 夜雨聆风
夜雨聆风最近我系统阅读了 verl 的 RL 后训练源码,并整理了一份较完整的架构分析报告。完整版本我放在了 GitHub 仓库中:
GitHub:https://github.com/junjiewang253-ctrl/verl-architecture-report
这篇文章是报告的精简博客版。相比完整报告,本文不会逐行展开所有源码细节,而是围绕一个核心问题展开:verl 是如何把一次 RL 后训练任务,从配置文件变成一个可运行的分布式训练系统的?
如果只把 verl 理解成一个 PPO 或 GRPO 训练脚本,会很容易低估它的系统复杂度。实际上,verl 更像是一个面向大模型 RL 后训练的分布式运行框架:它同时处理配置管理、Ray 资源调度、worker 组织、rollout 推理服务、reward 计算、PPO/GRPO 算法逻辑、checkpoint 和权重同步等问题。
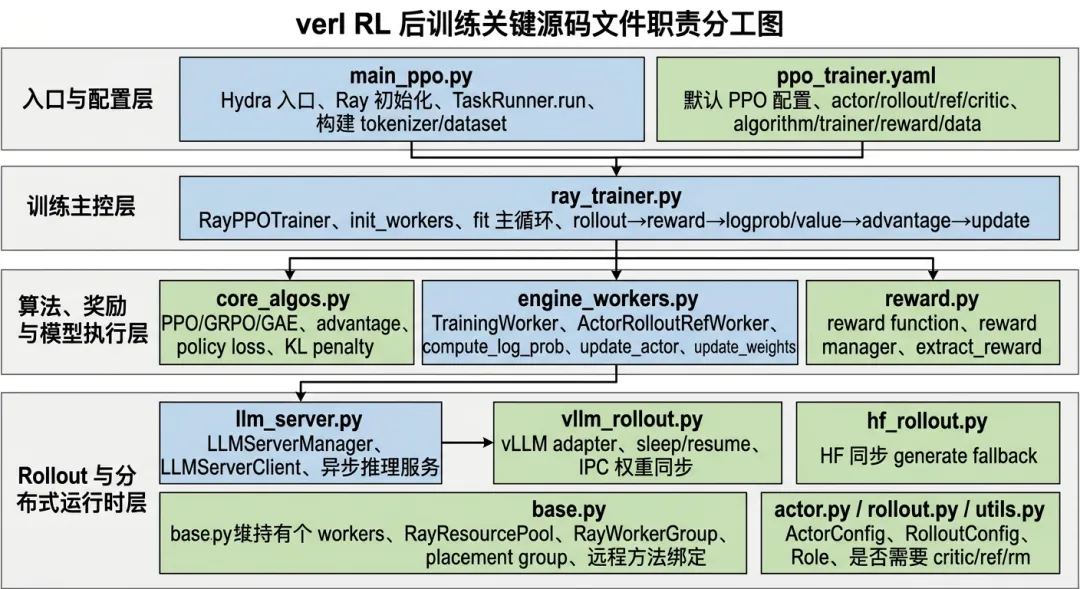
图 0-1 关键源码文件职责分工图
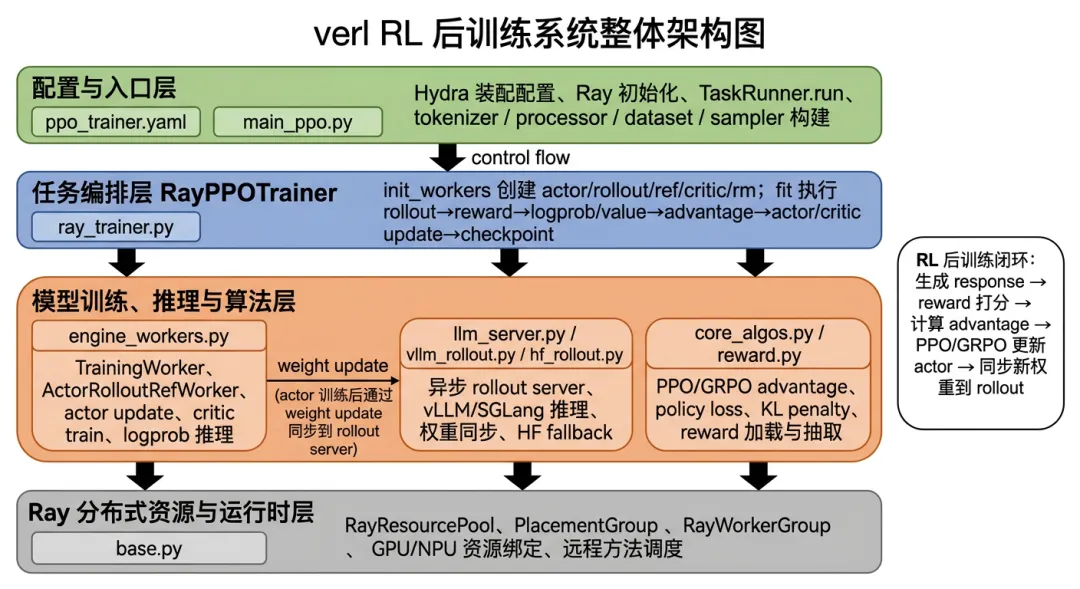
图 0-2 verl RL 后训练系统整体架构图
1. verl 不是一个训练脚本,而是一套分布式后训练系统
从整体上看,verl 的 RL 后训练系统可以分成几层。
最外层是配置和入口层,主要包括 `ppo_trainer.yaml` 和 `main_ppo.py`。`ppo_trainer.yaml` 负责声明一次训练所需的 actor、rollout、reference policy、critic、reward、algorithm、trainer、Ray 参数等配置;`main_ppo.py` 则负责接收 Hydra 组装后的配置,初始化 Ray,并把训练任务提交给远程的 `TaskRunner`。
中间是任务编排层,核心是 `ray_trainer.py` 中的 `RayPPOTrainer`。这是理解 verl 最关键的文件之一,因为完整训练数据流基本都在这里串起来:从 dataloader 取 prompt batch,调用 rollout server 生成 response,计算 reward、old log probability、reference log probability 和 value,再计算 advantage,最后更新 critic 和 actor,并把最新 actor 权重同步到 rollout server。
再往下是模型训练、推理和算法层。`engine_workers.py` 负责真正执行 actor、critic、reference model 的 forward、backward、optimizer step 和 logprob 推理;`llm_server.py` 和 `vllm_rollout.py` 负责异步 rollout 推理服务以及权重同步;`core_algos.py` 负责 PPO、GRPO、GAE、KL penalty、policy loss 等算法逻辑;`reward.py` 负责 reward function / reward manager 的加载和 reward tensor 的抽取。
最底层则是Ray 分布式资源与运行时层,主要由 `base.py` 承担。它封装了 Ray resource pool、placement group、worker group、远程方法绑定等机制。换句话说,verl 并不是直接用 `torchrun` 拉起几个进程,而是通过 Ray 把不同训练角色组织成可调度的远程 actor。
2. 从 YAML 到 RayPPOTrainer:训练任务是怎么被拉起来的
verl 的训练入口是 `main_ppo.py`。它首先通过 Hydra 读取配置。Hydra 在这里的作用可以理解为:把多个 YAML 配置文件组合成一个完整的 Python 配置对象。
RL 后训练的配置非常复杂,如果全部写成命令行参数,会非常难维护。比如 actor batch size、rollout tensor parallel size、reward model 路径、critic 是否启用、KL 系数、采样温度、Ray 资源数量等,都属于不同模块的配置。verl 通过 Hydra 的 defaults 机制,把这些参数拆分到 actor、rollout、ref、critic、reward、algorithm 等不同子配置中,再组合成一次完整训练配置。
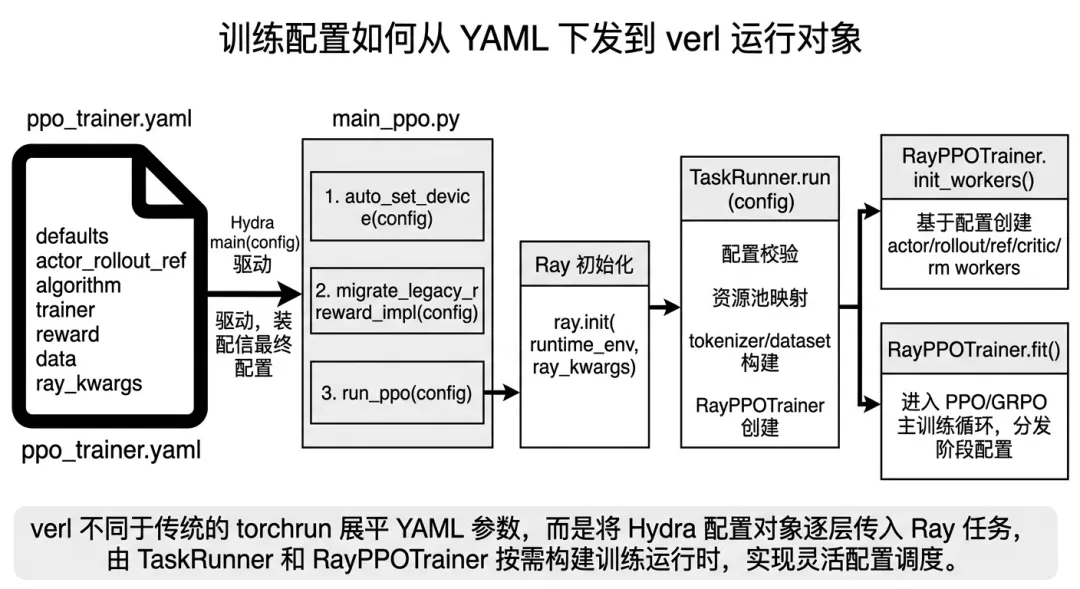
图 2-1 训练配置如何从 YAML 下发到 verl 运行对象
在 `run_ppo(config)` 中,verl 会先初始化 Ray,然后创建一个 Ray remote 形式的 `TaskRunner`。真正完成配置校验、资源池创建、worker 注册、dataset 构建和 trainer 启动的是 `TaskRunner.run(config)`。
所以整个启动链路可以概括为:
Hydra 把 YAML 变成 config;Ray 把训练任务放进远程 actor;TaskRunner 把配置转成资源池、worker、数据集和 trainer;RayPPOTrainer 才真正进入 RL 后训练主循环。
这个设计让配置管理、资源装配和训练逻辑之间保持了解耦。
3. base.py:verl 如何把 GPU/NPU 分给不同角色
很多人读 RL 框架源码时会先盯着 PPO loss,但在 verl 里,真正理解系统运行方式的关键反而是 `base.py`。
`base.py` 不负责 PPO、GRPO 或 reward 计算,它负责的是把 actor、rollout、reference、critic、reward 等逻辑角色转换成 Ray actors,并把这些 actors 放到合适的 GPU/NPU 资源上运行。
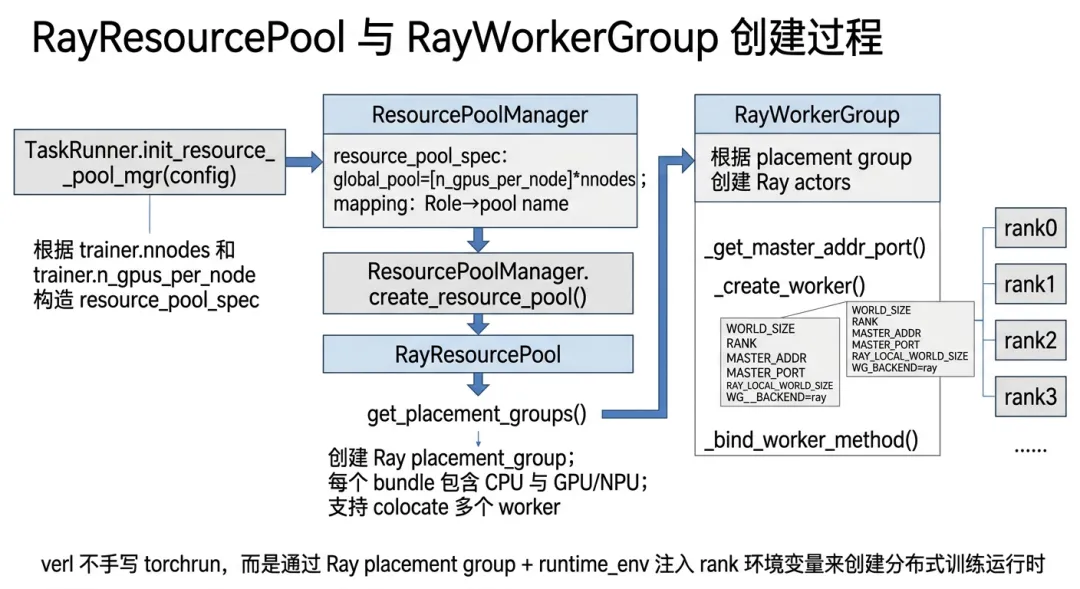
图 3-1 RayResourcePool 与 RayWorkerGroup 创建过程
在 verl 中,资源分配不是直接写死“actor 用第几张卡、critic 用第几张卡”。它会先构造 resource pool,例如单机 8 卡可以理解为:
global_pool: [8]
两机每机 8 卡可以理解为:
global_pool: [8, 8]
如果 reward model 或 teacher model 需要独立部署,还可以额外创建 `reward_pool`、`teacher_pool`。然后 verl 再维护一个 role 到 resource pool 的映射,比如 actor、rollout、reference、critic 默认都可以映射到 `global_pool`,而独立 reward model 可以映射到 `reward_pool`。
真正向 Ray 申请资源的是 `RayResourcePool.get_placement_groups()`。它会创建 placement group 和 bundle。可以近似理解为:**bundle 是一个单卡资源槽位,placement group 是一组资源槽位的预留。**
更有意思的是,verl 支持多个 worker group 在同一张 GPU 上共置运行。比如 actor、rollout、ref 可以通过 `max_colocate_count` 被放在同一批 bundle 上。这样做很适合 RL 后训练,因为 actor、rollout、ref 等角色有时并不需要完全独占一套物理 GPU,而是需要在不同阶段共享资源。
`RayWorkerGroup` 还会负责给每个 worker 注入分布式环境变量,比如 `WORLD_SIZE`、`RANK`、`MASTER_ADDR`、`MASTER_PORT`。这有点像 `torchrun` 做的事情,只不过在 verl 里,这些工作是通过 Ray 的 runtime environment 和 placement group 完成的。
更重要的是,`RayWorkerGroup` 会把 worker 中被注册的方法绑定到 controller 侧。于是 trainer 可以直接调用:
actor_rollout_wg.update_actor(...)
actor_rollout_wg.compute_log_prob(...)
critic_wg.train_mini_batch(...)
表面上看像普通 Python 方法调用,但底层实际是 Ray actor 的 remote 调用。这个封装让 `RayPPOTrainer.fit()` 可以专注于训练数据流,而不必在主循环里反复写底层分布式调度逻辑。
4. init_workers:不是“初始化几个模型”,而是搭建整个运行时系统
`RayPPOTrainer.init_workers()` 是 verl 从“配置对象”进入“真实分布式运行时”的关键函数。
很多时候我们会把它简单理解成“初始化 actor、critic、rollout、reward”。但更准确地说,它做的是一次完整的运行时装配:先让资源池真正落地,再把逻辑角色转换为 Ray worker,然后搭建 rollout server、reward loop、teacher/distillation 链路、checkpoint manager 和权重同步机制。
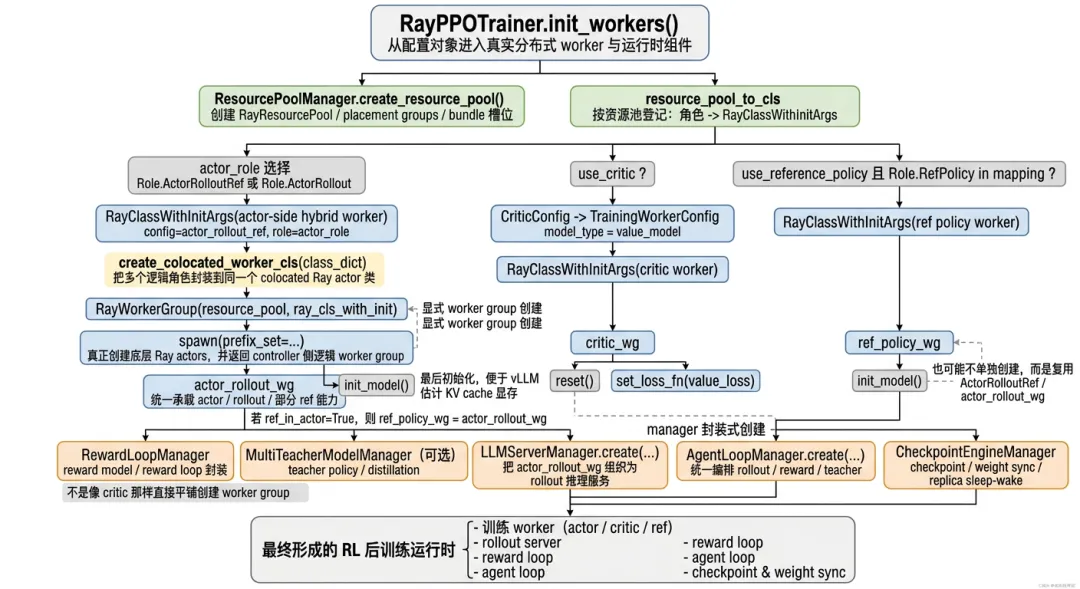
图 4-1 RayPPOTrainer.init_workers() 运行时装配流程图
在 actor 侧,verl 并不是总是分别创建 actor worker、rollout worker、ref worker。更常见的情况是,它把 actor、rollout、reference policy 相关能力组织成一个 actor-side hybrid worker,也就是 `ActorRolloutRefWorker`。这样 actor 训练、rollout 推理和 ref logprob 计算可以通过同一个混合 worker 体系完成。
critic 则复用统一模型训练引擎,但通过 `model_type="value_model"` 区分为 value model。也就是说,actor 和 critic 并不是两套完全不同的训练框架,它们底层都走统一的模型执行 worker,只是损失函数、模型类型和配置不同。
reference policy 的部署方式更灵活。它可以是独立 worker group,也可以由 `ActorRolloutRefWorker` 提供 ref 能力,还可以在 LoRA 场景下通过 `ref_in_actor=True` 直接复用 actor worker,并在推理时关闭 LoRA adapter 来计算 reference logprob。
真正把逻辑角色变成 Ray actor 的关键步骤,是 `create_colocated_worker_cls` 和 `RayWorkerGroup.spawn()`。如果多个角色被 colocate 到同一资源池中,controller 侧看到的 actor、critic、ref worker group 不一定对应物理上完全独立的 Ray actors,它们可能只是同一批底层 actors 的不同逻辑视图。
这也是 verl 系统设计里很重要的一点:逻辑角色和物理进程不是简单一一对应关系。
5. engine_workers.py:统一模型执行层
如果说 `ray_trainer.py` 负责训练流程编排,`base.py` 负责分布式运行时,那么 `engine_workers.py` 就是距离“模型真正执行”最近的一层。
它主要定义两个关键类:`TrainingWorker` 和 `ActorRolloutRefWorker`。
`TrainingWorker` 是统一模型训练/推理执行单元。它并不直接写死某一种训练后端,而是通过 `EngineRegistry.new()` 动态实例化具体模型执行引擎。底层可以是 FSDP、Megatron、VeOmni、TorchTitan、MindSpeed 等不同 engine。这样,上层 trainer 不需要关心参数如何 shard、梯度如何同步、optimizer 如何组织、checkpoint 如何存储,这些都交给具体 engine 处理。
`TrainingWorker` 对外暴露统一接口,比如:
train_mini_batch()
train_batch()
infer_batch()
save_checkpoint()
load_checkpoint()
set_loss_fn()
reset()
这说明它不是固定的 actor worker,而是一个统一执行壳。外部可以给它注入不同 loss function:actor 可以注入 PPO policy loss,critic 可以注入 value loss,distillation 场景也可以注入蒸馏相关 loss。
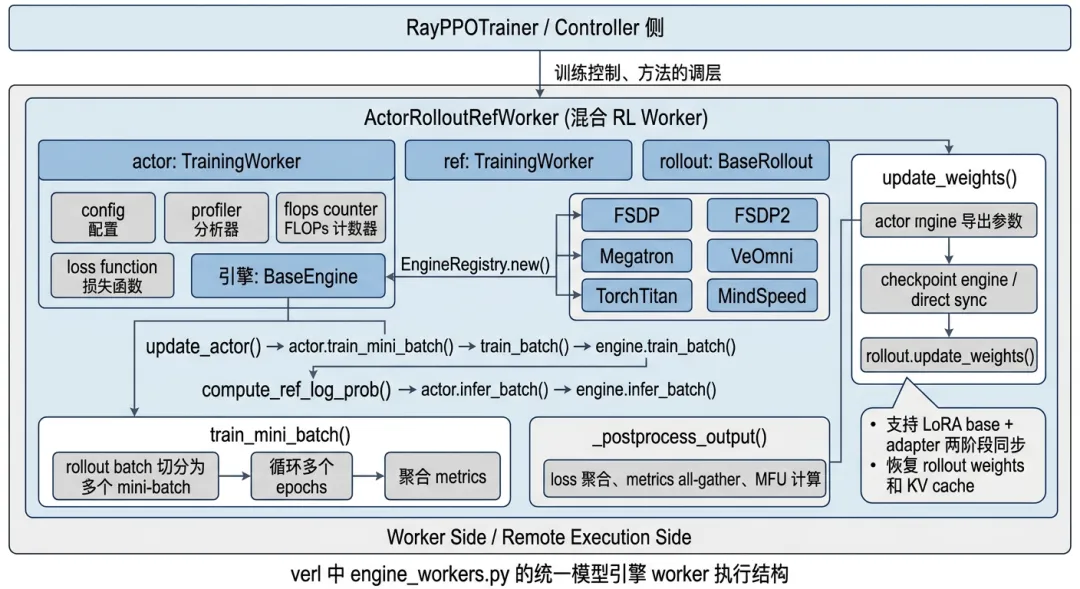
图5-1 verl中engine_workers.py的统一模型引擎worker执行结构
`ActorRolloutRefWorker` 本身更像一个角色容器。它可以根据 role 组合出仅 actor、仅 rollout、仅 ref、actor + rollout、actor + rollout + ref 等多种形态。真正的 actor 更新仍然通过内部的 `TrainingWorker` 完成,rollout 则通过 rollout backend 完成。
其中最关键的函数之一是 `update_weights()`。它负责把 actor 最新权重同步给 rollout 推理侧。这个过程不是简单复制参数,而是要处理训练态和推理态之间的一整套状态切换:恢复 rollout 权重空间、提取 actor 参数、区分 base 权重和 LoRA adapter 权重、执行参数同步、必要时把 actor 参数 offload 回 CPU,并恢复 rollout KV cache。
所以 `update_weights()` 是 actor 训练和 rollout 服务之间的桥梁。
6. Rollout:为什么 verl 要把生成做成异步服务
在 RL 后训练中,rollout 生成通常是最耗时、最占资源的环节之一。如果直接在训练进程里调用本地 `model.generate()`,会带来几个问题:训练图和推理图争抢显存,自回归解码吞吐较低,多请求并发和 prefix cache 难以充分利用,训练与生成也难以解耦。
verl 的主路径是把 rollout 做成服务化异步推理。训练器不直接调用本地生成函数,而是通过 `LLMServerClient` 向 rollout server 集群发送生成请求。负载均衡器会根据 least in-flight 和 sticky session 等规则选择合适的 server replica,以兼顾负载均衡和 prefix cache 命中率。
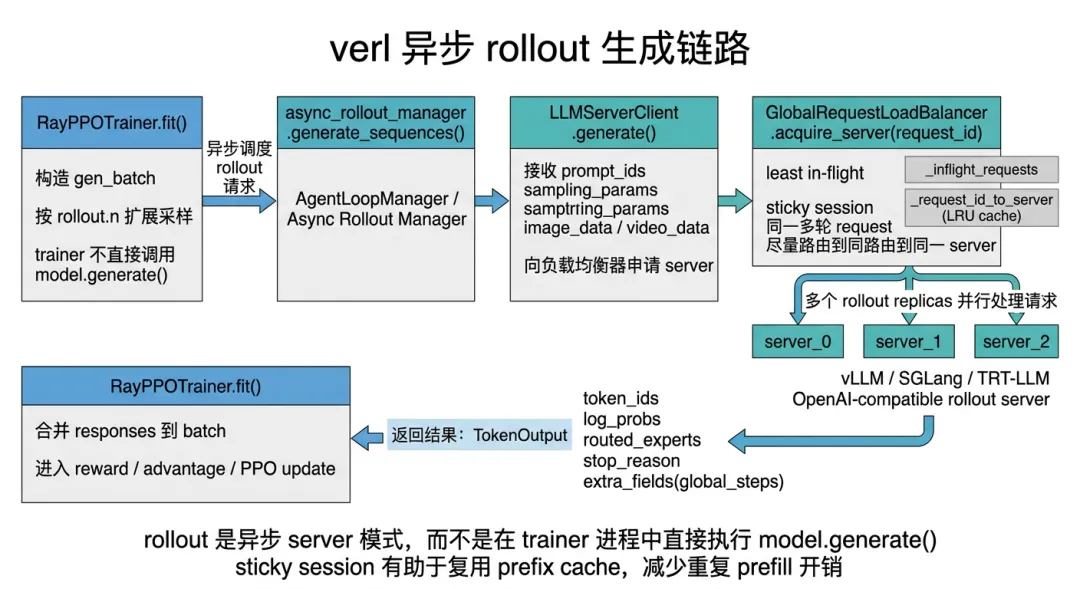
图6-1 异步rollout 生成链路
在这条链路中,`llm_server.py` 更像控制平面,负责创建 server replicas、启动全局负载均衡器、向 trainer 提供 client;`vllm_rollout.py` 中的 `ServerAdapter` 则负责连接具体推理后端,处理权重更新、sleep / resume、KV cache 清理等运行时问题。
一个容易被忽略但很重要的细节是:当 actor 权重更新后,rollout server 的旧 KV cache 必须清理。因为 KV cache 记录的是旧权重下生成过程中缓存的 key/value。如果模型权重已经变成新版本,而 cache 仍然对应旧权重,就会出现“新权重 + 旧缓存”的不一致生成。verl 在权重更新后清理 KV cache,本质上是在保证 rollout 结果对应当前 actor 权重。
这也说明 verl 的 rollout 子系统并不是简单封装 generate,而是把**异步调度、服务化推理、负载均衡、权重热更新和缓存一致性**放在了同一个系统里考虑。
7. HF 同步 Rollout:为什么还需要 fallback
虽然 verl 当前主路径已经转向异步 rollout server,但它仍然保留了 HF 同步 rollout 的 fallback 逻辑。
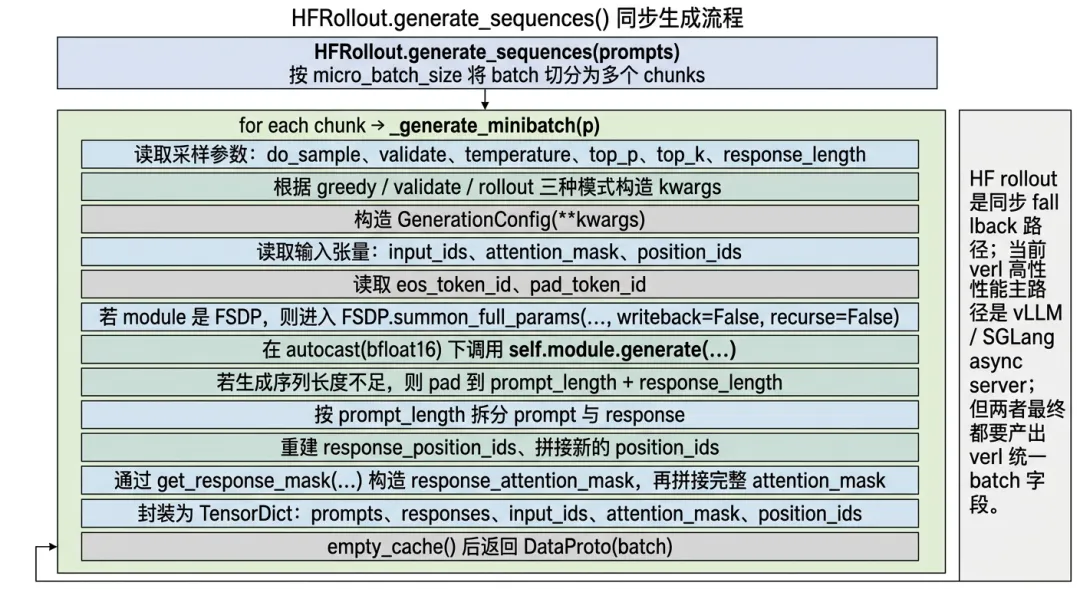
图7-1 HFRollout.generate_sequences() 同步生成流程
HF rollout 的价值不在于性能最强,而在于它提供了一条简单、稳定、低依赖的生成路径。对于理解 verl 的系统设计来说,这一点也很重要:verl 追求高性能,但并没有把所有能力都绑定在单一推理后端上,而是保留了可部署性和回退路径。
8. Reward:从自定义函数到 RewardManager
RL 后训练中的 reward 往往是任务相关的。数学任务可能检查最终答案是否正确,代码任务可能执行单元测试,格式约束任务可能检查输出是否符合 JSON 或指定标签。因此,reward 不适合完全写死在训练主循环里。
verl 的 `reward.py` 负责加载自定义 reward function 或默认 reward manager。它会先检查用户是否提供了自定义 reward function。如果提供了路径和函数名,就动态加载该函数,并把配置中的 `reward_kwargs` 包装进去。如果没有提供,则根据 reward manager 的名字选择默认评分逻辑。
这套设计的好处是:用户可以在不修改 verl 主代码的情况下,把任务特定的 reward 逻辑接入训练框架。
更进一步,reward 的执行不一定只是本地字符串比对。对于代码任务,reward 可能需要调用 sandbox 执行环境;对于工具调用任务,reward 可能需要根据外部执行结果打分。因此,RewardManager 本质上是一个“如何评分”的可执行后端,而不只是一个简单函数。
9. RayPPOTrainer.fit:真正的训练主循环
当资源、worker、rollout server、reward loop 和 checkpoint manager 都初始化完成后,训练才真正进入 `RayPPOTrainer.fit()`。
可以把一次训练 step 简化成下面这条数据流:
prompt batch
→rollout server 生成 response
→reward function / reward model 计算奖励
→actor 计算 old logprob
→reference policy 计算 ref logprob
→critic 计算 value
→GAE / GRPO 等算法计算 advantage
→更新 critic
→更新 actor
→actor 权重同步到 rollout server
这条链路体现了 verl 的核心设计:训练主循环本身更像一个 controller。它并不直接执行所有模型计算,而是调度不同 worker group 和 manager 完成各自职责。
这也是为什么前面的 worker 抽象、Ray 资源管理、rollout server 和 reward manager 如此重要。没有这些底层抽象,`fit()` 就会变成一个充满 remote 调用、资源调度、数据切分、权重同步细节的复杂函数;而 verl 通过分层封装,让主循环更接近算法数据流本身。
10. 总结:verl 的核心不是某个 PPO loss,而是系统化的 RL 后训练运行时
读完 verl 源码后,我最大的感受是:verl 的复杂度不只在算法,而在系统工程。
如果只看 PPO / GRPO 的 loss 公式,很难理解 verl 为什么要设计这么多层抽象。但从完整数据流看,这些抽象都有比较明确的作用:
`main_ppo.py` 和 Hydra 解决配置入口问题;`TaskRunner` 解决训练任务装配问题;`base.py` 解决 Ray 资源池、placement group 和 worker group 问题;`init_workers()` 解决运行时系统搭建问题;`engine_workers.py` 解决统一模型执行问题;`llm_server.py` 和 `vllm_rollout.py` 解决异步 rollout 服务问题;`reward.py` 解决任务相关 reward 接入问题;`core_algos.py` 则承载 PPO、GRPO、GAE、KL 等算法计算。
所以,verl 更像是一套面向大模型 RL 后训练的分布式系统,而不仅仅是一个 RL 算法实现。
完整报告中我对这些文件做了更细的源码级拆解,包括配置如何下发、Ray worker 如何创建、actor/rollout/ref 如何 colocate、TrainingWorker 如何对接不同 engine、rollout server 如何同步权重、reward manager 如何加载自定义评分逻辑等。感兴趣可以看完整仓库:
GitHub:https://github.com/junjiewang253-ctrl/verl-architecture-report
如果你也在读 verl,建议不要一开始就只盯着 PPO loss,而是先从这条主线入手:
配置入口
→ 资源池
→ worker 装配
→ 模型执行
→ rollout 服务
→ reward 计算
→ advantage / loss
→ actor 更新
→ 权重同步
沿着这条链路看,verl 的架构会清晰很多。
