 夜雨聆风
夜雨聆风
通 知
关于举办“2026AI蛋白质设计前沿技术实战培训班”的通知
培训形式
l基础奠基,工具实践,实例分析,互动答疑
l完成全部培训课程者由协会颁发培训证书
近年来,人工智能已彻底颠覆了蛋白质设计领域。以AlphaFold、ESM、RFdiffusion为代表的一系列AI工具,使得从零开始创造具有全新结构和功能的蛋白质成为可能,为生物医药、酶工程等领域带来了前所未有的机遇。 然而,强大的工具也带来了新的挑战:复杂的软件环境配置、多样的模型调用方式以及从“想法”到“设计”的完整工作流整合,成为了许多研究者,尤其是初学者的现实门槛。
本课程旨在系统性地解决这些问题。我们将从最基础的Linux与Conda环境管理讲起,确保每位学员搭建起稳定、可复现的计算平台。课程核心将深度实践三大前沿工具:利用ESM模型进行序列分析与特征提取;掌握ProteinMPNN为给定骨架设计最优序列;并通过RFdiffusion实现从无到有的蛋白质骨架生成。最终,我们将以一个完整的“设计靶向EGFR的全新结合蛋白”综合项目,串联所有技术环节,带领学员亲历从靶标分析、骨架生成、序列设计到AI结构验证的完整闭环,快速获得独立开展AI蛋白质设计的能力。因此,中国化工企业管理协会医药化工专业委员会决定于2026年 6月26-28日在杭州市举办“2026AI蛋白质设计前沿技术实战培训班”。届时将邀请行业内实践专家针对相关内容进行讲解与实操教学。参会名额有限,望各有关单位积极转发或组织相关人员尽快报名参加。现将有关事项通知如下:
会议组织 时间地点
组织机构
主办单位:中国化工企业管理协会医药化工专业委员会
承办单位:中科凯晟(北京)化工技术研究院
时间地点
时间:2026年6月26-28日(26日全天报到)
地点:杭州市
联系人:赵裕微信13051406726 电话19910381295
日程、培训内容、拟邀出席嘉宾
附件1:课程大纲 第一天:计算环境搭建与蛋白质序列设计 (6月27日,上午09:00-12:00;下午13:30-16:30) 上午: 模块一 & 模块二 模块一:Linux基础— Linux, Conda, VScode& Docker&Claude Code,kimi code 目标:为后续所有软件安装和运行扫清障碍,建立规范、可复现的科研计算环境管理能力。 Linux基础操作精讲: l文件系统与导航:ls, cd, pwd, mkdir 的高效使用技巧。 l文件管理:cp, mv, rm, vi, cat, head, tail 的实战应用。 l权限管理:理解并使用chmod 解决脚本执行权限问题。 l实操:在服务器上创建课程项目目录,并进行基本的文件组织。 Conda环境管理核心: l核心理念:通过环境隔离解决不同项目间的依赖冲突问题。 l环境生命周期:创建(create)、激活(activate)、退出(deactivate)、删除(remove) l软件包管理:安装(install/pip install)、查看(list)、导出配置(env export) l实操:为后续的ESM、ProteinMPNN和RFdiffusion创建独立的Conda环境。 Docker容器化入门: l概念对比:Docker与虚拟机的异同,镜像(Image)与容器(Container)的核心关系。 l核心命令:docker pull (拉取官方镜像), docker run (运行容器)。 l应用场景:讲解如何利用Docker一键部署复杂的生物信息学工具。 VScode远程开发实战: lSSH远程连接:配置Remote-SSH插件,一键连接实验室服务器,本地浏览远程文件。 l科研扩展生态:安装Python、Jupyter、Docker插件,构建蛋白质设计的编程环境。 l实操:通过VScode连接服务器,在课程目录中创建、编辑并直接运行蛋白质生成脚本。 Claude Code & Kimi Code AI辅助编程: l核心理念:AI嵌入终端与IDE,实现代码生成、重构、Debug闭环,加速生物信息学开发。 l工具定位:自主编程Agent,自然语言直驱文件系统与脚本执行,独立完成"写代码—运行—报错修复—结果分析"完整链路。 l实操:以自然语言驱动蛋白质设计全流程——自动生成RFdiffusion推理脚本、批量处理PDB文件、解析ProteinMPNN序列打分输出。 模块二:ESM模型探索 — 从安装到基础应用 目标:掌握Meta AI的ESM系列工具,为蛋白质序列分析和结构预测打下基础。 ESM (Evolutionary Scale Modeling) 简介: l蛋白质语言模型:讲解ESM如何将自然语言处理的思想应用于蛋白质序列。 l主要应用:序列嵌入、突变效应预测、结构预测(ESMFold)。 软件安装与环境配置: l使用pip 在之前创建的Conda环境中安装 fair-esm 库。 l依赖检查与GPU环境确认 ( torch, cuda)。 基础操作演示与实战: l获取序列嵌入(Embeddings):编写Python脚本,为给定的FASTA序列生成高维特征表示,并解释其用途。 l序列分类模型训练:基于ESM提取的序列嵌入特征,构建简单的分类器,完成蛋白质功能分类或亚细胞定位预测任务。 l单序列结构预测(ESMFold):使用ESMFold命令行工具或API,对一条蛋白质序列进行快速结构预测。 l结果分析:解读输出的PDB文件,重点关注pLDDT分数,并使用PyMOL等软件进行三维结构可视化。 l实操练习:学员独立完成一个未知蛋白的结构预测,并评估预测结果的可靠性。 下午: 模块三 模块三:ProteinMPNN深度实践 — 反向折叠与序列设计 (3小时) 目标:精通使用ProteinMPNN,根据给定的蛋白质骨架设计出全新的、高稳定性的氨基酸序列。 软件安装与环境配置: l从GitHub克隆 ProteinMPNN 官方仓库 ( git clone)。 l使用Conda创建专用环境并安装所有依赖项。 l下载预训练好的模型权重文件,并放置到指定目录。 序列设计核心流程: l基础工作流:输入PDB结构文件,运行设计脚本生成候选序列。 l重要参数解析:输入输出路径、生成序列数量、采样温度等。 l结果文件解读:理解输出FASTA中的序列评分及其意义。 进阶设计技巧: l位点控制策略:固定关键残基、排除特定位置、氨基酸偏好等。 l复杂体系设计:多链蛋白、同源多聚体的序列优化。 l参数调优实践:通过温度参数平衡序列多样性与结构匹配度。 l质量评估方法:筛选高分序列、分析氨基酸组成合理性。 |
第二天:蛋白质结构生成与综合项目实战 (6月28日,上午09:-12:00;下午13:30-16:30) 上午: 模块四 模块四:RFdiffusion核心技术 — 从无到有生成蛋白质骨架 (3小时) 目标:掌握蛋白质结构生成工具RFdiffusion,实现从头设计全新拓扑结构的能力。 软件安装与环境配置: l详细安装流程:分步指导通过git clone 获取源码,使用Conda/Mamba创建环境。 l常见问题排查:总结安装过程中可能遇到的编译错误、依赖冲突等问题及解决方案。 结构生成操作流程: l核心脚本run_inference.py :演示完整的命令行调用格式。 lContig字符串详解:详细讲解如何通过 contig 字符串定义生成长度、引入已知motif、指定二级结构等。例如: 'A1-100' (生成100个残基), '10-20/A1-10/10-20' (在A链1-10号残基两侧各生成10-20个残基)。 常用参数设置和输出结果解析: linference.output_prefix: 输出文件命名 ldenoiser.noise_scale_ca: 主链噪声水平控制 ldenoiser.noise_scale_frame: 局部构象噪声控制 lscaffolder.symmetry: 对称性参数(C2, D2, I等)。 l输出结果深度解析:使用PyMOL加载.traj.pdb轨迹文件,观察结构生成过程,并学习如何筛选最优候选结构。 下午: 模块五 & 模块六 模块五:RFdiffusion引导的Binder骨架生成 项目背景:设计一个能够特异性结合EGFR(表皮生长因子受体)的全新蛋白binder,用于潜在的癌症治疗应用。EGFR在多种癌症中过表达,是重要的药物靶点。 EGFR靶标分析: l解析EGFR蛋白结构特征(621 AA,胞外域关键结合位点)。 l确定设计目标:针对EGFR胞外域设计小分子binder。 l识别关键结合界面和潜在的相互作用热点区域。 RFdiffusion Binder设计实操: l输入EGFR结构PDB文件,指定目标结合区域。 l设置binder长度范围、扩散步数等关键参数。 l运行脚本生成20-50个候选binder骨架。 结果筛选与评估: l筛选策略实践:从生成结果中筛选出3-5个最优候选骨架,并进行可视化分析,检查结合界面的合理性。 模块六:序列生成 ProteinMPNN序列设计: l针对筛选骨架进行序列优化:输入RFdiffusion生成的top3候选骨架,固定界面关键残基,优化其余位置。 l参数调整与序列生成:设置合适的采样温度,每个骨架生成10-20条序列。 l序列筛选与优化:分析ProteinMPNN评分和氨基酸组成,检查界面残基的化学性质,选择每个骨架的top3序列进入验证阶段。 AlphaFold3结构验证: l序列折叠预测:将ProteinMPNN设计的序列提交AlphaFold3预测,评估pLDDT分数。 l结构比对与验证:计算预测结构与RFdiffusion骨架的RMSD(目标 < 2Å),在PyMOL中叠加比对,检查界面保持情况。 课程总结与讨论 l回顾完整设计流程:靶标分析→ 骨架生成 → 序列设计 → 结构验证。 l讨论挑战与改进方向,介绍后续优化策略。 课程总结与Q&A: l回顾两天课程的核心知识点与工作流。 l探讨AI蛋白质设计的当前局限与未来发展方向。 l提供进一步学习的资源和路径建议。 l开放式问答环节,解决学员所有遗留问题。 |
参会对象
培训对象
培训对象
1.蛋白质工程领域科研单位专家及学者;
2.农学、医学、药学及食品学院校及企业蛋白质功能开发负责人;
3.生物工程领域从业工作者。
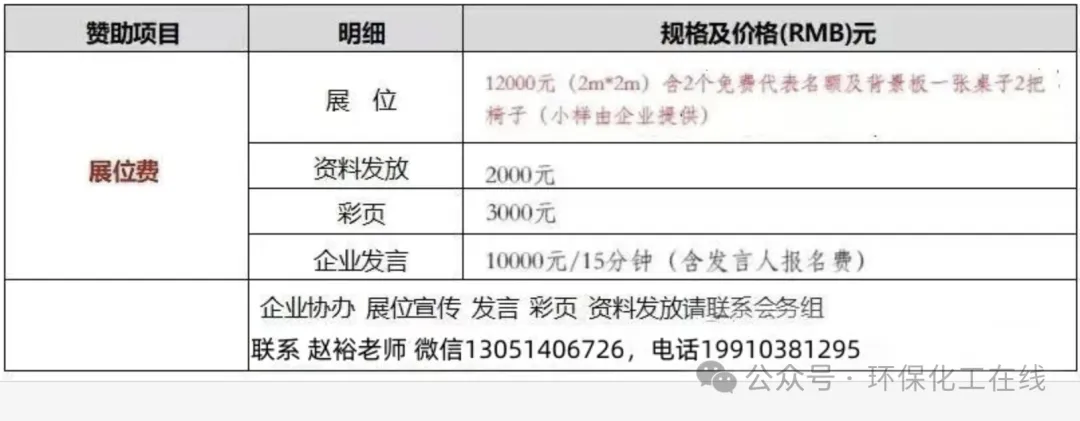
会议费用
及提供宣传推广项目概况
会议费用
会务费:3500元/人(含会议费、资料费等);同一企业报名2人以上3000元/人;住宿统一安排,费用自理。
及提供宣传推广项目概况

会议咨询报名
联系人:赵裕 微信:13051406726
电话:19910381295
1. 识别二维码填写参会报名表单

2.微信识别二维码可在线咨询

★感兴趣的人员欢迎咨询报名
★会议诚邀赞助单位,协办单位及新产品,新设备展示单位
也可点击:阅读原文 填写参会报名表单
