 夜雨聆风
夜雨聆风AI自动化审计-调用链分析
调用链追踪目前是ai自动化审计面临的一个很大的痛点,当我们的调用链sink数很多时,由于模型的上下文能力的限制,ai去追踪sink到source的这个过程很容易出现幻觉或者丢失,一旦处理不好就会出现大量token消耗后审计的结果还不尽人意的情况,为了解决这些问题,我做了以下的一些尝试,总结了一下思路和方法论。
codeql引发的思考
其实关于追踪调用这点,我刚开始立马想到的就是codeql和tabby这类自动化的审计工具,在ai还没兴起的时候,这两个自动化工具可以说是非常的火热的,他们能够实现从sink到source的精准查找,我最开始的想的思路框架就是,写一个py脚本去调用一个yaml文件,然后yaml文件里面就放大量的危险sink关键字,然后通过py脚本去把代码中的sink点挖掘出来,然后我们把找追踪调用链这个过程交给codeql和tabby这种工具去做,然后ai只负责去对输出的调用链结果做一个验证判断,判断是否为真实漏洞,这个过程ai只负责验证的模块,而且codeql这类工具基于不断的更新迭代情况下找调用链的能力也是非常强悍了,sink点的规则就算交给ai去做他也是去对一些危险函数方法进行grep和search的操作匹配,也是可以直接交给工具的,这样的话不仅能够降低token的消耗还能够提升审计的速率,也能一定程度上保证最终的审计效果,但是在实际测试中还是面临了一些问题,接下来我们对着codeql他在实际审计过程中的工作流程进行分析。
codeql的工作流
codeql他在审计的过程中会把整个项目(Java+class)解析、编译、提取成关系数据库,里面有:
AST/PSI(语法树)
调用图(Call Graph)
控制流图 CFG
数据流图 DFG / 污点传播图
然后用 QL(类似 SQL) 在数据库里查链、查路径、查可达性。
举个例子,假设我们项目中存在两个类
User.java // 有 getName()
UserService.java // main 里 new User + getName()
CodeQL 会劫持编译过程(javac),拿到:
源码 AST - 编译后的类型信息、泛型、继承、重载解析结果
class 文件 / 依赖 jar 的字节码也会被解析、反编译、并入同一套模型
对这两个类,会生成:
表:
Class、Method、Field、Call、Type、Override、…每条记录是一个 “节点”,关系是 “边”:
Call(调用点) → Method(被调用方法)Method → ClassClass → SuperClass
构建调用图(Call Graph)—— 这是调用链的基础
CodeQL 会做静态解析 + 类型推导 + 多态解析:
静态调用: new User().getName()→ 直接绑定到User.getName()多态调用: User u = new AdminUser(); u.getName()→ 能解析到所有重写的方法(AdminUser.getName、User.getName)CodeQL
最终在数据库里形成一张全局调用图(示例节点 / 边):
节点:
UserService.main(String[])
User.User(String, int)
User.getName()
边(调用关系):
UserService.main → User.构造方法
UserService.main → User.getName()
那怎么用 QL 查询调用链呢(举个可运行的例子)
想查:谁调用了 User.getName ()?调用链是什么?
CodeQL 的 QL 查询大概长这样(简化):
import java
from Method getName, Call call, Method caller
where
getName.hasQualifiedName("com.demo.User", "getName")
and call.getTarget() = getName // 调用的目标是 getName
and call.getCaller() = caller // 调用所在方法
select caller, call, getName
污点链 / 数据流链(安全审计核心)
比普通调用链更强:跟踪 “数据从哪来、到哪去、经过哪些方法”。
示例:用户可控参数 → 拼接 SQL → 执行(SQL 注入链)
// 源(Source):用户输入
String id = request.getParameter("id");
// 中间传递
String sql = "select * from users where id='" + id + "'";
// 汇(Sink):危险方法
stmt.executeQuery(sql);
CodeQL 会在数据流图上找从 Source 到 Sink 的所有可达路径,输出完整链:
request.getParameter("id")
→ UserService.getIdFromRequest
→ UserService.buildSql
→ Statement.executeQuery
这就是codeql自动化审计找漏洞链的原理。
面临的问题
我们刚刚提到过CodeQL 会劫持编译过程(javac),也就是说他是在编译代码的过程中提取信息的,也就是说你能用 javac /mvn compile /gradle compile 编译成功,CodeQL 才能跑。
那要是出现缺少依赖包(最常见),语法错误(哪怕一个分号漏了)都会编译失败,也就不能跑,但是实际案例中我们并没有那么多结构完整的代码,所以这个过程并不适用绝大部分情况。
并且,现在claude模型出来之后,我对ai模型的能力是保持着深度信任的态度,我个人认为,在codeql的这个过程中,codeql他其实构建好调用链后,通过ql去进行调用链的查询,其实是在数据库里面进行关系查询的,我认为这个过程其实也是有些类似于正则匹配,纯静态的,如果这一个过程,能够交给ai去做,写成一个专门的skills,ai其实能够做的更好
所以接下来我们要解决的问题就是以下两点,一个是如何在代码不规范的前提下尽可能构建出精准度较高的语义解析树,还有就是写一个能够基于语义解析树高效的追踪调用链工作流的skills
调用链追踪分析
首先是语义解析树的构建,往往ai在审计的过程中其实也是很简单粗暴的,在追踪调用链,从a的危险方法,到b的函数引用,再到http接口c的输入,ai其实也是去不断地进行grep这种筛选操作去找调用关系,而且这个过程中往往是需要跨多个class类的,如果项目结构比较复杂,代码量庞大,受制于上下文结构原因,就会造成注意力不集中,调用链缺失的情况。像微服务的java代码就是一个很好的案例。面对几千个class,上万个方法,ai在后面的的调用链出现了明显的注意力不集中,也就是偷懒。
面对这些问题,我第一个想到的是idea
idea的语义解析树
首先我们先来看看什么是语义解析树,他是源代码经过词法分析和语法分析后生成的结构化树形表示,它舍弃了代码的文本格式(如空格、分号、注释),只保留语法结构和语义关系,简而言之就是把代码中一个class他的方法,函数,包名,具体实现,等涉及到多层调用的这些参数给提取出来构建成一个树形结构,我在这里举个例子idea为什么能够实现ctrl加点击就能够找到java代码中这个方法的具体实现,为什么右键点击能够查看这个类被哪些类进行了引用,为什么可以直接查看这个抽线接口被哪些类进行了重写,就是因为它在后台做了两件事:全项目静态解析 + 建立符号索引图,之后所有跳转与查找都是在索引里查,而不是临时全文搜索。
<!--IDEA 代码跳转 & 调用查找 简化流程图-->
st=>start: 1. 导入Java项目
op1=>operation: 2. 配置JDK/Maven/Gradle
op2=>operation: 3. 全量扫描
sub1=>subroutine: 扫描范围
|-- 项目源码(.java)
|-- 依赖jar包(.class)
|-- JDK核心类库
op3=>operation: 4. 构建语法结构模型
sub2=>subroutine: 核心产出
|-- AST(抽象语法树)
|-- PSI(程序结构接口)
op4=>operation: 5. 建立全局索引
sub3=>subroutine: 索引类型
|-- 符号索引(类/方法/字段→位置)
|-- 引用索引(谁调用了谁)
cond1=>condition: 触发操作?
op5=>operation: 6.1 Ctrl+点击符号
op6=>operation: 6.2 Alt+F7查找调用
op7=>operation: 7.1 索引中查询符号定义位置
op8=>operation: 7.2 反向遍历引用关系图
e1=>end: 8.1 跳转到符号定义行
e2=>end: 8.2 展示所有调用点列表
st->op1->op2->sub1->op3->sub2->op4->sub3->cond1
cond1(yes, right)->op5->op7->e1
cond1(no, left)->op6->op8->e2
下面举个实际案例
假设项目里有两个文件,结构如下:
src/main/java/
├─ com/demo/
│ ├─ User.java // 定义 User 类
│ └─ UserService.java// 调用 User 类
User.java(类定义文件)
package com.demo;
public class User {
private String name;
private int age;
public User(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return this.name;
}
}
UserService.java(类调用文件)
package com.demo;
public class UserService {
public static void main(String[] args) {
User user = new User("张三", 25); // 调用 User 构造方法
String userName = user.getName(); // 调用 User.getName() 方法
System.out.println(userName);
}
}
当你把这个项目导入 IDEA 并配置好 JDK 后,IDEA 会执行以下步骤:
步骤 1:扫描文件,做语法分析生成 AST
对每个 .java 文件,IDEA 会先做词法分析(拆分关键字、标识符、字面量),再做语法分析生成 AST(抽象语法树)。对User.java,AST 结构大概是:
CompilationUnit → PackageDeclaration(com.demo) → ClassDeclaration(User) → FieldDeclaration(name/age) → ConstructorDeclaration → MethodDeclaration(getName)
对 UserService.java,AST 结构大概是:
CompilationUnit → PackageDeclaration(com.demo) → ClassDeclaration(UserService) → MethodDeclaration(main) → VariableDeclaration(user) → MethodInvocation(getName)
步骤 2:基于 AST 构建 PSI(程序结构接口)
PSI 是 IDEA 对代码的结构化内存模型,它不是文本,而是能识别 “语义” 的对象树。
以 User 类为例,IDEA 会生成这些 PSI 节点对象:
PsiClass | public class User | |
PsiField | private String name | |
PsiMethod | public String getName() |
同理,UserService 的 main 方法里,new User(...) 会生成 PsiNewExpression 节点,user.getName() 会生成 PsiMethodCallExpression 节点。
步骤 3:建立符号索引和引用关系索引
这是实现 Ctrl + 点击的核心步骤,IDEA 会抽离所有 “符号” 并建立映射关系。
符号索引(正向映射:符号 → 定义位置)
IDEA 会生成一张全局符号表,关键条目如下:
com.demo.User | |
com.demo.User#getName() | |
com.demo.UserService |
引用关系索引(反向映射:定义 → 被谁引用)
IDEA 会分析所有 “谁用了谁”,生成引用关系图,关键条目如下:
com.demo.User | new User(...) | |
com.demo.User#getName() | user.getName() |
现在我们看用户操作时,IDEA 是如何利用索引工作的。
场景 1:Ctrl + 点击 UserService 里的 User 类
操作:在 User user = new User(...); 中,Ctrl + 点击 User
IDEA 识别鼠标位置的符号是 User,并通过上下文(包com.demo)确定完整限定名com.demo.User;查符号索引,找到 com.demo.User对应的定义位置:User.java第 3 行;直接跳转到该位置,展示 public class User代码。
场景 2:Ctrl + 点击 user.getName() 里的 getName
操作:在 user.getName() 中,Ctrl + 点击 getName
IDEA 识别这是方法调用,先通过 user变量的类型(User),确定归属类com.demo.User;查符号索引,找到 com.demo.User#getName()对应的定义位置:User.java第 10 行;跳转到 public String getName()方法。
场景 3:Alt+F7 查找 User.getName() 的所有调用
操作:在 User.java 的 getName 方法上,按 Alt+F7
IDEA 查引用关系索引,找到所有引用 com.demo.User#getName()的位置;展示结果: UserService.java第 7 行user.getName();点击结果即可跳转到调用处。
所以通过这里我们可以知道idea他是通过构建语法解析树,将一套复杂冗余的代码,给变得清晰明了,那我们能不能也通过这种方式,写一个脚本,去将一套几百mb的代码,也解析成ast的语法树,然后输出成一个几十mb的json文件,然后让ai去围绕这个几十mb的文件去做代码分析呢,这样相比较阅读几百mb的代码,阅读几十mb提取出来的结构化文件,去找调用链就会显得更加的轻松精准,也节省了大量的token消耗
实际测试效果
针对于之前的分析,我后面去查看了大量类似的ast解析工具,像 JavaParser,Spoon,ANTLR,Tree-sitter等这一系列的工具,过程还是非常的曲折的,中途遇到了非常多的问题,实际测试下来感觉效果最好的就是idea自带的java-psi-impl.jar和Eclipse的jdt.core.jar,下面就举出几个来聊聊
首先是利用上面的工具在做一些解析代码测试的时候,面对一些抽象类,或者像一些接口,以及一些注解的提取是不够完整的,往往会出现缺失的情况,他们只会去做语法解析,不做 符号解析、作用域、继承、类型绑定
比如下面的代码
package com.demo;
import org.springframework.stereotype.Service;
import org.springframework.web.bind.annotation.GetMapping;
@Service
public abstract class UserService implements BaseService {
@GetMapping("/list")
public abstract List<User> listUsers();
@Override
public void init() {
}
}
像上面提到的工具去做提取
JavaParser 解析结果:
类名: UserService
是抽象类: true
实现的接口名字: [BaseService] <-- 只有名字,不知道在哪
类上注解:
- @Service <-- 只有名字,不知道包名
方法: listUsers
修饰符: public abstract
返回值字符串: List<User> <-- 只是字符串,不是真实类型
方法注解:
- @GetMapping <-- 只有名字,无包、无属性
方法: init
注解:
- @Override <-- 只知道有这个注解,不知道是否真的重写
不知道 @Service 是 org.springframework.stereotype.Service ,不知道 BaseService 是哪个包, 不知道 listUsers() 来自接口,不知道 init() 重写了哪个方法,List 只是文本,不是类型结构
Tree-Sitter 解析结果:
类定义: UserService
修饰符: abstract, public
父级节点: implements BaseService <-- 纯文本
注解节点: @Service <-- 纯字符串,无包信息
方法定义: listUsers
修饰符: abstract
注解节点: @GetMapping("/list") <-- 纯字符串
返回值节点: List<User> <-- 纯字符串
方法定义: init
注解节点: @Override <-- 纯字符串
不知道注解属于哪个包,不知道接口在哪,不知道方法是否重写, 不知道泛型类型,不知道类的继承结构,无法跨文件解析
Eclipse JDT 解析结果:
全类名: com.demo.UserService
类型: 抽象类
实现接口: com.demo.BaseService <-- 全类名绑定
类注解:
- @Service 来自包: org.springframework.stereotype.Service
方法: listUsers()
修饰符: public abstract
返回类型: java.util.List<com.demo.User> <-- 真实泛型类型
注解: @GetMapping 来自: org.springframework.web.bind.annotation.GetMapping
来源接口方法: com.demo.BaseService.listUsers()
方法: init()
注解: @Override
重写自方法: com.demo.BaseService.init() <-- 真实绑定
java-psi-impl.jar解析结果:
\=== PsiJavaFile 解析结果 ===
文件名:UserService.java
语言:Java
包声明:com.demo
导入列表:
1. import org.springframework.web.bind.annotation.GetMapping;
2. import org.springframework.stereotype.Service;
类:PsiClass
全类名:com.demo.UserService
修饰符:public abstract
类型:Java 类(不是接口、不是枚举)
父类:java.lang.Object(默认)
实现接口:
→ BaseService(解析为:com.demo.BaseService)
类注解:
1. @Service
- 注解全类名:org.springframework.stereotype.Service
- 属性:无
--------------------------------------------------
字段:无
--------------------------------------------------
方法 1:listUsers()
修饰符:public abstract
返回类型:java.util.List<com.demo.User> 【泛型已解析】
参数:无
抛出异常:无
方法注解:
1. @GetMapping
- 注解全类名:org.springframework.web.bind.annotation.GetMapping
- 属性 value = "/list"
方法来源:
→ 实现/重写自:com.demo.BaseService.listUsers()
--------------------------------------------------
方法 2:init()
修饰符:public
返回类型:void
参数:无
方法注解:
1. @Override
- 注解全类名:java.lang.Override
方法来源:
→ 重写自:com.demo.BaseService.init()
--------------------------------------------------
可以很明显的看出来java-psi-impl.jar和jdt.core.jar是能够完全解析整个项目结构的
第二个问题就是解析后输出的文件太大,最夸张的一次一个一百兆的代码给我输出了两个g的解析文件。。。。。。
但是经过不断的对比改进优化,将那几个ast解析的工具都提取出规则喂给ai,最终目前还是更新了一般比较稳定的ast解析工具
工具实测解析情况如下,面对一套大代码,8000+类25000+方法解析出来效果如图
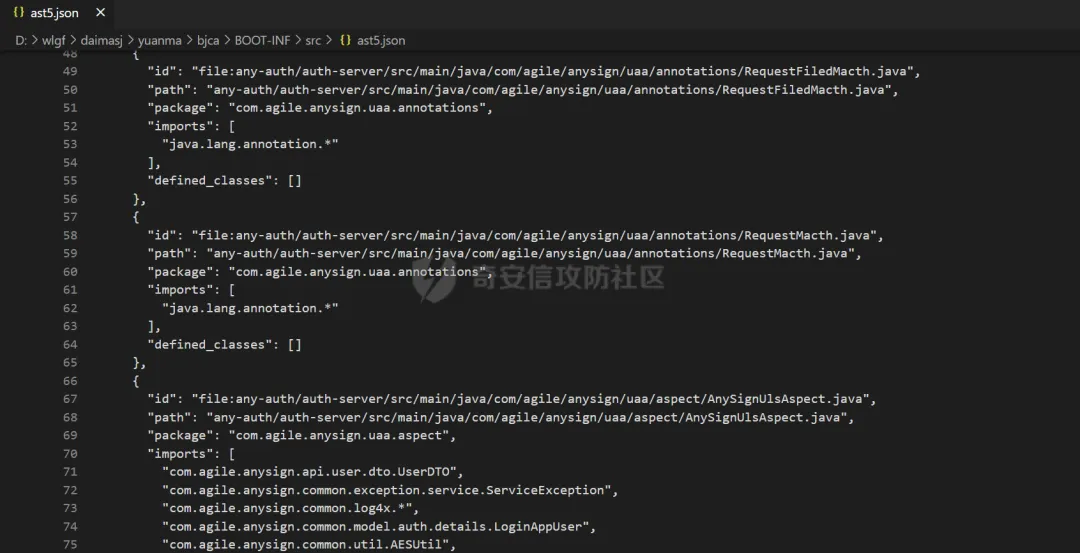
我们这里就简单做个测试,让ai去追踪代码中FileZipUtil.handlerFile这个方法的调用链。先让ai读一下怎么去通过ast.json去追踪调用链。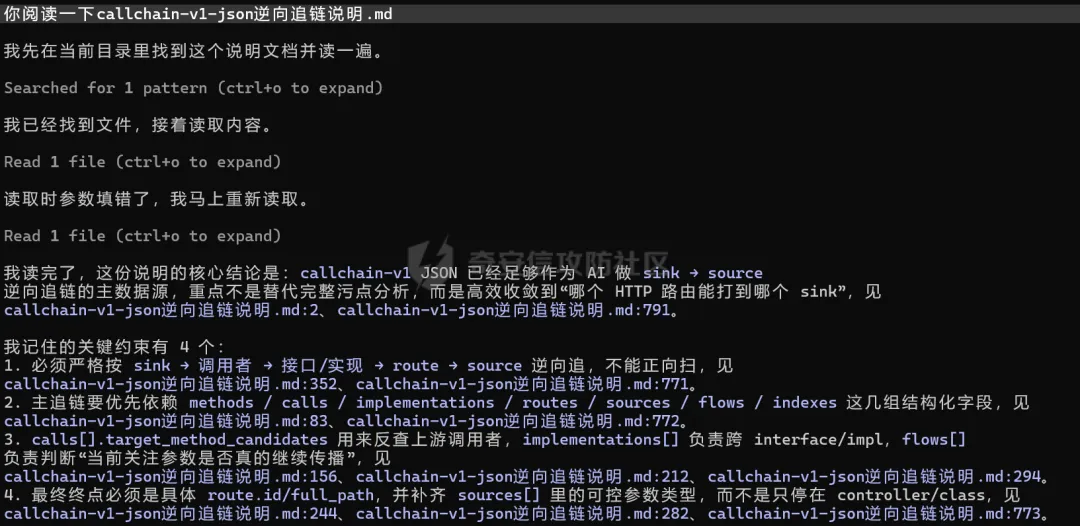
然后开始追踪调用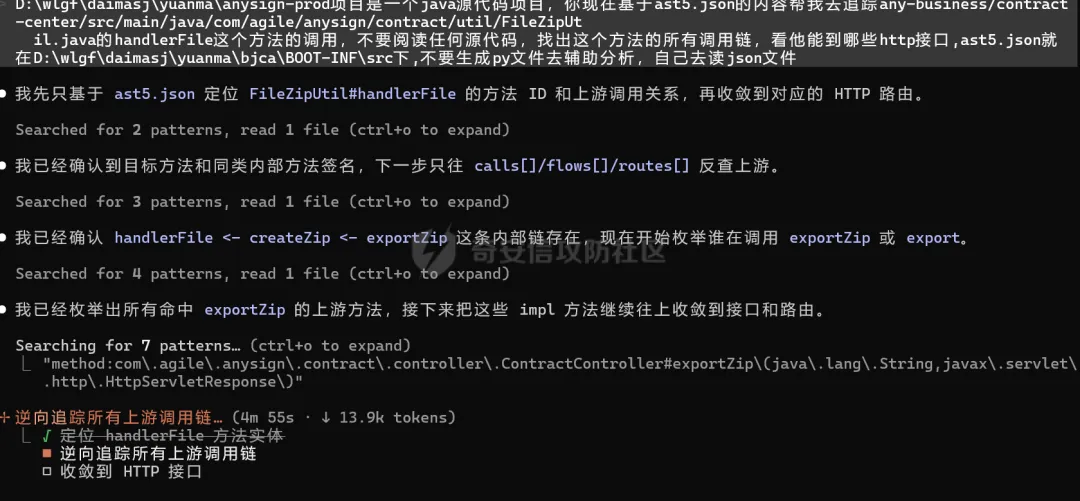
最终结果如下,ai在没有进行代码阅读的情况下,单纯就靠输出的astjson,完整的找出了10条调用链!八个可抵达路由,与人工复核结果一致!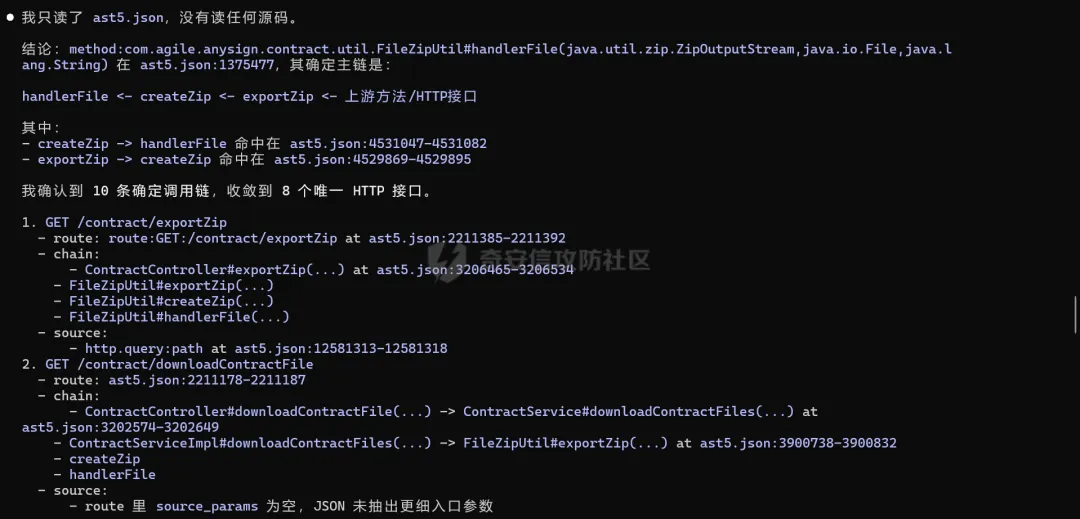
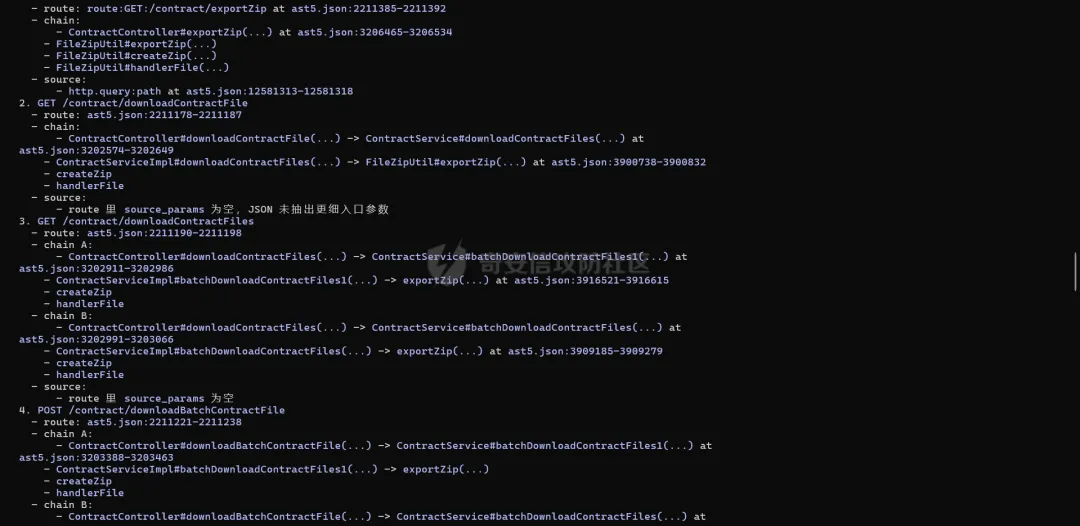
消耗时间大概是在八分钟左右,对于十条调用链的追踪,而且目前结果是没有去写个专门的skill让ai去进行追踪调用链,只是单独阅读了临时写的一个说明文档,如果在适配skill之后,花费的时间只会更短!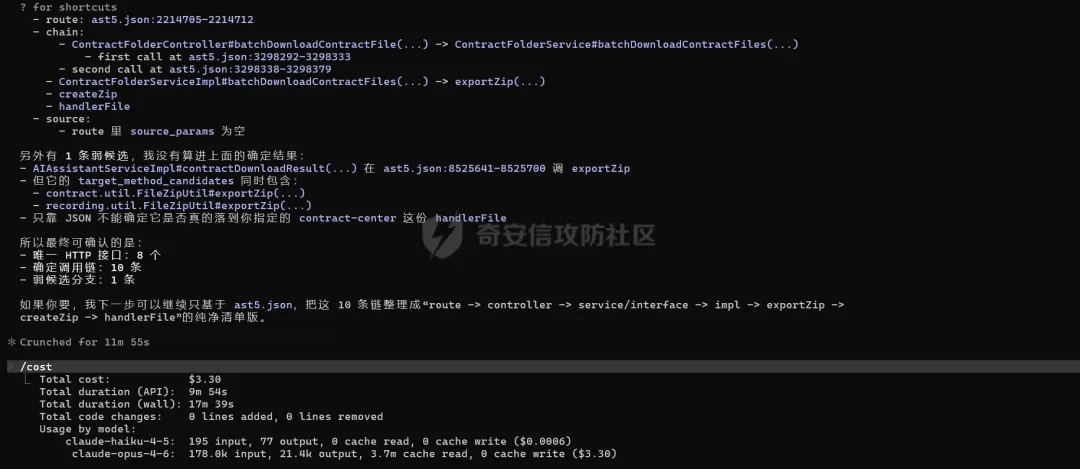
看看ai对json的评价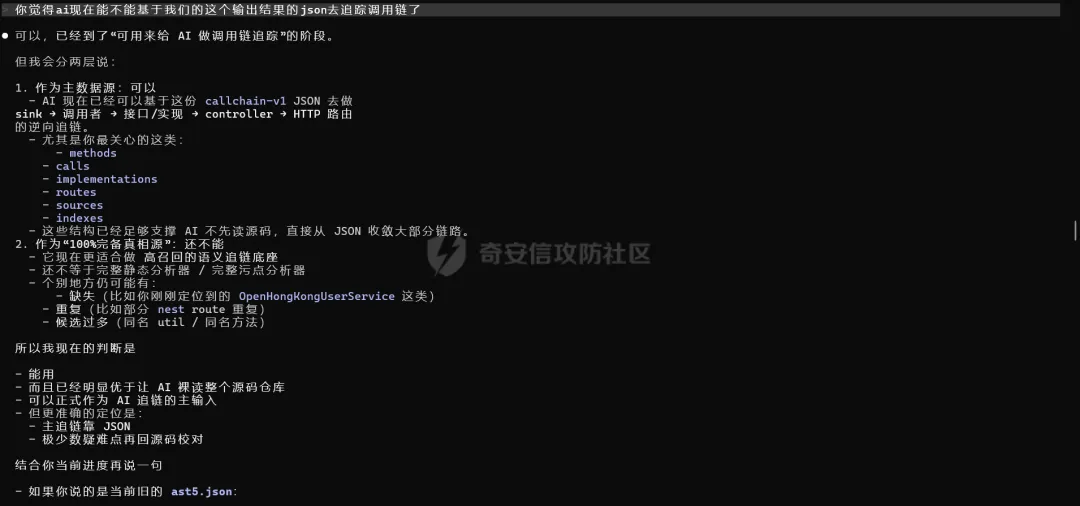
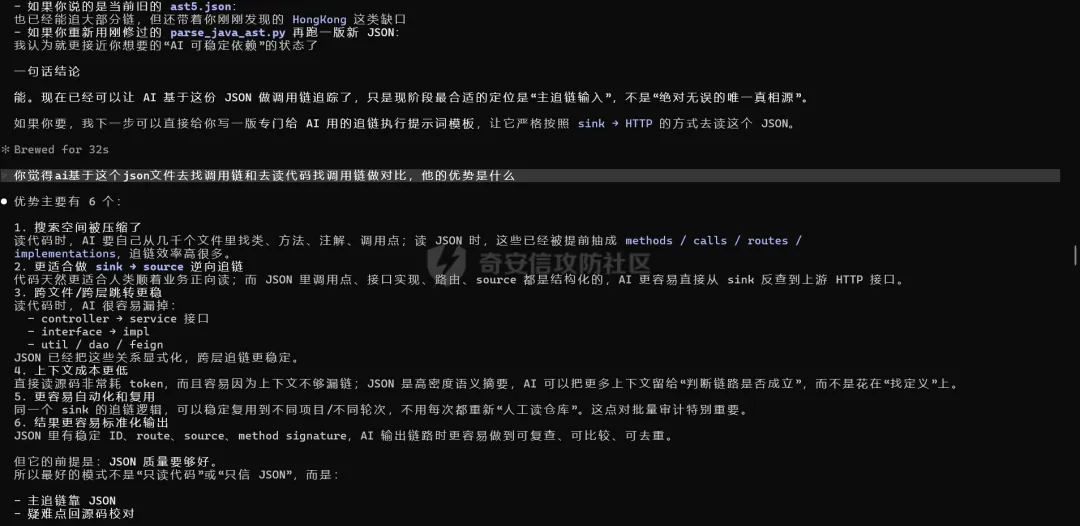
举个真实案例,一套微服务大代码去进行审计,接近8000的文件数,对89个sink点的追踪调用效果非常可观。
对于真实漏洞追踪链的分析
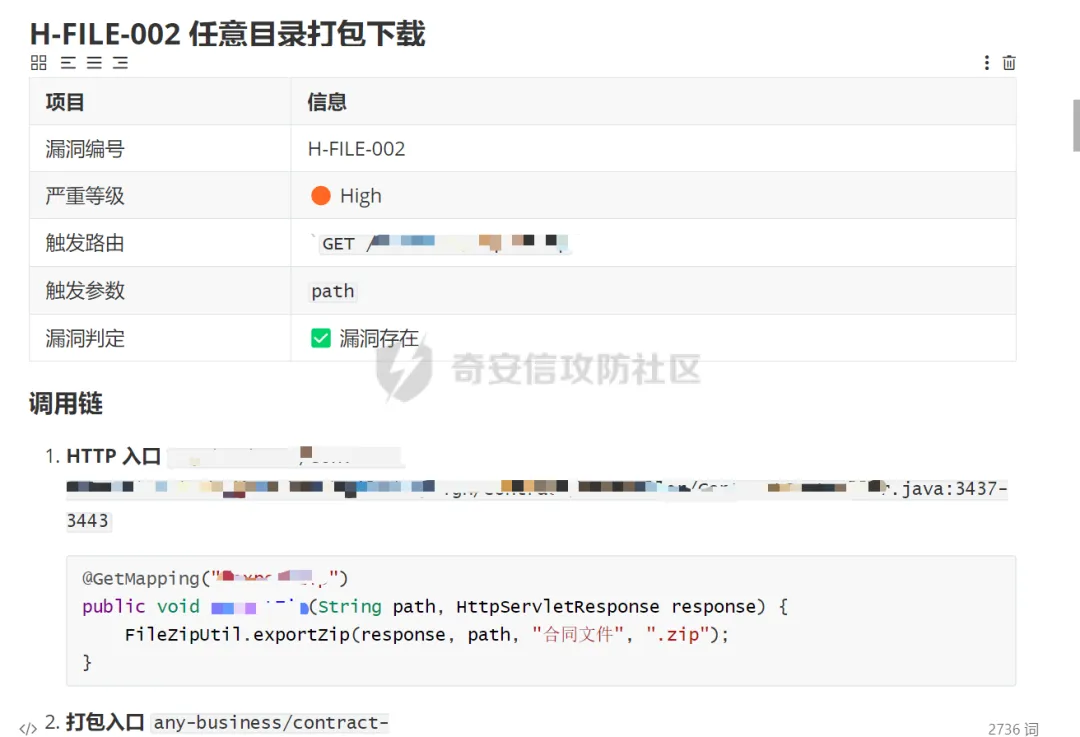
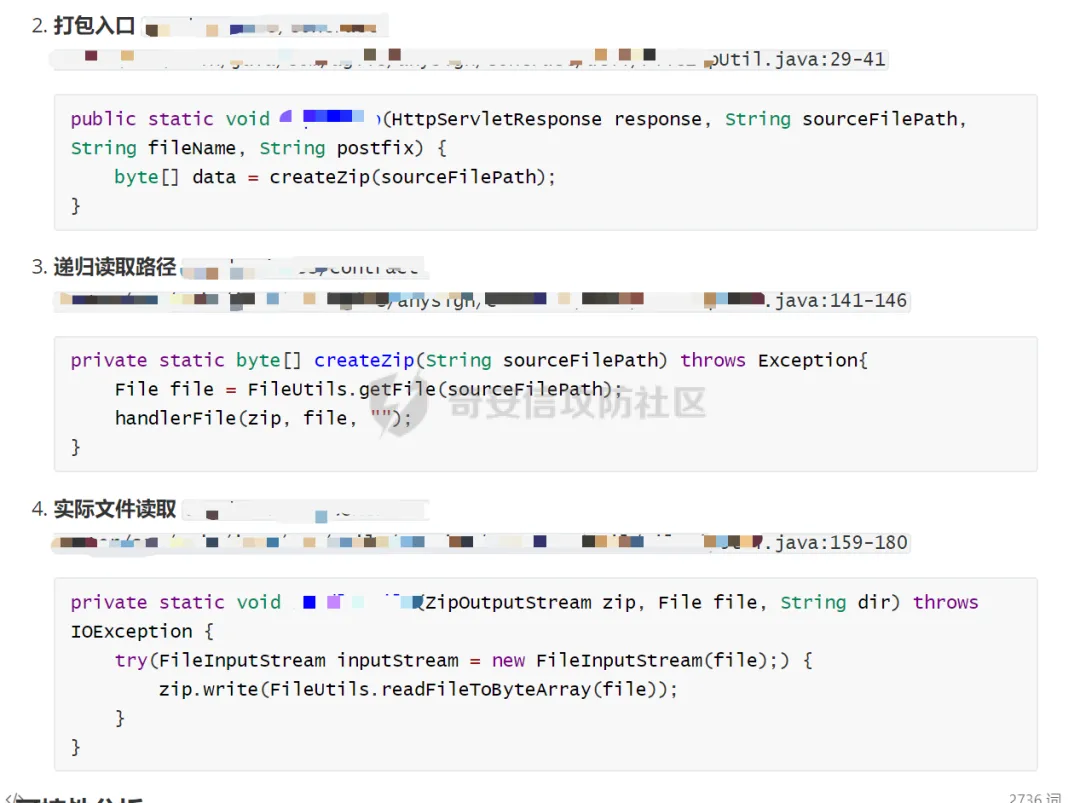

对于导不了source的调用链分析
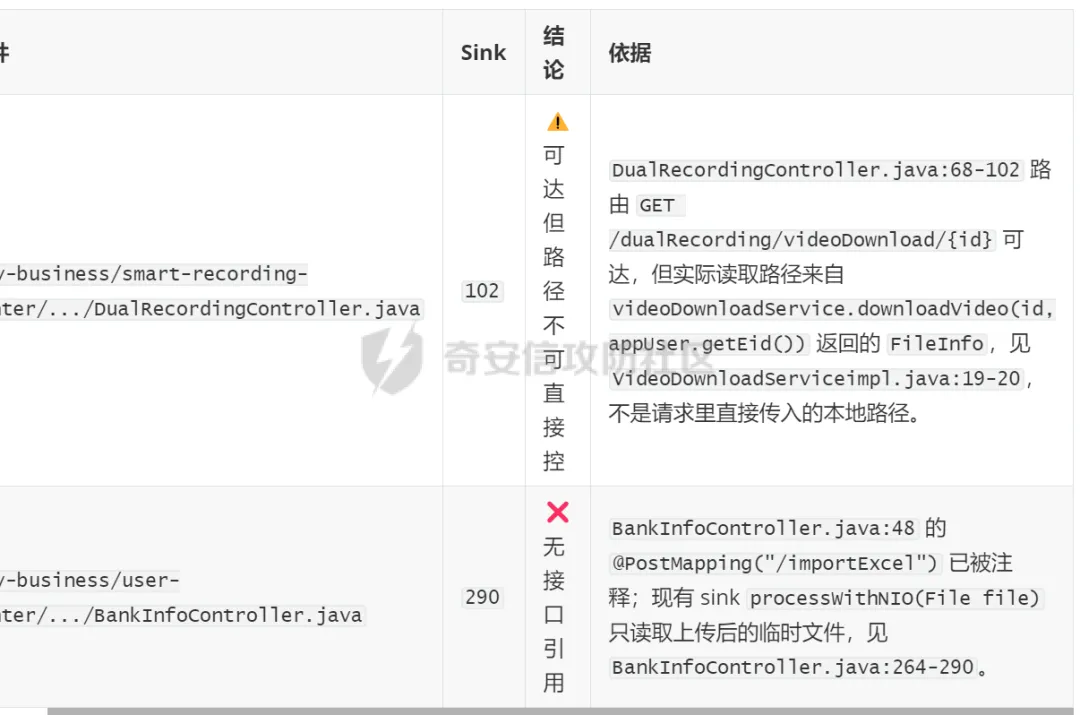
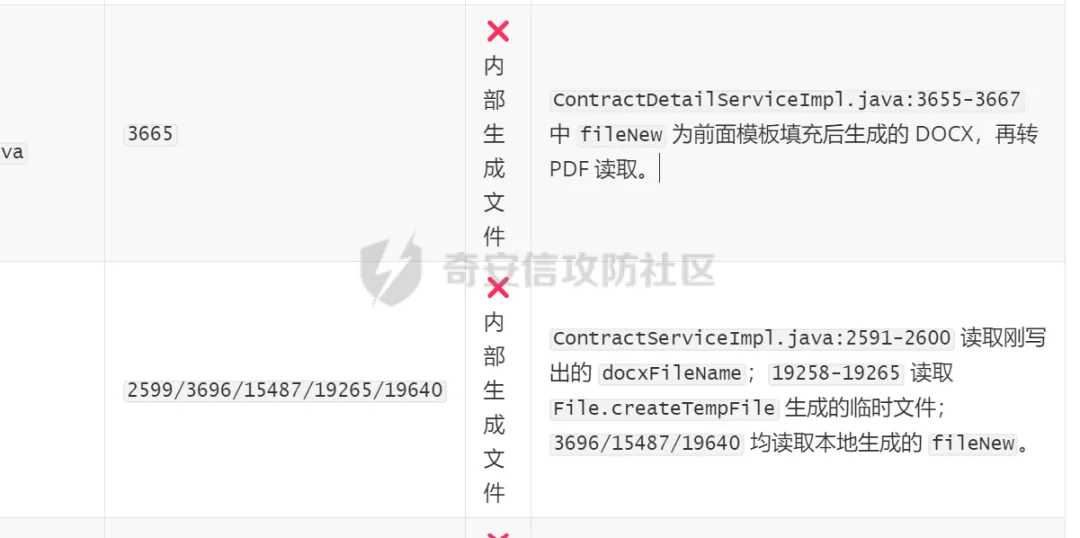
这些结果均经过人工复核,整体来说不仅审计时间变短了,并且token花费也确实实打实降低了很多。
总结
ai自动化审计这个过程其实会遇到很多的问题,这篇文章的研究重点其实就是想要证明,在当前的几千个接口数万个方法的复杂代码结构下,通过对ast的精准解析,ai其实可以不需要去阅读代码,仅仅只是凭借语义分析后的产物就实现更高效更快更节省token的去追踪调用链,我相信这也一定会成为ai自动化审计未来的主流方向!目前这篇文章更多想要的是抛砖引玉。调用链的分析也只是其中一环,包括现在也只是找到了一些思路,离真正的自动化还有很长的一段路要走,希望我的这些经验能对安全从业者产生一些帮助,后续我还会继续更新skills的设计思路,包括多agent的一个审计框架。
