 夜雨聆风
夜雨聆风微软研究院论文《LLMs Corrupt Your Documents When You Delegate》揭开普遍隐患:将文档长期、多轮修改工作全权委托给 AI,内容会逐步失真,哪怕是行业头部模型也无法幸免,办公、法务、财务等场景尤其需要警惕。

一、核心测试:DELEGATE-52 全场景压力实验
本次测试覆盖52 类文档形态,包含代码、合同、台账、字幕、乐谱、表格等办公常见文件,模拟职场真实流程:反复修改、合并拆分、多轮迭代、跨版本调整,以此检验模型内容保真能力。
- 整体结果
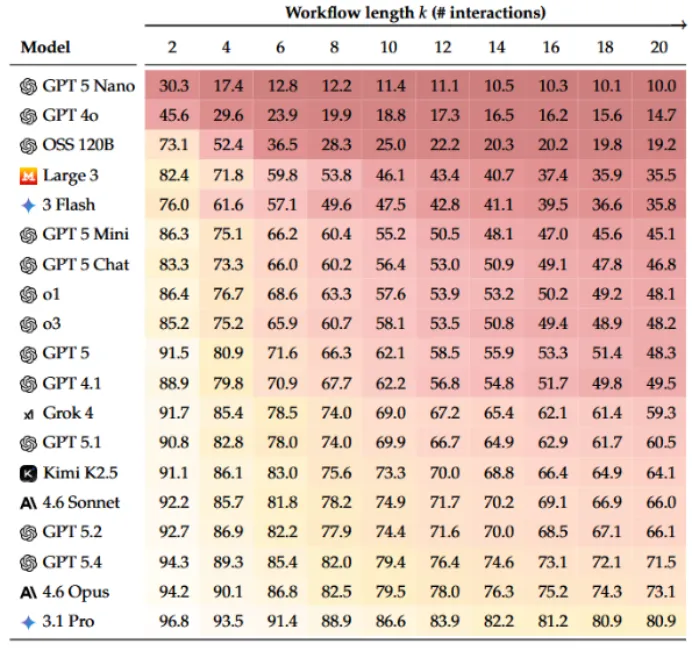
:参与测评的 19 款大模型,经过 20 轮交互后全部出现内容退化,平均保真度折损近半。 - 头部模型表现
:GPT 5.4、Claude 4.6 Opus、Gemini 3.1 Pro 等顶尖模型,20 轮迭代后内容损坏比例约25%,保真度分别跌至 71.5%、73.1%、80.9%。 - 出错特征
隐性篡改为主:无乱码、无大面积删改,句式、行文逻辑依旧流畅,仅悄悄改动关键词、限定条件、逻辑关系,肉眼通读极难识别。例如 “验收后付款” 改为 “交付后付款”、“建议” 改为 “决定”、“可能” 改为 “将会”。 突发式失误居多:并非逐轮小幅偏差,常在某一轮突然篡改核心条款、切断逻辑链,单次失误就大幅拉低内容质量。 越迭代越失真:交互次数拉至 100 轮,内容保真度持续下滑,模型不会自主修正问题。 
二、五大高风险规律,贴合日常办公场景
1. 场景分化:代码相对安全,非结构化文档高危
代码是唯一达标领域,语法规则、运行测试可快速排查错误;合同、协议、方案、纪要、规章制度等文本类文档风险最高,错误不影响阅读,却会改变核心权责、时间、金额等关键信息。
2. 叠加插件 / 工具,无法根治失真问题
为 AI 加装技能插件、扩展工具后,多步骤操作、跨功能切换反而增加出错节点。模型仍习惯大面积重写内容,而非精准修改指定片段,和 “让同事改一行文字,对方却全盘重构” 的问题如出一辙。
3. 文档越长,篡改概率越高
短文档(单页通知、简短说明)出错概率低;几十页长合同、多章节方案、海量数据表格,上下文复杂度飙升,模型极易遗漏细节、混淆条款,长文档是重灾区。
4. 附带参考资料,容易造成内容混杂
同时投喂主文档 + 旧版本、会议纪要、附属文件、截图备注等资料,模型会混淆有效信息与参考内容,出现条款错乱、内容拼接错误。
5. 短期表现具有迷惑性
前 1-2 轮修改,顶尖模型保真度可达 94%-97%,体验良好,容易让人放松警惕;随着迭代轮次增加,隐性错误不断累积,最终形成批量问题。

三、本质总结:AI 适合 “起草提速”,不适合 “全权托管”
当下大模型的能力边界清晰:✅ 优势:空白文档起草、初稿润色、格式统一、内容梳理、初稿提速;❌ 短板:无法胜任多轮迭代、持续修改、精准微调、高权责文档长期维护。AI 可以做办公 “辅助员”,但绝不能成为文档全流程 “负责人”,最终责任仍由使用者承担。
四、5 条落地实用规则,规避篡改风险
1. 拆分任务,拒绝整包托管
不将完整文档、全量修改需求一次性交给 AI。按章节、段落、功能拆分任务,每次仅限定小范围修改,问题更容易及时发现。
2. 优先查看改动痕迹,而非直接通读成品
使用支持内容对比(Diff) 的工具,聚焦具体修改片段。通篇阅读容易被流畅的行文误导,逐行核对改动点,可快速揪出隐性篡改。
3. 重点字段人工逐项复核
重点核查金额、日期、付款节点、权责条款、人名、地名、版本号、例外约定、生效条件等核心敏感信息,这类内容是 AI 篡改重灾区。
4. 长文档增设检查节点
页数多、条款复杂的文件,每完成一轮修改就做一次全量校验,不要等到多轮迭代结束再统一检查,避免错误层层叠加。
5. 区分任务类型,理性分配工作
可放心交给 AI:格式转换、排版、基础摘要、固定模板填充、有明确校验标准的结构化工作; 谨慎使用 AI:合同修订、商务条款调整、制度改写、法律文书、权责界定类内容,必须以人工审核为主。
结尾
AI 大幅提升了文档处理效率,但流畅的文字不等于准确的内容。尤其在商务、法务、财务等对严谨性要求极高的场景,始终守住 “人工终审” 底线。效率工具可以借力,核心责任不能转嫁。
