 夜雨聆风
夜雨聆风lead_agent/agent.py。结论是:agent.py 是 DeerFlow 主 Agent 的装配入口,它负责把模型、工具、中间件、系统提示词和状态结构交给 LangChain 的 create_agent。
这一篇继续往下看:
backend/packages/harness/deerflow/agents/lead_agent/prompt.py如果说 agent.py 定义的是 DeerFlow Lead Agent 的运行骨架,那么 prompt.py 定义的就是这个 Agent 的行为协议。
这里的 prompt 不是简单的角色描述,而是把 DeerFlow 的运行规则、工具使用边界、澄清策略、子 Agent 调度方式、文件目录约束、技能加载机制和引用规范,全部写进 system prompt。
也就是说,DeerFlow 的 Lead Agent 并不是只靠模型“自由发挥”,而是通过 prompt 和 middleware 共同约束出来的。
一、prompt.py 在启动链路中的位置
回到 agent.py,创建 Lead Agent 时会调用:
return create_agent( model=create_chat_model(...), tools=get_available_tools(...), middleware=_build_middlewares(...), system_prompt=apply_prompt_template(...), state_schema=ThreadState,)其中:
system_prompt=apply_prompt_template(...)就是 prompt.py 的核心出口。
agent.py 不直接拼接系统提示词,而是把这些运行参数传给 apply_prompt_template:
apply_prompt_template( subagent_enabled=subagent_enabled, max_concurrent_subagents=max_concurrent_subagents, agent_name=agent_name,)bootstrap 模式下会稍微特殊一点:
apply_prompt_template( subagent_enabled=subagent_enabled, max_concurrent_subagents=max_concurrent_subagents, available_skills=set(["bootstrap"]),)这说明 prompt.py 的职责不是静态文本管理,而是根据运行时配置动态生成最终 system prompt。
二、prompt.py 的核心结构
从源码看,prompt.py 主要由几类函数组成:
_build_subagent_sectionSYSTEM_PROMPT_TEMPLATE_get_memory_contextget_skills_prompt_sectionget_agent_soulget_deferred_tools_prompt_section_build_acp_section_build_custom_mounts_sectionapply_prompt_template可以分成三层理解:
第一层是静态模板:
SYSTEM_PROMPT_TEMPLATE
第二层是动态片段生成:
_build_subagent_section_get_memory_contextget_skills_prompt_sectionget_agent_soulget_deferred_tools_prompt_section_build_acp_section_build_custom_mounts_section
第三层是最终组装入口:
apply_prompt_template
整体流程是:
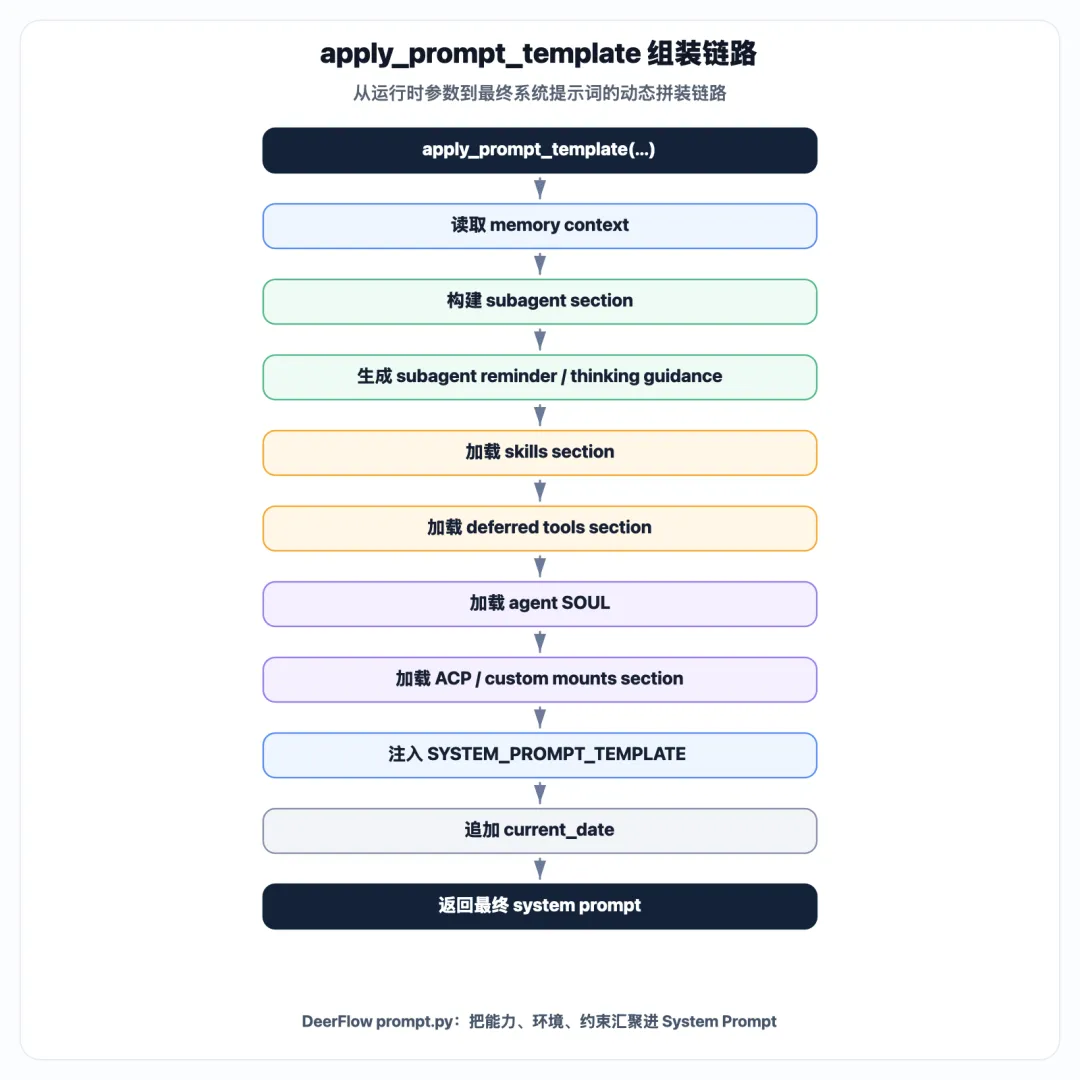
三、SYSTEM_PROMPT_TEMPLATE:不是人设,而是运行协议
SYSTEM_PROMPT_TEMPLATE 是整个 prompt 的主体。
它里面不是单纯写一句“你是 DeerFlow”,而是用多个 XML 风格标签拆出不同约束块:
<role><soul><memory><thinking_style><clarification_system><skill_system><available-deferred-tools><subagent_system><working_directory><response_style><citations><critical_reminders><current_date>这种写法的好处是边界明确。
每个模块负责约束 Agent 的一个行为维度:
role:定义默认身份 soul:注入自定义 Agent 人设 memory:注入长期记忆 thinking_style:约束任务分析方式 clarification_system:约束澄清优先级 skill_system:告诉模型如何加载技能 available-deferred-tools:告诉模型有哪些延迟工具 subagent_system:告诉模型如何调度子 Agent working_directory:告诉模型文件目录和产物输出规则 response_style:约束回复风格 citations:约束引用格式 critical_reminders:最后再次强调关键规则 current_date:注入当前日期
这就是 DeerFlow prompt 设计中最重要的一点:
Prompt 不是文案,而是 Agent Runtime 的行为协议。
四、Role 与 SOUL:默认 Agent 和自定义 Agent 的分层
模板里默认角色是:
You are {agent_name}, an open-source super agent.如果没有传入 agent_name,默认名称是:
agent_name or "DeerFlow 2.0"但 DeerFlow 还支持自定义 Agent。
自定义 Agent 的个性、职责、风格不是写死在主模板里,而是通过:
get_agent_soul(agent_name)读取:
load_agent_soul(agent_name)如果存在 SOUL 内容,就包进:
<soul>...</soul>这是一种清晰的分层:
SYSTEM_PROMPT_TEMPLATE管通用运行规则 SOUL.md管自定义 Agent 的身份和风格
这样 DeerFlow 可以复用同一个 Lead Agent 运行骨架,同时支持多个不同的自定义 Agent。
五、Memory 注入:把长期记忆变成上下文
prompt.py 里有一个函数:
_get_memory_context(agent_name)它的逻辑是:
读取 memory 配置 判断 memory.enabled和memory.injection_enabled根据 agent_name读取全局或当前 Agent 的 memory 数据调用 format_memory_for_injection如果有内容,则包进 <memory>标签
最终格式类似:
<memory>...</memory>这里要注意一点:memory 的写入不在 prompt.py 完成。
上一篇提到,DeerFlow 通过 MemoryMiddleware 在会话结束后异步更新 memory。prompt.py 只负责在下一次 Agent 启动时,把已经存在的 memory 读出来并注入到 system prompt。
所以 memory 链路可以理解为:
MemoryMiddleware 负责写入/更新prompt.py 负责读取/注入这个设计把记忆系统拆成了两个方向:
运行结束后沉淀经验 下一次运行前注入经验
六、Clarification System:先澄清,再行动
clarification_system 是 SYSTEM_PROMPT_TEMPLATE 中非常重要的一段。
它明确规定工作流优先级:
CLARIFY → PLAN → ACT也就是:
先分析用户请求是否清晰 如果缺少信息、存在歧义或涉及风险操作,必须先调用 ask_clarification澄清完成之后才能开始计划和执行
源码里列了几类必须澄清的场景:
missing_info:缺少必要信息 ambiguous_requirement:需求存在多种解释 approach_choice:存在多种可行方案 risk_confirmation:涉及危险或破坏性操作 suggestion:有建议但需要用户确认
这段 prompt 不是孤立生效的。
它和 agent.py 里的两个点配合:
第一,工具层暴露了:
ask_clarification_tool第二,middleware 链最后放了:
ClarificationMiddleware()所以完整链路是:
、
这就是 DeerFlow 里“澄清优先”的实现方式:prompt 负责行为诱导,middleware 负责运行时中断。
七、Subagent Section:把主 Agent 变成调度器
当 subagent_enabled=True 时,apply_prompt_template 会调用:
_build_subagent_section(max_concurrent_subagents)这段 prompt 会把 Lead Agent 的角色从普通执行者提升为任务调度器。
它给模型定义了三个动作:
DECOMPOSEDELEGATESYNTHESIZE也就是:
把复杂任务拆成多个子任务 通过 task工具并行分发给 subagent收集子任务结果后综合回答
这里还有一个关键参数:
max_concurrent_subagentsprompt 会把它写成硬限制:
MAXIMUM {n} task CALLS PER RESPONSE并且要求模型在调用 subagent 前先计数:
如果子任务数小于等于上限,一批发起 如果子任务数超过上限,拆成多批 当前轮只发起第一批 所有批次完成后再汇总
这个设计也不是只靠 prompt。
上一篇提到,agent.py 中还有:
SubagentLimitMiddleware(max_concurrent=max_concurrent_subagents)所以 subagent 并发控制同样是双层约束:
prompt 告诉模型不要超过限制middleware 在运行时截断超出的 task 调用这也是生产级 Agent 系统常见的设计:不要只相信模型遵守规则,要有后端硬约束。
八、Skills Section:按需加载能力,而不是一次性灌满上下文
get_skills_prompt_section 会调用:
load_skills(enabled_only=True)拿到当前启用的 skills,然后生成:
<skill_system> <available_skills> <skill> <name>...</name> <description>...</description> <location>...</location> </skill> </available_skills></skill_system>它重点强调的是 Progressive Loading Pattern。
也就是:
用户请求匹配某个 skill 时,先读取 skill 的主文件 理解 skill 的 workflow 和 instructions skill 文件里如果引用了其他资源,再按需加载 不要一次性把所有资源塞进上下文
这个设计的目标很明确:控制上下文膨胀。
DeerFlow 不是把每个 skill 的完整内容都拼进 system prompt,而是只拼:
skill 名称 skill 描述 skill 文件位置
真正需要时,再让 Agent 用文件工具读取对应 skill。
这比“把所有工具说明、所有技能说明一次性塞给模型”更适合长期运行。
bootstrap 模式下还有一个细节:
available_skills=set(["bootstrap"])这表示初始化自定义 Agent 时,只暴露 bootstrap skill,避免模型看到不相关技能。
九、Deferred Tools:大工具集下的工具检索机制
DeerFlow 支持 MCP tools。
问题是:MCP tools 一多,如果把所有工具 schema 都直接暴露给模型,上下文会膨胀,模型选择工具也会变差。
所以 DeerFlow 引入了 deferred tools。
get_deferred_tools_prompt_section 的逻辑是:
判断 tool_search.enabled是否开启获取 deferred registry 如果存在延迟工具,只把工具名写入 prompt
最终格式是:
<available-deferred-tools>tool_atool_btool_c</available-deferred-tools>注意,这里不是完整 schema,只是工具名列表。
模型知道“有哪些工具可能存在”,但不会直接拿到所有工具定义。需要时再通过 tool_search 检索和加载。
这是一种工具规模治理能力。
当工具数量很少时,直接暴露所有工具问题不大;当工具数量越来越多,必须把工具发现和工具调用拆开。
十、Working Directory:把文件操作约束成固定协议
working_directory 这一段是 DeerFlow 文件任务的关键。
它告诉模型三个固定目录:
/mnt/user-data/uploads/mnt/user-data/workspace/mnt/user-data/outputs含义分别是:
uploads:用户上传文件目录 workspace:临时工作目录 outputs:最终交付物目录
规则也很明确:
上传文件会自动出现在 <uploaded_files>上下文中读取上传文件要用 read_filePDF、PPT、Excel、Word 等文件可能有转换后的 Markdown 临时工作放在 workspace 最终交付物必须复制到 outputs 交付文件时使用 present_file
这段 prompt 解决的是一个常见问题:
Agent 可以读写文件,但它必须知道哪些目录可以读,哪些目录用来工作,哪些目录用来交付。
没有这层约束,模型可能把中间文件和最终文件混在一起,也可能生成了文件但用户无法下载。
所以 DeerFlow 通过 prompt 把文件系统操作约束成固定协议。
十一、ACP 和自定义挂载:把外部执行空间讲清楚
prompt.py 还有两个动态片段:
_build_acp_section()_build_custom_mounts_section()ACP section 只有配置了 ACP agents 时才会生成。
它强调:
ACP agents 有自己的独立 workspace 不在 /mnt/user-data/下执行ACP 输出通过 /mnt/acp-workspace/只读访问如果要交付给用户,需要复制到 /mnt/user-data/outputs/
自定义挂载 section 则读取:
get_app_config().sandbox.mounts然后把配置的挂载目录写入 prompt,并标记是 read-only 还是 read-write。
这两段的目标一致:让模型明确外部文件空间的边界。
Agent 一旦具备文件和命令执行能力,路径边界必须讲清楚。否则模型很容易把不同 workspace 混用。
十二、Response Style 与 Citations:输出也被协议化
DeerFlow 不只约束怎么执行,也约束怎么输出。
response_style 要求:
清晰简洁 默认少用复杂格式 聚焦交付结果,不解释过多过程
citations 则专门约束研究任务。
它要求只要使用 web search、web fetch 或外部信息源,就必须写引用。
引用分两种:
正文里的 inline citation:
claim [citation:Title](URL)文末 Sources:
[Title](URL) - Description这个设计说明 DeerFlow 的 prompt 不只是面向代码执行,也面向 deep research 类任务。
研究型 Agent 的核心风险之一是来源不清。DeerFlow 把引用格式直接写成 system prompt 规则,尽量让模型在生成报告时保留可追溯性。
十三、Critical Reminders:最后一道行为约束
模板最后还有:
<critical_reminders>...</critical_reminders>这里再次强调几个关键规则:
需求不清晰时先澄清 subagent 模式下要遵守调度限制 复杂任务优先加载相关 skill 输出文件必须放到 /mnt/user-data/outputs使用同一种语言回复用户 thinking 是内部过程,最终必须给用户可见回复
这一段的作用是收尾强化。
对于长 prompt 来说,重要规则只出现一次通常不够稳定。DeerFlow 会在不同位置重复强调关键边界,提升模型遵守概率。
这不是冗余,而是工程化 prompt 的常见做法。
十四、current_date:每次动态注入当前日期
apply_prompt_template 最后会追加:
return prompt + f"\n<current_date>{datetime.now().strftime('%Y-%m-%d, %A')}</current_date>"这意味着每次生成 system prompt 时,都会带上当前日期。
这个字段对研究类任务、时效性问题、计划类任务都有价值。
需要注意的是,它使用的是运行环境当前时间,而不是用户输入中的时间。
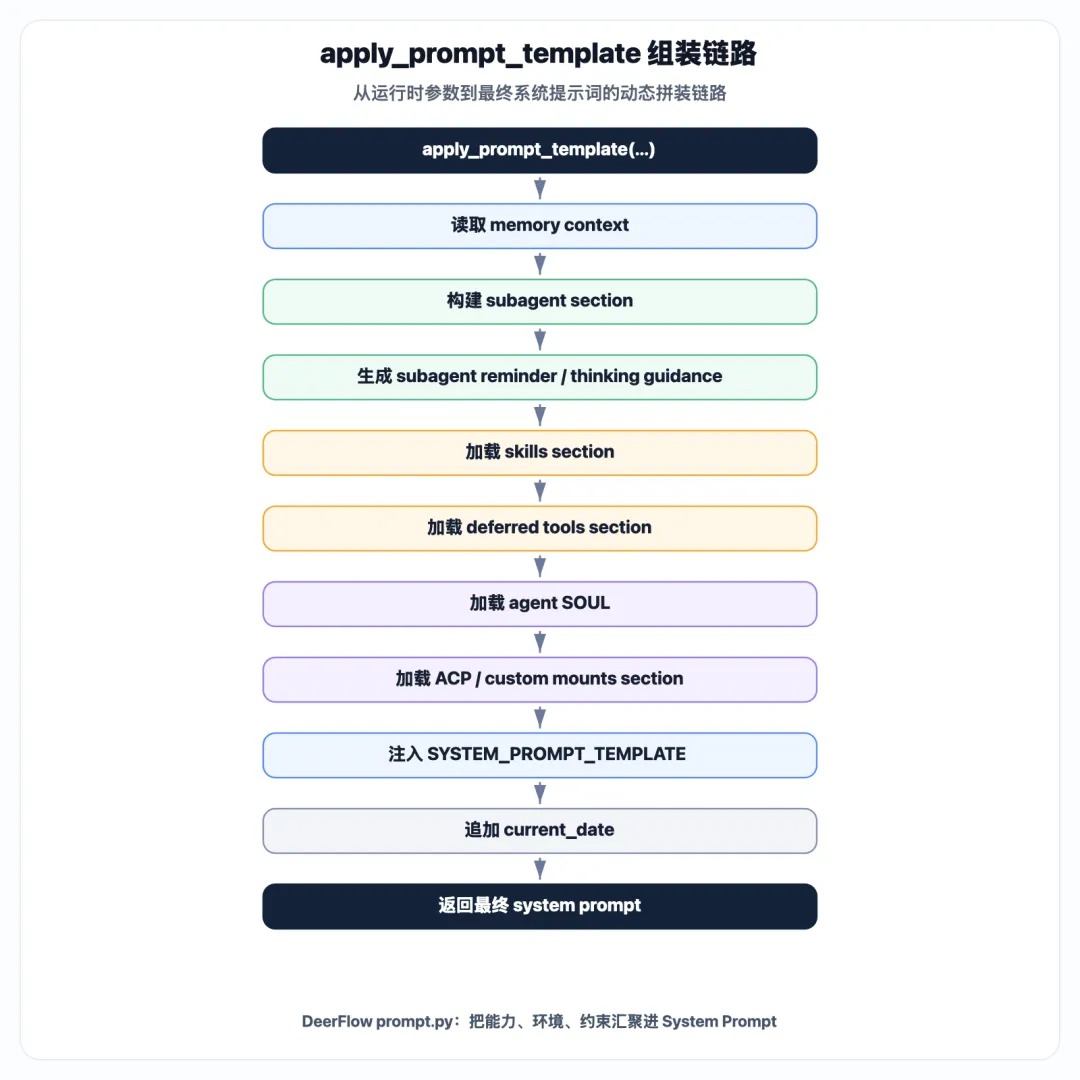
十五、最终组装流程
把 apply_prompt_template 展开看,流程是:
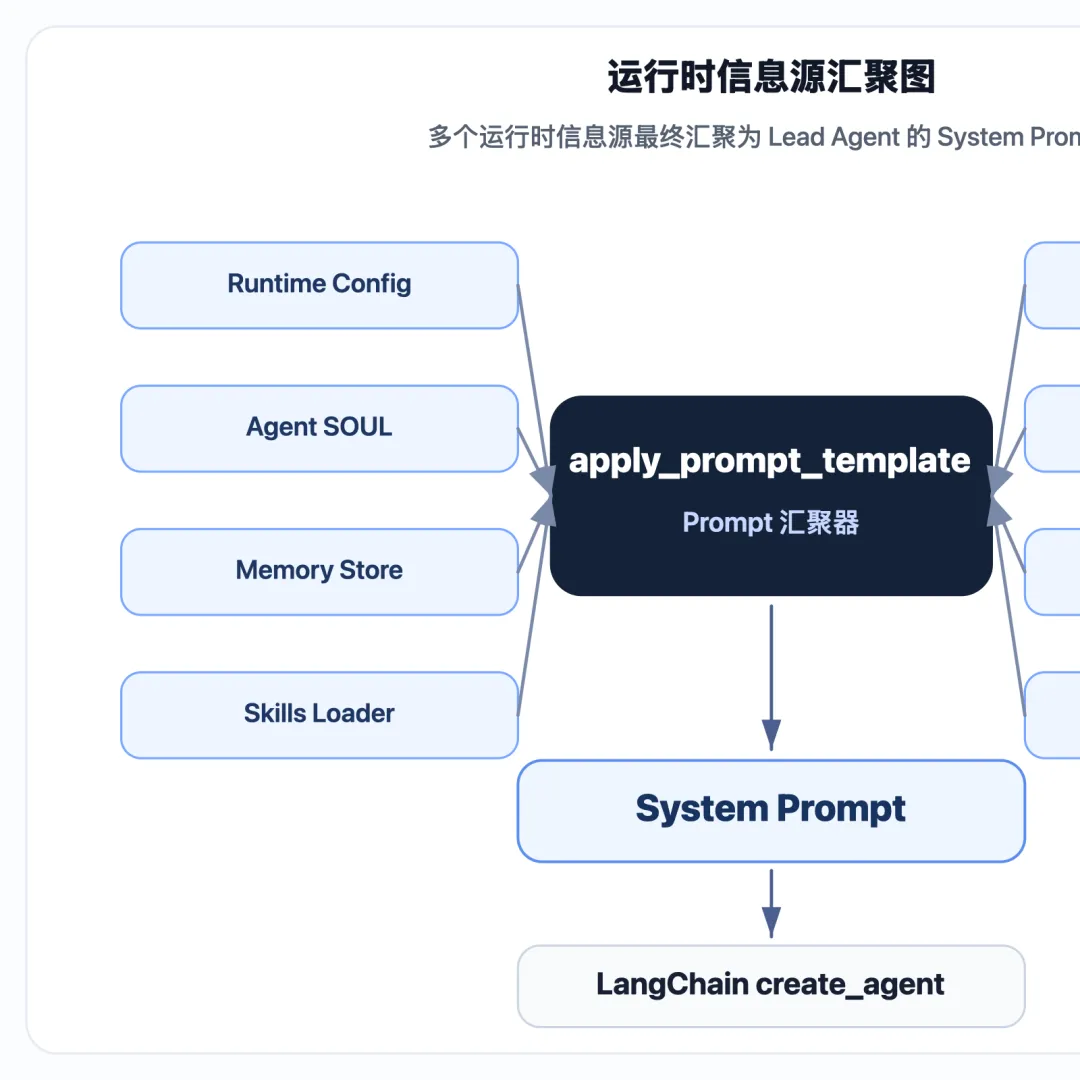
对应到架构上:
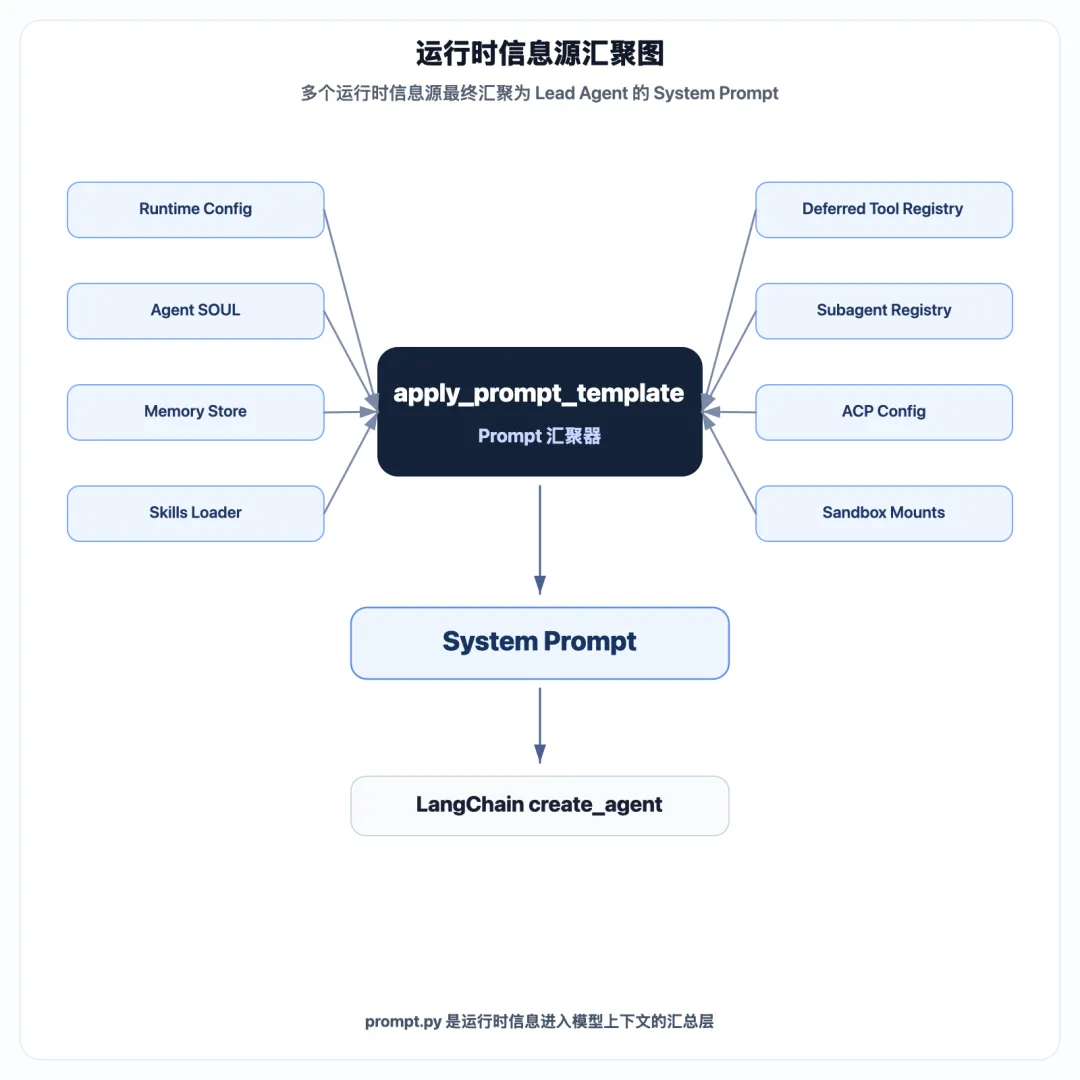
这张图可以说明 prompt.py 的定位:它是多个运行时信息源进入模型上下文的汇总层。
十六、核心源码:apply_prompt_template 是信息汇聚器
如果只看一个函数,prompt.py 最值得看的就是:
def apply_prompt_template( subagent_enabled: bool = False, max_concurrent_subagents: int = 3, *, agent_name: str | None = None, available_skills: set[str] | None = None,) -> str: memory_context = _get_memory_context(agent_name) n = max_concurrent_subagents subagent_section = _build_subagent_section(n) if subagent_enabled else "" subagent_reminder = (...) if subagent_enabled else "" subagent_thinking = (...) if subagent_enabled else "" skills_section = get_skills_prompt_section(available_skills) deferred_tools_section = get_deferred_tools_prompt_section() acp_section = _build_acp_section() custom_mounts_section = _build_custom_mounts_section() acp_and_mounts_section = "\n".join( section for section in (acp_section, custom_mounts_section) if section ) prompt = SYSTEM_PROMPT_TEMPLATE.format( agent_name=agent_name or "DeerFlow 2.0", soul=get_agent_soul(agent_name), skills_section=skills_section, deferred_tools_section=deferred_tools_section, memory_context=memory_context, subagent_section=subagent_section, subagent_reminder=subagent_reminder, subagent_thinking=subagent_thinking, acp_section=acp_and_mounts_section, ) return prompt + f"\n<current_date>{datetime.now().strftime('%Y-%m-%d, %A')}</current_date>"这段代码的核心不是复杂算法,而是把多个运行时信息源汇聚到同一个 system prompt:
agent_name决定默认角色名 SOUL.md决定自定义 Agent 个性 memory 决定长期记忆注入 skills 决定可按需加载的能力索引 deferred tools 决定大工具集下的工具发现入口 subagent 配置决定是否进入任务调度器模式 ACP 和 sandbox mounts 决定外部执行空间边界 current date 决定时间上下文
所以 apply_prompt_template 可以理解为 DeerFlow 的 Prompt 汇聚器。
它把“系统有什么能力、当前运行环境是什么、模型应该遵守什么协议”统一压缩进 system prompt。
十七、Prompt 和 Middleware 的闭环
DeerFlow 的设计不是单纯依赖 prompt。
很多关键能力都采用了“双层约束”:
prompt 负责告诉模型应该怎么做middleware 负责在运行时校验、拦截或兜底对应关系可以这样看:

clarification_system | ClarificationMiddlewareask_clarification 并中断执行 | |
subagent_systemtask | SubagentLimitMiddleware | |
working_directory | ThreadDataMiddlewareSandboxMiddleware 提供实际目录和执行环境 | |
ToolErrorHandlingMiddleware | ||
SummarizationMiddleware | ||
TodoMiddlewarewrite_todos 工具和 todos 状态 | ||
DeferredToolFilterMiddleware | ||
ViewImageMiddleware |
这张表是理解 DeerFlow 的关键。
一个生产级 Agent 系统不能只靠“提示词写得好”。模型可能忘记规则,可能过度调用工具,也可能在异常后无法恢复。
DeerFlow 的处理方式是:能写进 prompt 的写进 prompt,必须稳定执行的放到 middleware。
这也是 prompt.py 和上一篇 agent.py 能连起来的地方:
prompt.py定义行为协议 agent.py注册中间件 middleware 在运行时兜底协议执行
十八、prompt.py 的设计重点
从源码看,DeerFlow 的 prompt 设计有几个明显特点。
第一,prompt 是结构化的。
它用 XML 风格标签拆出不同协议块,而不是写成长段自然语言。
第二,prompt 是动态的。
不同 Agent、不同配置、不同工具环境下,最终 system prompt 不一样。
第三,prompt 和 middleware 配合。
比如 clarification 和 subagent 限流,都不是只靠 prompt。prompt 负责告诉模型该怎么做,middleware 负责在运行时兜底。
第四,prompt 控制上下文成本。
skills 只注入索引,不注入全文;deferred tools 只注入工具名,不注入完整 schema。
第五,prompt 明确文件系统协议。
uploads、workspace、outputs 的分工直接写进 system prompt,保证文件任务能被稳定交付。
十九、总结
prompt.py 是 DeerFlow Lead Agent 的行为协议层。
它不是简单定义“你是谁”,而是在 system prompt 中约束了一个 Super Agent 应该如何运行:
如何判断需求是否清晰 什么时候必须先澄清 如何加载 skill 如何读取 memory 如何发现 deferred tools 如何调度 subagent 如何处理文件目录 如何交付输出产物 如何引用外部来源 如何保持回复语言和输出风格
如果说上一篇的 agent.py 解决的是:
Lead Agent 怎么被创建出来?
那么这一篇的 prompt.py 解决的是:
Lead Agent 被创建出来之后,应该按照什么协议行动?
DeerFlow 的核心思路很清楚:
agent.py 提供运行骨架middlewares 提供运行时钩子和兜底prompt.py 提供模型行为协议ThreadState 提供长期状态承载tools 提供真实执行能力这几个模块组合起来,才构成 DeerFlow 的 Super Agent Harness。
参考源码
backend/packages/harness/deerflow/agents/lead_agent/prompt.pybackend/packages/harness/deerflow/agents/lead_agent/agent.pybackend/packages/harness/deerflow/tools/tools.pybackend/packages/harness/deerflow/tools/builtins/task_tool.pybackend/packages/harness/deerflow/agents/middlewares/clarification_middleware.pybackend/packages/harness/deerflow/agents/middlewares/subagent_limit_middleware.py
