 夜雨聆风
夜雨聆风AI智能体如何实现“技能”自我进化?MemTensor提出百万级技能库全生命周期治理框架SkillsVote
AI前沿 | 顶会论文解读
论文标题:SkillsVote: Lifecycle Governance of Agent Skills from Collection, Recommendation to Evolution
作者团队:Hongyi Liu, Haoyan Yang, Tao Jiang, Bo Tang, Feiyu Xiong, Zhiyu Li (MemTensor/记忆体科技)
发表会议:arXiv Preprint 2024
核心结论:提出了首个针对大模型Agent技能(Skills)的全生命周期治理框架,通过推荐、归因与受控演化,在不更新模型权重的情况下,使得GPT-5.2在Terminal-Bench和SWE-Bench Pro上分别实现高达7.9和2.6个百分点的显著性能提升。
📄 论文摘要
随着大语言模型(LLM)智能体在复杂长周期任务中的应用越来越广泛,它们在执行任务时留下的轨迹(Trajectories)本应成为可复用的宝贵经验。然而,原始的执行轨迹通常冗长、充满噪声且高度绑定特定环境,极难直接管理和复用。虽然将经验封装为结构化的“智能体技能(Agent Skills)”是解决之道,但在海量开源生态中,技能往往存在冗余、质量参差不齐等问题,盲目更新技能库甚至会“污染”智能体未来的上下文。
为了解决这一痛点,MemTensor团队提出了SkillsVote——一个从收集、推荐到自我演化的智能体技能全生命周期治理框架。该框架首先对百万级开源技能语料库进行环境和质量画像;在任务执行前,通过Agentic机制进行精准技能推荐;在任务执行后,创新性地将轨迹拆解为子任务(Subtasks)进行精细化归因,确保只有真正成功且具备复用价值的探索才能被“投票”准入技能库。这种机制成功赋予了冻结参数的大模型强大的自我学习与经验沉淀能力。
🏗️ 总架构设计
SkillsVote的系统架构设计将Agent技能视为一种需要严格治理的生态系统资产,构建了一个完整的“推荐-执行-归因-演化”闭环系统。整个生命周期包含以下四个核心阶段:
1. 百万级语料收集与画像 (Profiling):系统从GitHub等平台收集海量包含 `SKILL.md` 的技能包,并从运行环境需求、内容质量和可验证性三个维度为其生成画像,剔除无效的噪声数据。
2. 任务前智能推荐 (Pre-task Recommendation):Agent不直接解决任务,而是先在结构化的技能库中进行“Agentic Search(智能体搜索)”,不仅筛选出低冗余的相关技能,还为下游Solver Agent生成精简的组合使用指南。
3. 任务后精细归因 (Post-task Attribution):这是框架的中枢神经。将长轨迹拆解为语义完整的子任务(Subtasks),明确每一个成功或失败是因为技能指导、自主探索、环境问题还是结果信号导致。
4. 受控的技能演化 (Controlled Evolution):基于归因证据设立“门禁”。只有那些归因为成功且具备复用价值的探索,才会被打包成“证据组”,进而触发对现有技能的编辑(Edit)或创建全新技能(Create)。
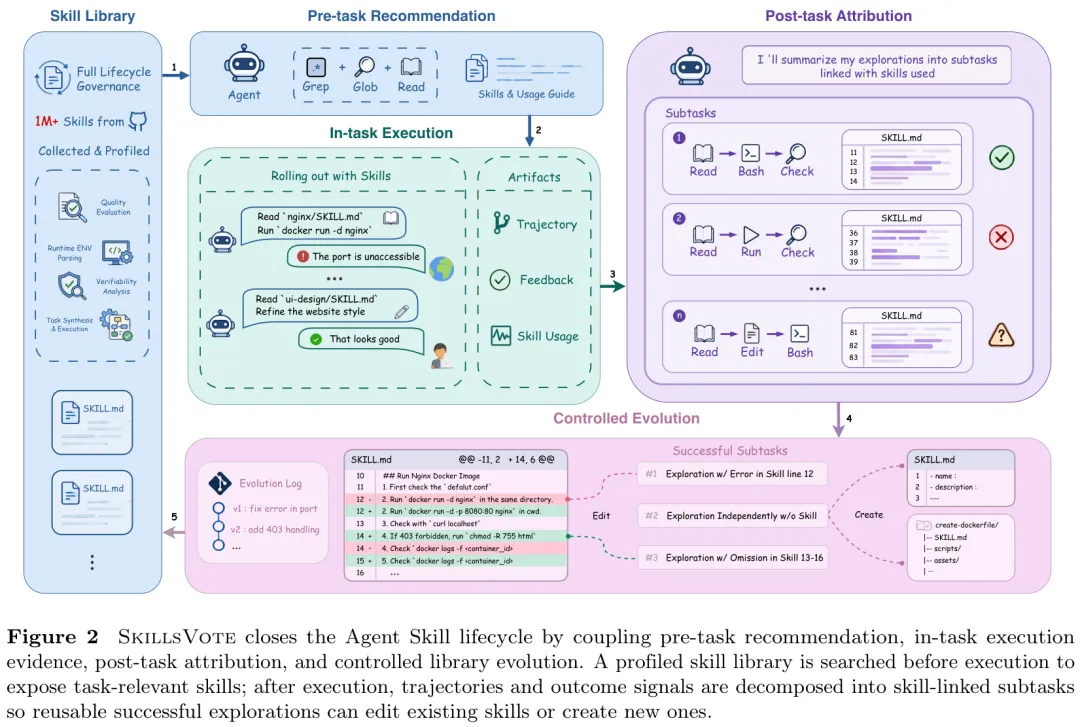
图1:SkillsVote闭环架构:耦合了任务前推荐、任务中执行、任务后归因以及受控库演化
💡 核心创新点
▪ Agentic智能库搜索推荐:突破了传统RAG(检索增强生成)静态语义匹配的局限。SkillsVote允许Agent利用工具主动与本地文件系统中的技能库交互、阅读技能文档,从而在复杂生态中动态过滤出不仅相关且环境兼容、能力互补的技能子集。
▪ 子任务级别 (Subtask-level) 信用分配:以往的研究要么使用过于宏观的任务级成功信号,要么使用过于细碎的步骤级(Step-level)反馈。SkillsVote引入了“Subtask”作为演化单元,精准隔离了技能引导的正确操作与偶然探索,有效解决了长视野任务中的信用分配(Credit Assignment)难题。
▪ 基于证据的受控演化机制:技能生态库的膨胀是一把双刃剑。SkillsVote实现了极其克制的演化逻辑:更新操作必须满足可采纳性(成功且可复用)、聚合性(同类经验合并)和正确路由(修改现有边界还是新建)三大门槛,彻底杜绝了无效失败经验污染技能库的风险。
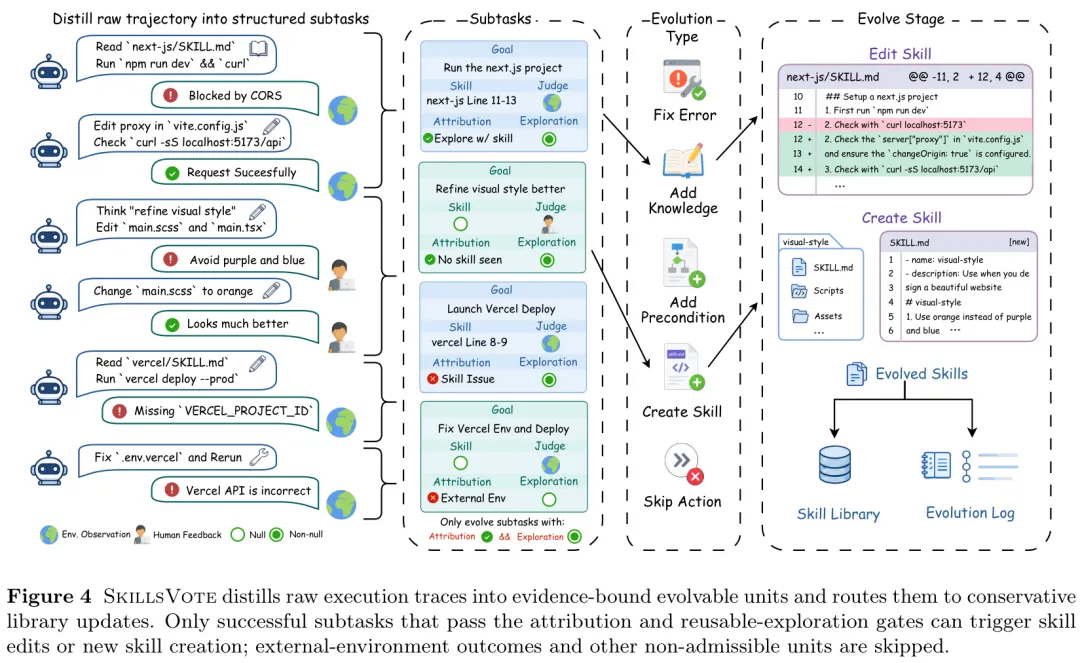
图2:从原始轨迹到受控技能演化的详细拆解(提取Subtasks并做归因过滤)
🔬 关键方法与实验结果
研究团队在极具挑战性的软件工程基准(SWE-Bench Pro)和终端操作基准(Terminal-Bench 2.0)上进行了全面的评测。实验设立了三种模式:无技能基线(No-skill Baseline)、从零开始的在线演化(Online Evolution)以及基于历史任务提炼的离线库迁移(Offline Evolution)。
在终端环境任务中(见下表),Offline演化展现了惊人的跨任务泛化能力。通过将旧任务蒸馏出的技能库迁移至未见过的测试任务,GPT-5.2 的整体准确率从51.0%大幅提升至58.9% (+7.9 pp),其中中等难度任务更是获得了 +10.2 pp 的提升。这充分证明了轨迹衍生出的技能并非只是机械地记住了答案,而是真正提炼出了可迁移的程序化先验知识。
| 模型与配置设置 | 整体准确率 (Overall) | 简单难度 (Easy) | 中等难度 (Medium) | 困难难度 (Hard) |
|---|---|---|---|---|
| GPT-5.2 无技能基线 | 51.0% | 75.0% | 54.9% | 40.7% |
| GPT-5.2 离线演化 (Offline) | 58.9% (↑7.9) | 90.0% (↑15.0) | 65.1% (↑10.2) | 43.3% (↑2.7) |
| GPT-5.4 mini 无技能基线 | 51.7% | 75.0% | 61.8% | 30.0% |
| GPT-5.4 mini 离线演化 | 57.5% (↑5.8) | 65.0% (↓10.0) | 64.7% (↑2.9) | 43.3% (↑13.3) |
此外,在推荐消融实验中发现,如果不做“智能推荐”而直接向Agent全量暴露在线技能库,不仅没有收益反而会导致平均性能下降。这证明了在庞大的技能库面前,精准的暴露控制 (Exposure Control) 与过滤机制是避免大模型产生幻觉和负迁移的关键。
🚀 应用价值与展望
在AI迈向更高阶自主运行(Autonomous Agent)的今天,基于模型权重微调的经验学习成本高昂且容易发生灾难性遗忘。SkillsVote证明了一套受严格治理的外部文件化技能系统,可以作为Agent积累长期经验的最佳基座载体。它为企业级Agent的落地提供了一条新思路:无需频繁进行昂贵的微调,通过搭建规范的技能库生态并辅以系统化的治理,即可让冻结参数的大模型在部署中实现“自我学习与进化”。 未来,这种框架有望促成一个高质量、可插拔的“大模型技能应用商店”的成熟生态。
📚 论文原文:arXiv:2605.18401 (预估链接)
💻 相关资源:https://github.com/MemTensor/skills-vote
🎯 核心亮点:首次提出百万级Agent技能库的全生命周期治理;独创子任务级归因过滤噪声;冻结大模型参数即可实现显著自我进化。
⭐ 觉得文章有用?欢迎分享给更多朋友! 💡 关注公众号,获取更多顶会论文深度分析 🔥 每日精选AI论文,解读最新技术进展
