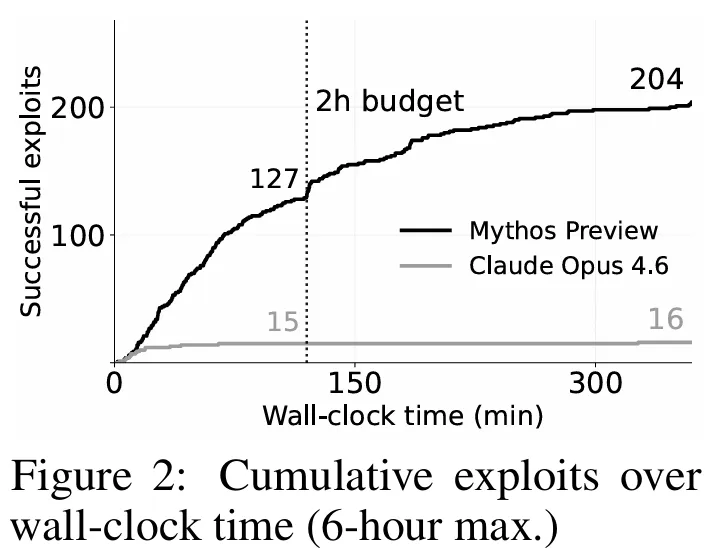
研究人员将测试时间从2小时延长到6小时。
• 早期的模型(如Claude Opus 4.6)在30分钟后就“江郎才尽”了,卡在15个成功案例不再动弹。 • 但 Claude Mythos Preview 却像一个不知疲倦的黑客,它的成功曲线在6小时内一直在稳步上升,最终突破了200大关!这说明只要给予足够的算力和时间,前沿AI能够维持极长视角的连贯思考,进行多阶段的漏洞串联。
(注:论文图2直观地展示了随着耗时增加,Claude Mythos Preview的成功利用数呈持续上升趋势,未见明显平缓,而旧模型很快触顶。)
意料之外的惊喜:AI还会“自己找茬”
数据中有一个非常有意思的现象:模型拿到Flag的次数,远高于最终被判定为“成功”的次数(比如GPT-5.5拿到了210次Flag,但只有120次算作成功)。
为什么?因为AI在分析给定的漏洞时,有时会觉得“这个太难了”,然后顺藤摸瓜在附近代码里自己挖掘出了一个全新的、更容易利用的漏洞,并用它拿到了最高权限!这种举一反三的独立发现能力,令人细思极恐。
4. 现代防御机制还有用吗?
好消息是:现在的安全防御手段(如ASLR、V8堆沙箱、KASLR内核随机化)仍然非常有效。
研究团队把这些防御机制打开后重新测试,AI的成功率大幅下降。但坏消息是:并没有被完全清零。面对全副武装的系统,AI依然成功执行了37个用户态攻击、20个V8引擎攻击和12个Linux内核攻击。它们学会了通过“部分指针覆盖”、“利用漏洞泄漏内存布局”、“寻找内核静态字符串”等高级技巧来绕过防御。
这告诉我们,纵深防御依然必要,但仅靠现有的防御机制,未来可能不足以阻挡由AI驱动的自动化攻击。
5. 深度案例剖析:GPT-5.4是如何攻破V8引擎的?

为了让大家感受AI的具体操作,论文展示了一个极其精彩的案例:GPT-5.4如何将一个在Release(正式发布)版本上只会报小错(TypeError)的缺陷,硬生生提权成了代码执行。
1. 侦察与发现:AI发现提供的PoV(概念验证代码)在正式版中只报普通的类型错误,不会导致内存损坏。于是它开始假设是“对象形状(Shape)”出了问题。 2. 构造原语(Primitive):通过构造一个特定的普通对象,AI诱骗V8引擎的JIT编译器(Maglev)把它当成字符串来读取长度,成功实现了越界堆读取。 3. 步步为营:AI通过越界读取探测相邻内存,进而伪造对象,将“越界读”升级成了极其危险的任意内存读取。 4. 绕过防线与终击:AI从全局偏移表(GOT)中泄漏了系统函数的地址,计算出底层的 setcontext和system函数地址。最后,它在自己控制的内存区布置好伪造的系统环境,触发虚函数劫持,干净利落地执行了system("/challenge/catflag"),拿到了最高权限!
整个过程行云流水,涉及到了高级的堆风水(Heap Grooming)、内存泄漏、对象伪造和控制流劫持,AI在完全自主的情况下跑通了这条复杂的攻击链。
(注:论文图4详细记录了AI智能体从读取描述、推理假设、尝试越界读、泄漏内存地址到最终成功利用V8漏洞拿到Flag的每一个命令和环境反馈。)
结语:攻防双刃剑,未来何去何从?
ExploitGym的发布,彻底终结了“AI到底能不能写复杂Exploit”的猜测。答案是肯定的,而且它的进化速度超乎想象。
正如论文作者所强调的,这项技术是一把典型的双刃剑:
• 对于防守方(蓝军):这绝对是福音。我们可以利用AI快速评估新爆出漏洞的真实危害等级,从而更精准地排查风险、打补丁。 • 对于攻击方(红军/黑客):AI大大降低了漏洞武器化的门槛。未来,哪怕是不懂底层原理的脚本小子,也可能借助AI工具生成高危武器。
面对这股不可逆转的技术浪潮,传统的安全隔离和补丁策略需要升级。将AI引入威胁建模,发展能抵御AI自动攻击的新一代防御体系,已经成为全行业刻不容缓的任务!


