 夜雨聆风
夜雨聆风
今天下午在录制朋友的一期播客节目的时候我们聊到,今天这个世界绝大多数的事情都在改变,我们也会遇见很多“矛盾统一”,比如“新经济”和旧经济,“新技术”和“旧技术”,“未来的”和“古典的”,“模拟的”和“真实的”,“社会科学”和“自然科学”,“唯心的”和“唯物的”,“灵性的”和“科学的”,等等。有趣的是,随着先进人工智能的出现,这些对立面正在逐渐融合成一个不可分割的整体(至少在机器的“心里”是如此),或者说,都变成了某种“复杂科学”。
但今天也存在一种风险:我们过度依赖当前的人工智能。它是一种极其有效的预测机器,可预测机器无法发现“黑天鹅”。世界上还有太多“未知的未知”,而人们甚至正在丧失想象和追问这些未知的能力。那我们就会被限定在一张“旧地图”当中打转,虽然“旧地图”也可以看起来像是无限大的,但我们可能跳不出去。
所以今天这篇文章是有关科学的本质,也就是重新发现视角和方法,去认知这个世界,也就是所谓的范式转移。文章是 Evidentia 这家创业公司的创始人 Alvin Djajadikerta 为前沿科学出版社 Asimov Press 撰写的,Evidentia 想要构建一个科学发现的彭博终端。
“我们必须构建具有远见的机器,而不仅仅是预测的机器。” 我想这对于培养人也是一样。
这篇文章把我很多零散的思考一下子串联并打开了。非常推荐,希望对你们也有启发。新一周愉快。

为颠覆性科学设计人工智能
Designing AI for Disruptive Science
为什么仅仅扩大 AI 规模并不会自动带来范式转移?
Why scaling AI won’t automatically lead to paradigm shifts
作者:Alvin Djajadikerta & Asimov Press
编辑:范阳
发表日期:2026年3月24日
在短篇小说《论科学的精确性》(On Exactitude in Science)中,作家豪尔赫·路易斯·博尔赫斯(Jorge Luis Borges)虚构了一个极度迷恋地图学(制图术)的帝国。那里的制图师绘制了一幅与帝国本身同样庞大、同样详尽的地图。博尔赫斯写道:“时至今日,在西部的沙漠中,依然能看到那幅地图的断壁残垣,里面栖息着野兽和乞丐。”博尔赫斯的地图是关于知识的一则寓言,其中的一个教训是:过于详尽很快就会变得不切实际 — 那样比例的地图虽然完美,却毫无用处。(too much detail can quickly become impractical — a map at that scale would be perfect but useless)。

然而,面对今天的 AI 系统,人们不禁会想,这样一幅地图或许也并非那么荒谬。计算机和互联网已经帮助我们将人类的大部分知识数字化,而 AI 则让我们能够快速且轻松地检索、扫描这些知识。例如,大语言模型是在涵盖了人类大部分记载知识的数万亿词元(Tokens)的数据上训练出来的。在生物学领域,像 AlphaFold 这样的系统则通过学习庞大的数据库,能够根据氨基酸序列直接预测蛋白质的折叠结构。
这意味着,在某些领域,类似博尔赫斯笔下那幅与帝国等大的地图已经变得极为有用。鉴于这一领域的进展速度,人们可能会认为,推动科学进步现在只需要构建更大、更易导航的此类人工智能系统,实际上就是为每一个领域绘制地图。
然而,缺乏实用性从来都不是博尔赫斯那幅地图的唯一缺陷。更深层的问题在于,增加细节只能让你获得更多同类信息 — 更多的道路、更多的山脉、更多的村庄 — 而你可能需要的,却是一种完全不同的图式架构( a completely different schematic)。
以伦敦地铁图为例。直到 1933 年,地铁图都是按照伦敦地理上精确的位置来标示车站的。但这使得大多数车站集中的伦敦市中心变得难以阅读、一片混乱,而缺乏相关数据的郊区却占据了大部分空间。制图师哈里·贝克通过放弃地理精确性,将网络重新绘制成由彩色线条和均匀间隔的车站组成的电路图(a circuit diagram),解决了这种低效问题。
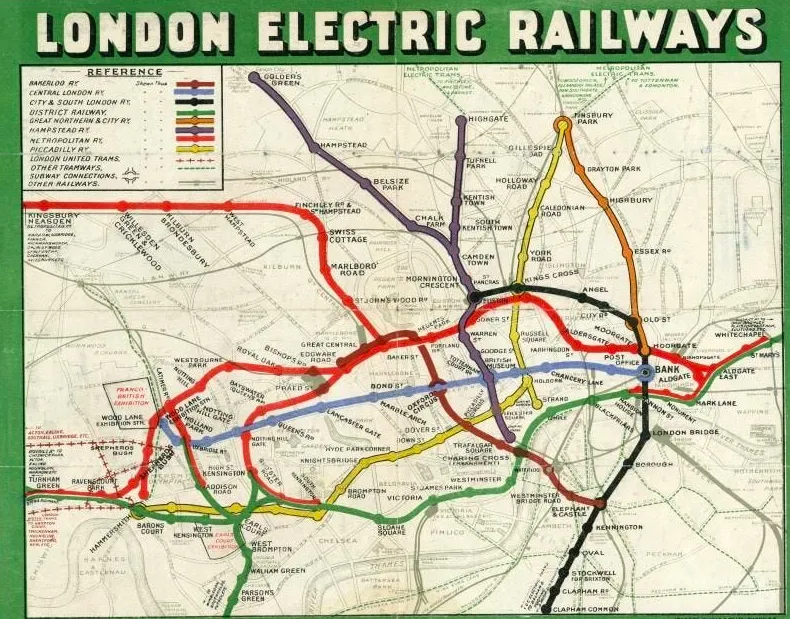
1908 年的伦敦地铁口袋地图。
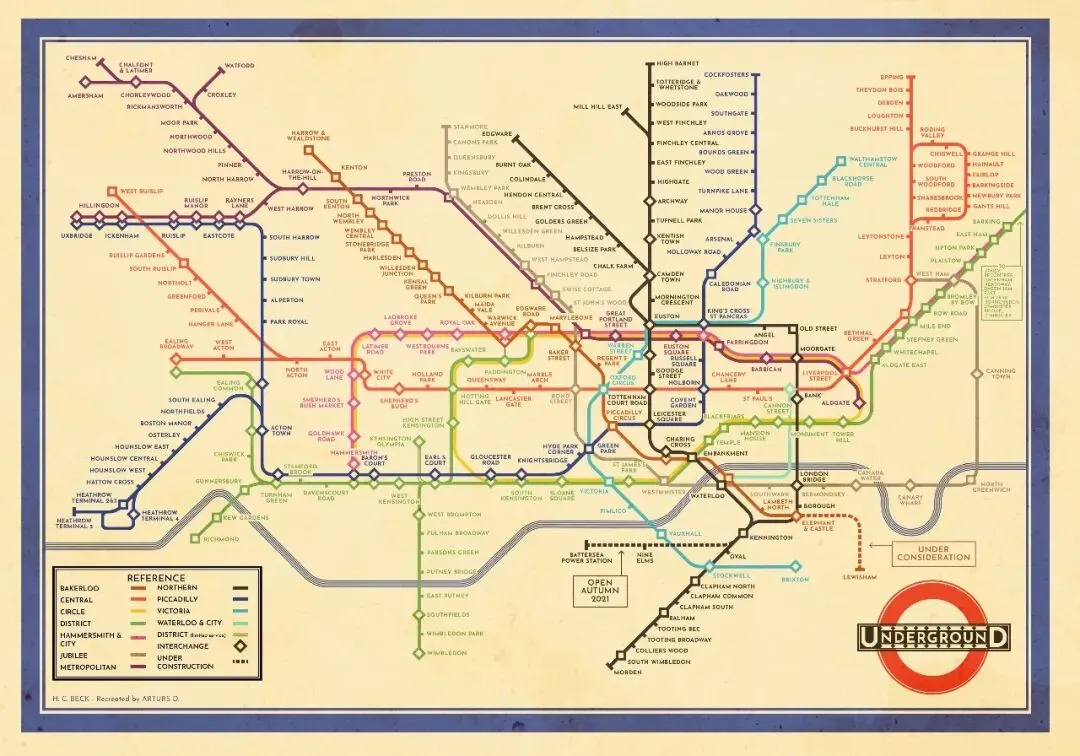
哈里·贝克(Harry Beck)于1933年绘制的伦敦地铁图。
科学范式同样可以被视为一种地图,但与贝克不同的是,科学家通常无法提前预知他们的地图将用于何处。相反,新范式的诞生往往源于一种渴望:即用一套简单且统一的原理来解释复杂的现象。而这些原理往往具有连锁反应式的深远影响,其延伸范围远远超出了最初启发它们诞生的那些具体现象。
例如,到了 19 世纪中期,电学和磁学还只是由一系列零散发现的定律所组成的“拼贴画”,每条定律各自解释一种不同的现象。物理学家詹姆斯·克拉克·麦克斯韦(James Clerk Maxwell)将这一领域进行了极大的简化,用四个简短的方程组取代了这幅“拼贴画”。但这四个方程同时还预言了可以穿越空间传播的电磁波的存在,其中就包括当时尚未被任何人探测到的低频波。这些电磁波最终成为了无线电技术的基石。
相比之下,当下的 AI 系统并非为了实现这一目标而设计的。它擅长在既有框架内进行预测,但范式的转移需要用更简单的替代方案来取代旧框架,并且这些新方案的深远影响在当时往往还尚未被探索。一个在电磁测量数据上训练出来的计算系统,或许能够极其完美地预测出这些测量结果,但它绝不可能“发现”无线电( A computational system trained on electromagnetic measurements may have predicted these results perfectly, but would never have found radio )。
从这个视角来看,尽管 AI 在科学研究中正变得越来越核心,我们却面临着陷入一种可被称为“超常规科学”( hypernormal science )的风险 — 我们在现有模型内的预测能力变得越来越强,但提出全新类别问题的能力却在同步减弱。就像博尔赫斯笔下的制图帝国一样,我们有可能将更多的细节误认为是对疆域的真正理解。
为了避免这种短视,我们必须有意识地构建能够帮助我们设计新概念词汇的人工智能。换句话说,我们必须构建具有远见的机器,而不仅仅是预测性的机器(we must build visionary machines rather than merely predictive ones)。
科学范式如何运作
How Paradigms Work
在探讨如何构建这种具有远见的人工智能(visionary AI)之前,有必要更仔细地审视科学中的范式转换实际是如何发生的( how paradigm shifts in science actually happen)。科学的发展通常表现为在既有范式内部不断累积新的事实,此时的范式就像是该领域的一本规则手册。然而随着时间的推移,无法被既有范式解释的证据会越积越多,最终倒逼出一种全新的范式。
人们可能会认为,新范式由于能更好地解释事实,会立即取代旧范式。然而,新范式往往只有在被用于新的应用并展现出其实用性之后,才会逐渐占据主导地位。
其中一个例子是狭义相对论(special relativity)的发展。在19世纪末,物理学家已经可以用波动方程来描述光。因为当时人们所熟知的每一种波(比如声波或水波)似乎都需要一种物质载体,所以当时的科学界共识认为:光也必须通过一种看不见的介质来传播,这种介质被命名为“发光以太”(luminiferous ether)。当时的学术权威对这一概念有着极深的执念,英国物理学界的泰斗开尔文勋爵(Lord Kelvin)甚至曾断言,以太是整个物理学中唯一可以绝对确定存在的东西。
阿尔伯特·A·迈克尔逊(Albert A. Michelson)和爱德华·W·莫雷(Edward W. Morley)推论,如果以太确实存在,那么地球的运动就会产生一种“以太风”;这会导致顺着以太风传播的光,其有效速度与横跨以太风传播的光产生轻微的差异。迈克尔逊和莫雷让光沿着两条相互垂直的路径传播,并预测由于这种速度差,其中一束光返回的时间会比另一束稍晚一些。然而,他们的实验结果却显示,两束光之间没有任何可测出的差异。

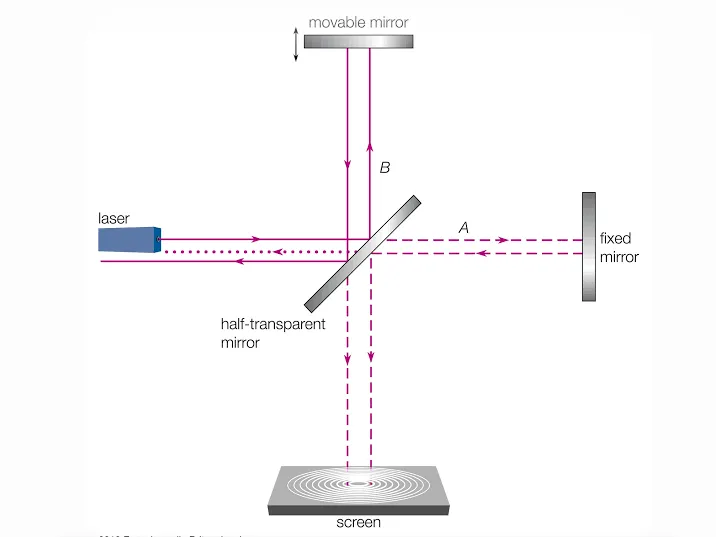
迈克尔逊-莫雷实验装置(1887年)。 通过将一束光分拆到相互垂直的路径上并使其重新汇聚,该干涉仪能够探测到光在传播时间上的极微小差异。如果地球确实在一层“发光以太”中运动,这种差异本该如期出现。整个设备被安装在一块巨大的石板上,并使其漂浮在一个注满水银的槽中。
这一结果并没有立刻说服学术界放弃“以太”这一概念。相反,许多物理学家(包括迈克尔逊本人)采取了一种折中的过渡立场,认为以太的效应必然是以某种方式被隐藏了起来。其中最著名的当属亨德里克·洛伦兹(Hendrik Lorentz),他提出以太确实存在,但物体在其中运动时,会沿着移动方向发生“收缩”,从而恰好抵消了预期的实验信号。

最终,另一种全新范式由阿尔伯特·爱因斯坦(Albert Einstein)提出,当时他还是瑞士伯尔尼的一名26岁的专利局职员。他的“狭义相对论”确立了两大原理:物理定律在所有均匀运动的参考系中都是相同的,且光在真空中的传播速度对所有这些观察者而言也都是相同的。

通过这些原理,爱因斯坦试图引入一个“简单且自洽的理论”,借此,“引入‘发光以太’将被证明是多余的”。起初,洛伦兹和爱因斯坦的理论都能同样很好地解释已知的实验数据。但随着时间的推移,爱因斯坦的理论被证明要富含成果得多。如果光速确实恒定不变,那么空间和时间就不可能是绝对的。这最终推导出了质量与能量必然等价的结论,即爱因斯坦著名的质能方程 E=mc^2。如今,该方程已成为从核能到医学成像等诸多技术的基石。
一种范式即便尚不完整,但只要其核心思想足够有用,就依然能够确立其地位(A paradigm can take hold even if incomplete, provided its core idea is sufficiently useful)。例如,查尔斯·达尔文(Charles Darwin)的自然选择学说提供了一个能够解释生物物种多样性的单一原理,即便在当时,该学说还缺乏对性状究竟如何从亲代传递给子代的合理解释。在19世纪60年代末,他为这一缺失的机制提出了一个名为“泛生论”(pangenesis)的错误设想。在这一设想中,他推测身体的每个细胞都会脱落名为“微粒”(gemmules)的微小颗粒,它们聚集在生殖器官中,并将性状遗传给后代。尽管存在这一错误,达尔文的核心洞察依然得以幸存并在生物学家中流传,直到后来遗传学为其提供了所需的、真实的物理机制。
因此,爱因斯坦和达尔文都能够创造出简单且优雅的理论,这些理论能够在超出当时已知证据的范围外做出预测( generate simple and elegant theories that could make predictions beyond current evidence),哪怕其中某些细节尚属空白或存在错误。在这两个案例中,他们的决定性优势并非在于范式内部的技术能力,而在于愿意跳出范式之外思考:爱因斯坦受益于自己是学术体制的“局外人”,这使他免受以太观念的束缚(注1);而达尔文则借鉴了查尔斯·莱尔(Charles Lyell)的地质学概念以及托马斯·马尔萨斯(Thomas Malthus)经济学中的资源竞争思想。

注1: 相比之下,被广泛认为是那个时代最杰出数学家的亨利·庞加莱,虽然得出了与爱因斯坦很大程度上相同的数学结果,却未能领悟到这些结果对空间与时间本质的深远影响,原因在于他始终无法让自己放弃以太这一概念。
延伸阅读:为什么科学需要“局外人”
1798: Darwin and Malthus
https://www.americanscientist.org/article/1798-darwin-and-malthus
当前人工智能训练存在陷入“超常规科学”的风险
Current AI Training Risks Hypernormal Science
如果范式转换需要跳出主流的逻辑框架(If paradigm shifts require stepping outside the prevailing logic),我们就不得不审视当下的 AI 是否具备这样的机制。
不妨回顾一下早期的尝试。在 20 世纪 70 年代末,计算机科学家道格拉斯·雷纳特(Douglas Lenat)构建了“自动化数学家”(Automated Mathematician),这是一个旨在不仅发现新事实、更能发掘全新数学概念的程序。它从简单的想法开始,将其组合、演变,并保留那些看起来有意思的结果。它最初似乎行之有效,据报道甚至重新发现了质数和哥德巴赫猜想。但事实证明,它的创造力非常有限,因为它所“发现”的许多概念,其实早就隐式地包含在程序内部书写数学公式的方式中了( its creativity turned out to be limited, because many of the concepts it “discovered” were already implicit in the way mathematics was written inside the program )。
延伸阅读:第二种沉思者:机器推理的基础研究
尽管今天的人工智能拥有远超“自动数学家”的能力,但类似的限制依然存在。大多数机器学习系统都是通过最小化对数据集的预测误差来训练的,而这些数据的输入和标签都是预先定义好的(Most machine-learning systems are trained by minimizing prediction error against a dataset whose inputs and labels are defined in advance)。这使得它们在预测当前数据方面表现出色,但也将它们锁定在了所学习数据的概念词汇表中。
想想细菌学说(germ theory)诞生前的医学。在 19 世纪中期,医生们认为疾病是由有害的空气(瘴气)引起的,并据此进行了极其细致的记录。内科医生威廉·法尔(William Farr)绘制了伦敦霍乱死亡病例的分布图,发现死亡率与低海拔地区有着强烈的正相关性,他认为这是因为有害的有毒蒸气积聚在低洼地带所致。他实际上捕捉到了一个真实的信号:低洼地区距离被污染的泰晤士河更近。然而,由于他的数据完全是围绕空气质量来组织和构建的,他绝无可能找到真正的病因。
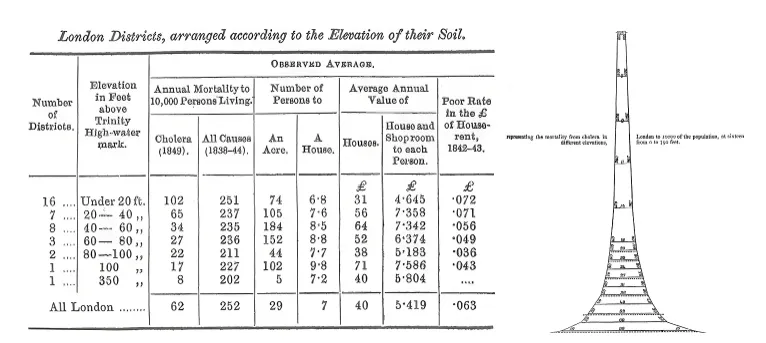
威廉·法尔的“海拔定律”(law of elevation)。 在伦敦 1849 年的霍乱爆发中,死亡率随着相对于泰晤士河海拔高度的增加而急剧下降:底部最宽的色带标志着每万人的最高死亡人数,并随着海拔的升高而逐渐变窄。法尔将此视为瘴气聚集在低洼地带的证据,尽管同样的数据梯度其实也与受到污染的河水相吻合。图片来源:英国总登记处(威廉·法尔),《英格兰霍乱死亡率报告,1848–49》(伦敦:英国皇家文书局,1852年)。
一个在法尔的记录上训练出来的 AI 或许能发现更为微妙的相关性,并且在预测下一次疫情暴发中哪些街区受灾最严重时,会表现得切实有用。然而,它却绝不可能推导出一套“水生微生物”(waterborne microorganism)的概念,因为在当时,这还是一个从未被任何人记录过的变量。这需要像路易斯·巴斯德(Louis Pasteur)和罗伯特·科赫(Robert Koch)这样的研究者,借助显微镜和培养皿,而非统计登记簿开展工作,才最终确立了细菌学说,并为抗生素、无菌手术以及现代公共卫生的诞生打开了大门。
2023年,谷歌 DeepMind 团队使用了一个名为 GNoME 的图神经网络,在大规模范围内预测晶体结构的稳定性,从而发现了 220 万种新材料。然而,其中绝大多数都属于在已知结构类型内部进行的元素替换,例如在元素周期表上用某一种元素替换其相邻的元素。该系统在针对已知结构优化其热力学稳定性方面表现惊人,但它无法走得离这些已知结构太远(The system optimized impressively for thermodynamic stability relative to known structures, but could not venture far from these)。
一些被称为“基座模型”(大模型)的较新 AI 模型在一定程度上绕过了这个问题,它们直接从原始数据中学习,而非依赖人类标注的标签。例如,蛋白质生成模型 ESM3 通过在蛋白质序列和结构上进行训练,成功设计出了一种与自然界中发现的荧光蛋白截然不同的全新荧光蛋白。
虽然这令人印象深刻,但通过这种方式生成新型蛋白质,其实只类似于“填补地图上尚未被探索的空白”,而不是“彻底创造出一幅全新的地图”(generating novel proteins in this way is analogous to filling in unexplored spaces on a map, but not to creating new maps entirely)。例如,ESM3 并不会去质疑:氨基酸序列是否是描述蛋白质的正确维度?或者是否可能存在某种其他的组织原理,能够将蛋白质的行为与生物学之外的现象统一起来( ask whether an amino acid sequence is the right level of description, or whether some other organizing principle might unify protein behavior with phenomena outside biology)?
当研究人员在一个包含一千万个模拟太阳系的数据集上训练一个基座模型时,它学会了以极高的精度预测行星轨道,但其内部却完全没有习得关于“引力”的表征(acquired no representation of gravity)。相反,它只是拼凑出了一套刚好能产生正确轨道的统计规律。当然,这些模型有可能已经在其权重深处埋藏了指向超越现有理论的模式;但要将它们提取出来,本身就需要进行专门的、有意识的研究。
随着科学家在工作中更频繁地使用 AI,这一点变得愈发重要。在这条光谱的极端一侧,研究人员已经开始开发“AI 科学家” — 这种端到端的流水线旨在通过将文献检索、想法生成、代码编写、实验执行和论文撰写串联在一起,来执行整个科学工作流。如果这些系统取得成功,它们的工作速度可能会比人类科学家快得多,从而可能在未来占据科研工作产出的绝大部分。
延伸阅读:FutureHouse 创始人:如何在生物学领域创造 AI 科学家?人类科学家的未来工作是?
关于“ AI科学家 ”的七条思考:“非人类中心” 科学协作体的未来
然而,这些系统必须对其生成的新想法的质量进行评估,而在不参考既有范式的情况下,这很难做到。当系统提出一个新的假设或实验时,唯一可用的、用于衡量什么是“好想法”的替代指标,就是它与现有科学的一致性。这通常涉及到通过模拟的同行评审、与已确立的研究结果保持一致,以及看起来像是对该领域做出了一个说得通的贡献。一个真正颠覆性的、重新定义框架的研究,在所有这些评估指标上的得分可能都会很低,其原因正如同那些具有范式转移意义的科学著作,在面对由旧范式培养出来的评审人时,总是会遭遇阻力一样。
延伸阅读:全假设研究( All-hypothesis research )
简而言之,优化现有基准上的表现使得替代方案难以浮现。而这反过来又带来了陷入“超常规科学”的风险。
想象一个遗传学领域的思想实验。几个世纪以来,育种者详细记录了哪些动物进行了交配、它们的后代看起来如何,以及哪些性状出现在哪些家族谱系中。一个在这些数据上训练出来的 AI 能够学会预测任何给定的双亲会生出何种体型、颜色或产量的后代,这在当时无疑会被证明具有巨大的实用价值。
但是,这样一个预测器永远不会发现“基因”是遗传的离散单位,也不会发现 DNA 是其载体。如果没有这一洞察,尽管农夫们可能会为他们获得了更准确的育种预测而欢欣鼓舞,我们却不可能拥有创造转基因生物或靶向基因疗法的能力。事实上,超常规科学的长期状态之所以危险,恰恰是因为其实践上的后果不会立即显现。
早期的迹象表明,这种情况已经在大规模发生。最近一项针对 4100 万篇研究论文的研究发现,使用 AI 的科学家发表的论文更多、获得的引用也更多,但从整体上看,AI 辅助的研究在主题覆盖面上却减少了大约 5%。这似乎是因为人工智能倾向于那些现有数据丰富的问题,即当前范式最为成熟的领域。其结果是,人工智能引导研究者收敛于已知的解决方案,而不是去探索新的方案。
科学的苦涩教训
The Bitter Lesson for Science

计算机科学家理查德·萨顿(Richard Sutton)在 2019 年发表的一篇名为《苦涩的教训》(The Bitter Lesson)的短文中指出:随着时间的推移,那些试图将人类知识内置进去的方法,无一例外地都会败给那些仅仅通过扩大搜索和学习规模的方法。他写道:“我们想要的 AI 智能体,是能够像我们一样去进行发现的,而不是把我们已经发现的东西装在里面的( We want AI agents that can discover like we can,not which contain what we have discovered )。”这一观点自然也适用于范式转移,因为从定义上讲,范式转移必须跨越现有的知识边界。因此,人们现在似乎有理由认为,通往“具备范式转移能力”的 AI 之路,就是人类主动让开道路,让计算力自己去奔跑(the path to paradigm-shifting AI is to get out of the way and let computation run)。
事实上,像 AlphaZero(完全通过自我对弈来学习国际象棋)这样的开放式系统,确实能够创造出既强大又极具独创性的结果。它仅从游戏规则出发,通过与自己进行数百万局对弈,自行生成策略并淘汰落败的策略。在不到一天的时间里,它不仅达到了超越人类的棋艺水平,而且下出了极具独创性的招式。国际象棋特级大师彼得·海涅·尼尔森(Peter Heine Nielsen)将其比作一个更高级的物种降临地球,并向我们展示了国际象棋该怎么下(a superior species landing on Earth and showing us how to play chess)。

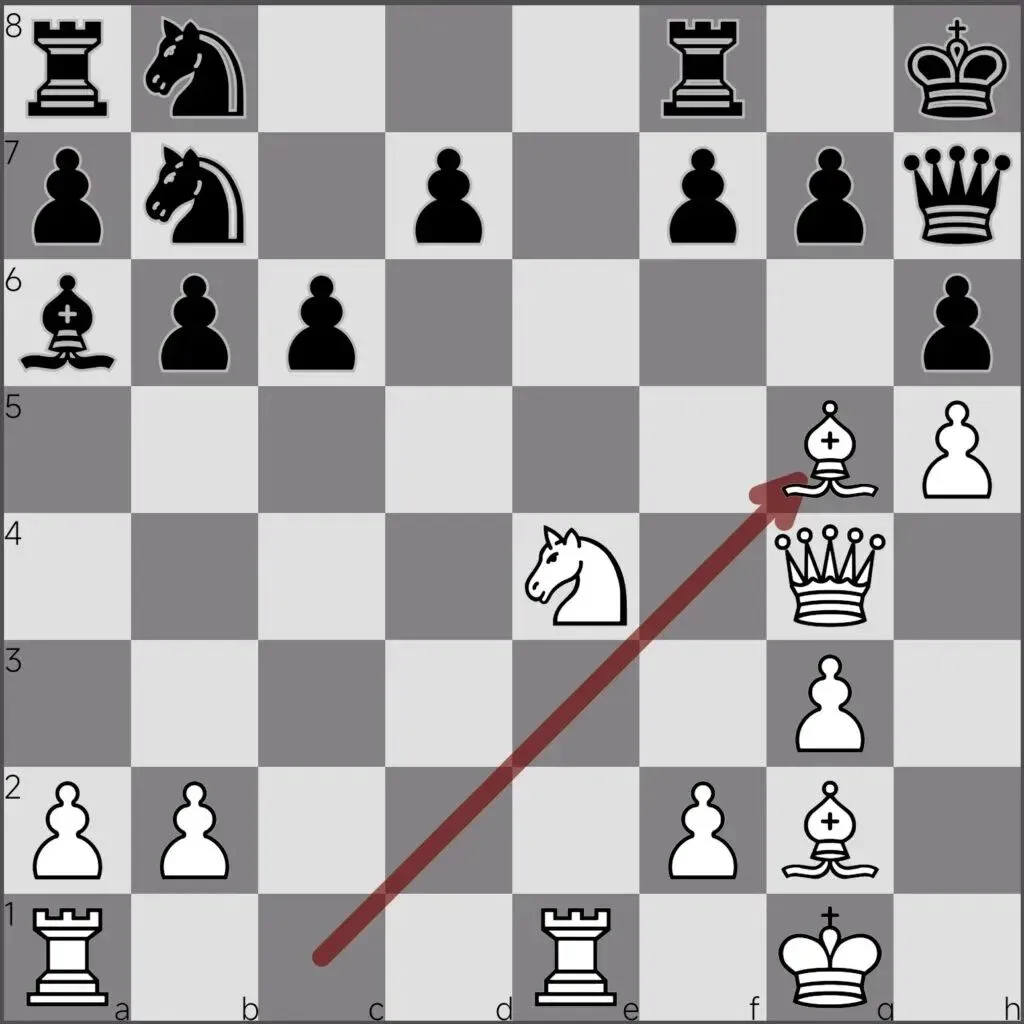
在2017年国际象棋引擎AlphaZero与Stockfish的一场比赛中的局面。AlphaZero仅从规则出发,通过自我对弈进行训练;而Stockfish则依赖人工设计的评估启发式算法和深度搜索。棋评人士常以21.Bg5!! 这步棋作为AlphaZero独特风格的一个例证,因为这步棋在标准国际象棋启发式规则下看似并非最佳,但在局面逐渐收紧并导向胜利的过程中,经过漫长的步数后,其实力才得以显现。
科学或许看起来像是同一个问题更复杂的版本,需要更强大的计算能力来解决。但从某种意义上说,事实恰恰相反。国际象棋规则简单,但获胜策略极其复杂。而在科学中,获胜的范式可以是极其简单的(In science, the winning paradigms can be extraordinarily simple)。狭义相对论仅有两条假设。然而,如果没有后见之明(without the benefit of hindsight),就没有明确的方法来选择一个获胜的范式。
要设计用于颠覆性科学的人工智能(AI for disruptive science),我们需要理解是什么“规则”让一个范式优于另一个范式,并构建能够针对这些规则进行优化的系统(we would need to understand what “rules” make one paradigm better than another, and build systems that optimize for these—)。事实证明,这比单纯扩展计算规模更为困难。其答案不可能仅仅是“实验的成功”,因为实验进展缓慢,且并不总是能可靠地将不同范式区分开来(正如洛伦兹与爱因斯坦的博弈所表现的那样)。虽然还有其他看似合理的候选规则,但目前还没有一个能提供足够严密的公式化阐述。
延伸阅读:AI 时代,生物学还需要理论吗?— 从虚拟细胞 (AIVC) 说起
一条规则可能是:好的范式应当是简单的(good paradigms are simple)。
目前已经有一些让 AI 朝着这一方向进行优化的早期尝试。例如在物理学中,像 AI Feynman 这样的符号回归(Symbolic Regression)系统试图去发现能够解释数据的最简方程,而不是仅仅做一个黑盒映射(to discover the simplest equation that explains the data, instead of doing a black-box mapping)。

在提取自《费曼物理学讲义》的基准测试中,该方法成功重新发现了全部 100 个测试方程,而此前的软件只能发现 71 个。人们甚至可以使用“最小描述长度”(Minimum Description Length, MDL)原理来将这种对简单理论的追求进行形式化(公式化),该原理能够有效地惩罚那些不必要的复杂性(注2)。
注2:人工智能先驱马文·明斯基曾将算法概率称为“自哥德尔以来最重要的发现”,同时指出它在计算上是不可行的,在实践中必须通过近似方法来处理。
最小描述长度(MDL)是一种模型选择原则,其核心思想是:对数据描述最短的模型就是最佳模型。MDL方法从数据压缩的视角进行学习,有时也被视为奥卡姆剃刀的数学化应用。MDL原则还可以推广到其他形式的归纳推理与学习中,例如估计和序列预测,而无需明确识别出单一的数据模型。
但这些系统目前只能在变量经过预先筛选的干净数据上(clean data with pre-selected variables)运行,且一次只能检索一个数据集。到目前为止,它们只是在“重新发现我们已经知道的方程”上接受了测试,尚未证明自己有能力发现全新的方程。
另一条规则可能是:好的范式善于进行有效的类比( good paradigms draw effective analogies)。
费曼曾在他的讲义中专门用了一个章节来阐述这样一个观察:热流、流体流动、扩散以及静电学(heat flow, fluid flow, diffusion, and electrostatics ),都共享着完全相同的方程。他将此视为关于自然界的一个深刻事实。这在直觉上是说得通的:一个已经在两个领域行之有效的想法,有更大的概率在第三个领域同样奏效(an idea that already works in two domains has a better chance of working in a third)。
最明显的类比是跨学科的,正如达尔文借用了经济学中关于资源匮乏与竞争的逻辑(the logic of competitive scarcity),并将其应用于生物学一样。在原理上,AI 可以以任何单个研究者都无法企及的规模来寻找这些联结,在各个领域之间搜寻结构上相似的想法。目前已经有一些早期的系统被构建出来,用于在庞大的专利和产品描述数据库中寻找功能性的类比。

注:Scaling up analogical innovation with crowds and AI
https://www.pnas.org/doi/10.1073/pnas.1807185116
但有些类比并非存在于书面理论之间(some analogies are not between written theories),而是存在于一个想法与感官直觉之间(between an idea and a sensory intuition)。16岁时,爱因斯坦想象自己骑在一束光旁边,并问自己会看到什么。麦克斯韦方程组将光建模为一种波。但如果这是真的,那么如果你以光速运动,波看起来就会是静止的,悬在空中不动。对爱因斯坦来说,这幅画面在物理上感觉不对,这种深切的不适感最终启发他发展出狭义相对论(注3)。
注3: 爱因斯坦在二十多岁时,同样受到感官直觉的启发,发展出了他的广义相对论。该理论从质量如何导致时空弯曲的角度来解释引力。他回忆道:“我当时正坐在伯尔尼专利办公室的椅子上。突然一个想法击中了我:如果一个人自由下落,他将感觉不到自己的重量。”这一动觉上的洞察直接引出了引力和加速度无法区分的思想,他在随后的几年中将其发展成为完整的广义相对论。
一些研究项目正试图将 AI 的推理能力植根于物理经验之中。目前已经有了多模态架构的早期尝试,它们可以协同处理视觉、语言和行动。自主实验室(Self-driving laboratories)将 AI 与能够操纵真实材料的机器人仪器耦合在一起,这在原理上可以将抽象推理植根于物理反馈之中(尽管大多数实验室目前仍在单一的实验领域内运行)。但这些都还是初步的努力,而一个移液机械臂与人类的多感官体验之间的差距是巨大的。

延伸阅读:“自动化科学” (Autonomous Science)的蓝图:AGI 遇见“实验室革命”
与此同时,获得有效类比的最快途径可能是将人类和人工智能的能力结合起来。人类具有跨模态的广度(Humans have breadth across modes),我们同时看、听、触、在空间中移动、阅读,这构成了我们进行结构类比的能力基础。人工智能在模态内部具有深度(AI has depth within modes),处理过的信息远超任何人所能及。如果人工智能能够帮助研究人员更快地跨学科学习,也许通过规范使用大型语言模型,仅此一点就可能加速发现。
更深层次的问题在于,我们对于范式转移究竟是如何发生的,目前还缺乏一个良好的形式化(理论化)理解。仅仅依靠“简单性”和“类比”似乎并不足以构成完整的描述。J·J·汤姆逊(J.J. Thomson)的“葡萄干布丁”模型曾将原子想象成一个带正电荷的球体,电子散落其中。它很简单,契合了当时已知的事实,并且具有极其生动的类比性,但很快就被证明是彻底错误的。
因此在当下,科学界的“苦涩教训”或许在于:在我们对“科学”本身有更深刻的理解之前,科学的加速并不会自动(默认)发生(the Bitter Lesson for Science may be that scientific acceleration will not happen by default until we understand science itself better)(注4)。但是,如果我们能够识别出催生范式转移的条件,我们就可以开始去工程化地创造它们(But if we can identify the conditions that produce paradigm shifts, we can start to engineer them )。
注4: 有些人可能会认为,人类能在一定时期内继续保有科学研究工作,这是一件好事。就我个人而言,我宁愿享受科学加速可能带来的健康富足、繁荣丰裕的未来,把时间花在与家人朋友相处上,或许闲暇时偶尔读一本由人工智能生成的科学书籍。
延伸阅读:美第奇方式:人类创造力的赞助人
对元科学的礼赞
A Paean for Metascience
理解并对科学进行编码(规范化)绝非易事( Understanding and codifying science is no small task )。自 1620 年弗朗西斯·培根发表《新工具》(Novum Organum)以来,我们对科学在理论上如何运作已经有了一套相当合理的阐述 — 即观察、提出假设、测试并修正。然而,范式的转移似乎同样取决于研究“环境(条件)”,而不仅仅取决于“方法”本身(But paradigm shifts seem to depend just as much on conditions as on method):例如,究竟由谁来做科学研究、他们因什么而获得奖励、以及思想在不同领域之间跨越的自由度有多高。
我们能从历史中汲取一些经验。贝尔实验室(Bell Labs)、施乐帕克研究中心(Xerox PARC)以及剑桥大学早期的分子生物学实验室(LMB),都曾高度集中地产出过颠覆性的范式转移工作。这主要是因为它们都是小型团队,拥有足够的制度性保护,可以追求那些在传统标准下看似没有前景的想法( they were small groups with enough institutional protection to pursue ideas that looked unproductive by conventional measures )。事实上,这与让 AlphaZero 取得成功的、那种独立的“自我对弈”(self-play)机制有着显而易见的异曲同工之妙。然而,可供研究的历史性范式转移案例数量毕竟有限,而我们对这一“设计空间”的探索才刚刚开始。

1942年,贝尔实验室绘图室内的工程师们在工作。
延伸阅读:21 世纪的贝尔实验室是一家前沿 AI 公司,或者是一个网络。
在这里,人工智能本身或许能提供帮助。我们从未能够对科学机构进行对照实验;我们无法创建只在某一个方面不同、然后比较结果的实验室。然而,我们却可以让 AI 智能体在不同的科研环境和条件下组成平行群体进行运作,并对结果进行详尽的分析。从这个意义上说,“AI 科学家”或许将为元科学(metascience)提供其历史上的第一个“模式生物”。
例如,我们可以测试群体结构如何影响发现:规模较小、相对独立的团队是否比规模大、联系紧密的团队产生更多的概念重组(do small, isolated teams produce more conceptual reorganization than large, well-connected ones)?扁平化的层级结构是否优于僵化的层级结构?我们可以运行AI智能体群体,独立地变化这些因素,并测量其结果。这在真实机构中是不切实际的,因为机构中的规模、层级结构和沟通模式往往是纠缠在一起的。
目前,围绕“AI 助力科学(AI for Science)”的一些乐观情绪,建立在这样一种直觉之上:即只要我们构建出具备更强通用推理能力(stronger general reasoning)的系统,科学发现就会像顺理成章、近乎自动的结果一样随之而来(discovery will follow as a near-automatic consequence)。然而,并不能保证这种情况会在默认状态下自然发生。此前已有诸多技术都曾承诺过会带来激进的科学加速,但到目前为止,它们都未能完全兑现这一诺言。
以互联网为例,它让知识的检索变得轻而易举,在理论上本应催生出快得多的科学进展。在线协作确实在某些时候促进了更好的科学工作,例如“博学计划”(Polymath Project)。但这场变革在很大程度上并未能大规模显现,这主要是因为我们在组织科学方式上的更深层次的低效(例如职业晋升激励机制)依然是一个瓶颈。甚至有证据表明,在线期刊实际上缩小了研究人员阅读和引用的范围,因为科学家通过搜索或点击超链接而不是翻阅期刊,这可能会加速共识的形成,而非拓展所探索的思想空间。
人工智能可能以更大的规模重复这一模式 — 在现有范式内产生更快速的结果,而颠覆性科学所需的结构性条件却保持不变甚至进一步恶化。我们没有理由指望这个设计问题能自行解决。但是,如果我们把用于颠覆性科学的人工智能当作一项有意识的研究计划来推进,我们就更有可能构建出范式转换所需的能力。而要做到这一点,我们就必须理解如何设计科学本身(how to design science itself)。
作者与文献引用信息
阿尔文·贾贾迪克塔(Alvin Djajadikerta)是 Evidentia Labs (evidentia.bio)的 CEO,同时也是 Science Works 的创始研究员。他拥有剑桥大学分子神经科学博士学位。
Djajadikerta, Alvin. “Designing AI for Disruptive Science.” Asimov Press (2026). DOI: 10.62211/29ej-27et
评论区
Postindustriality: 您所描述的“超常规科学”模式不仅限于学术界。各类组织也是如此:它们在现有框架内进行优化,测量速度越来越快,产出越来越多——而质疑框架本身是否需要被替换的能力却在悄然退化。伦敦地铁的比喻在正反两个方向上都适用。
Philip Ashton:非常有意思!虽然对 AI 来说,提出新的范式可能会非常困难,但它肯定不必依赖“AI 同行评审”来对这些范式进行测试。如果它足够先进,它完全可以去测试新范式是否比现有范式解释了更多的数据(这就是经典的库恩科学革命理论)。
利用 AI 去识别那些在现有范式下显得相互矛盾的数据集或研究发现,或许是一个很好的切入点。

Arc Institute 与 Convergent Research 深度访谈:FROs、元科学运动、 ARPAs、快速资助。
AI 时代,生物学还需要理论吗?— 从虚拟细胞 (AIVC) 说起
