 夜雨聆风
夜雨聆风大摩的亚洲/科技产业研究团队在 2026年5月中下旬发布了一份关于NVIDIA 下一代 Vera Rubin 平台(VR200 NVL72 机架)物料清单拆解 视角的研究报告。这个报告自下而上拆解了 NVIDIA Rubin算力集群的造价,是非常好的学习 AI infra 的内容。
这份报告的细节很多,先说研究报告大概结论:一台完整的 Rubin 机架,出厂价将高达 780 万美元(近 5600 万人民币),相比上一代 Blackwell 几乎翻倍!更重要的是,这份拆解揭示了一个行业新逻辑:除GPU外,AI 供应链的价值在向存储、PCB/CCL、被动元件MLCC、基础组件 ABF载板、液冷与电源、甚至是一些 ODM 厂商(这个最反直觉)外溢。
一、NVIDIA的算力架构的变迁史





简单总结NVIDIA 算力集群演进的核心规律:从 P100 到 Rubin,NVIDIA 算力集群的演进可以用一句话概括:“用速度更快的物理连接(从 PCIe -> 内部 NVLink -> 外部网线 -> 机架内铜缆 -> HBM4),不断消灭数据传输的延迟。” 黄仁勋不仅是在做芯片,他是在用网络、散热、材料和电源,把整个数据中心重写成一台巨大的、不可分割的超级计算机。
二、NVIDIA Rubin 平台 BOM 物料清单定量拆解
2.1 核心研究逻辑:算力瓶颈由计算节点转向系统级互联
长期以来,AI 算力集群投资逻辑高度聚焦 GPU 芯片半导体微架构迭代。摩根士丹利针对 Vera Rubin 平台(VR200 NVL72 机架)自下而上 BOM 定量模型显示,AI 算力短板已从计算节点,转变为涵盖数据传输、能量传输的系统级互联物理极限。Rubin 时代,非 GPU 组件资本支出增速首度超越主芯片,系统总拥有成本优化,愈发依托底层物理材料与配电架构重构。
2.2 供应链核心子系统:BOM 增量与技术规格定量分析
Blackwell(GB200)阶段,NVIDIA 自研 CPU、GPU 芯片整机成本占比约65%,牢牢掌握供应链议价主导权。发展至 Rubin(VR200 NVL72)机架体系,芯片成本占比将回落至 51% 左右。占比下滑并非芯片降价所致,Rubin 单颗硬件定价创下历史新高:单颗 Rubin GPU 预估售价 5.5 万美元,单颗 Vera CPU 预估售价 5000 美元。核心原因在于机架内高带宽存储、超高层 PCB、高压直流配电等非芯片部件规格全面升级,成本上涨幅度远超核心芯片。
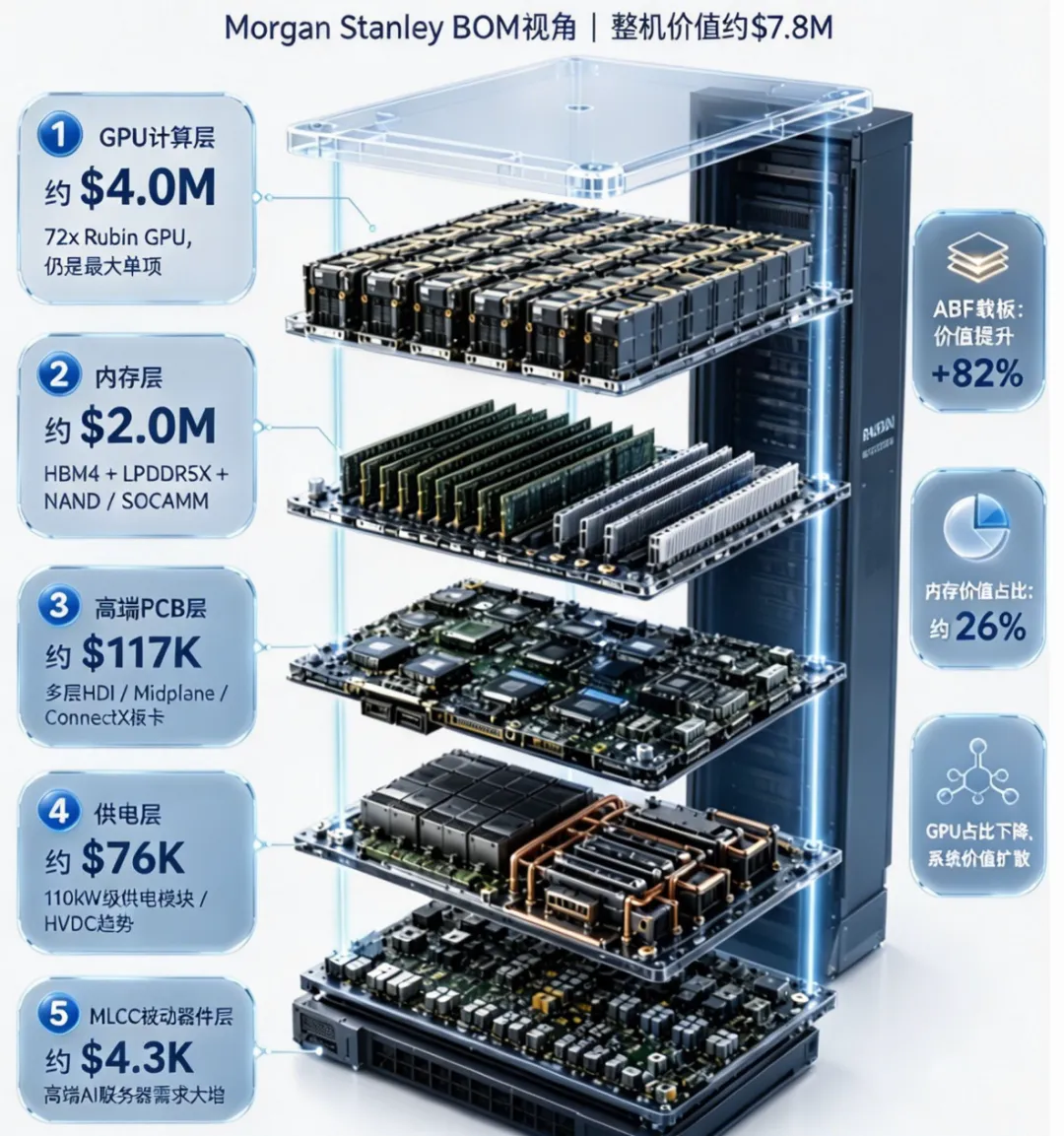
供应链核心子系统:BOM 增量与技术规格定量分析:
对比 GB300 与 Rubin 机架物料差异,可见各子系统技术迭代与价值增幅变化:
存储系统:为适配 AI 智能体、多模态大模型高并发、长上下文推理需求,Rubin 重构缓存与闪存架构。搭载3nm 工艺 HBM4 第六代高带宽内存,整机配备54TB LPDDR5X 内存,搭配价值百万美元级 3D NAND 闪存。整机存储成本暴涨 435%,成本占比从不足 10% 攀升至 25%-30%,形成显著"存储税"效应,成为仅次于主芯片的第二大成本模块。
高速互联系统:高速信号衰减、高密度互联成为架构核心物理难题,倒逼物理介质规格升级。机架内部全面引入高密度、超高层数(高达 44 层)的 Compute Midplane(计算中置板),以及 72 个 ConnectX 模块 PCB;覆铜板(CCL)全面进入超低损耗(Ultra Low Loss)的 M8 级别。单机架 PCB 物料成本从 3.5 万美元增至 11.7 万美元,涨幅达 233%。
电源系统:单机架功耗从120kW-140kW 飙升至 250kW,传统交流电配电模式触碰效率与空间上限。摒弃多级电能转换损耗,采用±400V 至 800V 高压直流直供架构(HVDC),能源转换效率提升 4-5 个百分点,可达 92%-95%。高压电路对稳压滤波要求提升,高阶耐压贴片电容用量大增,MLCC 元件成本上涨 182%,整套电源系统成本增幅 32%,总成本突破 15 万美元。
散热与封装系统:
液冷(Thermal):针对 250kW 的极端热设计功耗(TDP),Rubin 系统全面拥抱去风扇化的全液冷设计。整机架液冷系统价值量录得 7.21 万美元(+12%),且其部署与 HVDC 电源系统呈现高度的技术协同。
ABF 载板:受 HBM4 堆叠工艺及先进封装(CoWoS)复杂度提升影响,单颗 Rubin GPU 对应的 ABF 载板成本上扬至约 200 美元,整体成本增长 +82%。
ODM 代工产业财务模型重估:市场曾预判 NVIDIA 统一机架互联架构后,代工厂技术壁垒与盈利空间会持续压缩,量化数据推翻该结论。Rubin VR200 NVL72 机架出厂均价,从上代400 万美元提升至 780 万美元。代工毛利率保持平稳前提下,单台机架利润额度提升 35%-40%,大幅提振头部代工企业营收利润。
三、硬件造价攀升,单位 Token 成本却逆势走低
算力集群演进呈现特殊科技特征:整机硬件采购成本不断抬高,但单位 Token 生产成本实现指数级下降。
单位 Token 成本 =(系统折旧 + 运营能耗)÷ 实际 Token 吞吐量
注:该成本对比,以各代旗舰硬件全生命周期总拥有成本为基准,衡量模型实际生产效率,并非同款模型跨硬件运行成本。算力成本从 V100 时代10 美元 / 百万 Token,降至 Rubin 架构预估0.01 美元 / 百万 Token 以下,跨度达数个数量级,底层逻辑可分为三大驱动维度。下表以生成 100万个 Token(1M Tokens) 为基准,对比了各代核心集群的成本结构(包含电费、折旧及网络平摊):
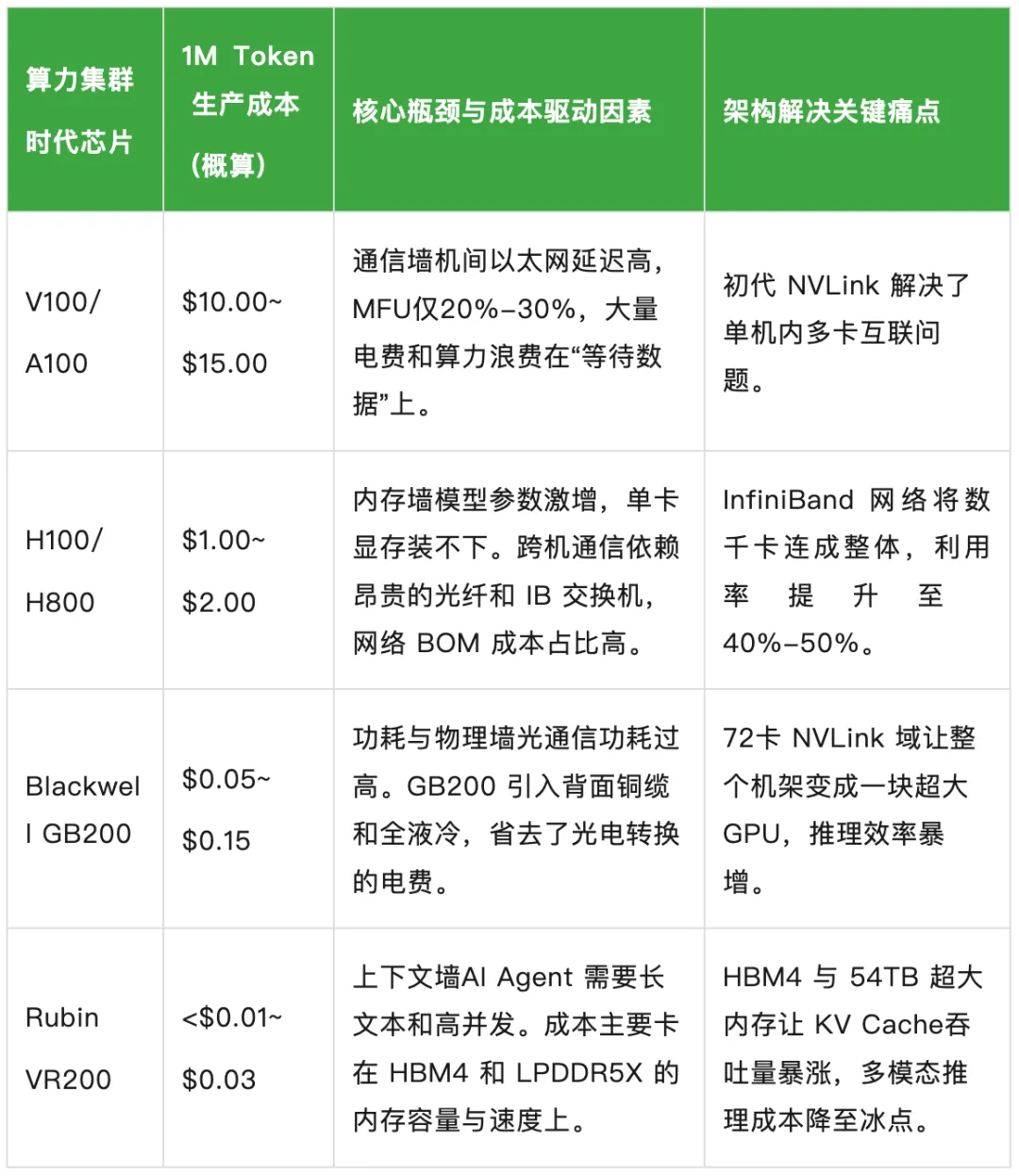
计算受限转向带宽受限的成本对冲
早期大模型成本偏高,根源为算力密度不足,属于计算受限场景。3nm 工艺落地后,芯片峰值算力大幅提升,计算成本占比持续下降。
当前效率瓶颈转为数据吞吐速率不足的“带宽受限”问题。Rubin 重金投入高端 PCB、M8 覆铜板与 HBM4 内存,核心目的在于提升算力的实际利用率(MFU)。存储与互联硬件高额投入,规避数据卡顿造成的算力闲置,大幅提升 Token 产出总量,最终摊薄单枚生成成本。
KV Cache下存储成本价值兑现
全周期架构优化实现节能增效
电力能耗是算力长期运营的核心隐性成本。全液冷散热、高密度铜缆互联虽然在前期抬高了硬件采购费用(CapEx),但大幅减少了电能损耗、降低了机房能效指标(PUE)。这种长期运营成本(OpEx)的缩减,有效提升了单位功耗的算力产出,最终缩减了长期摊销后的 Token 生产成本。
进一步分启发:Rubin 全面平台落地后,大模型推理算力逐步迈入普惠标准化阶段,边际生产成本无限趋近于零。低廉算力打破 API 高价约束,重构 AI 商业应用模式,再下一步就看AI应用的商业化何时爆发了。本报告/文章仅供个人产业研究之用,不构成任何形式的投资建议或投资依据。
