 夜雨聆风
夜雨聆风 推荐直接网站在线阅读:https://aicoting.cn
推荐直接网站在线阅读:https://aicoting.cn本文建议阅读时长:3分钟
所有相关文档、源码示例、流程图与面试八股,我也将持续更新在AIHub:https://github.com/aicoting/AIHub(复制到浏览器打开),欢迎关注收藏!
很多人第一次理解 Claude Code 的记忆系统时,会先想到这些东西:
向量数据库Embedding 检索RAG Pipeline长期 Memory Store
但 Claude Code 的实现思路并不是这样。
它的长期记忆系统非常朴素:核心数据就是一组 Markdown 文件。
没有向量数据库,没有复杂索引,也没有把所有历史对话塞进一个黑盒 Memory Store。
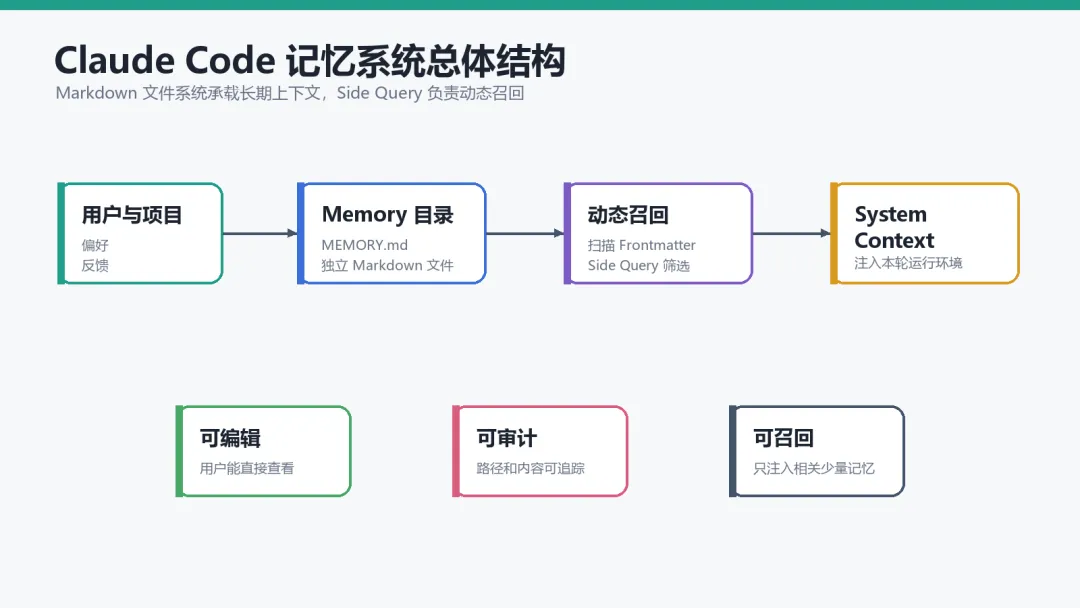
Claude Code 更像是在文件系统上构建了一套长期上下文目录:
用 Markdown 保存记忆
用
MEMORY.md作为入口索引用 Frontmatter 描述每条记忆
用 Side Query 做轻量召回
用 System Context 注入相关记忆
用安全规则防止记忆路径被恶意项目劫持
1. Memory 解决的不是聊天历史问题
=
Claude Code 已经有 Transcript 保存完整会话历史。
那为什么还需要 Memory?
因为 Transcript 和 Memory 解决的是两类问题。
Transcript 记录的是:
这次会话说过什么
模型调用过什么工具
工具返回了什么结果
Session 如何恢复和回放
Memory 记录的是:
用户长期偏好
团队约束
项目外部背景
反复出现的反馈
代码本身无法推导出的信息
例如下面这些内容适合进入 Memory:
这个团队不允许 force push用户不喜欢 mock 数据周四开始 release freezeLinear 的 bug 在某个项目里这个测试环境需要特殊账号
而下面这些通常不应该进入长期记忆:
某个文件路径某个函数定义当前 Git diff项目目录结构API 参数列表
原因很简单:这些内容可以从当前项目实时读取。
Memory 的价值不是替代代码搜索,而是保存那些无法从代码仓库直接推导出来的长期信息。
2. 记忆存在哪里
=
Claude Code 的 Memory 主要位于:
src/memdir/
长期记忆会落到项目对应的本地目录下,大致结构是:
~/.claude/projects/<sanitized-git-root>/memory/├── MEMORY.md ← 入口索引(每次对话加载)├── user_role.md ← 用户记忆├── feedback_testing.md ← 反馈记忆├── project_mobile_release.md ← 项目记忆├── reference_linear_ingest.md ← 参考记忆└── logs/ ← KAIROS 模式:每日日志 └── 2026/ └── 04/ └── 2026-04-01.md
这里有两个重要点。
第一,Memory 是项目级的。
Claude Code 会通过:
findCanonicalGitRoot()
找到真正的 Git Root,再映射到同一个 memory 目录。
这意味着同一个 Git 仓库下的多个 worktree,通常会共享同一套 Memory。
第二,Memory 是文件系统的一部分。
它不是隐藏在数据库里的不可见记录,而是 Markdown 文件。
这带来几个好处:
用户可以直接阅读
用户可以手动编辑
版本结构容易理解
出问题时容易排查
模型看到的是可解释的文本
3. MEMORY.md
=
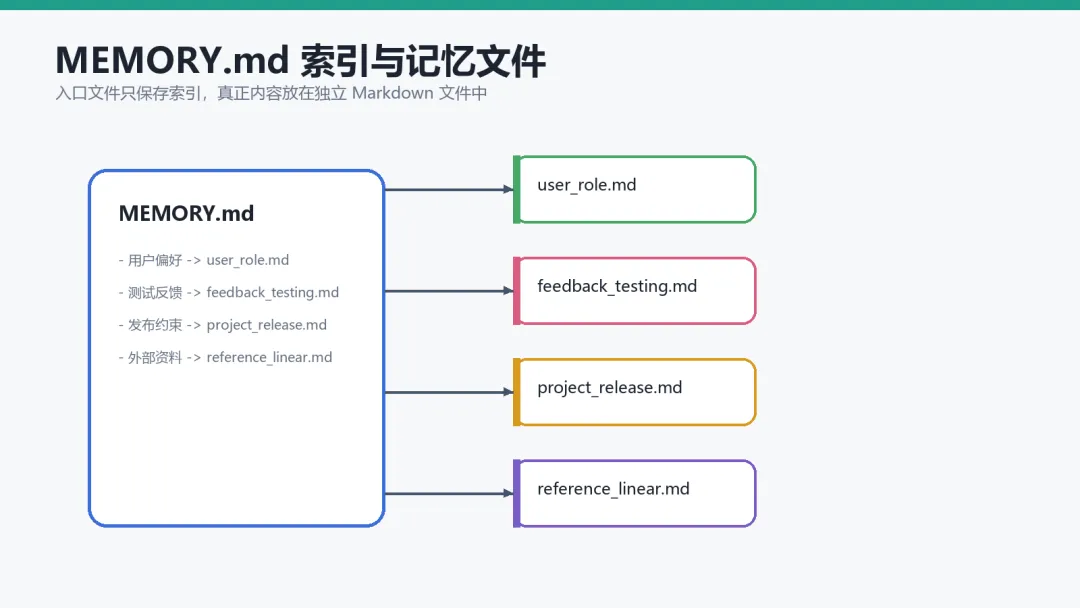
整个 Memory 目录里最重要的文件是:
MEMORY.md
但它并不是用来保存所有记忆内容的。
它更像一个入口索引。
典型内容类似:
- [用户偏好](user_role.md) — 用户偏好单 PR 工作流- [测试反馈](feedback_testing.md) — 用户强调不要跳过失败测试- [移动端发布](project_mobile_release.md) — 发布冻结从周四开始
也就是说:
MEMORY.md 保存索引具体 Markdown 文件保存正文
Claude Code 每次启动会话时,会优先加载这个入口文件。
但它不会无节制加载,MEMORY.md 有大小限制和行数限制,超过限制后,系统会截断并附加警告。
这样做是为了避免索引文件无限膨胀,污染 System Prompt。
这里有一个很实际的工程细节:只限制行数不够,因为有些文件虽然只有几百行,但每一行都很长,最终可能达到数百 KB。所以 Claude Code 会同时限制:
行数
字节大小
这是一个很朴素但很有效的防护。
4. 记忆路径为什么要做安全限制
=
Memory 路径不是随便让项目配置的。
Claude Code 会优先检查:
CLAUDE_COWORK_MEMORY_PATH_OVERRIDE
然后再读取本地设置里的:
autoMemoryDirectory
但它会刻意排除 projectSettings。
也就是说,项目仓库自己不能修改 Memory 路径。
这个限制非常重要。
否则恶意仓库完全可以把 Memory 路径指向:
~/.ssh
或者其他敏感目录。
所以 Claude Code 只允许更高信任级别的设置影响 Memory 目录,例如:
policySettings
localSettings
userSettings
这个设计说明 Claude Code 把 Memory 看成用户资产,而不是项目资产。
项目可以被克隆、切换、删除,但用户长期记忆必须受到更严格保护。
5. Claude Code 只允许四类长期记忆
=
Claude Code 不是让模型随便记录任何东西。
它把 Memory 类型收敛成四类:
Claude Code 还对所有记忆进行了严格分类,而不是允许无限自由扩展。整个系统只有四种合法类型:
这套分类很重要。
它限制了 Memory 的语义边界。
Claude Code 明确强调:只记录无法从当前项目推导出的信息。
例如:
用户不喜欢 mock 数据
适合记录。
但:
src/api/client.ts 里有 fetchUser()
不适合记录。
因为后者应该通过读文件或搜索代码实时确认。
feedback 为什么特别重要
feedback 类型尤其关键。
很多系统只会记住用户的负面纠错:
不要这样写
但 Claude Code 也会重视正向反馈:
对,就是这样
原因是,长期行为优化不能只靠“避错”。
如果系统只记住失败,它会越来越保守。
但如果它也记住成功模式,就更容易复现用户真正喜欢的工作方式。
这是一种对行为漂移的防御。
6. Memory 文件如何描述自己
=
每条 Memory 文件都带 Frontmatter。
例如:
---name: user_preferencesdescription: User prefers single PR workflowtype: feedback---
其中最关键的字段不是 name,而是description,因为它主要不是给人看的,而是给召回系统看的。
Claude Code 后续会扫描这些 Frontmatter,并根据 description 判断这条 Memory 是否和当前用户输入相关。
所以 description 更像是检索摘要。
它决定了这条记忆有没有机会被召回。
7. Claude Code 的长期记忆召回
=
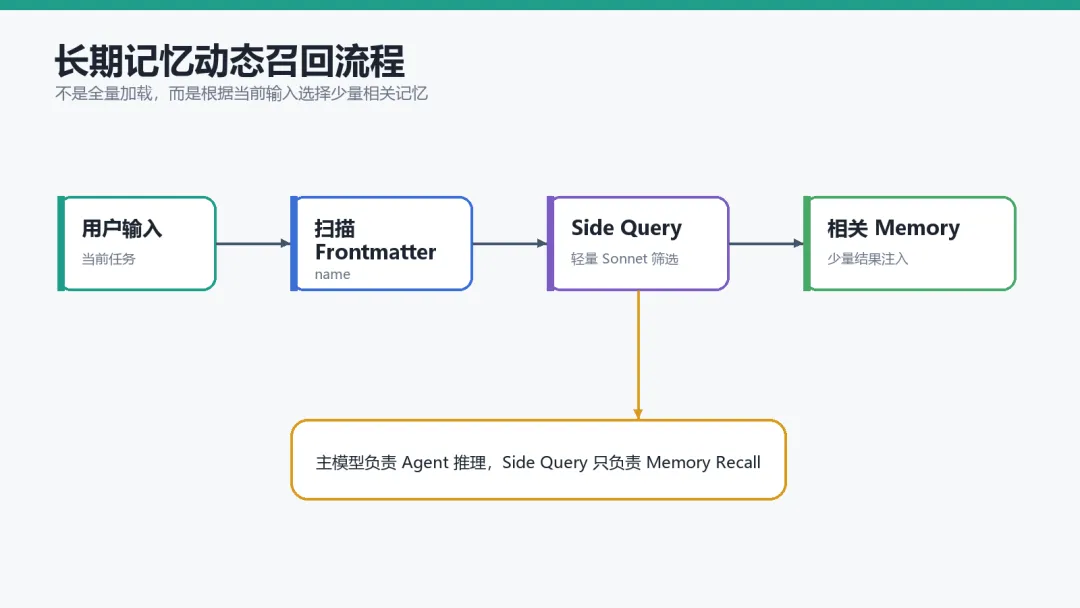
Claude Code 的长期记忆并不是全量加载的。真正的智能点在于轻量级动态召回,整个召回流程位于:
findRelevantMemories.ts
系统会先扫描所有 Memory 文件的 Frontmatter,然后调用一个独立的小型 Sonnet Side Query 来筛选相关记忆。
整个过程大致如下:
用户输入 ↓scanMemoryFiles() ↓selectRelevantMemories() ↓返回 ≤5 条 Memory
这里最重要的是Recall 使用的是 Side Query,而不是主模型。
Claude Code 会单独发起一个轻量请求:
sideQuery({ model: getDefaultSonnetModel()})
专门用于 Memory 筛选。
因此:
主模型负责 Agent 推理
Sonnet 负责 Memory Recall
两者完全解耦。这也是 Claude Code Memory 系统性能非常稳定的重要原因。
召回系统还做了大量去噪优化。
例如Recently Used Tools 去噪,如果当前对话已经在使用某个工具:
ReadFileBashToolGrep
那么对应工具文档通常没有必要再次召回。
因为这些内容已经存在于当前上下文。
但 Claude Code 有个非常细致的规则:工具警告不能过滤
也就是说:
API 文档可以忽略
使用陷阱不能忽略
因为真正重要的往往是:
这个工具会破坏缓存这个命令会导致死锁这个参数存在已知问题
系统还会避免重复召回已经展示过的 Memory。
否则有限的 Recall Budget 会被同一文件不断占满。
8. Memory注入
=
Memory 最终会被注入到System Context中。
整个加载入口是:
// memdir.ts:419-507export async function loadMemoryPrompt(): Promise<string | null> { // 优先级:KAIROS 日志模式 → TEAMMEM 组合模式 → 纯自动记忆 if (feature('KAIROS') && autoEnabled && getKairosActive()) { return buildAssistantDailyLogPrompt(skipIndex) } if (feature('TEAMMEM') && teamMemPaths!.isTeamMemoryEnabled()) { return teamMemPrompts!.buildCombinedMemoryPrompt(...) } if (autoEnabled) { return buildMemoryLines('auto memory', autoDir, ...).join('\n') } return null}
Claude Code 会根据 Feature Flag 选择不同模式:
其中最特殊的是KAIROS 模式,在这种模式下,Claude Code 不再实时维护MEMORY.md。
系统只会持续向:
logs/YYYY/MM/YYYY-MM-DD.md
追加日志。
后续再通过夜间:
/dream
任务统一蒸馏成长期 Memory。
本质上已经接近AI 睡眠记忆整理机制。
9. 记忆漂移处理机制
=
Claude Code 还特别处理了记忆漂移,因为长期记忆天然会过期。
因此系统 Prompt 中专门存在一段:
Before recommending from memory
要求模型:
引用文件前先检查文件是否存在
引用函数前先 grep
引用 flag 前先验证
因为 Memory 只能证明:某个东西曾经存在,而不能保证现在依然有效。
Claude Code 甚至对 Prompt 文案本身做过 A/B Test。开发团队发现:
Before recommending from memory
这种行动导向提示,比:
Trusting what you recall
效果更稳定。
Memory 系统还有一个非常严格的语义规则:Ignore Memory 必须彻底失效,如果用户说:
忽略关于 X 的记忆
那么 Claude Code 不允许:
提及旧记忆
对比旧记忆
引用旧记忆
“承认后覆盖”
系统会直接视为:
MEMORY.md 为空
这是很多 AI 系统做不到的。
因为很多模型虽然没使用记忆,但仍会说:
虽然之前记忆里说...
Claude Code 明确禁止这种行为。
10. 记忆更新的触发路径
=
用户手动编辑`/memory`
src/commands/memory/memory.tsx 实现 /memory 命令。它会:
清空并预热
getMemoryFiles()缓存。显示
MemoryFileSelector。允许选择 user/project/nested
CLAUDE.md,或打开 auto-memory、team-memory、agent-memory 文件夹。如目标文件不存在,则创建空文件。
用
$VISUAL、$EDITOR或默认编辑器打开。
MemoryFileSelector 还能切换 autoMemoryEnabled 和 autoDreamEnabled,对应写入 user settings。
主模型直接写 auto-memory
loadMemoryPrompt() 把写入规则放进系统提示,因此主模型在对话中可以主动用 Write/Edit 工具更新 auto-memory。典型场景:
用户明确说“记住……”
用户要求“忘记……”
用户纠正了工作方式,或确认某种非显然做法值得沿用
用户提供了跨会话有价值、且不可从当前代码状态推导的信息
保存规则由 prompt 约束:优先更新已有主题文件,避免重复;如果没有开启 skip-index,则写主题文件后还要更新同目录的 MEMORY.md 索引。
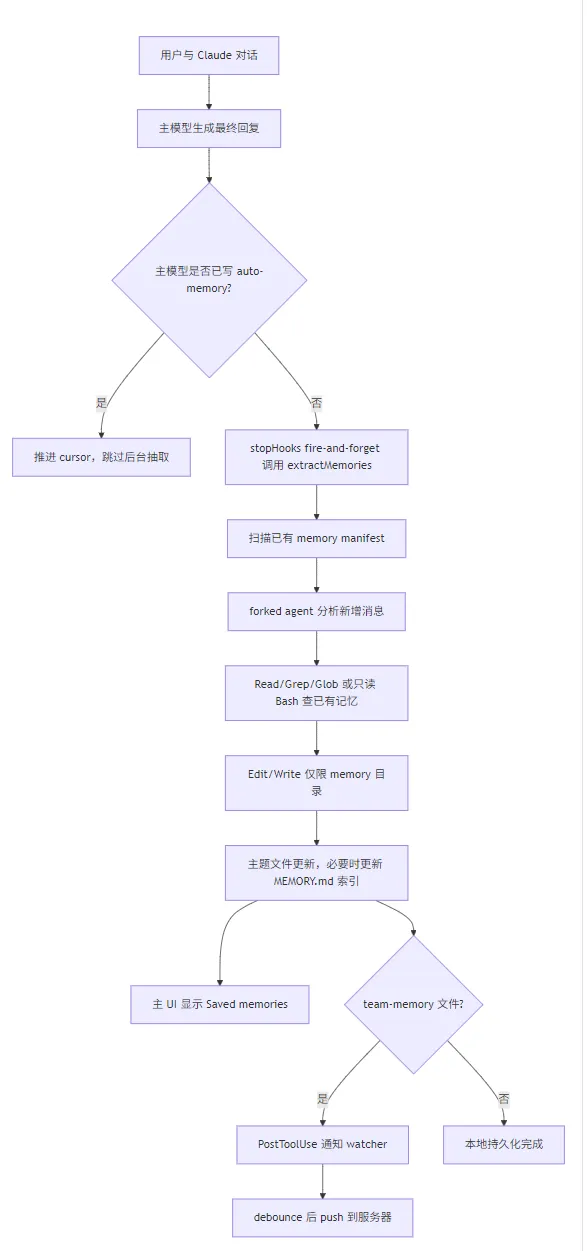
回合结束后台抽取
src/services/extractMemories/extractMemories.ts 是自动更新的核心。它在每个完整 query loop 结束后由 src/query/stopHooks.ts fire-and-forget 调用,条件包括:
EXTRACT_MEMORIESfeature 打开。isExtractModeActive()为真。当前不是 subagent。
不是 bare/simple 模式。
auto-memory 已启用。
不是 remote mode。
抽取器通过 initExtractMemories() 建立闭包状态:
lastMemoryMessageUuid:只处理上次抽取后新增的模型可见消息。inProgress与pendingContext:防止并发抽取;如果抽取中又来了新回合,只保留最新上下文,在当前抽取结束后跑一次 trailing extraction。turnsSinceLastExtraction:按远程配置控制每 N 个 eligible turns 抽取一次。
运行时,它会先检查主模型是否已经写过 auto-memory。如果最近消息中已有 Write/Edit 指向 auto-memory 路径,后台抽取会跳过并推进 cursor,避免同一回合重复保存。
若需要抽取,它会:
扫描已有 memory manifest,提示子代理优先更新已有文件。
构造抽取 prompt。
用
runForkedAgent()启动一个 forked agent,共享父会话 prompt cache,但不写 transcript。限制工具权限:Read/Grep/Glob 可用,Bash 只允许只读命令,Edit/Write 只能写 auto-memory 目录。
最多运行 5 turn。
记录写入文件,过滤掉机械更新的
MEMORY.md,向主 UI 追加“Saved memories”系统消息。
这个后台抽取是 best-effort。失败只记录 telemetry/debug,不打断主对话。
auto-dream 定期整理
src/services/autoDream/autoDream.ts 负责把多次会话积累的记忆做周期性整理。它同样在 stop hooks 后台触发,但有更重的门槛:
auto-memory 开启。
auto-dream 开启。
非 remote mode。
非 Kairos daily-log 模式。
距上次 consolidation 超过配置小时数,默认 24 小时。
上次整理后有足够多的会话,默认 5 个。
能拿到 consolidation lock。
触发后,auto-dream 用 forked agent 跑 consolidation prompt,读取 memory 目录和 transcript 目录,整理已有记忆。工具权限复用 createAutoMemCanUseTool(),也就是只允许只读搜索和 memory 目录内写入。完成后会把 touched files 作为 “Improved memories” 提示给用户;失败会回滚 lock mtime,让后续有机会重试。
Kairos daily-log 模式
src/memdir/memdir.ts 中的 buildAssistantDailyLogPrompt() 说明了 Kairos/assistant 长会话模式的特殊写法:新记忆不直接维护 MEMORY.md,而是追加到 logs/YYYY/MM/YYYY-MM-DD.md。夜间或手动 /dream 再把 daily logs 蒸馏成主题文件和 MEMORY.md。
这个模式强调 append-only,避免长生命周期 assistant 会话频繁重写索引。
team-memory 同步
team-memory 的本地写入仍由主模型或后台抽取完成,但同步由 src/services/teamMemorySync/watcher.ts 负责:
启动时检查 feature、auto/team memory、OAuth、GitHub remote。
创建 sync state。
先从服务器 pull。
对 team-memory 目录启动递归
fs.watch。文件变化后 2 秒 debounce,再 push 到服务器。
src/utils/sessionFileAccessHooks.ts 的 PostToolUse hook 会在 Edit/Write team-memory 文件后调用 notifyTeamMemoryWrite(),作为 fs.watch 漏事件时的补偿。
对于永久性 push 失败,例如 no oauth、no repo、非 409/429 的 4xx,watcher 会进入 suppression,避免无限重试。删除文件会清除 suppression,因为这可能是“文件太多”等错误的恢复动作。
Agent 记忆更新
插件或 Agent 定义中如果声明 memory: user|project|local,src/utils/plugins/loadPluginAgents.ts 会在 Agent 的 system prompt 中注入 loadAgentMemoryPrompt(),并为它添加可读写 memory 的工具能力。之后 Agent 与主模型一样,通过 prompt 指令直接读写自己的 MEMORY.md 和主题文件。
因此,Claude Code 的记忆系统本质上并不是传统意义上的聊天历史保存。
它更接近一个基于文件系统、具备长期语义组织、动态召回、行为反馈、压缩协同与跨 Session 持久化能力的 AI Memory Operating System。
📚推荐阅读
1 | |
2 | |
3 | |
4 | |
5 | |
6 |

