夜雨聆风
夜雨聆风LG - 机器学习 CV - 计算机视觉 CL - 计算与语言 RO - 机器人
1、[LG] Local linear convergence of gradient methods for overparameterized Gaussian mixtures
2、[LG] Universal Decision Learners
3、[LG] Hedging on the Frontier:Learning New Tasks with Few Samples
4、[RO] Don't Fool Me Twice:Adapting to Adversity in the Wild with Experience-Driven Reasoning
5、[CL] Towards Efficient LLMs Annealing with Principled Sample Selection
摘要:过参数化高斯混合模型下梯度法的局部线性收敛性、通用决策学习器、基于极少样本的新任务学习、利用经验驱动推理实现真实复杂环境下的逆境自适应、通过原则性样本选择实现高效LLM退火
1、[LG] Local linear convergence of gradient methods for overparameterized Gaussian mixtures
J Wang, V Charisopoulos, M Fazel
[University of Washington]
过参数化高斯混合模型下梯度法的局部线性收敛性
要点:
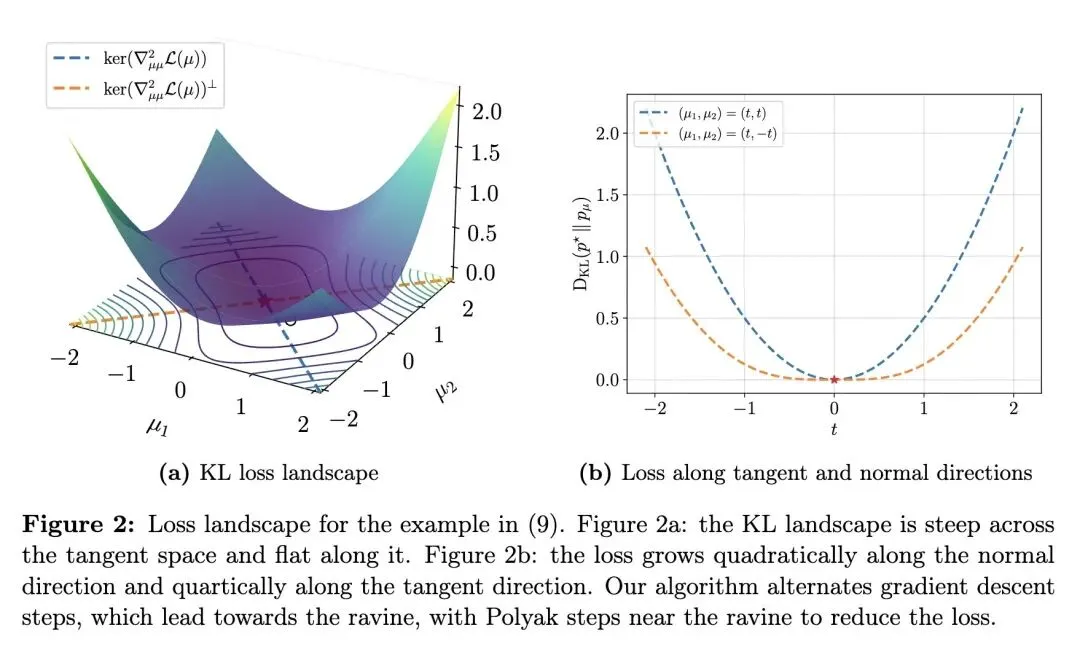
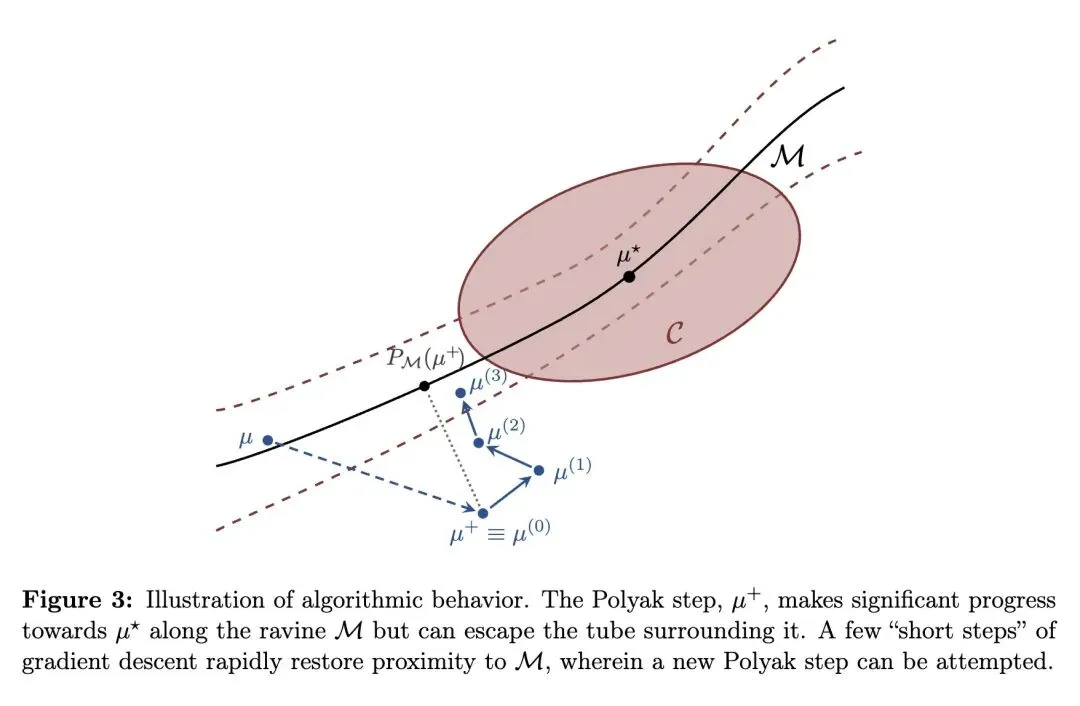
挑战了传统认知:即过度参数化模型中由于Fisher信息矩阵奇异导致的局部收敛缓慢(次线性收敛)是一种不可避免的内在缺陷。 揭示了过度参数化高斯混合模型(GMMs)在极小值附近的KL散度损失景观形成了一个特定的“沟壑”(缓慢增长的流形),损失在切线方向呈四次(quartic)增长,在法线方向呈二次增长。 引入了一种基于阶段切换、感知几何结构的非阶优化算法(基于GDPolyak),该算法在多个“短”标准梯度下降步和一个“长”Polyak步之间交替进行。 “短”梯度下降步用于快速逼近缓慢增长的“沟壑”,而“长”Polyak步则沿“沟壑”以几何级数缩小与最优解的距离,从而实现局部线性收敛。 将估计误差在几何上分解为“聚类偏差”(聚合学生均值到教师均值的距离)和“簇内色散”(学生组件围绕其聚合均值的方差)。 理论和实证均表明,标准梯度EM算法极难降低“簇内色散”(这是导致减速的根本原因),而Polyak步长能极其锐利地消除这种色散。 建立了微扰分析,证明该算法对任意混合权重具有鲁棒性,能够收敛到接近最优的解,其误差上限为一个自然的错误指定阈值(),该阈值由学生簇与真实教师组件之间的权重不匹配程度决定。 提出了一个反直觉的实证发现:即使经过多次梯度EM迭代,标准的修剪(pruning)技术也无法完全消除冗余的学生组件,这凸显了在实践中需要能够原生处理精准过度参数化而无需依赖完美修剪的优化算法。
主旨: 本文主要解决了在学习过度参数化的高斯混合模型(GMMs)时,梯度EM算法虽然能实现全局收敛(避免陷入虚假局部最优),但在局部极小值附近由于参数冗余导致的严重收敛减速(次线性收敛)问题。文章旨在设计一种既能享受过度参数化的全局优势,又能克服其局部奇异性、实现局部快速(线性)收敛的一阶优化方法。
创新:
损失景观的流形识别:创新性地证明了GMMs在过度参数化下的KL散度损失具有“沟壑”(Ravine)几何结构,即在特定方向上呈现四次多项式级别的极其平缓的增长。 结合几何结构的交替优化策略:将Davis等人提出的GDPolyak算法创新性地应用于GMMs的训练中,通过交替使用梯度下降(用于垂直逼近平缓流形)和Polyak步长(用于沿着平缓流形加速前进),巧妙绕过了导致梯度EM减速的平坦方向。 误差的几何解耦机制:首次将过度参数化GMM的误差显式分解为“聚类偏差”和“簇内色散”,为理解优化算法为何在局部陷入停滞提供了全新的几何视角。
贡献:
理论贡献:给出了局部收敛减速(沟壑结构)的严格几何特征,并证明了在最优解附近KL损失满足四次增长条件。建立了在存在权重不匹配(Weight Mismatch)时的微扰分析框架。 方法贡献:提出了一种适用于过度参数化混合模型的几何感知一阶优化算法,在不使用高成本二阶(Hessian)信息的情况下,成功恢复了局部近似线性的收敛速度。 实证贡献:通过大量实验验证了标准梯度EM在处理“簇内色散”时的无力感,并证明了新算法在降低KL损失和参数距离上的指数级提升,同时展示了其对实际权重不匹配的鲁棒性。
提升:
收敛速度:在进入局部收敛阶段后,将现有梯度EM算法的次线性收敛速度(如 或更慢)大幅提升至近似局部线性收敛(几何级数递减)。 优化精度:在同等迭代次数下,新算法能够将KL损失和参数距离(Parameter distance)降低数个数量级(从实验图表看,相比EM算法损失下降速度成指数倍拉开差距)。 克服平坦陷阱能力:显著提升了模型消除“簇内色散”(冗余组件间的方差)的能力。
不足:
局限于总体/无限样本设定(Population Level):目前的理论分析主要建立在总体梯度EM的设定上(假设有无限样本可以精确计算期望),尚未将保证扩展到更具挑战性的有限样本(Finite-sample)随机梯度设定中。 阶段切换的硬性阈值:算法的实现(Algorithm 1)人工地将过程分为了两个阶段,并通过“冻结学生权重”来触发局部加速阶段,缺乏一种无需人工干预、端到端自适应调整权重的统一算法形态。 超参数的理论量化:尽管证明了局部加速区域(邻域)的存在,但缺乏对该邻域大小、所需精确阈值的定量估计,在实际应用中需要一定成本去调参。
心得:
过度参数化的“双刃剑”可以通过几何手段被驯服:传统观念认为过度参数化赋予了模型极好的全局损失景观(消除局部死胡同),但必然以牺牲局部极小值处的锐度(导致奇异Hessian矩阵和训练缓慢)为代价。本文极具启发性地指出,这种“代价”并非死局,只要优化器能够“感知”到这种奇异性造成的特殊几何结构(如四次增长的沟壑),就能通过简单的策略(如Polyak步长)重新找回线性收敛。 误差分解揭示了算法的物理意义:将冗余组件的误差分解为“聚类偏差”(整体偏离度)和“簇内色散”(内部松散度)是非常高明的视角。它直观地解释了为什么梯度下降会变慢——因为所有的冗余神经元都在做微小的互相抵消,梯度很难把它们强行“捏合”在一起。这种思路对分析神经网络中注意力头或多分支结构的冗余性也有极大的借鉴意义。 一阶算法的潜力远未触顶:面对奇异的损失景观,直觉往往引导我们去使用牛顿法或拟牛顿法(利用曲率信息)。但本文证明,只需巧妙组合最基础的梯度下降(寻找低维流形)和Polyak步长(一种依赖目标函数下界的一阶自适应步长),就能在奇异问题上媲美高阶算法的收敛速度,这为大规模机器学习优化提供了一条极具性价比的新路径。
一句话总结:
本文打破了“过度参数化必然导致局部优化极度缓慢”的传统悲观认知,通过揭示高斯混合模型在局部极小值处的“四次增长沟壑”几何结构,创新性地提出了一种交替使用梯度下降和Polyak步长的一阶算法,在保留过度参数化带来的全局收敛优势的同时,成功实现了局部近似线性的指数级加速。
We study the problem of learning Gaussian mixture models under overparameterization. Prior work has shown that while overparameterization is essential for avoiding spurious local optima and enables global recovery of the ground-truth model using the gradientEM (expectation-maximization) algorithm, it can dramatically slow down the local rate of convergence. Under certain assumptions on the mixture weights, we show that a standard divergence measure minimized by statistical learning procedures possesses a manifold of slow growth on which the well-known Polyak stepsize reduces the loss geometrically, and design a gradient-based method that converges to minimizers at a locally linear rate. Additionally, we show that our method converges to nearly optimal solutions — up to a natural misspecification threshold — for mixtures with arbitrary weights. At a high level, the method alternates between several “short” gradient descent steps that approach the manifold and “long” Polyak steps that contract the distance to minimizers. Our results suggest that slow convergence is not an intrinsic challenge of overparameterization, but can be overcome by exploiting the favorable structure of the loss landscape.
https://arxiv.org/abs/2605.30936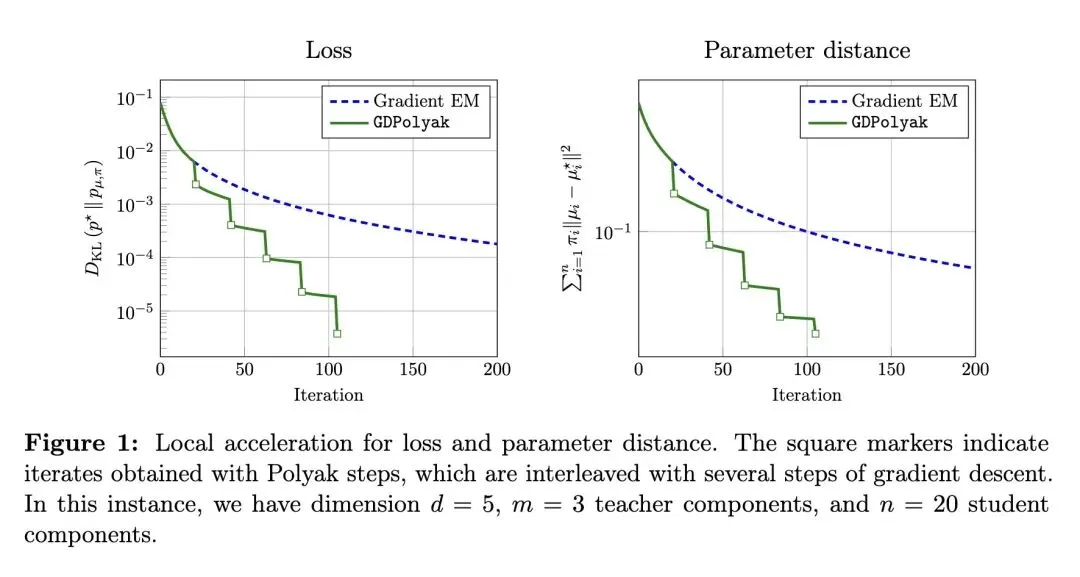
2、[LG] Universal Decision Learners
S Mahadevan
[Adobe Research]
通用决策学习器
要点:
使用范畴论(特别是坎扩张,Kan extensions)为多样化的决策范式(规划、强化学习、博弈论、在线学习和因果推断)构建了一个统一的数学基础。 挑战了“不同决策领域需要不同理论框架”的传统观点,提出它们实际上都在实例化完全相同的普遍数学问题:将局部的行为数据以典范(canonical)的方式扩展到新的上下文中。 将“左坎扩张”(Left Kan Extension, )映射为前向操作,如展开(rollout)、路径聚合和候选生成。 将“右坎扩张”(Right Kan Extension, )映射为后向一致性操作,如约束满足、贝尔曼不动点(Bellman fixed-points)和博弈论均衡。 将通用决策学习器(UDL)抽象地定义为两阶段复合操作 ,即先展开局部决策候选,然后强制实现全局一致性。 提出了一个极具反直觉的视角:长视角的序列决策(如强化学习中的价值函数)应该通过“协同归纳”(coinductive)语义(通过展开行为和观察来表征)来理解,而不是传统的归纳构造。 将状态抽象和双模拟(bisimulation)纯语义化地重新定义为“坎不变性”(Kan invariance),即如果两个状态的坎扩张全局行为是同构的,则它们是等价的,从而摆脱了句法层面的定义。 引入了“同伦坎等价”(Homotopy Kan Equivalence)来形式化因果可识别性和表征形变等概念,即如果不同的内部模型诱导出相同的观察性坎扩张,则认为它们是等价的。 在概念上重新解释了深度强化学习:函数逼近仅仅是“近似坎计算”,而表征学习则是寻找保留价值语义的“近似余代数态射”(approximate coalgebra morphisms)。
主旨: 本文旨在解决现有人工智能中各个决策子领域(如强化学习、因果推断、博弈论等)理论各自为战的问题。文章提出,所有这些决策系统本质上都是在解决同一个问题:如何将局部观察到的决策数据,全局一致地扩展到未知的上下文中。为此,作者引入了范畴论作为统一语言,提出了“通用决策学习器”(Universal Decision Learners, UDL)框架。
创新:
范畴论与决策机制的精准映射:首次极其精妙地将范畴论中的核心概念“坎扩张”与决策过程对应——左坎扩张对应前向搜索/展开,右坎扩张对应后向一致性/贝尔曼方程。 协同归纳语义的引入:打破了机器学习中普遍的“归纳”(Induction)思维,将动态系统和强化学习定义为“协同归纳”(Coinduction)过程,即事物不是由其组成部分定义的,而是由其对外界的响应和展开行为定义的。 语义化的抽象理论:提出了基于“坎不变性”和“同伦坎不变性”的抽象理论。这使得状态等价(如强化学习中的双模拟)和因果推断中的可识别性,能够在同一个高维拓扑/范畴概念下被解释。 统一的UDL方程:将复杂的决策过程抽象为一个极其简洁的范畴算子组合:。
贡献:
理论大一统:为强化学习、MDPs、纳什均衡、无悔在线学习和因果干预提供了一个完全统一的范畴论底层数学架构。 重新定义深度强化学习本质:为深度强化学习中的表征学习提供了坚实的数学解释,将其定义为寻找“近似余代数态射”,并将结构化损失(如GNN中的平滑惩罚)解释为强制保持范畴图表交换性的正则化。 提供跨领域转译的工具:通过证明这些决策过程具有相同的“泛象性质”(Universal Property),为未来在不同AI分支之间直接平移算法思想提供了数学依据。
提升:
概念和理论维度的降维打击:本文是一篇纯理论文章,没有在标准基准集上提供实证指标(如Reward提升或收敛速度加快)的对比。它的“提升”体现在认知和理论层面——它将孤立的算法技巧(如TD-learning、值迭代、纳什均衡求解)提升为一种严密的、普遍的数学泛象性质(Universal comparison property),极大地提升了决策智能理论的优美度和统一性。
不足:
缺乏具体的算法实例化:正如作者在讨论中所承认的,UDL目前纯粹是一个解释性的语义框架,尚未推导出一个在经验表现上能超越现有SOTA(如PPO, SAC)的全新具体算法。 极高的理解门槛:文章严重依赖于高级抽象代数和范畴论(Functor, Limit/Colimit, Kan Extension, Coalgebra, Homotopy),这与主流以概率论和微积分为基础的机器学习社区存在巨大的认知鸿沟,可能阻碍其实际应用。 深度学习中的非理想近似:理论假设了完美的坎扩张或可控的度量投影,但在高维非凸的神经网络优化中,如何严格保证“近似余代数态射”的同态性,仍是一个未解决的工程/数学难题。
心得:
认知视角的颠覆:从“归纳”到“协同归纳”:我们习惯于认为学习是从数据中“归纳”(Induction)出规律,构建出一个静态的模型。但本文极具启发性地指出,对于长期序列决策(如强化学习),学习实际上是“协同归纳”(Coinduction)的——你不需要穷尽底层状态的构造,你只需要保证状态的“展开行为(观测和响应)”在时间步上是一致的。理解了协同归纳,就能瞬间顿悟为什么Bellman方程这种“自己定义自己”的自举(Bootstrapping)机制在数学上是严密且必不可少的。 寻找AI的“大一统理论”:当发现马尔可夫决策过程的Bellman不动点、博弈论中的纳什均衡、在线学习的无悔条件,竟然在范畴论中全部对应于同一个数学概念(右坎扩张)时,这种理论的震撼力是巨大的。这意味着AI的许多子领域其实在盲人摸象,如果我们掌握了范畴论这门“数学的数学”,就有可能将因果推断领域的突破,通过函子直接映射并应用到强化学习或博弈论中。 重新审视神经网络架构的设计直觉:文章指出,在强化学习中使用图神经网络(GNN)或Transformer(注意力机制),本质上是为了给网络提供一种“关系先验”,使其更容易逼近真实的“余代数态射”。这启发我们:设计新的网络架构,不应仅仅为了减少拟合误差,而应思考该架构的拓扑结构是否自然地匹配了该任务“坎扩张”所在的范畴图表(Diagrams)。
一句话总结:
本文运用范畴论发起了对人工智能决策理论的“大一统”,创造性地通过“坎扩张”和“协同归纳”将强化学习、博弈论、因果推断等看似迥异的领域统一为同一个“将局部数据典范地扩展为全局一致行为”的数学问题,彻底重塑了我们对序列决策本质的理解。
Many theories of decision making -- planning, reinforcement learning, causal intervention, online learning, and game-theoretic equilibrium -- turn local information into globally coherent behavior. This paper proposes a common categorical formulation: a Universal Decision Learner (UDL) extends a partially specified decision functor from observed contexts to new contexts by a pair of universal constructions. Left Kan extensions express rollout, aggregation, and candidate generation; right Kan extensions express consistency, constraint satisfaction, and fixed-point semantics. The central claim is not that every decision problem has the same algorithm, but that many decision formalisms instantiate the same universal problem: extend local behavioral data canonically, then characterize the globally coherent extensions. We give the abstract UDL construction, prove its universal comparison property, define Kan-invariant behavioral equivalence and minimal abstractions, and show how Bellman equations, planning recursions, causal interventions, online regret, and equilibria arise as special cases. The supplementary material develops the reinforcement-learning specialization in more detail.
https://arxiv.org/abs/2605.30694
3、[LG] Hedging on the Frontier: Learning New Tasks with Few Samples
T Wegel, F D Gennaro, G So, F Yang
[ETH Zurich & UC San Diego]
前沿对冲:基于极少样本的新任务学习
要点:
形式化了一个极具实用价值但探索不足的场景:如何利用模型在公开基准测试集上的已知评估结果,仅用极少量的样本为新目标任务选择或学习一个最优模型。 引入了“弱单调性”(Weak Monotonicity)假设:如果一个模型在所有基准任务上都严格优于另一个模型,那么它在目标任务上也应该表现得更好。 反直觉发现1:- 随着基准测试数量()的增加,弱单调性假设实际上变得更弱*(更容易满足)。因为维度越高,模型在所有维度上完全支配另一个模型的概率就越小。这从理论上证明了现代构建庞大、多任务基准测试套件(如HELM)的合理性。 证明了弱单调性严格泛化了标准的多源域自适应假设(如目标分布是源分布的凸混合),并且与标准的分布偏移假设(如协变量偏移或标签偏移)完全正交。 定义了一种新的复杂度度量——帕累托覆盖数(Pareto Covering Number),以捕捉帕累托前沿的统计复杂度。 反直觉发现2:- 帕累托覆盖密度的极限分布不是均匀的*。它自然地为包含“不当权衡”(improper trade-offs,即法向量在某维度趋于零,意味着在某基准上微小的提升会导致另一基准上巨大的性能下降)的区域分配较低的密度。几何形状本身指导了统计效率。 提出了“在前沿上对冲”(Hedging on the Frontier)的策略:将假设搜索空间限制在帕累托集(或其边缘)内,以大幅降低低数据机制下经验风险最小化(ERM)的方差。 引入了一种无需调整超参数的自适应边缘ERM(Adaptive Margin ERM)。随着目标样本量 的增加,它将搜索空间从严格的帕累托前沿逐渐扩展到完整的假设空间,在单调性被破坏时自然回退到标准ERM。 反直觉发现3:- 在模型选择聚合(MSA)中,传统方法在字典的凸包(convex hull)内进行对冲。本文表明,在单调性下,改在帕累托前沿上进行对冲会产生一种“人造的詹森差距”(artificial Jensen's gap),从而即使在没有强凸损失函数或Bernstein条件的情况下,也能解锁快速率*()。
主旨: 本文旨在解决在拥有多个基准任务性能数据的情况下,如何仅利用极少量目标任务数据进行高效迁移学习和模型选择的问题。通过提出“弱单调性”假设,文章证明了学习算法不应在整个假设空间中盲目搜索,而应将候选模型修剪至基准任务构成的“帕累托前沿”上,并根据前沿的几何特征进行“对冲”,从而大幅降低小样本学习的统计复杂度。
创新:
脱离分布假设的单调性建模:放弃了传统迁移学习中对源域和目标域概率分布关系的强假设(如协变量偏移),转而使用基于排名的“弱单调性”作为桥梁,这种宏观黑盒视角的假设在基础模型时代更为稳健和普适。 帕累托前沿的几何与统计测度结合:首次精确推导了帕累托覆盖数在尺度趋于零时的极限分布,揭示了帕累托前沿的曲率和法向量如何直接决定覆盖密度,从而将多目标优化的几何学与统计学习理论深度融合。 跨越凸包的聚合策略:在模型选择聚合(MSA)领域,打破了在“基模型凸包”内寻找最优解的传统,创新性地证明了向帕累托前沿投影可以绕过损失函数的强凸性要求,直接获得 的快速学习率。
贡献:
理论框架:建立了一个在(近似)弱单调性下进行目标任务学习的严格统计理论框架,并提出了用于量化单调性违反程度的“单调性模量”(Modulus of Monotonicity)。 复杂度刻画:推导了帕累托覆盖数的渐近行为,证明了其自适应于帕累托前沿几何形状的特性,并给出了匹配的极小极大下界。 实用算法设计:提出了一种无需超参数的自适应边缘ERM(Adaptive Margin ERM)算法,在少量数据时享受帕累托前沿的低方差红利,在数据量增大时保证全局一致性。 MSA速率突破:在一定的强凹几何间隙假设下,为不具备强凸性的损失函数提供了实现模型聚合快速率(Fast Rates)的理论证明。
提升:
小样本泛化能力:在目标样本极少(如 )的情况下,相较于在全局假设空间中进行ERM,将搜索空间限制在帕累托前沿能显著降低方差,大幅降低超额风险(Excess Risk)。 假设的普适性:相比于多源域自适应中常用的“目标分布是源分布的凸组合”假设,弱单调性更为宽松。在目标任务不是源任务混合的情况下,新方法依然能利用基准提供有效信号。 无强凸依赖的收敛率:在模型选择聚合中,将收敛速率从标准的 提升至 ,且无需传统理论中苛刻的损失函数曲率假设。
不足:
忽略基准评估的噪声:理论分析假设基准风险 是精确已知的(即源域有无限样本)。在实际中,基准测试的评估本身带有方差和噪声,这可能会扰乱帕累托前沿的构建。 连续空间中的计算瓶颈:虽然在有限的模型库(Finite Model Zoo,如HELM排行榜)中计算帕累托前沿很容易,但在连续或无限的假设空间中,精确计算最小的 -帕累托覆盖是一个NP困难问题。 MSA中强凹间隙的获取困难:在模型选择聚合中为了获得快速率,算法需要知道帕累托集与凸包之间的“强凹间隙”()及其对应的投影。这需要对问题的几何结构有极强的先验知识,在黑盒模型中很难直接计算。
心得:
维度的诅咒在此处反转为“维度的祝福”:直觉上,增加约束或增加基准测试的维度会让问题变得更难。但本文极其巧妙地指出,在“弱单调性”假设下,增加基准任务 的数量,实际上会让“模型A在所有基准上都优于模型B”这一前置条件变得极其罕见。前置条件越难触发,单调性假设就越不容易被打破(变得更弱)。这为当前业界疯狂堆叠基准测试(如构建包含几十个子任务的榜单)提供了一个完美的统计学背书:基准越多,它们作为整体联合抵御“过拟合”或“排名失效”的能力就越强。 统计学习自带“规避极端”的几何智慧:本文对帕累托覆盖数极限分布的推导非常惊艳。它从纯数学角度证明了:在构建覆盖网格时,那些需要牺牲巨大代价才能换取微小收益的“不当权衡点”(法向量接近坐标轴)自然会被分配极低的密度。这意味着在小样本下进行学习时,算法不需要人为去过滤这些极端的“偏科”模型,帕累托前沿的内生几何结构本身就已经引导算法去“对冲”(Hedging)那些表现更加均衡的模型。 突破凸包,向帕累托前沿借取“人造曲率”:传统的聚合算法(Aggregation)为了对抗方差,习惯于把多个基模型的预测值进行加权平均(即落在凸包内)。但这往往受限于损失函数本身是否具有强凸性。本文给出了一个破局的思路:既然在单调性下帕累托前沿严格支配凸包,那么把预测点强制拉拽到帕累托前沿上,就等同于在损失平面上人为制造出了一个“詹森差距”(Jensen's gap)。这种利用假设空间的外部几何结构来弥补损失函数内部曲率缺失的思路,对优化理论具有极高的启发价值。
一句话总结:
本文通过引入“弱单调性”假设,深刻揭示了帕累托前沿几何结构与统计复杂度的内在联系,证明了在小样本迁移学习和模型聚合中,将搜索空间限制并对冲于基准测试构成的帕累托前沿上,不仅能大幅降低估计方差,还能巧妙解锁超越常规的快速收敛率。
When a learner faces a new task with few samples, it must leverage any available side information. In practice, this often comes in the form of model evaluations on related tasks in public benchmarks. A key question then is how to model task relatedness such that it is both realistic and the benchmark evaluations lead to provable gains. Empirically, we observe that weak monotonicity is often approximately satisfied: if a model dominates another on many benchmarks, it also tends to outperform on the new task. We explore the statistical complexity of learning under (approximate) weak monotonicity, leveraging it within two learning paradigms: transfer learning and model selection aggregation. We show that not only can we prune the model class based on monotonicity, but we can also further adapt to the geometry of the available trade-offs by hedging on the frontier.
https://arxiv.org/abs/2605.30997
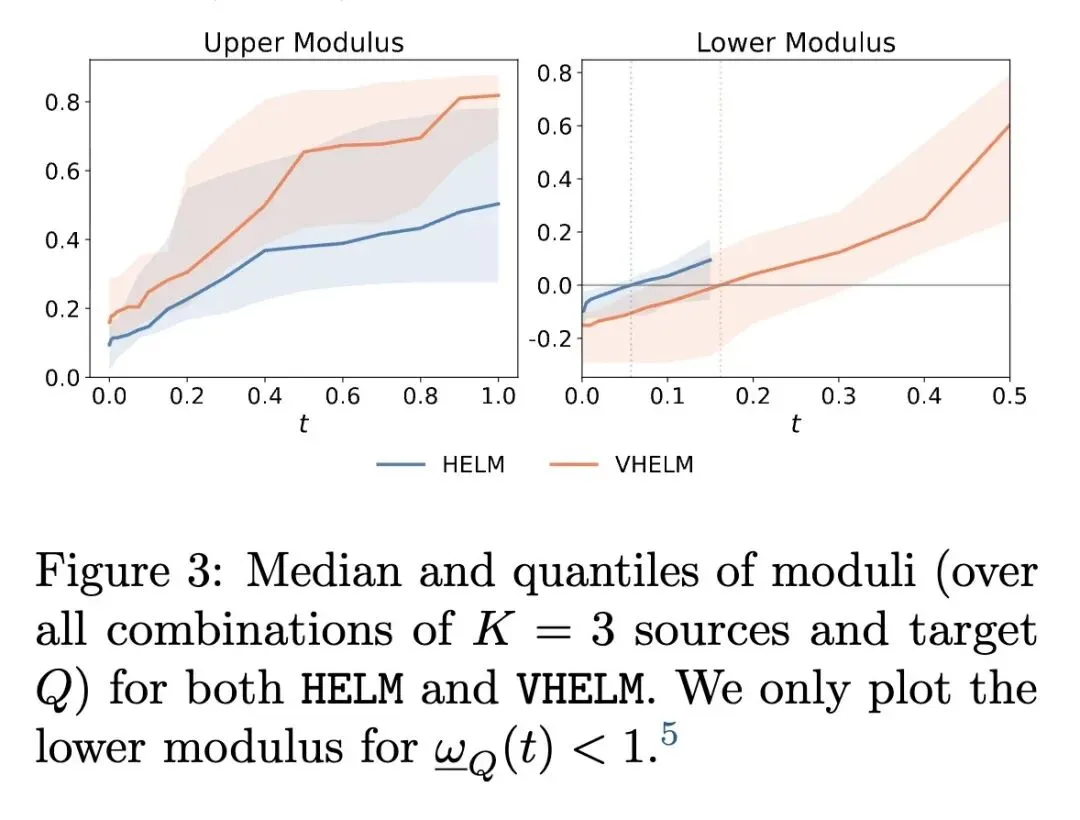
4、[RO] Don't Fool Me Twice: Adapting to Adversity in the Wild with Experience-Driven Reasoning
N S Ravie, A Jong, K Jain, J Liu…
[Indian Institute of Technology & CMU]
拒绝重蹈覆辙:利用经验驱动推理实现真实复杂环境下的逆境自适应
要点:
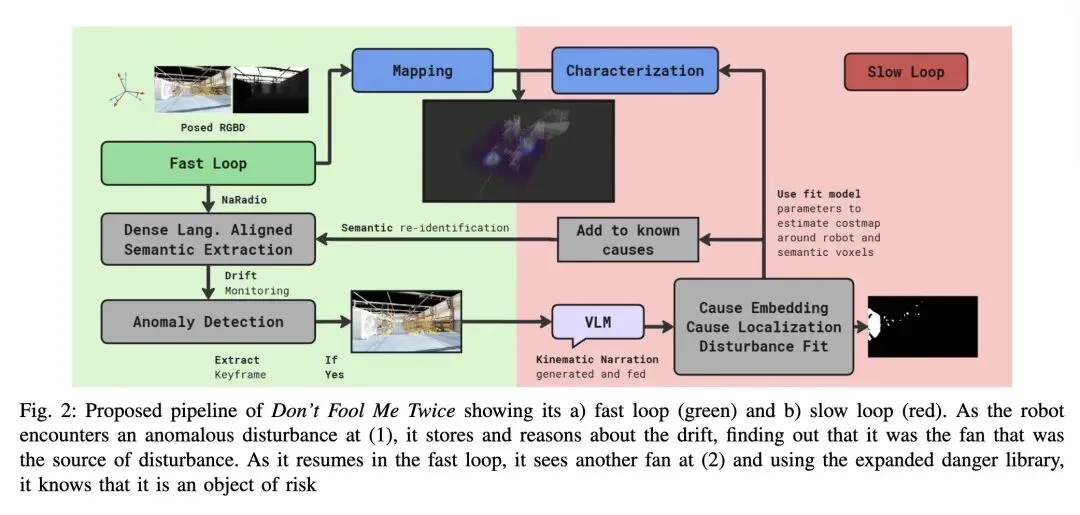
挑战了目前使用视觉语言模型(VLMs)进行“抢占式(preemptive)”危险检测的主流范式,指出基于互联网常识的先验会导致过度保守的路径规划,因为“危险”是高度依赖于具体具身机器人的(例如,湿滑的地板对轮式机器人是危险的,但对无人机毫无影响)。 引入了一种反直觉的“事后(post-hoc)”(事件驱动)推理机制:机器人不再不断地询问VLM“这里有什么危险?”,而是等到实际发生运行异常时,才去查询VLM来归因。这极大地减少了误报和计算延迟。 将物理扰动(如风扇吹出的风)和算法/感知失效(如由于无纹理墙壁或红外过度曝光导致的视觉里程计漂移)纳入一个统一的数学框架中。两者都被视为与语义对象绑定的、具有空间边界的扰动场。 克服了标准高斯过程(GPs)在瞬态异常期间极端少样本(<50个样本)情况下的失效问题。它将空间几何形状(通过语义体素先验固定)与扰动强度解耦,将环境适应转化为固定形状模板上的贝叶斯线性回归,从而安全地估计认知不确定性(Epistemic Uncertainty)。 实证表明,个性化、由经验驱动的“危险库”使得机器人能够展现出涌现的自适应行为(停止、倒车、重新规划路线),而不是盲目坚持或简单套用硬编码的避障半径。
主旨: 本文旨在解决移动机器人在未知非结构化环境中面临具身特定(embodiment-specific)且无法预见的危险的问题。为此,作者提出了一个名为“Don't Fool Me Twice (DFM2)”的持续学习框架。该框架允许机器人通过自身的运行经验(如轨迹偏差或状态估计协方差异常)在线学习,利用视觉语言模型(VLM)进行事后语义归因,并通过体素级核回归量化扰动场,从而构建个性化的危险库,以便在未来遇到相同语义对象时主动规避。
创新:
事件驱动的VLM归因机制(Post-hoc Reasoning):摒弃了主流的“先预测后规划”策略,改为“先受挫、后归因、再记忆”,有效解决了VLM在机器人应用中因缺乏物理交互常识而导致的过度保守问题。 物理与感知失效的统一空间建模:创新性地将VIO(视觉惯性里程计)因纯黑无纹理表面或反光造成的算法崩溃,与风扇造成的物理偏移一视同仁,均抽象为三维空间中的语义可学习行为场。 解耦的少样本交互建模:在极少量观测数据下,放弃了联合优化核函数长度尺度和振幅的传统GP做法,转而利用语义体素限定干扰形状,仅对振幅和偏差进行贝叶斯线性回归,实现了高效、稳定的不确定性估计。
贡献:
经验驱动的语义关联:构建了一个通过运行异常信号自动触发、将长尾危险与密集视觉语义绑定的机器人个性化“危险库”。 不确定性感知的预测性适应:提出了一种结合空间模板和贝叶斯回归的保守规划机制,使得机器人在靠近未知程度较高的危险源时能自动扩大安全裕度。 跨平台与跨模态的广泛验证:在仿真和真实硬件上,跨越了不同的机器人形态(四旋翼无人机、轮式机器人)和完全不同的失败模式(外部风力扰动、内部感知特征退化)对框架进行了验证。
提升:
生存率与误差控制:在仿真实验中,DFM2的生存率达到了81.8%,远超纯几何方法的40.9%和主动VLM方法的59.1%;同时将累积扰动误差降低了3倍以上。 消除过度保守(效率提升):相比于主动避障的VLM基线方法,DFM2规划的路径更短(29.3m vs 34.0m),到达时间更快,证明其有效地避免了“把所有看起来危险的东西都当成真实威胁”的弊端。 真实硬件上的定位鲁棒性:在面对无纹理表面导致感知退化的硬件测试中,DFM2大幅提高了视觉里程计的内点率(Inlier Ratio 从0.28升至0.45),显著降低了位姿协方差轨迹和定位降级时间。
不足:
严重依赖危险源的“视觉可观测性”:如果危险源在视觉上不可见或极难分辨(例如透明的积水、极细的铁丝),该框架将无法进行有效的语义归因和提取。 杂乱场景下的单次归因脆弱性:在极度杂乱的环境中,仅凭一次失败经历可能导致VLM将扰动错误归因于附近的无关物体,目前缺乏跨多次交互的因果交叉验证机制。 模块化设计的潜在误差累积:DFM2由多个独立设计的模块(异常检测、VLM查询、核回归)拼接而成,模块间的边界可能会引入累积误差,未能实现端到端的联合优化。
心得:
“危险”的本质是相对的,而非绝对的:这篇文章带来了一个深刻的哲学视角的转变。在具身智能中,环境属性本身无所谓安全或危险,危险是“环境与特定机器人软硬件堆栈交互”后产生的相对属性。因此,抛开具体机器人谈零样本(Zero-shot)的危险预测是注定低效的。 “偷懒”的VLM策略反而更智能:目前具身智能界流行让大模型实时分析每一帧图像以预测风险,这不仅算力开销巨大,而且极易产生幻觉。DFM2的“不见棺材不掉泪(事后查询)”策略非常巧妙,把VLM降级为一个“尸检法医”而不是“预言家”,利用强烈的物理误差信号来触发查询,极大地收敛了VLM的搜索空间,提高了归因的准确性。 将软件失效“物理化”的降维打击:文章中最让我惊艳的一点,是它将VIO(视觉里程计)因为看到纯黑墙壁而丢失特征点这种纯粹的“软件/算法失败”,抽象成了一个类似于风场、磁场的“空间物理排斥场”。这种抽象将复杂的软件边界情况降维成了一个简单的几何避障问题,为评估和处理黑盒算法的失效边界提供了一种极其优雅的思路。
一句话总结:
DFM2框架赋予了机器人“吃一堑,长一智”的能力,它通过在机器人实际遭遇物理偏移或算法崩溃后,利用视觉语言模型将异常事后归因于具体的语义对象,并构建空间扰动场模型,从而在未来精准、不保守地规避属于该特定机器人的专属危险。
In robotics, dangers and adversity modes are often embodiment-specific and relative to each agent. A frontier of autonomous mobile robotics is to enable agents to operate effectively in the wild in unseen unstructured environments. A significant challenge in unseen unstructured environments is that it may not be possible to predict all the dangers to the specific robot. Although recent work has used large foundation vision-language models (VLMs) to preemptively predict an exhaustive list of common-sense dangers, it remains difficult to capture possible interaction and embodiment-dependent adversities. We propose a continual learning framework for a mobile embodied agent to learn online from disturbances and attribute anomalous behaviours to causes through semantics, enabling better prediction and planning of the world in the future. Our framework, “Don’t Fool Me Twice”, first observes disturbances and describes their effects on the robot; this description is augmented with visual context to query a VLM to predict possible causes; the local disturbance is characterized using kernel regression, which allows for efficient, few-shot modeling of transient anomalies. We leverage semantic voxelcentric modeling to estimate epistemic uncertainty, enabling richer downstream recovery by treating interaction-driven disturbances as learnable spatial behaviors. We present four hypotheses and validate them in simulation and on hardware across embodiments and adversity modes.
https://arxiv.org/abs/2605.31119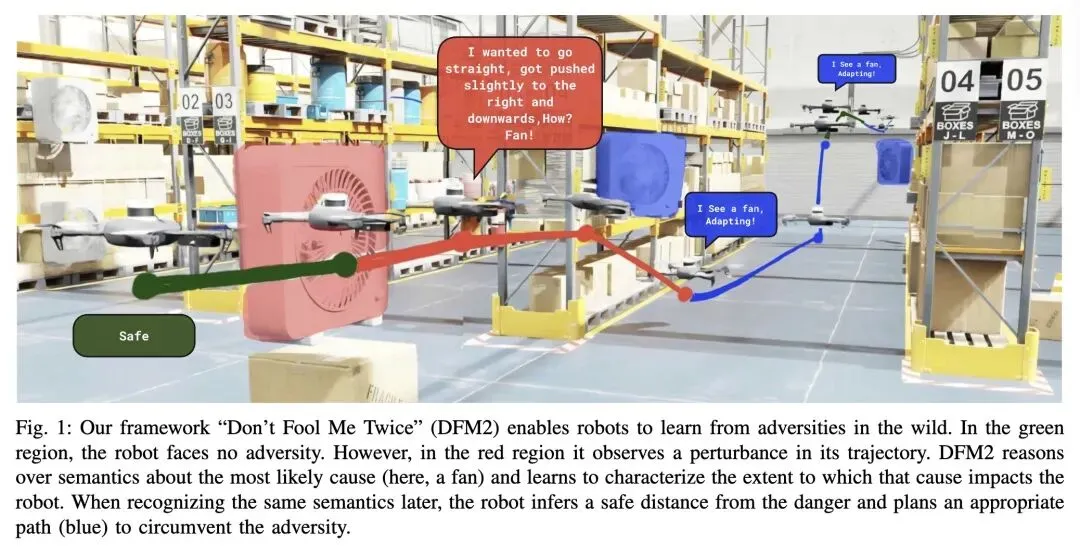

5、[CL] Towards Efficient LLMs Annealing with Principled Sample Selection
Y Xu, J Hao, W Zhang, Z Li…
[Microsoft Research Asia]
通过原则性样本选择实现高效LLM退火
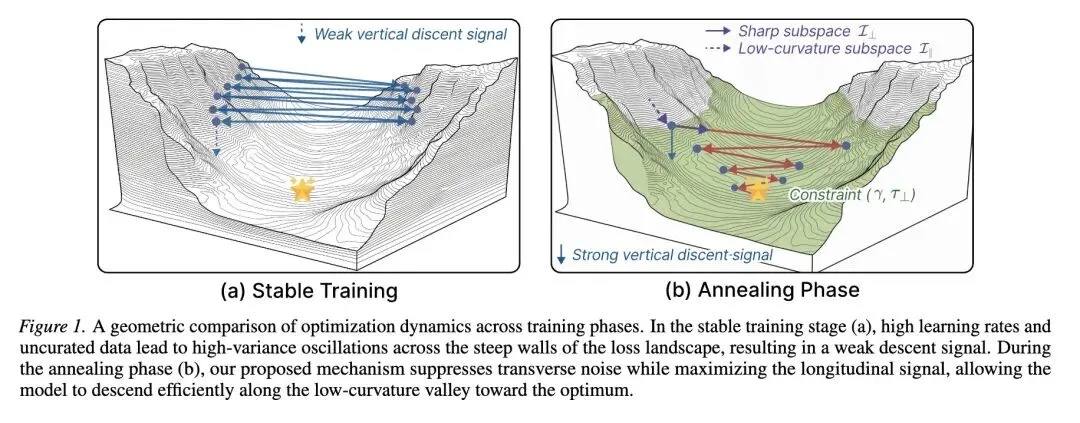
要点:
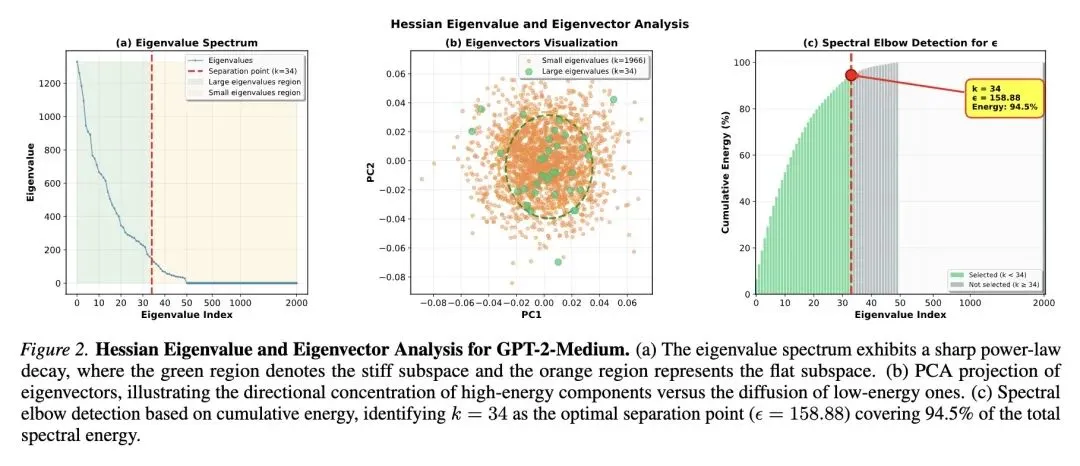
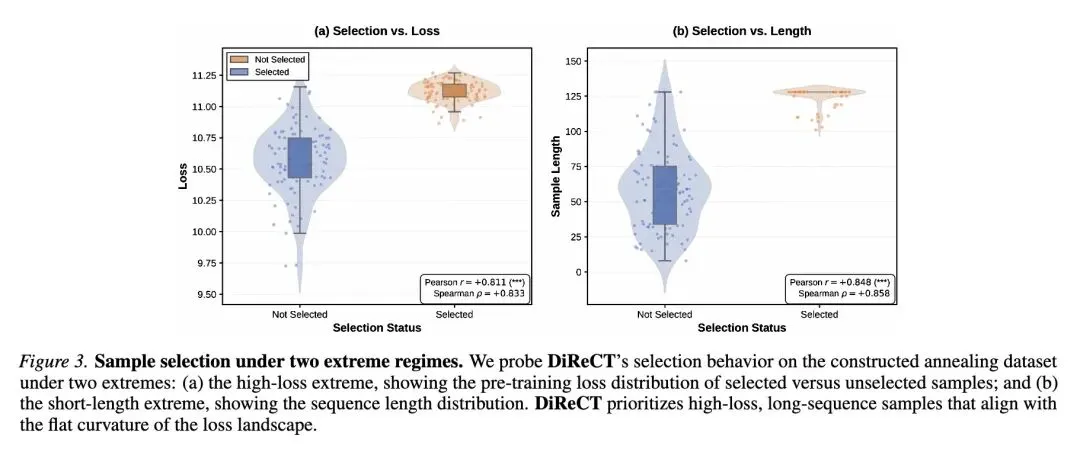
指出了大语言模型(LLM)训练中的关键空白:“退火阶段”(训练后期)对模型收敛和最终质量至关重要,但当前的数据选择策略(如增加数学/代码或长上下文数据的采样)纯粹基于经验启发式方法,缺乏优化理论的基础。 提供了退火阶段的几何学视角: 将“稳定训练阶段”描述为在损失景观的陡峭墙壁上反弹(高方差噪声),而“退火阶段”则需要过渡到沿着平坦、低曲率的山谷下降。 引入了DiReCT(方向约束训练)框架: 这是一个新的、有数学原理支撑的框架,它基于损失景观的谱几何(spectral geometry),将退火阶段的数据选择公式化为一个约束优化问题。 利用海森矩阵(Hessian Matrix): DiReCT利用验证集海森矩阵的特征谱,将参数空间划分为“刚性(stiff)”子空间(高曲率/尖锐方向)和“平坦(flat)”子空间(低曲率山谷)。 核心选择逻辑: 该算法主动选择那些其梯度在“平坦”子空间中能最大化下降信号的训练样本,同时严格限制其在“刚性”子空间中的梯度噪声,以防止优化不稳定和灾难性遗忘。 采用计算效率技巧: 由于直接计算LLM的完整海森矩阵是不可能的,DiReCT使用随机草图(randomized sketching)技术将高维梯度投影到一个小得多的子空间()中,从而高效地近似主导的谱结构。 用SCA解决优化难题: 通过将离散的组合优化问题松弛到连续域,并使用逐次凸近似(SCA)求解器,解决了非凸的数据选择问题。 提供PAC-Bayesian理论基础: 证明了选择与平坦特征方向对齐的样本会主动使损失景观变得更平坦(收缩曲率迹),这直接转化为更紧的PAC-Bayesian泛化界限(更好的训练-测试差距)。 展示了卓越的实证性能: 在GPT-2-Medium和Llama-1.1B上进行了评估。DiReCT在综合指标上始终优于经验基线(均匀采样、困惑度、损失、InfoBatch),特别是在推理任务(数学、代码)上获得了显著提升。 揭示了反直觉的选择行为: DiReCT自然地偏好高损失、长序列的样本——这不仅仅是因为它们“难”,而是因为它们的梯度向量在数学上更好地与验证集海森矩阵的平坦方向对齐。
主旨: 本文旨在解决大语言模型(LLM)预训练后期(退火阶段)数据选择缺乏理论指导的问题。作者提出通过分析损失景观的谱几何(海森矩阵的特征值分布),将数据选择转化为一个约束优化问题:挑选出那些能够引导模型在低曲率(平坦)山谷中快速下降,同时避免在高曲率(陡峭)方向上产生破坏性震荡的样本,从而实现更高效、更稳定的模型收敛。
创新:
从经验启发式转向几何驱动: 打破了以往在退火阶段盲目增加“高质量数据”(如数学、代码)或长文本的经验做法,首次将数据选择与模型当前的优化几何状态(海森矩阵)直接绑定。 双重方向约束机制: 创新性地提出同时在两个正交的子空间中进行操作:最大化平坦方向的梯度投影(促进学习),并硬性约束陡峭方向的梯度能量(防止遗忘和崩溃)。 高维空间的近似高效求解: 结合随机草图(Randomized Sketching)和逐次凸近似(SCA),将计算代价极其昂贵的几十亿参数的海森矩阵特征值分解和组合优化问题,转化为实际可行的高效算法。
贡献:
理论框架: 提出了DiReCT框架,为LLM退火阶段的数据选择提供了首个系统的、基于优化理论和谱几何的解决方案。 理论证明: 提供了严格的PAC-Bayesian理论分析,证明了沿着平坦方向更新参数能够收缩曲率的迹(trace),从而保证更好的泛化能力。 实证验证与解释: 在多个模型规模(355M, 1.1B)上验证了该方法的有效性,优于现有SOTA数据选择方法;并对算法选择出的“高损失、长序列”样本给出了基于优化动力学的物理解释。
提升:
下游任务性能: 相比于均匀采样和InfoBatch等强大的基线方法,DiReCT在数学(GSM8K)、代码(HumanEval)以及复杂的常识推理任务上取得了显著的准确率提升。 收敛效率: 确保在退火阶段,模型能够更有效地利用有限的训练步数(Tokens)逼近最优解,避免了无效的梯度震荡。
不足:
静态海森矩阵的局限性: DiReCT仅在退火阶段开始时()计算一次验证集的海森矩阵。随着训练的进行,损失景观会发生变化,静态的特征方向可能会失效。动态跟踪这些变化会导致计算成本大幅增加。 前向传播的开销: 尽管随机草图技术降低了投影和存储的成本,但收集整个训练集(哪怕是子集)的梯度仍然需要进行一次完整的前向和反向传播。在万亿token规模的预训练中,这依然是一个不可忽视的计算开销。
心得:
“难”数据之所以有用,是因为其几何特性: 过去我们总是凭直觉认为,在训练后期喂给模型“高损失”或“长上下文”的数据有助于提升能力。这篇文章从谱几何的角度给出了极具启发性的解释:这些数据之所以有效,是因为它们的梯度向量恰好富含与损失函数“平坦山谷”对齐的成分,能够推动模型在已经饱和的参数空间中继续前进,而不是简单地因为它们“更难”。 在优化中,“刹车”和“油门”同样重要: DiReCT的设计哲学非常精妙。它不仅仅是寻找梯度最大的方向(踩油门),更重要的是,它明确识别出了那些不能碰的“高曲率方向”(陡峭的悬崖),并硬性限制了在这些方向上的梯度能量(踩刹车)。这对于理解如何避免LLM微调或退火阶段的“灾难性遗忘”提供了重要的数学视角。 理论与工程的完美妥协: 海森矩阵(二阶导数)在深度学习中一直因为计算量过大()而难以实际应用。作者使用 Randomized Sketching 将维度从 降到 ,这展示了在面对大模型时代的计算墙时,如何利用降维打击的数学工具将理论思想落地。
一句话总结: 本文提出了一种名为 DiReCT 的新颖框架,它摒弃了传统的经验式数据筛选,转而利用损失景观的谱几何特性(海森矩阵),通过约束优化挑选出能引导模型在“平坦山谷”中下降且不触碰“陡峭峭壁”的训练样本,从而为 LLM 的退火阶段提供了一种具备坚实理论基础且高效的定向数据选择策略。
The annealing phase is a pivotal convergence stage in LLM pre-training that ultimately determines final model quality. However, effectively selecting training data during this phase remains a key challenge. Current strategies rely on empirical heuristics, such as domain filtering or context extension, which lack a principled grounding in optimization theory. In this work, we characterize the annealing phase through the lens of the loss landscape’s spectral geometry. We argue that optimal convergence requires gradient updates to satisfy heterogeneous constraints across different eigen-directions. Building on this insight, we formulate data selection as a problem of satisfying these directional constraints. To this end, we propose DiReCT (Directionally-Restrained Constrained Training), a novel framework that reformulates sample selection in the annealing stage as a constrained optimization problem. By imposing explicit directional constraints on persample gradients based on the spectral properties of the Hessian, DiReCT identifies samples that align with the optimal curvature-aware descent path. Extensive experiments across various model scales demonstrate that DiReCT consistently achieves state-of-the-art performance.
https://arxiv.org/abs/2605.31175