 夜雨聆风
夜雨聆风
在上一篇AI 安全运营平台,真正难的不是 Agent文章中,想到了很多问题,但是没有给出答案,所以,后续的填坑来了。问题太多,需要分几期展开说,今天先聊聊AI安全运营平台的初步认知。
首先,这是我理解的AI安全运营平台:
一个真正的 AI 安全运营平台,不是在 SOC 旁边加一个会说话的助手,而是把 AI 沉到数据、工具、流程、证据和审批的底层,让每一次响应都可行动、可追溯、可问责。
因为AI 安全运营平台如果只是在原安全产品上多个聊天框,分析师问一句“这个告警严重吗”,AI 回一段分析,再顺手生成一份报告。
那就太浅了。
如果平台最后只停在这里,它更像一个安全 Copilot,或者一个接了知识库的问答助手。它可以提高分析师查资料、写报告、做初步研判的效率,但还没有真正进入安全运营的主流程。
真正难的地方在于:
一条告警进来以后,安全团队要看的不是一句解释,而是一串问题:这条告警从哪里来?有没有关联主机、账号、IP、域名、邮件、流量、漏洞、资产重要性?要不要联动 EDR?要不要封禁防火墙策略?谁来审批?误封了怎么办?最后报告里的每一个结论,能不能对应到日志、工具返回、人工确认和处置结果?
这些问题如果没有回答清楚,AI 再会说,也很难变成安全运营平台。
那么,AI 安全运营平台到底是什么?
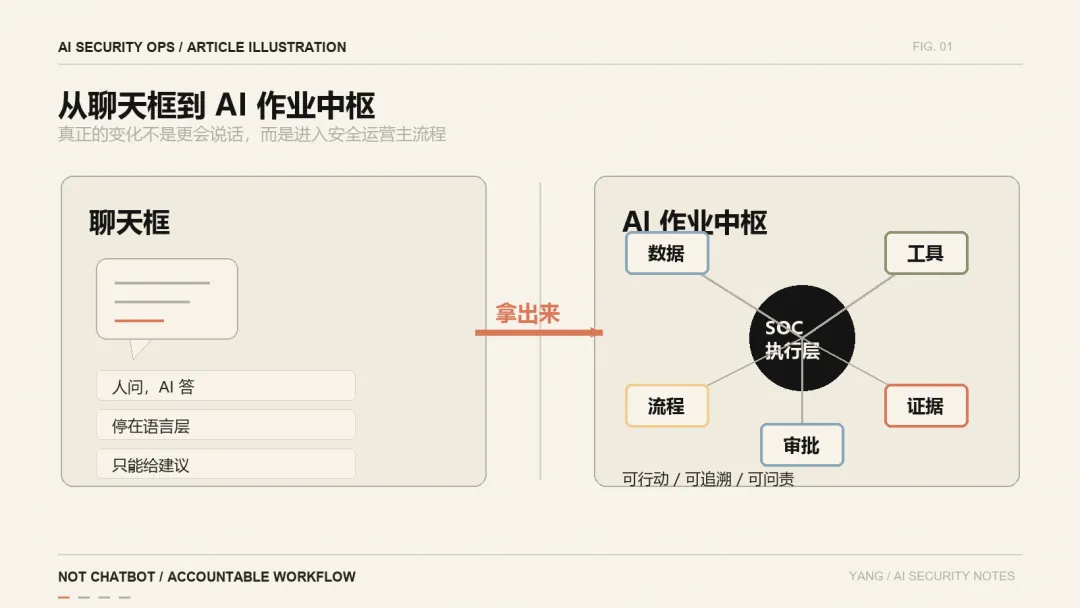
一、核心定位:站在现有安全工具之上、承担认知劳动、留下完整证据链的 AI 作业中枢。
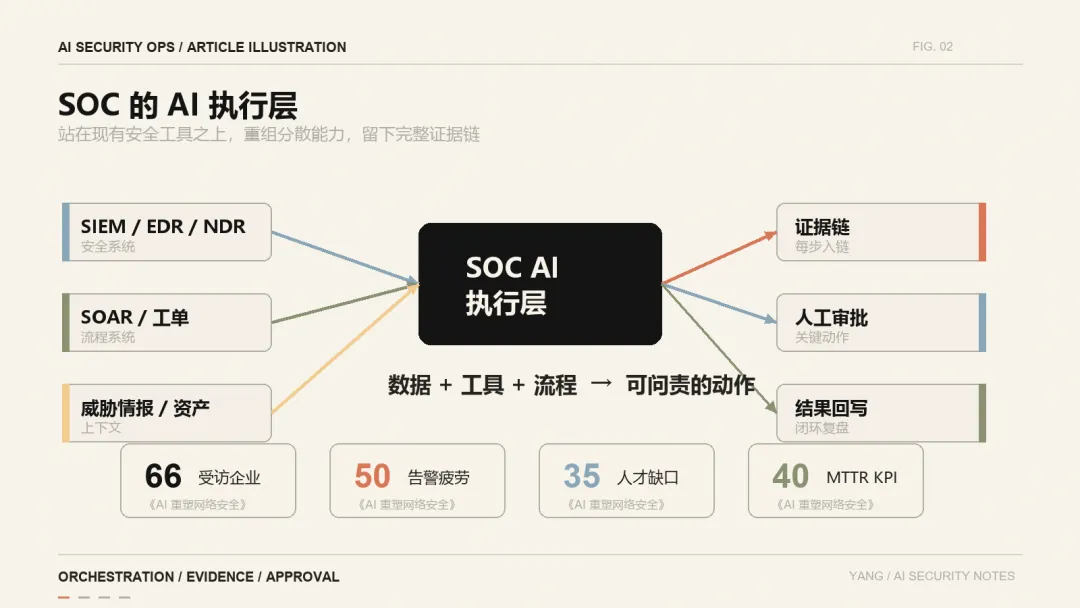
AI 安全运营平台,是把企业已有的安全数据、安全工具、研判流程、处置动作、证据链和人工审批,重新组织成一个可行动、可审计、可问责的 AI 作业中枢。
关键的地方在于:
第一,它不是凭空替代 SIEM、EDR、NDR、SOAR、工单、威胁情报、资产系统。恰恰相反,它要站在这些系统之上,把它们原本分散的能力重新编排起来。
第二,它不是只负责回答问题。它至少要能在明确边界内完成一段工作流:告警进入、初步分诊、多源查询、证据聚合、风险判断、处置建议、人工审批、动作执行、结果回写。
第三,它必须可追溯。安全场景里最怕一句“AI 判断是高危”。真正能上生产的说法应该是:它基于哪几条日志、哪个工具返回、哪个时间窗口、哪个资产上下文、哪个人工审批节点,得出了这个结论。
数说安全《AI 重塑网络安全》报告里有一组数据很能说明为什么这个方向会变热:在 66 家受访企业中,50 家明确提到告警疲劳,35 家提到安全人才缺口,40 家把压缩 MTTR 作为核心 KPI。
这不是为了追概念。
安全运营的压力本来就来自三件事:告警太多、人不够、响应时间压不下来。AI 安全运营平台要解决的,也不是“让报告更像专家写的”,而是把原来严重依赖资深分析师的认知劳动,拆成一段段可以被机器承担、被人审查、被系统记录的流程。
这就是它的核心定位:SOC 的 AI 执行层——把数据、工具、流程编排成可问责的动作。
二、它不是聊天机器人,也不是 Agent 框架
1. 它不只是聊天机器人
聊天机器人做的是“人问,AI 答”。这在安全里当然有用,比如查知识库、解释告警字段、总结报告、生成处置建议。
但聊天机器人有一个天然边界:它大多停在语言层。
安全运营不是语言层工作。安全运营里有大量真实动作:查日志、拉资产、跑沙箱、调用威胁情报、创建工单、隔离主机、封禁 IP、回滚策略。
如果 AI 只能回答“建议你隔离主机”,但不能把隔离动作放进权限、审批、审计和回滚链路里,它仍然只是助手。
2. 它也不是 Agent 框架
LangChain、LangGraph、LlamaIndex、CrewAI、AutoGen 这类东西很重要,但它们更像构建材料,或者说,只是个脚手架。
框架可以提供状态、节点/边、工具调用、记忆、路由。但一个生产级 AI 安全运营平台,还要处理更多麻烦事:
安全数据怎么接入,字段怎么统一,噪声怎么降下来。 Agent 能看到哪些数据,不能看到哪些数据。 工具调用有没有最小权限和临时凭证。 高风险动作是否必须人工审批。 每一次推理和工具返回能否被重放。 模型幻觉、越权调用、敏感数据泄露、误动作如何评测和监控。
这些不是框架默认送你的能力。
这也是为什么我更愿意把 Agent 框架看成平台里的一个组件,而不是平台本身。一个能跑 demo 的 Agent,离一个能进客户生产环境的安全运营平台,中间隔着数据、权限、证据、审计和运维。
3. 它也不只是 SOC 产品增强
SOC 产品增强更像 Copilot 化:给 SIEM 加自然语言查询,给 SOAR 加剧本推荐,给 EDR 加对话式调查。
这些功能当然有价值,但它们通常还是围绕人的原有流程做增强。分析师仍然是每一步的主执行者,AI 更像旁边的辅助面板。
AI 安全运营平台的变化更深一点:工作单元开始从“人类分析师手工流程”,变成“智能体可执行流程”。人仍然重要,但位置会变成目标设定者、审批者、异常接管者和最终责任人。
《AI 重塑网络安全》报告里把这个阶段拆得很清楚:Copilot 1.0 是自然语言问答,Copilot 2.0 是结构化分析和建议,Agent 1.0 是在明确边界内自主执行标准化工作流,关键节点人工审批。至于全自主 Agent 2.0,报告也很谨慎地判断:目前还处于研究阶段,并没有成熟产品。
这个边界很重要。
今天比较现实的目标,不是让 AI 独立处理所有安全事件,而是让它先在 L1 告警处理、日常巡检、影子资产排查、钓鱼邮件研判、标准化溯源这些边界清楚的场景里,承担可控的一段流程。
三、它和 OpenClaw 的关系:不要把运行时当成完整平台
很多人会问:那它和 OpenClaw 有什么区别?
事实上, OpenClaw 本身不是一个安全运营平台。按它官方 GitHub 的定位,OpenClaw 是一个本地优先的个人 AI 助手。它的架构文档里包含 Interface、Gateway、Agent 等模块,可以承接多界面、多工具、多 Agent 的协作。
这类能力对 AI 安全运营平台当然有启发,尤其是 Agent 运行、工具调用、会话和网关。但它和完整的安全运营平台不是同一个抽象层级。
具体来说,大致的区别如下:
直白的讲,OpenClaw 可以像“Agent 运行层的一块材料”,但 AI 安全运营平台还要有安全数据底座、场景 Agent、治理层、证据层、评测层和运营闭环。
这就像你不能因为有了容器运行时,就说自己有了完整的生产级云平台。运行时很重要,但调度、网络、存储、权限、审计、监控、运维都要补上,才能真正上生产。
当然,MCP、A2A、OpenClaw 等运行时正在推动安全能力开放化,但也需要分层看:
MCP 更偏工具和数据源连接层,让模型标准化访问外部能力。 A2A 更偏 Agent 间协作层,让不同 Agent 能通信和协同。 OpenClaw 这类运行时更偏执行和网关层,承接任务运行、工具调用、权限和审计的一部分。
它们可以是平台的基础设施,但不是完整平台本身。
四、AI安全运营平台技术架构:四个平面
从架构角度拆,AI 安全运营平台大致有四个平面。
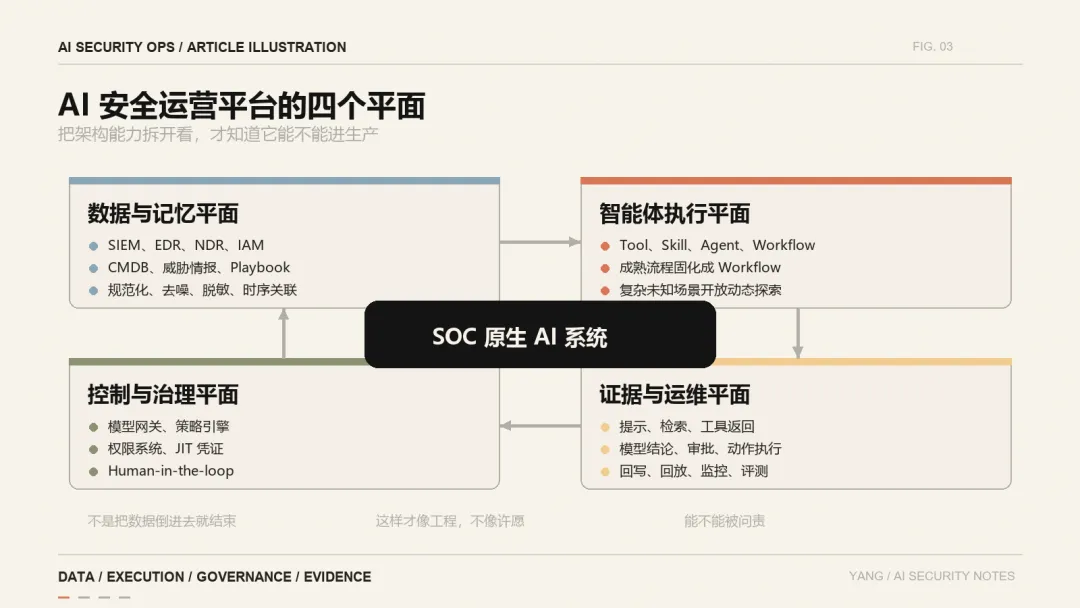
1. 数据与记忆平面
这是平台的感官和长期记忆。
它要接入 SIEM、EDR、NDR、邮件网关、IAM、堡垒机、防火墙、API 日志、漏洞扫描、CMDB、威胁情报、历史事件、Playbook、制度文档。
但接入不是把数据倒进去就结束。真正难的是规范化、去噪、脱敏、权限过滤、语义索引和时序关联。
我遇到过一个很典型的场景案例:只打通主机端数据,确实可以跑一部分溯源,但不完整;要完整溯源,就会碰到流量侧、应用侧、API 请求响应、防火墙日志和业务风险分析,那就必须继续补数据源。
没有足够的数据接入,AI 的推理只能停在浅层。
Memory 也在这一层。短期记忆保存当前事件上下文,长期记忆保存历史案例、误报规则、处置经验、组织环境和可复用 Playbook。
2. 智能体执行平面
这是平台真正“干活”的地方。
这里会有 Tool、Skill、Agent、Workflow。
Tool 是原子能力,比如查日志、查 IOC、跑 URL 沙箱、查询 CMDB、隔离主机、封禁 IP、创建工单等。
Skill 是组合能力,比如“钓鱼邮件研判”,它可能包含邮件头分析、URL 沙箱、发件人历史行为、收件人画像、威胁情报比对、标准化输出。比如影子资产排查,也是典型 Skill:拉 CMDB 全量清单、拉主机在线情况、做网络探活、加载白名单、交叉比对,最后输出影子资产清单。
Agent 是带角色、目标、记忆和规划能力的行动者。比如研判 Agent、调查 Agent、处置 Agent、报告 Agent。它通过 LLM 做推理,决定下一步调用哪个 Skill 或 Tool。
Workflow 是多个 Agent、Skill 和人工节点的编排链。它可以是相对固定的 SOP,也可以是有状态图的动态流程。安全场景里不能什么都让 Agent 自由发挥,大量成熟流程应该固化成 Workflow,复杂未知场景再开放一部分动态探索。
还有个关键点:大数据量不能全部丢给模型。能用脚本、规则、查询引擎先处理的,就先处理成结构化结果,再交给模型做综合判断。这样才像工程,不像许愿。
3. 控制与治理平面
这是平台能不能进生产的关键。
这一层至少要有模型网关、策略引擎、权限系统、JIT 凭证、人工审批中心和动作边界。
模型网关决定什么任务用什么模型。实时检测不可能每条日志都上大模型,威胁检测这类场景需要小模型满足毫秒级延迟和高吞吐,大模型更适合复杂研判和交互分析。
权限系统决定 Agent 能看到什么、能调用什么、能不能写动作。安全智能体不应该天然拥有长期高权限。更合理的方式是按任务申请临时权限,用完收回。
Human-in-the-loop 也在这一层。高影响动作,例如封禁核心业务域名、隔离关键服务器、调整防火墙策略,必须有人审批同意,按下确认键。人工审批不是 AI 不先进,而是当前阶段最现实的生产边界。
4. 证据与运维平面
这是最容易在 demo 里被忽略,却最决定成败的一层。
证据不是普通日志。它要记录每一次提示、检索、工具调用、工具返回、模型结论、人工审批、凭证发放、动作执行、结果回写。
安全平台最后一定会遇到追责问题:为什么隔离这台主机?为什么判断这是误报?为什么没有封禁这个 IP?为什么报告里说攻击链已经闭合?
没有证据链,这些问题最后都会变成项目现场的锅。
这一层可能还要包括评测、提示词注入防护、运行监控、工具失败率监控、回滚和审计等。AI 安全运营平台本身也会出问题,所以它也需要被监控和响应。
五、AI安全运营平台内部到底怎么协同
把上面那些概念放到一次真实流程里,会更容易理解。
假设上午 10:23,邮件网关检测到一封发给财务总监的可疑邮件,正文里有一个伪装成 OA 系统的链接。
第一步,数据接入把邮件网关告警规范化,写入事件仓,同时关联收件人、资产、历史邮件和组织上下文。
第二步,Workflow 识别这是“可疑钓鱼邮件”,启动钓鱼研判流程。
第三步,研判 Agent 被激活。它拿到角色和任务:作为邮件安全分析师,判断这封邮件是否为钓鱼,给出威胁等级和处置建议。
第四步,Memory 装载上下文。短期记忆里有当前邮件内容、链接、收件人、时间线。长期记忆通过 RAG 检索过去 90 天针对财务岗的钓鱼模式、历史误报、内部 Playbook。这里要有 ACL,Agent 只能看到它有权看的数据。
第五步,LLM 通过模型网关参与推理。它不直接拍结论,而是先输出需要验证的假设:检查邮件头、跑 URL 沙箱、查域名信誉、比对历史发件人。
第六步,Agent 调用 Skill。这里的“钓鱼研判 Skill”组合多个 Tool:邮件头工具、URL 沙箱、威胁情报查询、历史发件人查询。
第七步,Tool 返回事实结果。比如 SPF/DKIM/DMARC 异常、URL 沙箱出现仿冒登录页、域名注册时间很短、同类链接在外部情报中被标记。
第八步,LLM 基于工具结果二次综合,给出结论和建议:高度可疑,建议隔离邮件、提醒收件人、阻断域名,并对同组织内相似邮件做横向排查。
第九步,Human-in-the-loop 介入。隔离单封邮件可能是低风险动作,可以按白名单策略执行;全网封禁域名属于高影响动作,需要分析师审批。
第十步,执行动作通过 JIT 凭证调用邮件网关或防火墙接口,动作完成后回写结果。
第十一步,Evidence 把前面所有步骤入链。谁触发的流程,Agent 看了什么数据,模型怎么推理,工具返回了什么,谁审批了动作,最后执行结果是什么,都要能回放。
第十二步,Memory 更新。这个案例可以沉淀为新的样本、误报规则或 Playbook,供下次研判复用。

这个流程里,核心组件间的关系可以压成几组:
这里最容易被低估的是 Evidence 和 Human-in-the-loop。
因为 demo 最爱展示 AI 怎么快速分析,最不爱展示它怎么被约束、怎么留证、怎么被人打断、怎么回滚。但真实企业环境里,恰恰是这些不显眼的地方决定能不能上线。
六、判断一个平台是不是“真平台”
判断一个 AI 安全运营平台,不要先问“模型准不准”,先看这四道门有没有做成架构能力。
第一道门:数据门。
它能不能接入真实数据?能不能做字段标准化、权限过滤、脱敏和时序关联?如果只能上传几份文档做问答,不是安全运营平台。
第二道门:工具门。
它能不能调用真实安全工具?Tool 是不是标准化暴露?Skill 能不能复用?动作有没有沙箱、权限、回滚和审批?
第三道门:证据门。
它能不能把每一次推理、检索、工具调用、审批、处置都记录下来?报告里的结论能不能逐条对应证据?如果不能,越智能越危险。
第四道门:人工门。
哪些事情 AI 可以自动做,哪些必须人确认,哪些异常要升级,哪些动作永远不能交给 AI?这个边界不清楚,平台就不该进生产。
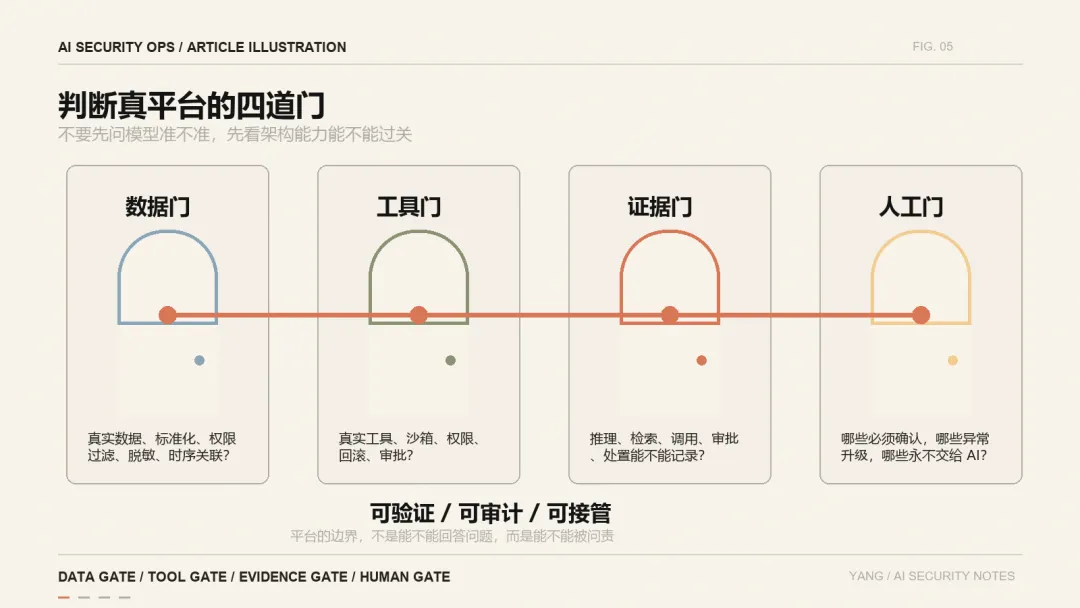
从这个角度看,AI 安全运营平台真正的核心不是“AI 会不会做安全”,而是“AI 能不能在安全工作的责任链里,承担一段可验证、可审计、可接管的流程”。
平台的边界,不是能不能回答问题,而是能不能被问责。
以上是我的一些思考和记录,欢迎拍砖,如果觉得总结的还行,欢迎点赞~转发~加关注!
下一章再继续拆:AI安全运营平台适合哪些业务场景,哪些步骤是固定 Workflow,哪些步骤应该交给 Agent 动态判断。
