 夜雨聆风
夜雨聆风本文转载自:ScienceAI

图片转载自机器之心-ScienceAI
蛋白质药物研发正在进入一个新的阶段:研究者不再只满足于改造天然蛋白质,而是希望按需设计具备特定功能、能够稳定折叠、并具有成药潜力的全新蛋白质分子。
在这一过程中,「功能性」和「可折叠性」始终是从头蛋白质设计的核心挑战。一个序列即使被模型预测具有目标功能,如果无法形成稳定三维结构,也难以在实验中表达和发挥作用;相反,一个折叠良好的蛋白质,如果无法实现预期的结合、催化或调控功能,也无法真正进入药物研发流程。
近期,清华大学智能产业研究院(AIR)与水木分子团队联合提出的 CodeFP(Co-generative Functional Protein Design),为这一长期难题提供了新的建模思路。该工作围绕「功能 — 序列 — 结构」的协同生成展开,通过离散扩散模型同时生成氨基酸序列与局部结构 Token,在设计早期就让功能约束、序列规律和结构可实现性共同参与优化。
研究论文《Co-Generative De Novo Functional Protein Design》已被机器学习顶会 ICML 2026 接收。

论文地址:https://arxiv.org/abs/2605.00948
目前,研究团队已在 OpenBioMed 正式开源 CodeFP 的模型参数,并提供了完整的推理实现。
开源地址:
https://github.com/PharMolix/OpenBioMed
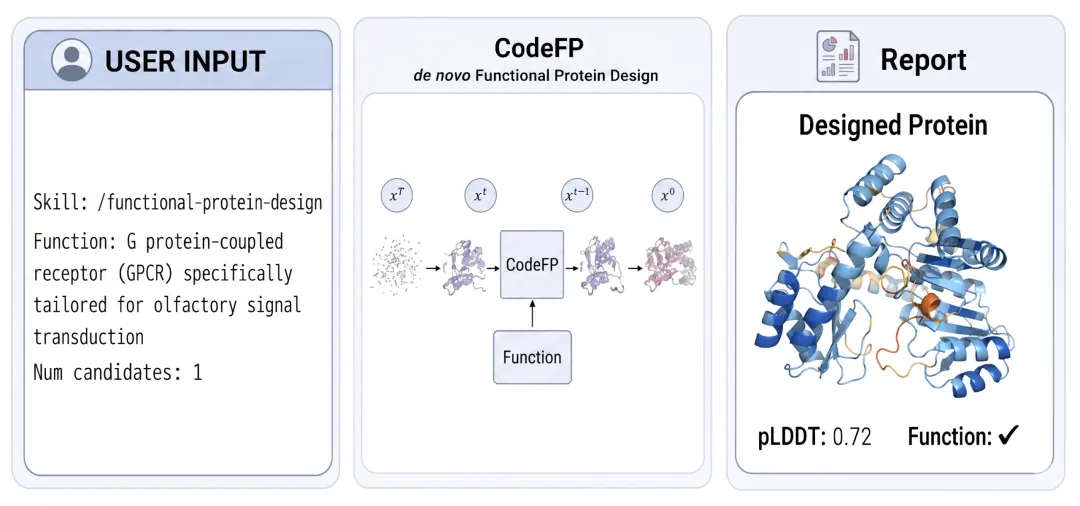
图1:在 OpenBioMed 平台上使用skill调用 CodeFP 进行从头功能蛋白质设计
从单一路径到协同生成:为什么 CodeFP 重要?
现有从头功能蛋白质设计方法大致可分为两类。
一类是直接从功能生成序列,例如基于蛋白质语言模型的生成方法。这类模型能够继承天然蛋白质序列中的进化规律,因此生成序列通常具备较好的自然性和可折叠潜力,但对复杂功能,尤其是多功能组合的精准控制仍存在不足。
另一类方法先生成满足功能需求的蛋白质骨架,再通过反向折叠得到序列。这一策略更强调结构与功能的对应关系,但如果骨架生成阶段缺少序列层面的约束,后续得到的氨基酸序列可能难以折叠回目标结构,导致结构设计与序列可实现性脱节。
CodeFP 的关键突破在于改变了「先序列后结构」或「先结构后序列」的单向流程。模型将蛋白质表示为两类离散 Token:一类是氨基酸序列 Token,另一类是描述局部构象的结构 Token。在扩散去噪过程中,二者交替更新、持续交互,使结构生成受到序列规律约束,同时让序列设计获得结构信息支持,从而提升功能实现与结构稳定性的联合表现。

图 2:CodeFP 如何通过协同解码解决问题
三个核心设计:让功能真正落到结构上
CodeFP 的技术创新主要体现在三个方面。
首先是序列 — 结构协同生成。模型基于 DPLM-2 的离散蛋白质表示,将局部蛋白质结构量化为结构 Token,并与氨基酸 Token 一起建模。通过多模态离散扩散,CodeFP 在每一步生成中同时修正序列与结构,使两种信息不再彼此割裂。
其次是功能 — 结构检索机制(Functional-Structural Retrieval, FSR)。传统方法往往用 one-hot 向量或文本嵌入表示功能标签,但蛋白质功能并不是抽象语义本身,而是由具体的局部结构基序承载。CodeFP 构建了功能结构锚点数据库,将 GO 功能标签与代表性局部结构模体关联起来,并通过交叉注意力注入生成过程。换言之,模型在生成蛋白质前,能够获得「实现该功能通常需要怎样的局部结构」的先验信息。
第三是局部结构 — 功能辅助监督(Local Structure-Function Supervision, LSFS)。结构离散化会带来一对多映射问题:相似功能可能对应多种结构 Token 表达,训练中容易产生模糊信号。CodeFP 在连续隐藏状态上加入功能预测监督,使模型在生成局部结构时能够更直接地对齐目标功能,从而提升功能条件学习的稳定性。
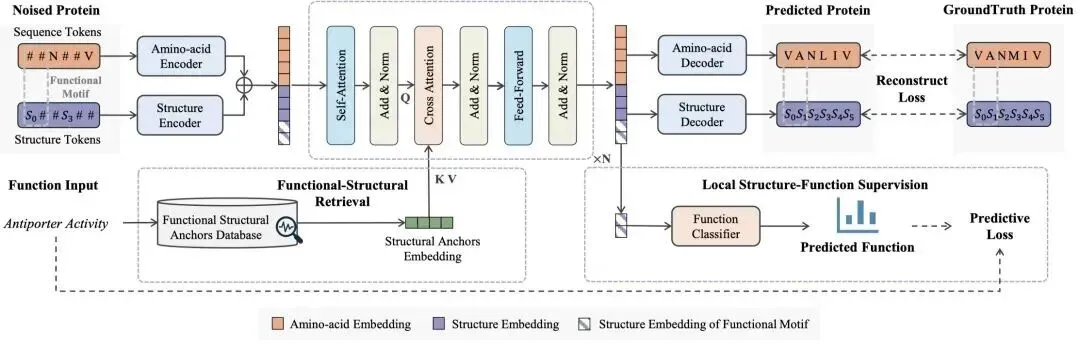
图3:CodeFP 模型全貌
实验结果:功能一致性与可折叠性同步提升
在 GO 条件蛋白生成任务中,CodeFP 在功能一致性、结构可折叠性和生成分布自然性方面均取得了领先表现。
论文结果显示,与最强基线相比,CodeFP 在功能一致性上平均提升 6.1%,在可折叠性上提升 3.2%。在更具体的指标上,CodeFP 的 F1-Macro 达到 0.446,高于 CFP-Gen 的 0.370;pLDDT > 70 的结构成功率达到 80.65%,高于 Pinal 的 74.22%。这些结果表明,CodeFP 不仅更能满足目标功能约束,也更有可能生成可稳定折叠的蛋白质序列。
更值得关注的是模型在分布外功能组合上的表现。对于训练集中未出现、但自然界中存在的功能组合,CodeFP 的 F1-Macro 相比基线提升 9.1%,显示出更强的零样本组合泛化能力。在一个多功能蛋白质案例中,CodeFP 生成序列的 pLDDT 达到 94.9、pTM 达到 0.96,同时与同功能天然蛋白质的最高序列一致性仅为 32%,说明模型并非简单复现训练样本,而是在探索新的序列空间。
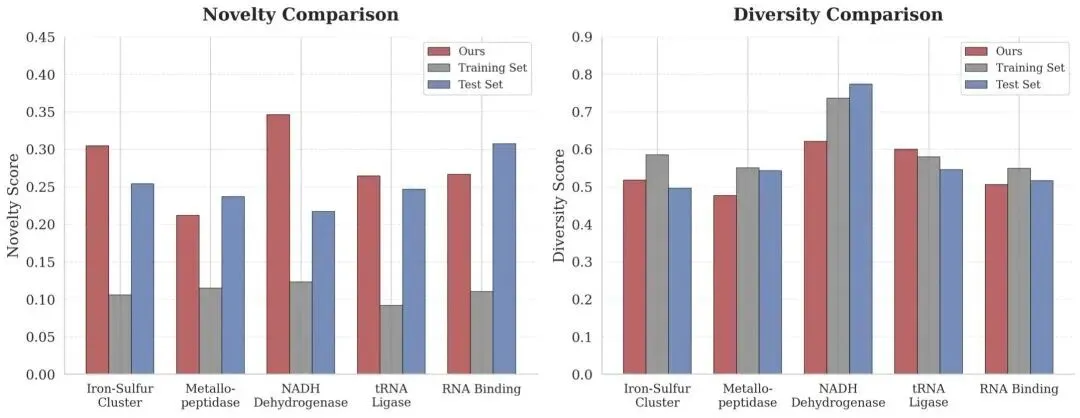
图4:生成新颖性与多样性分析。展示了五种不同功能任务下新颖性(左)与多样性(右)的分布。
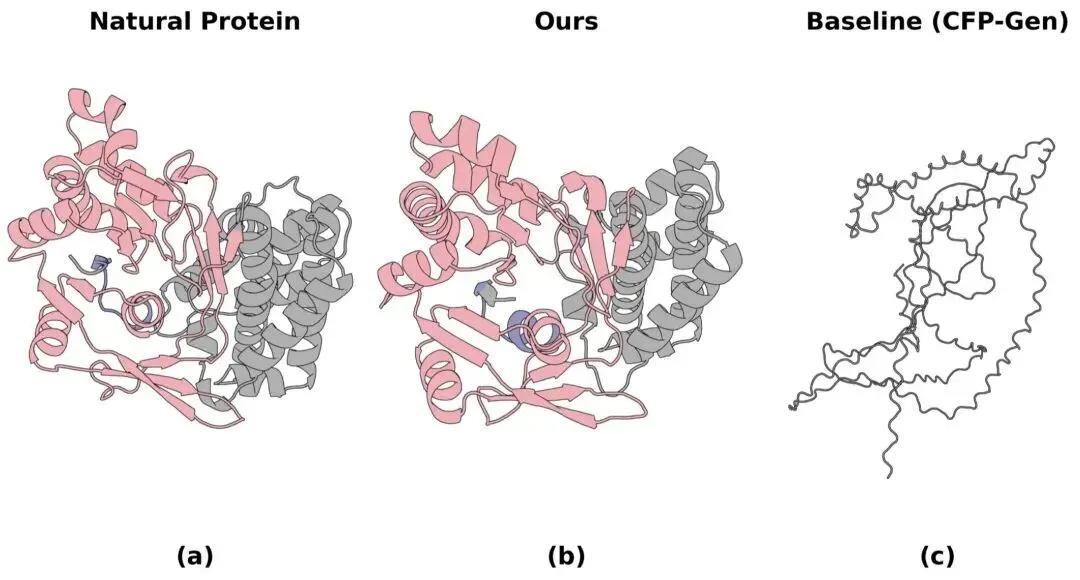
图5:OOD 组合多功能蛋白质生成可视化。基于未见过的功能组合(甘露醇-1-磷酸5-脱氢酶活性与 NAD 结合)生成目标蛋白质。
(a) 天然结构
(b) 本文方法生成结构
(c) 基线 CFP-Gen 生成结构
图中红色为 NAD 结合基序,蓝色为脱氢酶催化基序。
面向药物研发的意义
对于大分子药物研发而言,CodeFP 的价值不只在于生成「看起来合理」的蛋白质序列,更在于把功能设计与结构可实现性放进同一个生成框架中。
在近期应用上,它有望用于蛋白质药物的稳定性优化、功能增强和多功能模块设计,帮助研究人员在计算阶段提前筛除难以折叠或难以表达的候选分子,提高后续实验验证效率。
在更长远的应用中,类似 CodeFP 的方法有望推动可编程蛋白质药物、人工酶、生物制造催化剂、细胞器靶向蛋白以及多特异性治疗分子的设计。特别是在复杂功能组合场景中,模型对 OOD 功能组合的泛化能力,为设计自然界中少见甚至未见过的功能蛋白质提供了新的技术基础。
当然,从计算设计到真实药物仍需要湿实验验证。论文也指出,未来仍需扩展功能数据集、提升复杂功能组合生成的鲁棒性,并进一步通过实验验证模型的实际可用性。对于 AI 制药而言,这恰恰是算法平台走向产业闭环的关键一步。
CodeFP 展示了水木分子在 AI 蛋白质设计方向的持续探索:通过将蛋白质语言模型、离散扩散、结构先验和功能监督结合起来,从源头提升功能蛋白质设计的可控性与可实现性。随着计算模型与实验平台进一步闭环,从头设计有望从「生成候选序列」走向「系统化创造可验证、可优化、可成药的新型蛋白质分子」。
参考文献
Chen, X., Luo, Y., Fan, S., & Nie, Z. Co-Generative De Novo Functional Protein Design. Preprint, 2026.
Kortemme, T. De novo protein design—from new structures to programmable functions. Cell, 2024.
关于水木分子
AI赋能生命科学,促进人类健康长寿。水木分子,作为清华系大模型创业公司,成立于2023年6月,源自张亚勤院士创办的清华大学智能产业研究院(AIR),清华大学万国数据教授、AIR首席研究员聂再清教授担任公司首席科学家。水木分子致力于打造生命科学领域的基础大模型和智能体平台,利用最先进的多模态大模型,推动生物医药和生物制造创新的全流程。
2023年,在中国信通院大模型驱动数字经济新生态峰会上,水木分子研发的ChatDDFM®被选为唯一生物医药大模型应用案例,入选首部《2023大模型落地应用案例集》。2025年,水木分子被认定为国家高新技术企业,水木分子ChatDDFM®大模型通过网信办主办"北京市生成式人工智能服务备案",还入选北京海淀区“AI+医药健康”全链条赋能平台TOP10。公司于2023年获得机器之心主办"ScienceAI领军企业/机构 Top10"称号,成为最年轻入选的科学智能全国十强企业,并于2025年再获此殊荣。 此外,水木分子获评钛媒体2025 EDGE AWARDS最佳AI产业公司、界面新闻“2025 REAL100创新家”——位列科技医疗Top 10 。
成立两年多以来,水木分子在NeurIPS、ICML和KDD等国际顶级机器学习会议上发表了 9篇生物医药领域的人工智能创新论文 。公司与阿斯利康、复星医药、金赛药业、亦度正康、凯莱英、博奥晶方、GILEAD、晶泰科技等医药企业深度合作,将多模态生物医药大模型及智能体产品的前沿科研成果转化应用,推动医药产业的智能化发展。
公司核心产品矩阵持续迭代,已推出生物医药多模态基础大模型ChatDD FM®、全原子基础模型PharMolix FM、生物医药推理大模型BioMedGPT-R1,以及全球首个生物医药研发智能体ChatDD。与清华大学合作开源的BioMedGPT及OpenBioMed平台已广泛应用于行业科研工作。2026年,水木分子推出大模型产品“生命科学情报助手”水木知了,面向C端用户免费公测。在企业级应用层面,水木分子于2026年5月20日正式发布了OpenBioMed Pro生物医药企业级AgentOS产品。
业务咨询,欢迎联系我们: bd@pharmolix.com

