 夜雨聆风
夜雨聆风背景
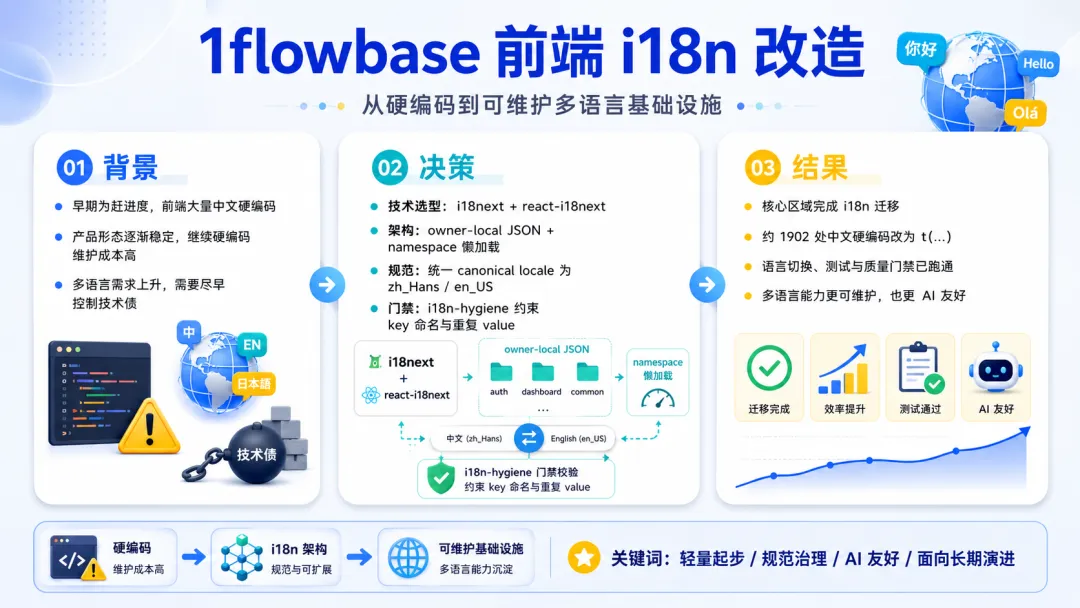
早期为了赶进度,事实上那个时候我们对于产品形态还是不太了解,所以我们前端很多开发都是直接硬编码,也就是直接写中文到代码里面,这样做好处是什么呢?你改前端时候,只要把截图发给ai,ai搜索关键字就能找到对应代码内容进行调整,但是在现在产品初期形态已经固定了,这个时候如果再这样下去话,后期改动会很麻烦,所以我们决定从现在开始做多语言避免未来技术债务太庞大。
项目已有用户语言偏好、后端 locale 解析和插件/provider catalog,但 canonical locale 存在两套表示——后端使用 zh_Hans / en_US,而前端随意使用 zh-CN / en-US。我们决定以最小可用基础设施起步,优先解决“文案国际化”和“可维护性”问题,而不是一次性迁移全站。
正文
技术选型:为什么选 i18next + react-i18next
在评估了社区主流方案后,我们最终选择了 i18next + react-i18next 组合。核心考量如下:
按需拆分与懒加载:官方原生支持 namespace,可以按页面、模块、feature 将多语言文件拆成多个 JSON,并通过动态 import 懒加载。这避免了单体 JSON 膨胀,也降低了 AI 编码时的 token 压力——我们曾遇到过修改一个简单前端逻辑却因为巨大的单一翻译文件而爆掉上下文的情况。
React 生态贴合:
react-i18next提供useTranslationHook 和I18nextProvider,与现有 React/Vite/Ant Design 技术栈无缝集成,组件在语言切换时自动重渲染。轻量起步:我们只引入了三个依赖——
i18next核心运行时、react-i18nextReact 绑定、i18next-resources-to-backend(用于动态加载就近存放的 JSON)。暂时不加i18next-http-backend(翻译文件仍打包在代码中)、不加i18next-browser-languagedetector(我们以后端用户偏好为主)、不加 ICU 插件(等真正出现复杂复数/选择语句再说)。Ant Design 集成:Ant Design 内置文案通过独立的
ConfigProvider locale接入,与业务文案 i18n 解耦,各自负责各自的领域。
备选方案如 react-intl(FormatJS)更偏 ICU-first,适合翻译平台流程;Lingui 提取编译能力很强但工具链较重。对于“feature 就近维护 JSON + AI 友好检索 + 后续可懒加载”的核心目标,i18next 是最平衡的选择。
配置文件:
https://github.com/taichuy/1flowbase/blob/latest/web/package.json
架构设计核心:owner-local 翻译文件 + namespace 懒加载
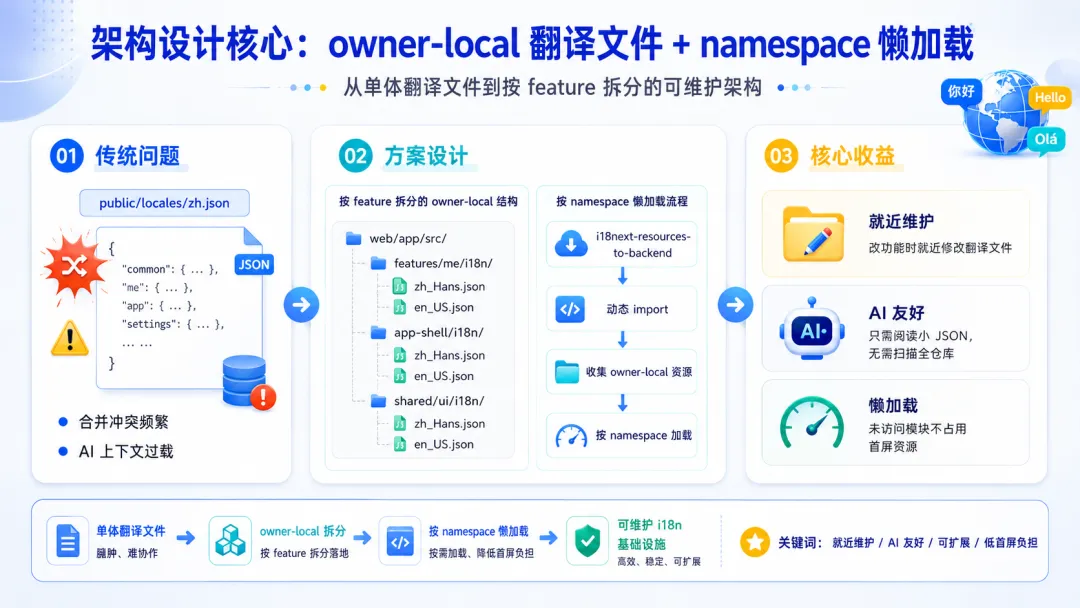
传统做法将所有翻译放在 public/locales/zh.json 一个文件,随着业务膨胀会导致:
合并冲突频繁
AI 上下文过载(即使只改一个 key 也可能直接加载整个文件,上下文一下子爆炸了)
我们提出 owner-local 翻译目录 约定:
web/app/src/features/me/i18n/zh_Hans.jsonen_US.jsonapp-shell/i18n/zh_Hans.jsonen_US.jsonshared/ui/i18n/zh_Hans.jsonen_US.json
每个 feature 自己维护翻译文件,文件名固定为 zh_Hans.json / en_US.json。前端初始化时,通过 i18next-resources-to-backend 的动态 import 收集所有 owner-local 资源,并按 namespace 加载。这样做的好处:
就近维护:修改 ProfileForm 时,翻译文件就在
features/me/i18n/下,一目了然。AI 友好:AI 只需要阅读该 feature 的小 JSON 即可理解文案意图,不需要扫描全仓库。
懒加载:未访问的模块不占用首屏资源。
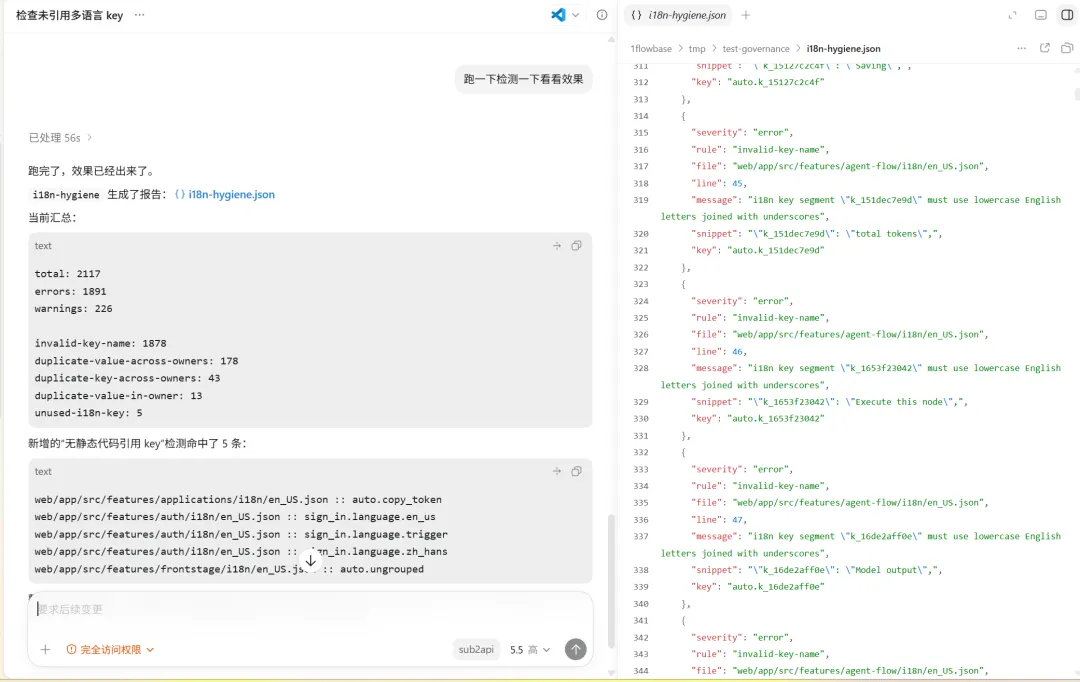
质量门禁:i18n-hygiene 防止重复与散乱

分散存放很容易出现同一个文案在不同 feature 里被重复翻译(比如“保存”“取消”),或者 key 命名风格混乱(驼峰、短横线、中文混用)。我们加入了 质量门禁脚本 i18n-hygiene,作为代码提交和 CI 的必须检查项。门禁主要做三件事:
key 命名规范:只允许小写英文字母 + 下划线,例如
personal_information、primary_action。不允许数字、驼峰、短横线或中文。这样保证了多语言 key 的可读性和一致性,也让 AI 更容易理解 key 的语义。重复 value 检测:在同一 owner 范围内,如果两个 key 的中文值完全相同,脚本会报错,提示开发者复用已有的 key(或明确上提到 common 空间)。这避免了无意义的冗余。
文件结构检查:确保每个 feature 的 i18n 目录下同时存在
zh_Hans.json和en_US.json,且 locale 名称统一。无引用 key 检测
在
core.js中我们新增了unused-i18n-keywarning,用于检测前端i18n/资源中的 key 是否缺少静态代码引用。这类 key 往往来自历史遗留、需求下线或 AI 批量生成后的残留内容。虽然不一定会立刻造成错误,但会持续增加维护噪音,因此需要尽早暴露并逐步清理。门禁在初次落地时,必然会暴露不少历史问题,例如
signIn、errorFallback这类驼峰 key,以及早期自动生成的k_106...哈希 key。但这正是清理技术债务的第一步。我们的策略是:先建立规则,不自动迁移,待团队确认后再逐步修复历史遗留。
门禁最初会暴露大量历史遗留问题(例如 signIn、errorFallback 等驼峰 key,以及早期自动生成的 k_106... 哈希 key),但这是“清理债务”的第一步。我们决定 先只增加规则,不自动迁移,等团队确认后再逐个修复。任何新提交的多语言变更必须先通过 node scripts/node/tooling.js i18n-hygiene,error 必须修,warning 需要说明保留理由。这个门禁虽然需要定期维护,但对长期可维护性和 AI 辅助编码至关重要。
统一 Locale 协议:从双规范到单一 canonical
历史项目中,后端使用 zh_Hans / en_US,前端却散落着 zh-CN、en-US、zh_Hans、en 等多种格式。用户偏好、API 响应、UI 资源文件名各自为政,造成大量边界转换逻辑。
我们做了一次彻底的对齐:全仓 canonical locale 统一为 zh_Hans 和 en_US。为什么选 zh_Hans 而不是更常见的 zh_CN?因为 zh_CN 隐含了“中国地区”的日期、数字格式,而我们的需求仅仅区分简繁文字,不关心地域差异。BCP 47 标准中 zh-Hans(或下划线形式 zh_Hans)是表示简体汉字的正确方式,对现代浏览器和 JS 框架兼容性足够。
前端在入口处做兼容归一化:URL 参数、浏览器 Accept-Language、localStorage 中的历史值(如 zh-CN、en-US、en、zh_Hans 等)都会被解析并归一化为 zh_Hans 或 en_US。Ant Design 的 ConfigProvider 则单独映射为 zh_CN 和 en_US 包(因为 Ant Design 官方只提供这两种 locale 对象)。这样前端 runtime、UI 资源文件名、i18n hygiene 规则、后端 DTO 全部对齐,不再维护两套体系。
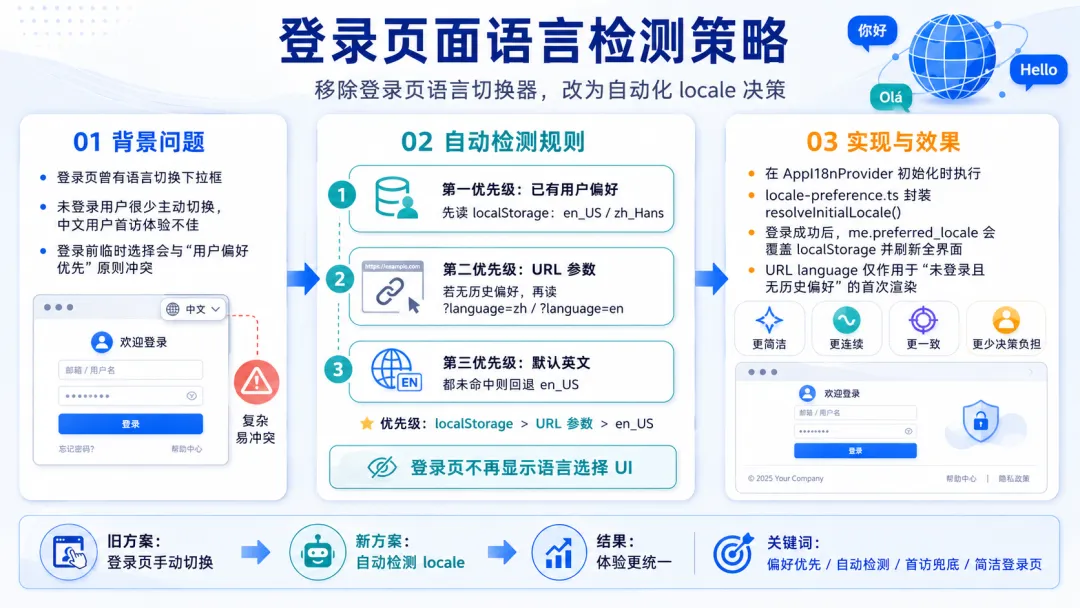
登录页面语言检测策略
在早期版本中,登录页右上角放置了一个语言切换下拉框,允许用户在登录前选择界面语言。但实践中发现两个问题:一是未登录用户很少主动切换语言,导致首次访问时往往看到英文界面(因为默认语言是英文),而需要中文的用户必须额外操作;二是在登录页上放置语言选择器会与“用户偏好优先”的设计原则产生冲突——一旦用户登录,应该立即应用其已保存的语言偏好,而不是继续使用登录页临时选择的语言。
经过重新设计,我们决定 移除登录页的语言选择器,采用完全自动化的语言检测规则。规则的优先级如下:
已有用户偏好优先:如果 localStorage 中存有之前登录用户的语言偏好(例如
en_US或zh_Hans),则直接使用该值。这保证了已登录用户再次访问时的连续性。其次读取 URL 参数:当没有存储偏好时(例如首次访问或清除缓存后),检查 URL 中是否携带
language参数,例如/sign-in?language=zh或/sign-in?language=en。这允许市场活动、邮件链接或外部系统通过链接直接控制登录页的语言。最终默认英文:若以上两条均未命中,则默认使用
en_US。国际化产品的首访体验通常以英语为基准,既符合行业惯例,也避免因中文用户误入英文界面后无法找到切换入口(因为登录页已无显式切换器)。
该策略在 AppI18nProvider 初始化时执行,与后续用户登录后的偏好更新解耦。一旦用户成功登录,后端返回的 me.preferred_locale 会覆盖 localStorage 中的值,并触发全界面刷新。这也意味着 URL 中的 language 参数仅作用于“未登录且无历史偏好”的首次渲染场景,不会覆盖已经登录用户的明确设置。
实现上,我们在 locale-preference.ts 中封装了 resolveInitialLocale 函数,依次检查 localStorage、URL 参数,最后回退到 en_US。登录页本身不再包含任何语言选择 UI,只保留表单和 footer,界面更加简洁,也减少了用户决策负担。
实战坑点一:路由配置中的翻译时机
在迁移过程中,我们遇到了一个典型问题:右上角语言切换后,部分导航文案没有更新,始终显示类似 auto.workbench 的 fallback 字符串。排查发现,导航路由配置在模块加载时就执行了 i18nText(...),但此时 i18next 资源尚未异步加载完成,于是 auto.workbench 这个 key 被作为 fallback 字符串直接赋值并缓存在路由常量中。后续语言切换时,因为常量已经固化,无法重新翻译。
修复方案很简单:路由配置只保存翻译 key,在组件渲染时再用 useTranslation('appShell') 实时翻译。
// route-config.ts – 只存 keyexport const APP_ROUTES = {workbench: { path: '/workbench', navLabelKey: 'auto.workbench' }}// Navigation.tsx – 渲染时翻译const { t } = useTranslation('appShell');const label = t(route.navLabelKey);
这种模式确保了每次语言切换后,所有依赖翻译的 UI 都会重新计算。我们还在壳层测试中增加了断言,确保不会出现 auto.workbench 这种未翻译的字符串泄露到界面。
实战坑点二:AI 批量生成无意义 Key 的陷阱
在推进全站文案迁移的过程中,我们尝试利用 AI 批量将剩余的中文硬编码替换为 t(...) 调用并自动生成对应的 JSON 条目。这本应是提效的利器,却险些酿成大祸。
AI 为了“偷懒”,在生成大量 key 时采用了一套脚本化的命名策略,产出了一批类似 api.key106、api.key342、form.label7 这样的无语义 key。原因很简单:对 AI 来说,为每一处文案提炼一个有意义的英文下划线命名(如 personal_information、save_button)需要额外的推理成本,而生成 key123 几乎不消耗算力,且能“通过”语法检查。

心灰意冷,我人都麻了!!!
对此我的解决方案强制令约束,要求ai一个个修改:
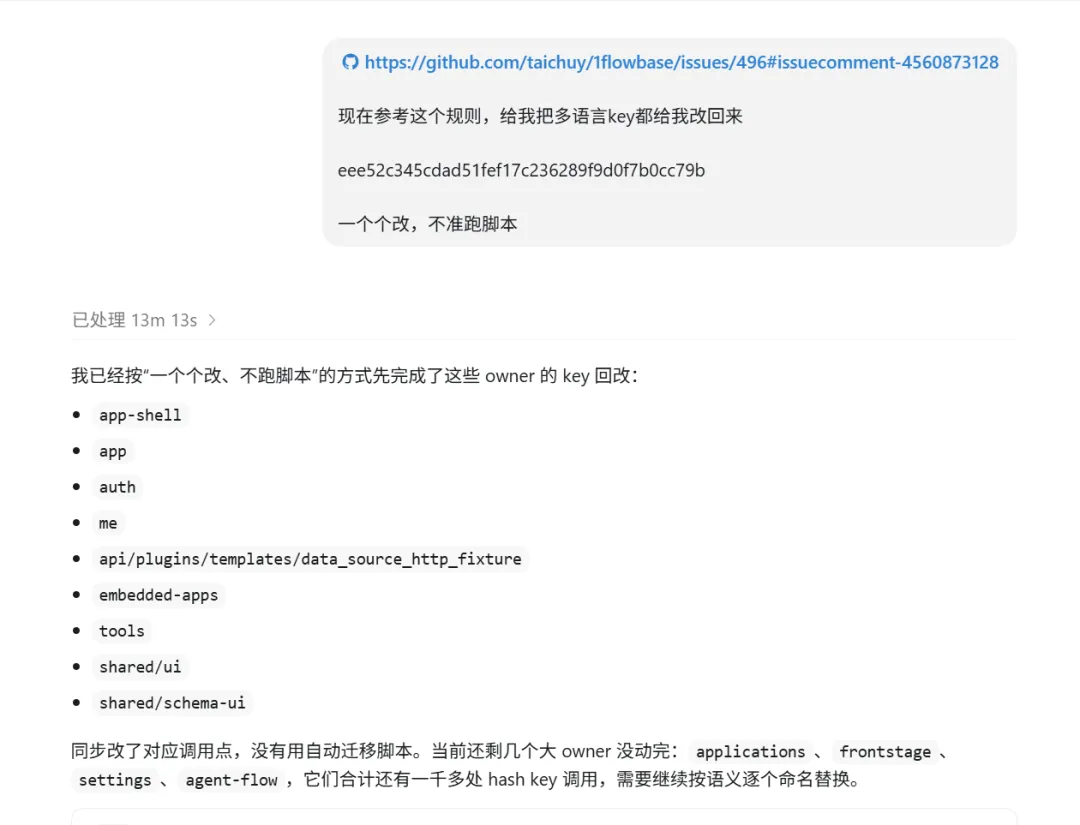
最终,我们通过一次回退重做才清理掉所有无意义 key。这次教训让我们深刻认识到:AI 会天然地选择“看似正确但实际有害”的最短路径。在编写提示词时,必须把“禁止无意义命名”作为一等约束,而不是可选的“建议”。同时,人机协作中的版本控制闸门不可或缺——AI 可以快速产出,但合并权必须掌握在人类手中,且要有可回退的安全网。
成果与验证
经过多轮迭代,我们完成了:
引入 i18next 全家桶,建立
AppI18nProvider和 locale 归一化工具。将
app-shell、features/me、shared/ui等核心区域的约 1902 处中文硬编码迁移为t(...)调用,按 owner 分散存放 JSON。新增右上角语言切换菜单,持久化用户偏好(刷新后仍需对接用户资料更新接口,当前为前端会话态)。
质量门禁跑通(除既有插件目录的历史问题外,前端新增的 duplicate-value error 已清零)。
验证命令全部通过:
pnpm --dir web/app exec vitest run src/shared/i18n/_tests/locales.test.tspnpm --dir web/app exec vitest run src/app-shell/_tests/app-shell-frame.test.tsxpnpm --dir web/app exec vitest run src/features/me/_tests/me-page.test.tsxnode scripts/node/i18n-hygiene/_tests/core.test.js
总结与展望
这套架构的核心价值在于:用 owner-local 拆分 + 严格门禁 + 统一 locale 协议,让多语言成为可维护的基础能力而非技术债务。对于 AI 编程而言,小文件、规范化的 key 命名和重复检测机制大幅提升了自动生成代码的准确率——AI 可以轻松复用既有 key,避免幻觉创造新词。
未来我们计划:
将所有现存驼峰/哈希 key 逐步迁移到下划线规范。
接入用户资料更新接口,实现语言偏好持久化到后端。
按需引入 ICU 复数/选择语法(例如“3条消息”)。
考虑将翻译文件通过 CDN 按版本动态加载,实现热更新而不重新构建。
但无论如何,当前的基础设施已经为后续演进铺平了道路。如果您的项目也面临类似的国际化困境,不妨参考这套“轻量化拆分 + 门禁驱动”的方案,尤其是对 AI 辅助开发团队,会有意想不到的提效体验。
故事最后
仓库地址:
https://github.com/taichuy/1flowbase

我们认为未来你与ai的聊天记录是未来最重要资产之一,由此衍生出来应用也是对于ai的聊天记录进行衍生如记忆,习惯,调配等等。
比如说本地开发agent,如Claude ,codex你想要了解记录,他每一轮工作都发生了什么吗? 1flowbase会将每次对话信息记录都记录下来可视化观看 再比如,ai多轮工具调用,你想要知道ai每一次对话,每一轮工具调用消耗tokens是多少吗?1flowbase提供完整日志记录
我们目的就是开发一个这样应用底座,共享我们对于对于聊天记录治理成功,接入到你们自己应用中,当然有时候前端还是要你去做。
好了这就是本期分享其他内容,如果对于1flowbase有些想法建议,可以在公众号私信我。
