 夜雨聆风
夜雨聆风GPU 不够,算力不够,内存不够,网络不够。
这些都对。
但我最近越来越觉得,市场对 AI 基础设施的理解还少了一层更底层的东西:
电。
不是一句简单的“AI 很耗电”。
真正的问题是:AI 正在把数据中心从一个传统的信息技术设施,推向一个高密度工业电力系统。
以前我们讨论数据中心,重点是服务器、芯片、网络、存储。
现在还要问一个更物理的问题:
这么多电,怎么从电网一路送到 GPU 核心,而且尽量少损耗、少发热、少占空间,还要足够稳定?
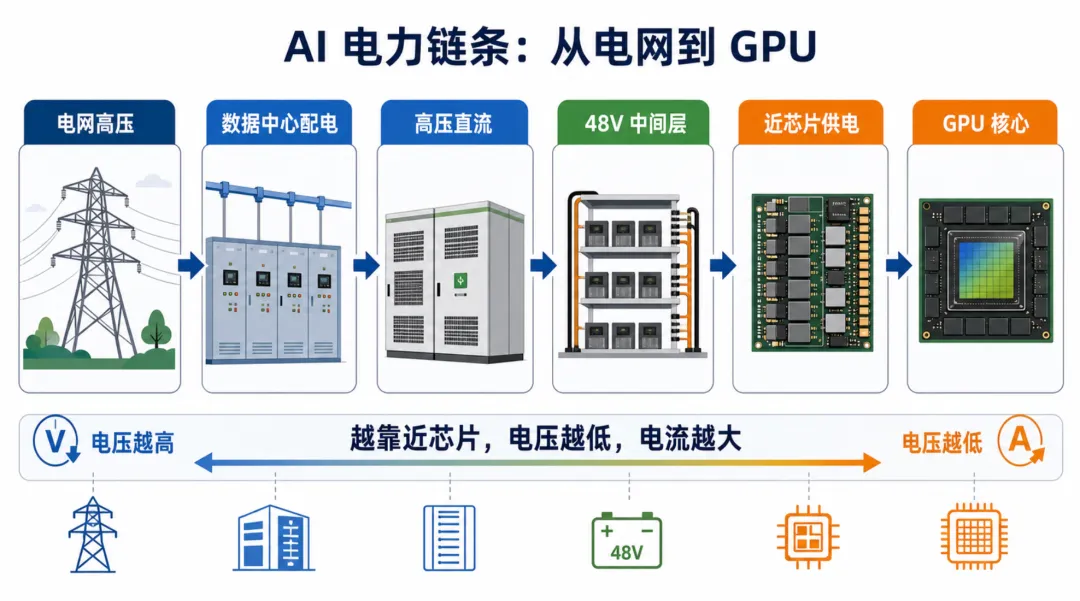
这才是这轮 AI 电力主线里最重要的变化。
1. GPU 为什么不能直接“接上电”就完了
最底层只有一个公式:
功率 = 电压 × 电流。
同样要送很多功率,要么提高电压,要么提高电流。
但电流越大,线路损耗越严重。更麻烦的是,损耗大概跟电流的平方相关。
也就是说,电流变成 2 倍,损耗可能接近 4 倍。
所以人类电力系统一直有一个基本原则:
远距离输电用高电压、低电流。靠近最终设备之后,再一级一级降压。
你可以把它想成运水。
远距离送大量水,不能只靠一根越来越粗的水管硬推。更有效的方式是提高压力,让水高效送到目的地附近,然后在最后再降到可以安全使用的压力。
电也是一样。
从发电厂到数据中心,再到机柜、服务器、GPU,电不是一根线直接过去,而是一条完整链条。
发电厂 → 高压输电 → 变电站 → 数据中心园区配电 → 楼内配电 → 机柜供电 → 服务器电源 → 主板电压调节 → GPU 核心
越远,越需要高电压来高效运输。
越靠近芯片,越需要低电压来安全、精确地使用。
2. 为什么最后 GPU 吃的是很低的电压
GPU 不是因为“贵”,所以需要低电压。
真正原因是芯片内部的晶体管太小。
这些晶体管像极小的电子开关,不能承受高电压。电压太高,不是“不太好”,而是可能直接击穿、过热、出错,甚至损坏。
所以 GPU 外部可能经历几百伏、几十伏的供电层级,但真正到核心附近,电压会被降到接近 1V,甚至更低。
这就是为什么有些文章会用一个很夸张的表达:
从几十万伏,一路到 0.65V。
它想表达的不是一个数字游戏。
它想说的是:每一个 AI token 背后,都有一条从国家级电网到芯片内部的电力链条。
没有电,GPU 只是昂贵的金属。
电送不到,算力就不能上线。
电送到了但转换效率低,成本和热量就会放大。
电不稳定,GPU 就不能可靠地满负载运行。
3. AI 真正改变的是功率密度
传统服务器也需要电。
为什么以前没有这么复杂?
核心差别是功率密度。
AI GPU 做的不是普通计算。
它在同时调动大量计算单元,做海量矩阵运算,还要不断搬运模型权重、激活值、缓存、上下文和网络数据。
AI 的电不只花在“算”上,也花在“搬数据”上。
单颗 GPU 功率上升 × 每台服务器 GPU 数量增加 × 每个机柜服务器密度提高 = 机柜功率密度爆炸
以前一个机柜几十千瓦可能已经很高。
现在 AI 机柜正在走向更高的功率级别。
这时,问题就不再是“多接几根线”。
问题变成:线缆够不够粗?铜排怎么设计?连接器会不会过热?电压会不会跌落?转换损耗怎么控制?热量怎么带走?备电系统能不能支撑?
这就是为什么 AI 数据中心不是简单扩容,而是在重做电力架构。
4. 为什么交流电和直流电的问题变重要
电网和楼宇配电主要是交流电。
但 GPU、CPU、内存这些芯片最终吃的是低压直流电。
所以数据中心必须把交流电变成直流电,再把直流电一层层降压。
问题是,每一次转换都有损耗。
损耗不是机器被磨坏,而是能量有一部分变成了热。
比如输入 100 份电,转换效率 96%,输出 96 份可用电,剩下 4 份变成热。
在普通设备里,4% 好像不多。
但在 AI 数据中心里,如果总功率是几百兆瓦,4% 就是非常大的电费和热量。
更麻烦的是,热还要靠冷却系统带走。
冷却系统自己又继续耗电。
所以 AI 电力架构要解决三个问题:少转换,高效率转换,靠近负载精准转换。
这就是为什么行业开始讨论更高电压的直流配电。
不是因为 GPU 要直接吃高压直流。
GPU 不会直接吃 800V。
真正的逻辑是:先用较高电压的直流,把大功率更高效地送到靠近机柜或服务器的位置。
然后再逐级降压,最后送到 GPU 核心。
5. 48V 为什么曾经是进步,现在又可能不够
服务器内部过去常见的是 12V 供电。
后来功率变大,12V 开始吃力。
因为同样送 4800W:
12V 需要 400A。48V 只需要 100A。
电流小了,线缆可以更细,损耗更低,发热更少。
所以 48V 曾经是一次非常重要的升级。
但 AI 把功率继续往上推。
如果一个机柜需要 100kW,用 48V 来送电,大约需要 2000A 以上的电流。
这已经不是简单“线粗一点”就能解决的问题。
它会牵涉到铜排、连接器、接触电阻、热管理、短路保护、机柜空间和可靠性。
所以我的理解是:
48V 不是错了。它只是从过去的“终点”,变成了新的“中间层”。
未来更可能出现的结构是:
电网交流电 → 高压直流配电 → 48V → 更低电压 → GPU 核心
也就是说,48V 仍然重要。
但它不再是整个系统的最终答案。

6. 为什么最后一厘米也很难
越靠近 GPU,电压越低。
但这里有一个反直觉的地方:
电压低,不代表问题简单。
因为功率仍然很高。
假设 GPU 核心附近需要 700W,电压是 0.7V,那么电流就是 1000A。
也就是说,最后一段虽然电压很低,但电流巨大。
大电流最怕走远路。
走得越远,损耗越大,发热越多,电压越不稳定。
所以最后一级电压转换必须尽量靠近 GPU。
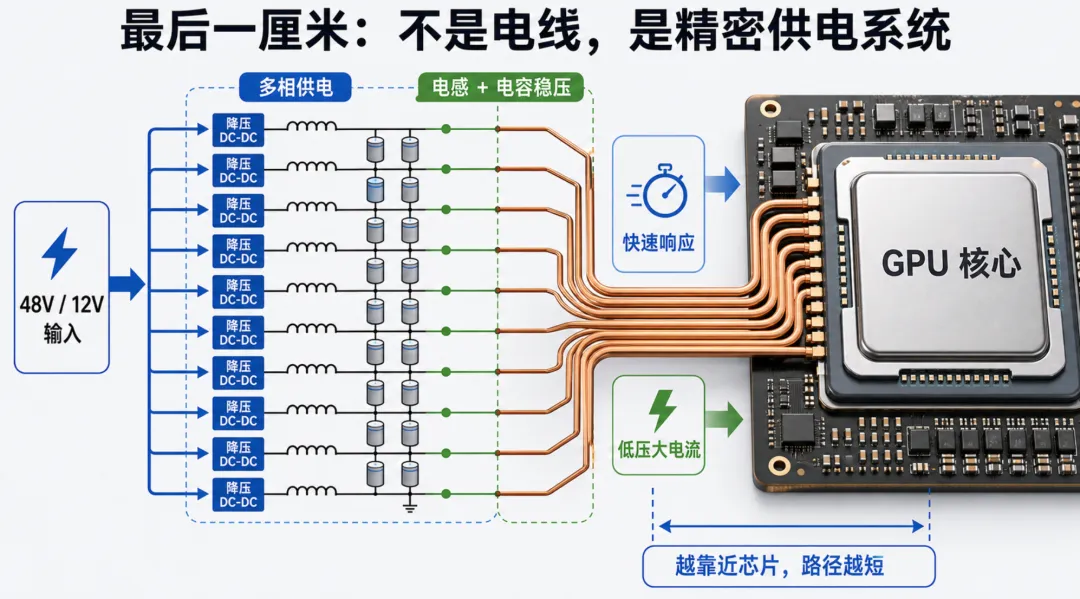
这就是所谓的近芯片供电。
它不是一根电线的问题,而是一整套精密系统。
电压调节模块 → 多相供电 → 功率开关 → 电感 → 电容 → 连接器 → 封装供电路径 → 散热
GPU 的负载也不是平稳的。
它可能这一瞬间满负载计算,下一瞬间等待数据,再下一瞬间又进入高负载。
电源系统必须快速反应。
补电慢了,电压会掉。
补过头了,电压会冲高。
两边都可能影响芯片稳定性。
所以最后一厘米的本质是:在离 GPU 尽可能近的位置,把较高电压快速、稳定、高效率地降到芯片需要的超低电压,并让巨大电流只走最短路径。
7. 新材料为什么被推到前台
电压转换靠什么?
交流电降压主要靠变压器。
直流电降压主要靠直流转换器。
直流转换器的核心像一个高速开关:
开关不断打开、关闭,电感和电容把这种脉冲整理成稳定的低压直流电。
开关越快、损耗越低、耐压越强,整个电源系统就越小、越高效、越少发热。
这就是为什么氮化镓和碳化硅开始被更多讨论。
它们不是因为名字听起来先进。
而是因为 AI 电力架构对功率、效率、空间和热量的要求越来越极端。
粗略理解:
氮化镓更偏高频、高效率、小体积。碳化硅更偏高电压、大功率、高温和可靠性。
一个更可能出现在靠近服务器和芯片的高密度电源转换里。
一个更可能出现在更高压、更大功率的电力转换层。
但我不认为这条主线应该被简单理解成“新材料概念”。
真正的因果链是:
AI GPU 功率上升 → 机柜功率密度上升 → 传统配电和转换架构吃力 → 需要更高效率、更小体积、更少发热 → 电力转换器里的功率器件被迫升级
材料只是工具。
真正的主线是电力架构被重做。
8. 我看到的那个被低估的点
市场经常把这件事讲成一句话:
AI 很耗电。
但这句话太粗了。
我的看法是,真正被低估的点不是“用电量增加”,而是:
AI 把数据中心变成了一个从电网到芯片都需要重新设计的高密度电力系统。
这条链条可以分成三层。
第一层,是电从哪里来,怎么接进数据中心。
第二层,是进入数据中心之后,怎么高效送到机柜和服务器。
第三层,是最后怎么稳定、快速、低损耗地喂给 GPU 核心。
每一层都有不同的瓶颈。
每一层也有不同的产业机会。
但最重要的不是贴一个“AI 电力”的标签。
真正要问的是:
哪一层最难绕开?哪一层供给最紧?哪一层能把工程瓶颈变成真实利润?哪一层只是概念上沾边?
这是我理解这条主线的方式。
9. 风险也要讲清楚
第一,技术路线还没有完全统一。
高压直流、48V、近芯片供电、新材料器件,不同客户和不同系统可能会有不同选择。
第二,旧数据中心不会一夜之间全部重做。
新架构更可能先从新建的高密度 AI 数据中心开始,而不是立刻替代所有旧设施。
第三,最酷的技术不一定是最好的生意。
有些技术很先进,但收入还小,利润还没验证,客户导入周期也可能很长。
第四,如果 AI 资本开支放缓,这条主线的紧迫性也会下降。
如果 GPU 功率密度不再继续上升,电力架构升级的速度也可能低于现在的预期。
所以我不会把它理解成一个简单的主题。
我更愿意把它理解成一个观察框架。
10. 我的当前看法
AI 的第一层故事是模型。
第二层故事是 GPU。
第三层故事是内存、网络、存储和封装。
但再往下,还有一层更物理、更底层的故事:
电怎么送到芯片。
这件事听起来没有模型那么性感,也没有 GPU 那么直观。
但它非常真实。
因为所有 token 最后都要消耗电。
而电不是一个抽象数字。
它必须从电网过来,经过转换,经过配电,经过散热约束,最后变成 GPU 核心可以安全使用的低压直流电。
所以这条主线的本质不是:
AI 需要更多电。
更准确地说是:AI 需要一整套新的高密度送电方式。
这就是我现在对 AI 电力链条的底层理解。

