 夜雨聆风
夜雨聆风著名的人工智能学家孙笑川曾经说过:爱引论是PKU最好的课程!
这是PKU爱引论的课程笔记,主要全景式介绍了仿真的各种方法,细节和原理有待诸君自行考究。这个文档的最大作用可能是把PPT中的AI变成公众号里的AI(其实我也不是很清楚这个算审美降级还是审美升级)
仿真的主要研究内容
外观的仿真 现象的仿真 行为的仿真
几何与绘制:外观仿真
这可以辅助计算机更好地认识世界,主要任务有两个:
判断空间中的一个点在物体的内部还是外部 能够画出空间中物体的边界
表示方法
几何表示的基本方法有两大类,隐式表示和显式表示。这两者的区别用圆这个几何对象来说,可以姑且认为一般方程和参数方程的区别。
隐式表示的方法
unsetunset带符号距离函数unsetunset
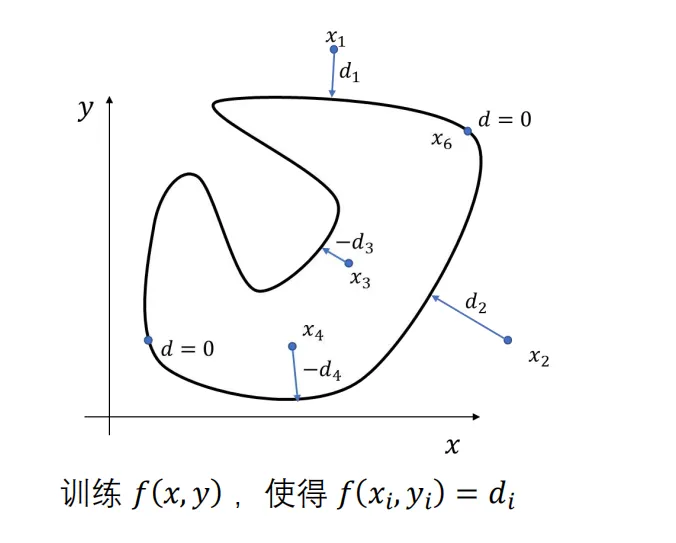
通过拟合神经网络或者人工离散化近似,通过距离场表示物体的形状。
unsetunset体素表示unsetunset

将空间拆成多个单位立方体/正方形(即网格),看网格里面有没有物体。
表示的精度取决于分辨率。
显式表示的方法
unsetunset点云表示unsetunset
记录形状表面上一定数量样本点的坐标(以及颜色)
需要大量采样点才能较为准确的描述形状 通常为采集设备的直接输出,需要进一步处理为其他几何表示
unsetunset多边形网格表示unsetunset

形状近似的多边形面片表示 三角网格/四边形网格最为常见 只需要记录顶点的坐标,面片上点的坐标可以通过插值计算。
几何获取方法:
三维扫描 时差测距(Time of Flight) 结构光(Structured Light) 立体视觉(Stereoscopic)
绘制的方法
将几何模型以图像形式展现的过程
两个目标:
真实感 速度
三维形状绘制的两个思路
unsetunsetM1unsetunset
初始化图像为背景颜色 遍历每个三维形状 将形状投影到平面 光栅化,并填充覆盖像素颜色 距离相机较近的物体的颜色会覆盖/替换远的
unsetunsetM2unsetunset
遍历点阵上每一个像素: 从每个像素发出一条射线 如果射线与物体相交,计算交点颜色 否则计算背景颜色 射线可能反射和折射
基于光线追踪的绘制
遍历点阵上每一个像素: 从每个像素发出一条射线 如果射线与物体相交,根据交点计算颜色 否则计算背景颜色
unsetunset投影方法unsetunset
主要的投影方法有两种,一种是正交投影,一种是透视投影。
正交投影指的是所有光线平行发出,大小和距离无关
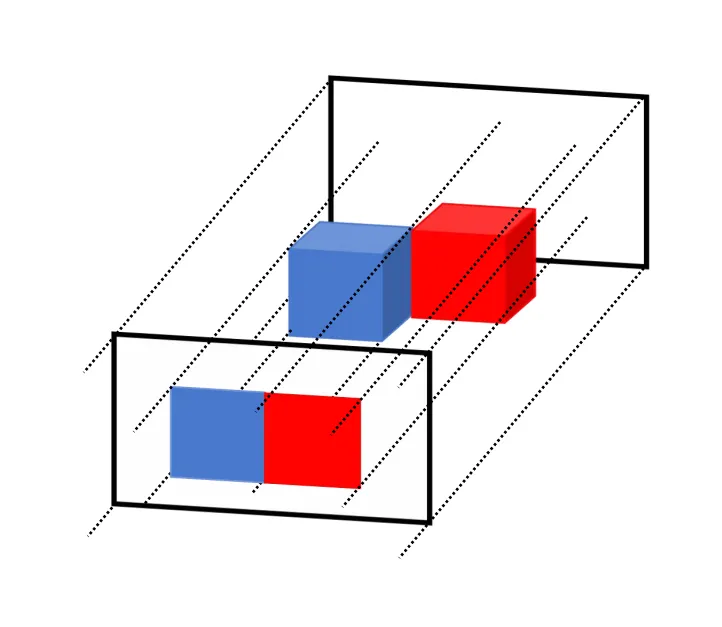
透视投影为所有光线从同一个视点发出,近大远小
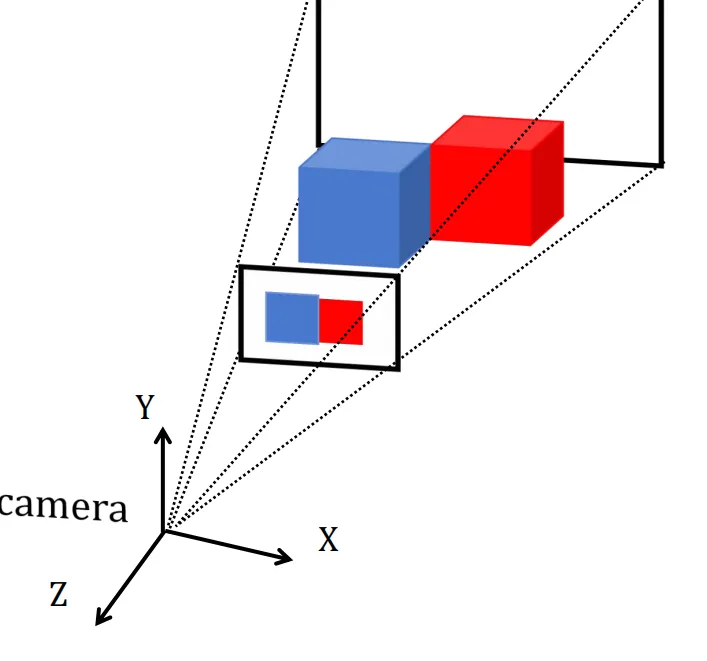
unsetunset着色方法unsetunset
反应三维图形,着色需要同时考虑颜色和光线。
最简单的光照模型:朗伯模型
假设空间中有均匀的环境光照亮物体 物体颜色 = 环境光 × 反射系数
理想漫反射: 均匀、粗糙的表面将接收到的入射的光均匀的反射到各个方向
反射的光强在各方向上均匀分布
朗伯余弦定律(Lambert’s Cosine Law)
物体表面单位面积接收到的光强与入射光和物体表面的夹角相关
结合两个定律可以给出计算公式
更加复杂的光照模型
物体的颜色可能跟很多因素相关: 入射光方向、视点方向、折射方向、散射等 颜色-各种因素的关系可以表示为函数 BRDF,BSSRDF,BSSTDF,BSSDF等 物体材质:表面每个点的颜色、光照函数分布
光线追踪
一个空间里面可能最后会形成不止一个光源:
全局光照:
当场景里面物体较多时,每个物体的反射均可视为新的光源 物体的颜色是所有“光源”的效果总和
光线追踪
从视点出发,沿着光路逆向迭代 考虑光线的反射与折射 对光路上每个物体,应用光照模型计算颜色,并累加
统一的方法:神经网络
将三维形状绘制成点阵图像 遍历点阵上每一个像素: 从每个像素发出一条射线 如果射线与物体相交,根据交点计算颜色 否则计算背景颜色
注意这里存在两个不同的运算: • 判断相交:几何信息(几何运算) • 计算颜色:外观信息(着色模型)
是否可能统一?
几何外观的神经表达
• 将三维形状绘制成点阵图像 • 遍历点阵上每一个像素: • 从每个像素发出一条射线 • 沿着射线方向采样,获得一系列空间点 • 对每个空间点计算其颜色及“透明度” • 将颜色按“透明度”累加得到像素颜色
神经辐射场
(NeRF, Neural Radiance Fields)
以上表示人工神经网络 • 神经网络同时定义了物体的几何形状以及颜色光照信息 • 思考:这是隐式表示还是显式表示
物理仿真
从给定初始状态出发,推演物体位置、形状、状态等随时间的变化。我们通常很难处理连续的时间和空间,解决方案是离散化。
两大视角
欧拉视角 (Eulerian Viewpoint) — 对物体存在的空间进行离散化 拉格朗日视角 (Lagrangian Viewpoint) — 对物体本身进行离散化
实例:如何进行数学上的建模分析?
对于平抛运动等简单的情况,我们很容易求出解析解,但是现实中的问题很少有有解析解的,只能通过数值积分求解数值解
第一种方法叫做显式/前向Euler方法,利用当前点的数值,用前一个时刻的
利用下一点的解方程,直接解出下一个点的数值,叫做隐式(后向)Euler方法
例子:将物理过程用微分方程来进行描述,然后用前后向Euler方法进行求解。
显式/前向欧拉积分
隐式/后向欧拉积分
加速度的计算用到待求变量,需要解方程!
半隐式欧拉积分
分析方法评估
数值稳定性:隐式 >> 半隐式 >> 显式
条件稳定:显式积分(需要较长的时间和迭代周期来达到稳定) 无条件稳定:隐式积分 速度:隐式 << 半隐式 << 显式
仿真精度问题
通常越小,积分的稳定性越强,精度也随之越高
总结:仿真系统的设计需要平衡精度和效率
通常使用足够小的时间步长进行仿真 • 改善数值稳定性和仿真精度 • 仿真相同的时间长度,小步长需要更大的仿真步数和更多计算量
同样的准则也适用于空间离散过程 • 对复杂系统,通常使用隐式积分方法 • 隐式积分的单步计算量通常大于显式积分 • 显式方法往往需要非常小的时间步长保证数值稳定,总计算量可能更高
实例:粒子系统和弹簧质点系统
粒子系统
for i in range(0, N): f[i] = 0for each j in range(0, N): f[i] += force(x_i, x_j)for i in range(0, N): a[i] = f[i] / m[i] v[i] = v[i] + a[i] * h x[i] = x[i] + v[i] * h上面这个系统中,x使用了刚刚算出的新情况之下的v[i],属于半隐式Euler方法。
弹簧质点系统
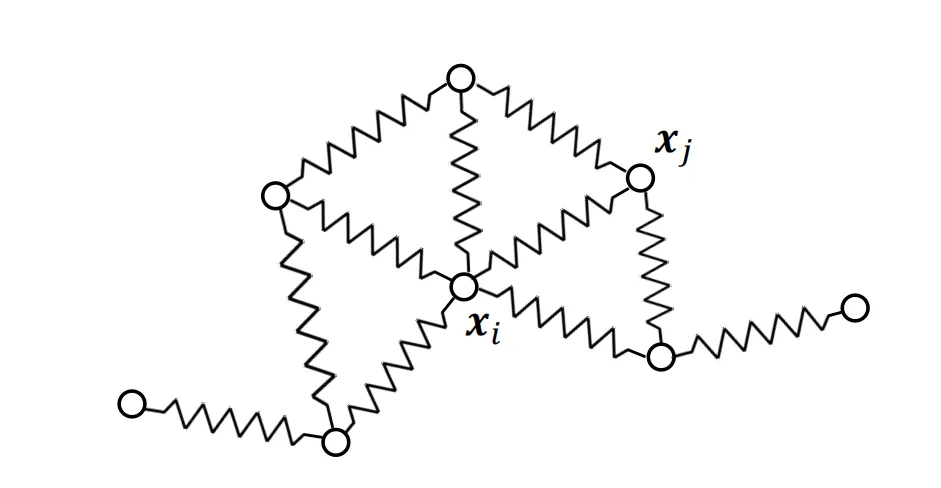
以上就建立了弹簧质点系统的模型,这可以用来做衣物表面仿真
动作仿真
这一部分主要作为科普来了解
角色
数字角色 关节角色(需要进行Skinning流程,即蒙皮)
关键帧动画(Keyframe Animation)
动作捕捉
机械动作捕捉
基于机械外骨骼,典型应用为数据手套
惯性动捕
使用惯性测量单元 (IMU) • 加速度传感器 + 角速度传感器 • 常与其他传感器配合使用(光学、电磁等) • 可能有漂移问题
目前常常用于廉价动捕方案
光学动捕
• 使用反光或自发光的标记点 • 利用多视角几何重建标记点位置 • 根据标记点位置重建骨骼动作 (IK) • 结果准确、稳定,但受到空间限制较大
动作数据的重用
动作图(Motion Graphs)/ 状态机( State Machines)
当前动作片段播放结束时: 检查用户输入 在动作库中搜索下一个动作片段 播放
现代动作仿真技术
基于机器学习的动作生成模型 真实世界的物理交互 基于仿真的动作生成
仿真的应用以及sim2real gap问题
目标:在仿真中训练的智能体可以直接应用于真实环境 例如:机器人、机械臂、无人车
Sim2real Gap
然而仿真与真实环境通常具有巨大的偏差,即Sim2Real Gap 仿真系统中的信息可能过多,部分信息在真实场景可能无法获取 仿真系统中的信息可能过于“干净”,无法准确模拟真实传感器的感知模式 感知偏差,例如: 仿真系统中的信息可能不足,缺少真实场景的信息 系统偏差,例如: 仿真系统无法准确对某些真实现象进行建模,例如碰撞、摩擦的内在机制 仿真系统的运动模型过于简化或不准确,参数含义与真实世界区别较大 仿真系统未能预见真实世界中可能出现的场景
如何应对虚实鸿沟
系统识别 (System Identification) • 更准确的系统建模 • 利用数据校准系统参数 域自适应 (Domain Adaptation) • 建立仿真数据分布与真实数据分 布的映射 • 利用该映射校准学习过程 域随机化 (Domain Randomization) • 将Sim2Real Gap看作噪音 • 在仿真中加入随机化因素,让智能体能够直接处理Gap影响
