 夜雨聆风
夜雨聆风
DTinsight导读:
本文来自喜马拉雅数据平台负责人陈叶超,在以『解锁AI新增长』为主题的第三届AI企业应用落地场景峰会暨OpenClaw研讨会上的主题演讲,包括以下精彩内容:
数据上下文工程
面向C端搜索推荐用户上下文

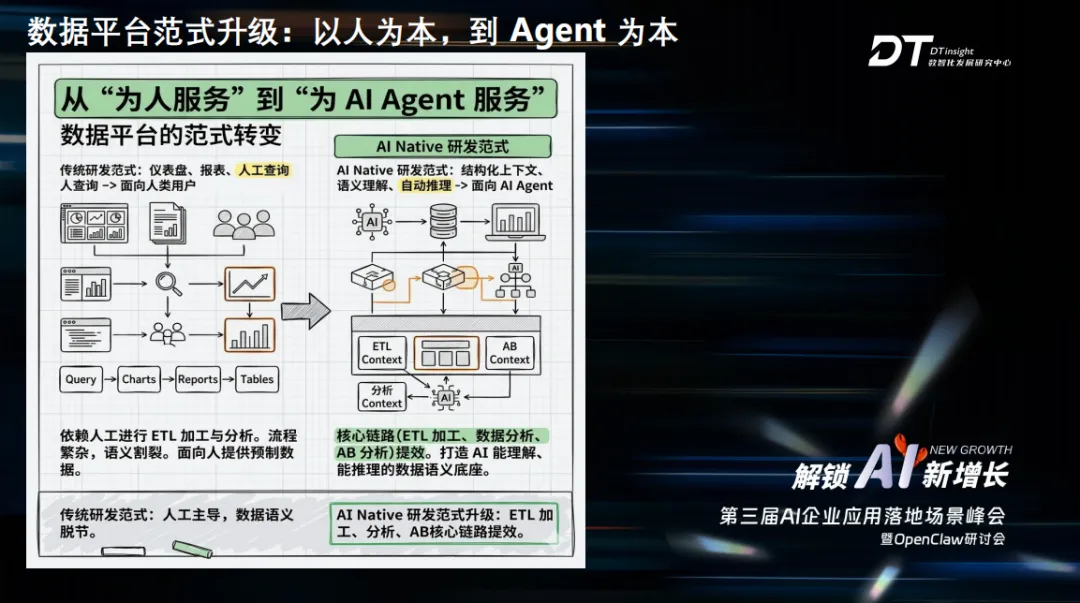
“传统数据平台存在效率瓶颈、能力上限、业务价值难以规模化三大核心痛点,因此需要用 AI Native 方式重构数据平台。”
 AI数据平台构建背景挑战
AI数据平台构建背景挑战
三年前,喜马拉雅数据平台与市面上的通用架构是一致的,底层为多元数据底座,涵盖应用、RDC 及混合部署等各类数据来源,支撑湖仓一体、多引擎融合等基础能力;中间层为计算引擎与数据开发流水线,集成多类型离线、实时计算能力,覆盖数据开发、清洗加工、报表应用、数据资产治理全流程;上层搭建数据产品、A/B 测试等业务系统,最终全面赋能营销推广与企业各类核心业务运转。
AI时代,原有传统数据架构,面临多重核心挑战:第一,数据消费主体彻底转变。以喜马拉雅为例,当前超八成曲速类数据产品由 AI 自动化消费,人工使用仅约两成;而短短一年多前,AI 消费占比仅一成,数据供给面向 AI 的适配能力严重不足;第二,数据开发效率难以匹配 AI 节奏。传统模式需需求提报、排期对接、口径对齐等流程,开发周期动辄一周甚至半月,链路冗长、门槛偏高,亟需依靠 AI 重构数据生产流程、提效降本;第三,数据形态与 AI 消费需求脱节。过往推荐、报表等场景,依赖标准化、规则化的特征加工数据。
但是,大模型原生适配文本类原始数据,无法直接消费结构化特征,现有数据生产体系,难以满足大模型实时、原生的数据取用要求,整体架构尚未做好 AI 化适配。
整体来看,当前数据平台主要面临三大类问题。第一,效率瓶颈严重。过往整套数据体系与取数分析流程,均围绕人工使用场景搭建,核心优化人机交互体验,完全没有适配 AI 自动化消费的需求。同时数据开发链路冗长繁琐,算法团队普遍缺乏完整的数据处理能力,相关需求只能交由数仓承接,叠加部门排期限制,面对热点事件、临时业务诉求等时效性场景,经常出现业务窗口期结束,画像与特征才完成开发的情况,严重跟不上业务节奏。
第二,能力上限非常有限。主流报表形式内容固化,指标经过人工筛选设定,只能呈现固定结果,无法回应业务的延伸疑问,复杂问题只能依靠人工反复拆解、逐层下钻,整体灵活度不足。传统用户画像和特征加工高度依赖固定标签体系与人工规则,刻画颗粒度粗糙,难以从海量行为数据中挖掘个性化、隐性的细节特征,就像早期规则式自动驾驶一样,无法覆盖多元复杂的实际场景,没办法深度理解用户真实行为与业务本质。
第三,业务价值难以规模化。长期以来,数据团队更多聚焦底层底座搭建、运维保障、基础资源支撑等基础工作,输出的多为底层能力,很难直接落地可量化的业务价值,只能通过降本增效这类间接维度佐证自身作用。无法进行自主智能体数据分析,依靠导出 Excel 文件对接智能体分析,不仅受数据量限制、分析能力有限,多源数据联动、自主下钻查询都需要人工反复导出操作,形成新的人工流程依赖,完全无法适配企业海量、多维度的复杂数据环境,导致 AI 数据应用难以规模化落地。
 打造AI原生数据平台
打造AI原生数据平台
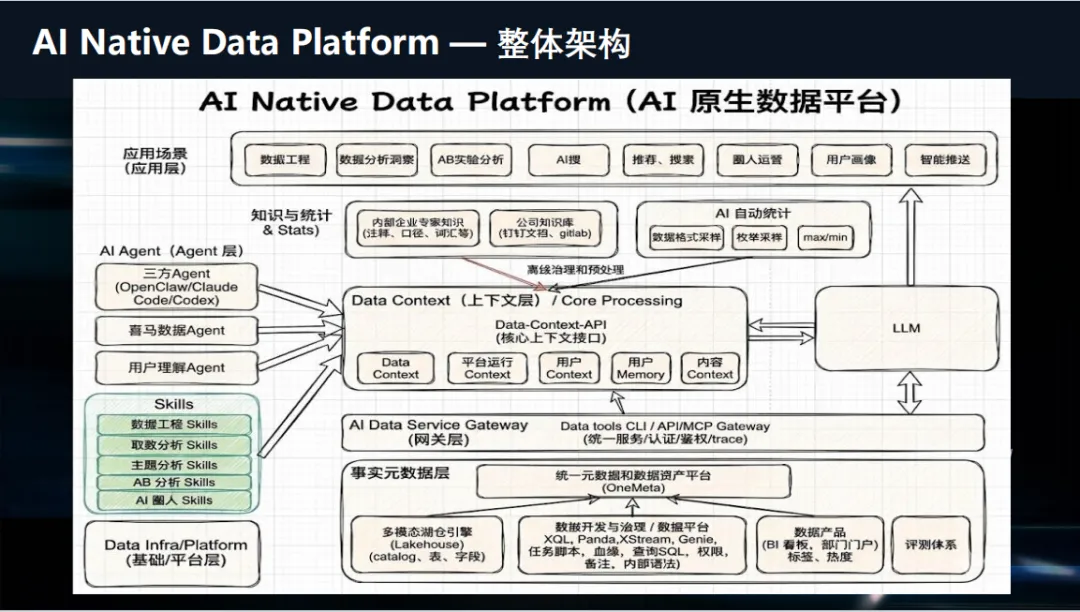
基于AI时代背景下数据平台的痛点,喜马拉雅对数据平台进行了升级迭代。底层基础架构基本保持稳定,不做大范围改动,仅适度引入多模态存储、向量数据库等能力,兼顾稳定性与新型数据承载需求。升级核心集中在中间层的数据资产语义化建设方面。为满足 AI 自主下钻、灵活分析的需求,搭建了多层级语义上下文体系,内容来源覆盖数仓事实源数据、全链路数据血缘,依托原有成熟的血缘能力,可实时捕获数据表变更、字段枚举更新、ETL 脚本调整等动态信息,并完成自动解析与映射。
同时,结合高频依赖表自动打标、业务知识库沉淀、重点项目与核心策略汇总,统一纳入语义体系,为 AI 生成分析、解读业务逻辑提供完整依据。针对数据表枚举含义、字段规则等隐性信息,依托大模型自动完成字段值域统计、特征梳理,整合汇聚后形成结构化多层级的数据上下文,分层承载全局指标、业务口径、关联关系等信息,实现从指标溯源到数据表探查的智能检索逻辑。
区分多类上下文体系,包含服务数仓开发与报表决策的数据资产上下文、汇聚任务报错、脚本变更、口径迭代、指标异常等信息的平台运营上下文,用以强化语义推理精度,支撑自动化运维场景。
除此之外,同步搭建用户上下文与内容上下文。用户侧构建长效记忆体系,整合长期偏好、短期行为、使用场景、对话记录与结构化用户摘要;内容侧统一音频、专辑等内容标签体系,实现用户行为标签与内容属性标签的语义对齐,保障个性化推荐、交互式问答等业务场景高效落地。
在能力输出与应用消费层面,封装各类标准化技能组件,覆盖数据工程、自助取数、专题分析、A/B 测试等场景,可自动生成 ETL 加工逻辑与查询分析语句。依托统一的技能与上下文底座,对接第三方大模型及自研数据智能体,全面打通数据生产、分析、运维全链路智能能力,实现从依赖于人转向依赖于Agent。
 AI落地实践
AI落地实践
在实践中,AI 技能落地后业务查询效率要求大幅提升,默认切换 StarRocks 引擎,但复杂多表关联场景无法适配。内部SQL系统基于 Spark 自研的系统能支撑大规模复杂查询,借助 AI 配置简单规则,即可实现查询引擎自动路由与失败兜底切换,替代了传统需资深工程师耗时半年以上开发、还难以完全兼容的路由引擎方案,也意味着技术开发要跳出传统固有思路,改用 AI 原生思维做方案设计。
在AI能力调用方面,面对存量产品不断迭代升级、底层重构的现状,通过批量定义 CLI并借助 CLI 代理转发调用原有系统,无需重写任何底层代码,复用原有 Infra 和平台产品,只新增 Gateway 中间层。同时网关实现了统一认证与权限管控,规避了高风险操作隐患。用户只对接网关不直连后台,形成语义请求闭环,还能统一收集上下文信息,反哺技能持续迭代优化。
在AI Native 用户上下文与记忆体系构建实践中,大模型全链路重构后流程大幅简化:先把用户画像序列、上下文配置做规整输入,通过上下文工程送入大模型,由模型自主刻画用户长短期记忆并生成摘要;再通过向量化模型做向量编码,存入向量库,完成内容与用户的统一归一化沉淀。后续应用链路十分轻量化,推荐场景做向量召回再进入排序,搜索场景直接取用记忆摘要做关联匹配。整套架构依托数据采集、在线 KV 存储,再通过专属服务把 KV 数据转化为大模型可理解文本,经上下文压缩处理后,借助自定义 UDF 能力、大模型网关调度调度推理集群,形成顺滑完整的处理链路。
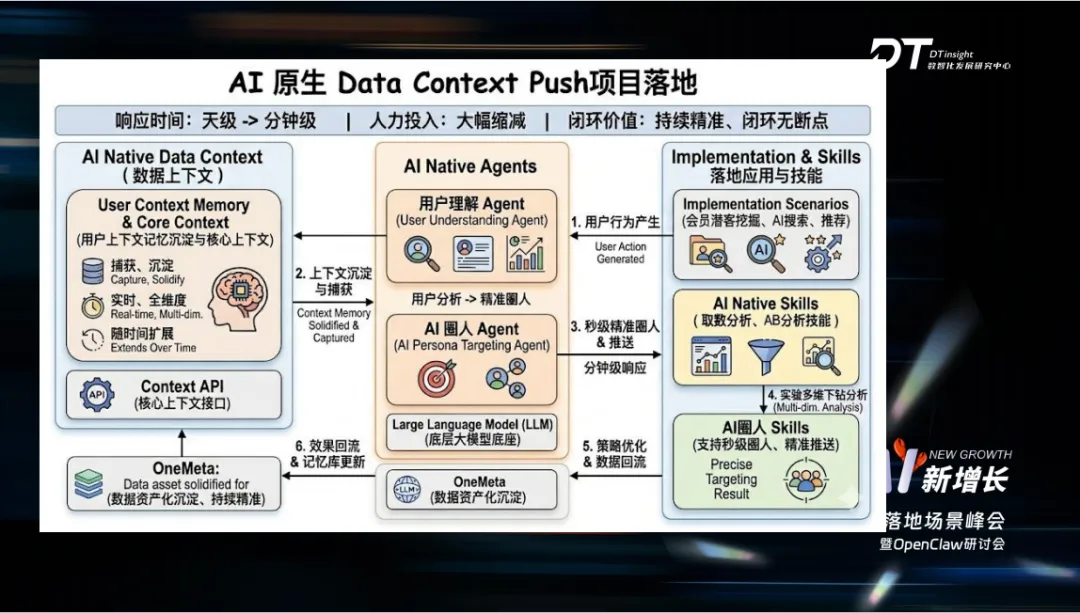
在基于上下文工程打造的 AR 剖析项目中,核心具备 AR 圈人能力:只需给出目标需求,系统就能自动圈选对应人群并发起实验。随后调用各类技能拉取数据开展分析,分析完成后自动生成报告,还能对报告内容进一步逐层拆解细化。依托 Agent 能力、上下文工程以及知识库的加持,很多过去难以落地实现的复杂分析与业务工作,如今都能轻松高效完成。
在AI 应用落地有以下几条核心原则:一是本地优先,优先依托已有文档和上下文能力处理需求,仅在无法满足时,再启用复杂检索搜索能力;二是不过早压缩数据,处理行为序列时先保留原始完整数据,交由大模型自主推理多维度信息,待模型推理完成、关键特征明确后,再做数据压缩,避免提前压缩丢失关键细节;三是先用顶级大模型定能力上限,以大模型效果为基准,再用轻量化小模型做规模化落地替代。
落地这套开发模式后,数据开发效率提升约两倍,查询速度实现十倍提升。数科人员只需简单调整配置,依托可被模型理解的语义与压缩资产,就能实现从全自动开发到上线部署的全流程打通,大幅简化了业务落地流程。

第三届AI企业应用落地场景峰会暨OpenClaw研讨会,于2026年3月27日在上海圆满闭幕。本次峰会以“解锁AI新增长”为主题,由DTinsight中国数智发展研究中心主办,DT千川汇、TGO20组、作为智库支持,吸引来自智能制造、汽车、半导体、新能源、金融、消费、互联网、交通等泛行业,超100家头部企业CIO、CAIO、CTO、AI负责人等数字化领军者齐聚,探寻AI规模化落地路径,让AI真正成为驱动企业增长的确定性力量。
同时,大会发布了《AI大模型应用生态全景图鉴》,进行了“年度AI卓越创新实践”、“年度AI卓越解决方案”的颁奖盛典,两场【圆桌对话】探讨OpenClaw发展趋势,为AI落地把脉。







