 夜雨聆风
夜雨聆风昨天我们讲:
模型不是员工。
今天讲一个你可能经常听到、但很容易误解的词:
Token。
Token 也叫词元。
你不用一上来就学公式。
但你一定要知道它在干什么。
因为很多人用 AI 失败,不是模型不行,而是上来就把一堆材料全丢进去。
会议纪要。
客户反馈。
聊天记录。
产品文档。
自己的想法。
全部塞给 AI,然后问一句:
“帮我总结一下。”
结果 AI 写得很多,看起来也挺像那么回事。
但你仔细一看:
重点没抓住。
旧信息和新信息混在一起。
客户原话和你的猜测分不清。
前面明明说过的要求,后面又忘了。
这篇不讲技术百科。
你只拿走三样东西:
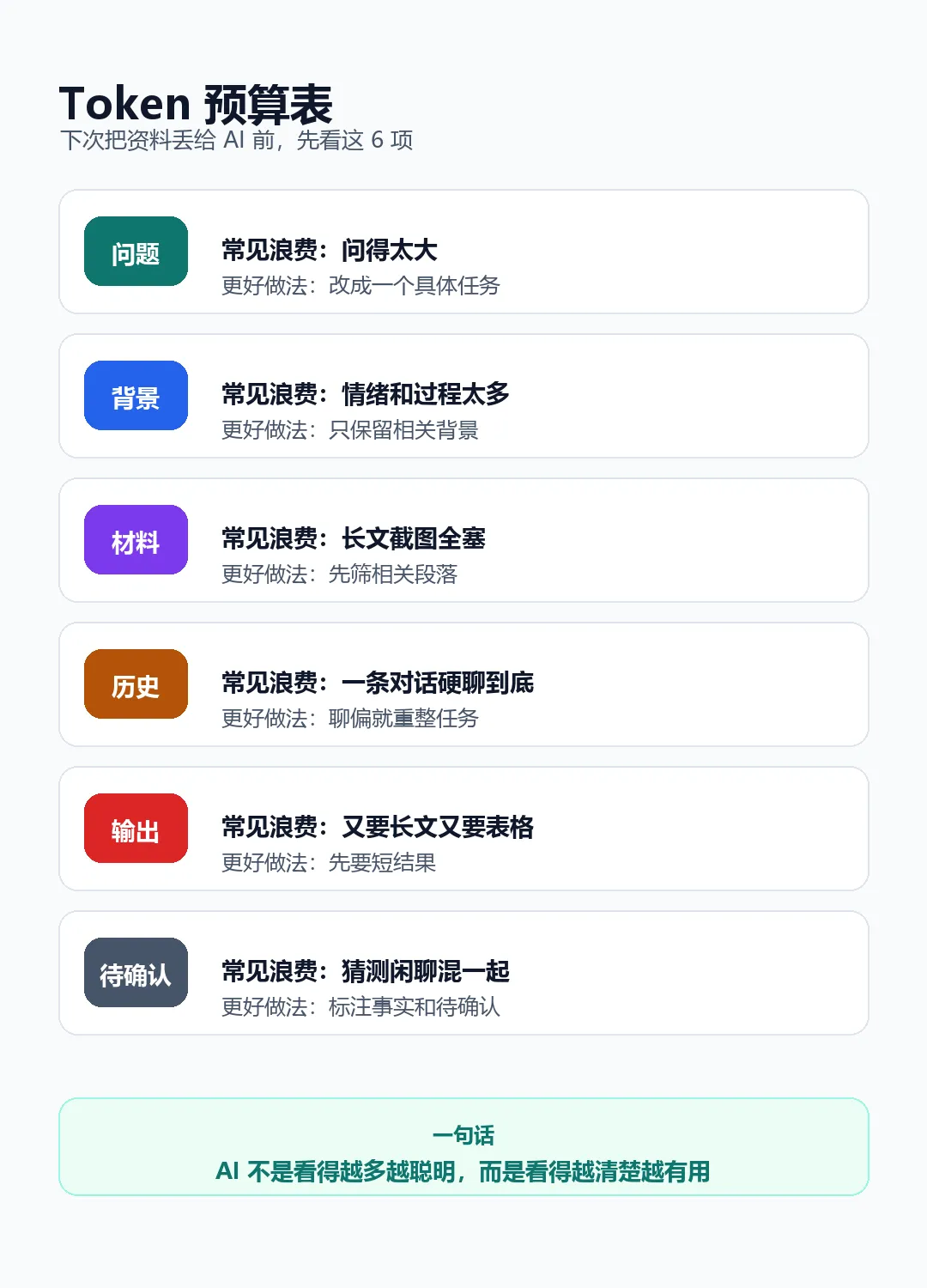
一张 Token 预算表。
一个处理长资料的三步法。
一段可以直接复制的提示词。
先看这张预算表
你可以先把 Token 理解成:
AI 处理信息时花掉的预算单位。
一次 AI 对话里,预算大概会花在这些地方:
你只要记住一句话:
AI 不是看得越多越聪明,而是看得越清楚越有用。
这句话比你记住 Token 的定义更重要。
Token 到底是什么
人读文章,是看字、句子和意思。
模型处理文字,会先把文字拆成更小的信息单位。
这些单位就是 Token,也叫词元。
它可以是一个字、一个词的一部分、一个符号,也可能是一段常见字符组合。
不同模型拆法不完全一样。
所以小白没必要先纠结:
“一个中文到底等于几个 Token?”
你先理解成:
模型每读一点信息、写一点信息,都在花预算。
你的问题会花。
你贴进去的材料会花。
前面的聊天记录会花。
AI 接下来生成的答案也会花。
当预算被无关材料占掉,真正重要的信息就容易被挤掉、冲淡或混在一起。
为什么 AI 聊久了会忘事
你可以把一次对话想成一张临时工作台。
桌面上可以放:
任务目标。
背景材料。
聊天历史。
输出要求。
AI 正在生成的答案。
但桌面不是仓库。
也不是长期记忆。
你聊得越久,桌面上东西越多。
如果不整理,旧要求就可能变模糊。
如果新材料太多,原来的重点就可能被冲淡。
如果中间改了几次方向,AI 也可能分不清你现在到底要什么。
所以你看到的“AI 忘事”,很多时候不是玄学。
而是当前对话里的信息已经乱了。
一个真实场景:让 AI 整理客户反馈
假设你手里有 80 条客户反馈。
你想让 AI 帮你整理出三个东西:
客户最常抱怨的问题。 哪些问题需要马上处理。 哪些只是个别情绪,不要误判。
很多人的问法是:
下面是客户反馈,帮我总结一下。这句话太粗。
AI 可能会给你一份很漂亮的总结。
但它不一定分得清:
哪些是高频问题。
哪些是严重问题。
哪些是单个客户的情绪。
哪些是你自己补充的判断。
更好的做法,是先做信息预算。
三步法:先整理信息,再让 AI 回答
第一步:先定任务
不要问“帮我分析一下”。
先写清楚:
我不是要你写完整报告。 我只要你先判断:这些客户反馈里,哪些问题最值得优先处理。任务越小,预算越集中。
第二步:先清材料
不要把所有东西都当成证据。
先让 AI 把材料分成四类:
这一步很关键。
因为资料多不等于证据清楚。
第三步:再控输出
不要一开始就要长报告。
先要一个短结果:
请先输出 5 个最值得处理的问题,每个问题只写: 问题、依据、影响、下一步。短结果更容易检查。
检查通过,再让 AI 扩写成报告。
这就是会用 Token 的方式:
不是省字数。
而是把预算花在真正有用的信息上。
直接复制这段
下次你要让 AI 读长资料,先不要让它直接写答案。
先复制这段:
我想让你先帮我做信息预算,不要直接给最终答案。 我的任务是: ____ 下面是资料: ____ 请你先把资料整理成 4 类: 1. 事实:资料里明确出现的信息 2. 判断:根据资料推出来的看法 3. 待确认:证据不够、需要我核实的地方 4. 无关内容:对当前任务没有帮助的信息 然后再输出: - 当前最相关的 5 条信息 - 每条信息对应的依据 - 你建议我下一步怎么问 要求: - 不要编造资料里没有的信息 - 不确定就写“待确认” - 不要先写长报告 - 先帮我把材料整理清楚这段提示词的重点,不是让模型变强。
而是先把桌面收干净。
桌面干净了,后面的回答才更稳。

10 分钟小实验
今天就可以试一次。
找一份你最近想让 AI 处理的材料。
可以是:
会议纪要。
客户反馈。
一篇长文章。
一份课程笔记。
先不要问:
“帮我总结。”
先问:
请把这份资料分成: 事实、判断、待确认、无关内容。然后你检查两件事:
它有没有把你的猜测当成事实? 它有没有把无关信息写进重点?
如果这两件事都能检查出来,你就已经开始真正理解 Token 了。
因为你不再把 AI 当成一个无限记忆的盒子。
你开始管理它能看到什么。
常见误区
Token 越多越好吗?
不一定。
更长的上下文能放更多内容。
但更多内容不等于更清楚。
如果资料重复、冲突、过期,放得越多,AI 越容易失焦。
省 Token 是不是少写字?
不是。
真正要省的不是字数,而是无关信息。
一句无关背景,也会污染判断。
一段关键证据,应该保留。
上下文是不是长期记忆?
不是。
上下文更像这一次任务的临时工作台。
长期知识要靠资料整理、知识库、检索、引用和复盘。
这不是单靠一次聊天能解决的。
我需要精确计算 Token 吗?
普通小白暂时不需要。
你先学会一件事:
别把混乱资料直接丢给 AI。
等你要做 API 成本估算、长文档问答、知识库系统,再去学具体计算。
最后
Token 这个词,看起来很技术。
但你可以先把它理解成一笔账:
每次让 AI 干活,都要花信息预算。
你问的问题会花。
你给的资料会花。
聊天历史会花。
AI 输出也会花。
所以小白学 AI,不要只问:
“这个模型能看多少字?”
更应该问:
“我到底该让它看什么?”
AI 不是看得越多越聪明,而是看得越清楚越有用。
如果这篇对你有用,点个在看。
也欢迎留言:你最想让 AI 读哪类长资料?
