夜雨聆风
夜雨聆风点击上方 前端Q,关注公众号
回复加群,加入前端Q技术交流群
我最近跟几个做 AI 平台的朋友聊天,发现一个很普遍的现象:
公司里的 AI Agent,正在变成一个"经验黑洞"。
每个团队都接了 Cursor、Claude Code、自研 Agent 之类的工具,每个人都在跟 AI 反复磨合自己的工作流。问题是,这些磨合出来的经验,最后绝大多数都留在了某个人的电脑里,留在某次会话里,留在某个临时记的小笔记里。
下一个新人进来,照样从头摸。
下一个新项目启动,照样从头摸。
下一个新 Agent 上线,照样从头摸。
我研究 Hermes Agent 越深,越觉得它真正提出的不只是一个"自学习 Agent"的方案,更是一个企业不得不面对的问题:
Agent 学到的经验,到底属于谁?怎么管?怎么传?
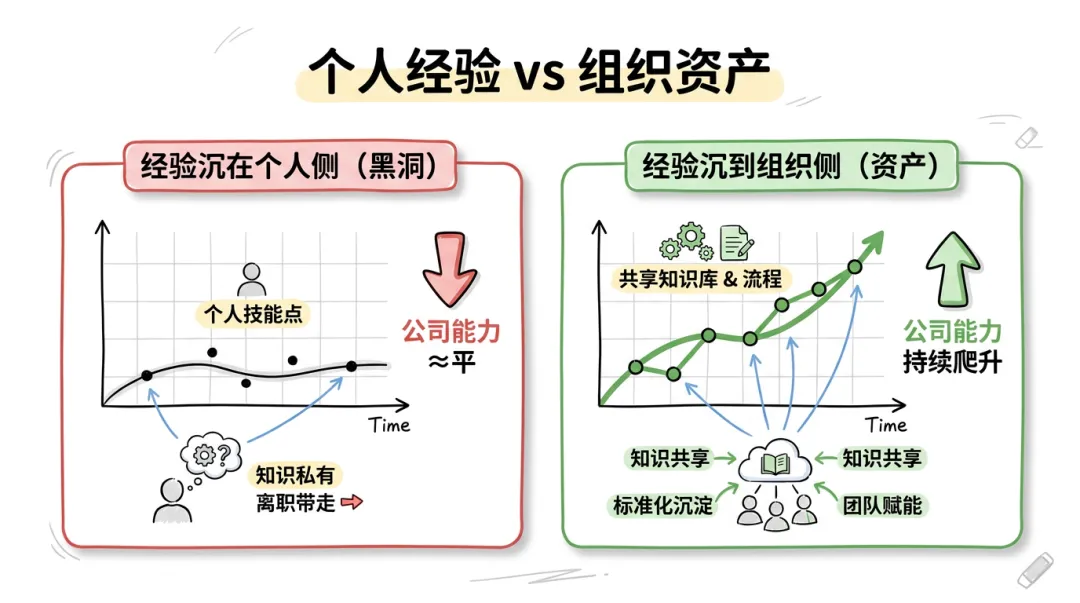
这张图我觉得讲清了一件事:左边是经验沉在个人侧,公司能感知到的能力曲线几乎是平的;右边是经验沉到组织侧,公司层面的能力会随时间稳步爬升。
而 Skill Hub,就是把"右边"这件事变成可工程化的产物。
先把问题讲透:企业 AI 落地的隐形 Tax
我把目前看到的企业 AI 落地路径粗略分成三种。
第一种,"工具采购型"。
公司买了 Cursor 或者 Claude Code,发给开发,让大家随便用。
短期看效率确实有提升,每个人写代码、写文档、查问题都更快了。
长期看,几乎没有沉淀。每个人对 AI 的使用方式不同,效率差距巨大,但公司层面拿不到一份"我们到底在 AI 上学到了什么"的资产。
第二种,"小作坊自研型"。
每个业务团队自己写一些 Prompt 模板、自己接一些 MCP 工具、自己整一些工作流。
业务方写法千差万别,工程质量参差不齐。一个团队踩过的坑,另一个团队继续踩。
更糟的是,这些 Prompt 没有版本,没有评估,没有治理。线上 AI 突然变笨了,谁都不知道是哪次改 Prompt 搞坏的。
第三种,"中台收口型"。
公司决定建一个统一的 Agent 平台,所有 AI 能力都往里收。
听起来很美好,但很容易跑偏。常见的问题是:平台团队自己定义能力,业务方只能用现成的;新需求要排期;平台和业务越走越远。
这三种模式都有同一个隐形税:
AI 能力没有变成组织资产,每一次效率提升都很难持续累积。
我把这种成本叫做"隐形 AI Tax"。
它不会出现在任何账单里,但它真实存在:你公司投入了 AI 工具的钱、投入了使用时间、踩过了无数次坑,最后只换来了"个体级提升",而不是"组织级提升"。
为什么 Skill 才是真正的组织资产
要讲清楚为什么 Skill Hub 是关键,得先回到一个朴素的问题:
Agent 在工作过程中沉淀下来的东西,哪些是个人的,哪些是组织的?
我的分法是这样:
| 类别 | 主要归属 | 举例 |
|---|---|---|
| 用户偏好 | 个人 | 我喜欢简洁的回复风格、我用 vim、我习惯先 dry-run 再执行 |
| 环境事实 | 个人 / 项目 | 我本地用的 Node 版本、我项目用的包管理器 |
| 项目约定 | 项目 | 这个项目用 pnpm、PR 前必须跑 pnpm test |
| 团队规范 | 团队 / 组织 | 上线前必须做支付链路回归、生产数据库默认只读 |
| 流程经验 | 团队 / 组织 | 慢 SQL 排查的标准动作、发版失败时的恢复流程 |
前两项明显是个人的,留在个人的 Memory 里就行。
但后三项不一样。团队规范和流程经验,本质上是组织在反复试错之后总结出来的"做事方式"。
这种东西如果只留在某个人的 Memory,那就等于一份"私有文档"。换个人就没了。
它必须以某种结构化的方式存在,才能被复用、被评估、被审核、被沉淀。
这就是 Skill 的核心定位:
Skill 是组织对 Agent 说"在这个场景,我们就是这么做事的"。
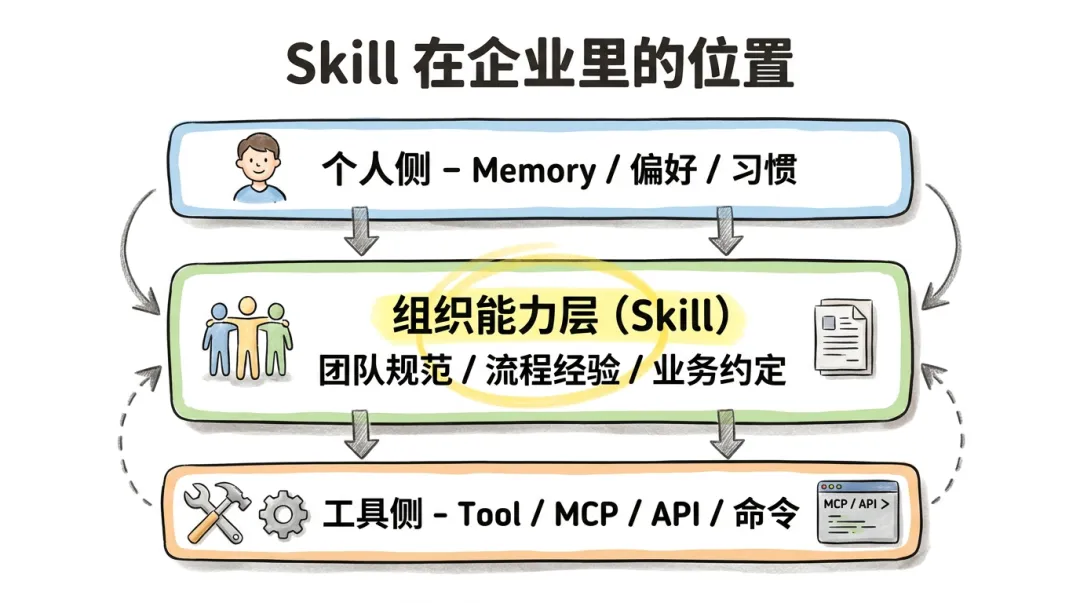
注意这张图里 Skill 的位置:它既不在个人侧(避免每人一份),也不在工具侧(不是写死的硬编码),而是在组织能力层。它是一个被组织共享、被组织治理的东西。
Skill Hub 解决的不是写 Skill,而是治理 Skill
很多人对 Skill Hub 的第一反应是:"不就是个 Skill 仓库吗?"
我之前也这么想。
但当你认真思考企业里 AI 落地会遇到的真实问题,就会发现 Skill Hub 必须比"Skill 的 GitHub"做得更多。
我列一下我能想到的真实问题:
这每一个问题,都不是"做个 Skill 仓库"能回答的。
它们指向的是一整套工程治理:版本、评估、灰度、回滚、审计、所有权、生命周期。
所以 Skill Hub 的真正价值,不是收藏 Skill,而是让 Skill 在企业里能像软件一样被认真对待。
我习惯把 Skill Hub 的能力概括成五件事:
- 写得好:Skill 有明确结构和质量标准,不是一段散乱的 Prompt
- 测得准:每个 Skill 都有自己的测试集,能被自动评估
- 管得住:Skill 有版本、有 owner、有审核流程
- 放得开:能灰度发布、按团队订阅、按场景启用
- 收得回:能监控使用情况,能回滚,能优雅废弃
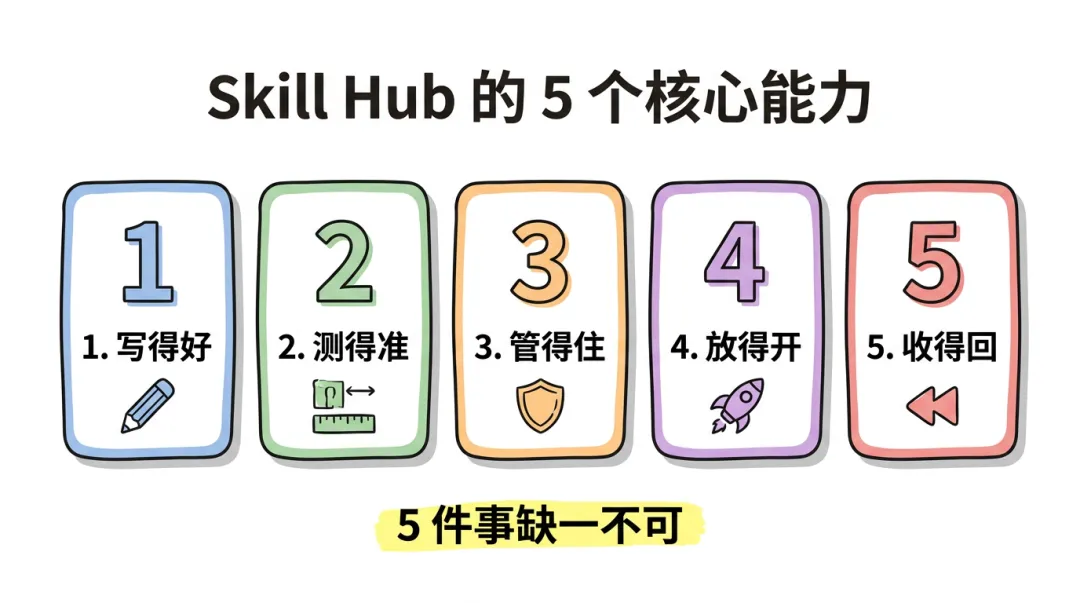
这五件事缺一个,组织 AI 能力就站不住。
一个真实场景:发版 Skill 是怎么从个人脑子里搬出来的
抽象讲多了不直观,我用一个我观察到的真实场景串一下。
某团队的发版流程,过去是这样的:
这就是典型的"组织能力沉在个人脑子"。
第一阶段:让 AI 帮自己干活。
老张试着把发版前要做的事写成 Prompt,喂给 Cursor 或者 Claude Code。第一次效果不错,他觉得 AI 真好用。
但这个 Prompt 在他自己电脑上。
第二阶段:写成 Skill。
老张意识到这个 Prompt 老用,就把它写成了 Skill:
name: frontend-release-check
version: 1.0.0
owner: zhang
description: 前端发版前的标准检查
---
## When to use
当用户准备发布前端服务到生产时使用
## Steps
1. 检查是否有未提交变更
2. 拉取最新 main 分支
3. 跑 lint / typecheck / unit test
4. 跑 build
5. 生成 changelog
6. 提示需要人工 QA 的页面
效果好多了。但问题是:
第三阶段:进入 Skill Hub。
把这个 Skill 推送到企业 Skill Hub 之后,事情发生了变化。
pages/payment/* 必须发起人工 QA 流程"到这一步,"前端发版"这件事,不再是老张脑子里的隐性经验,而是一份组织资产:
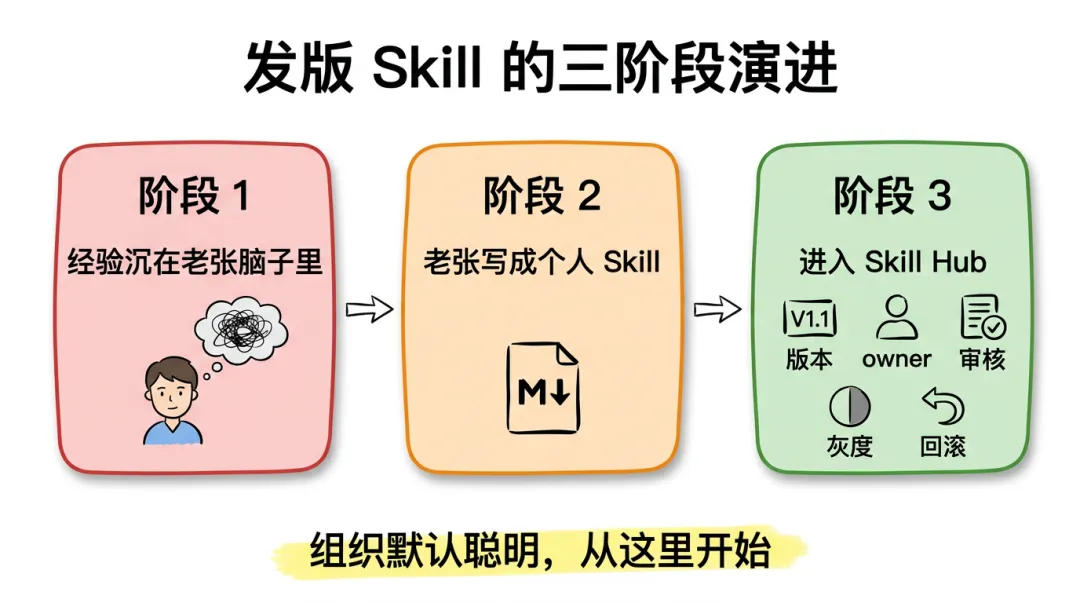
这个例子虽然小,但它揭示了一个很关键的转变:
当 Skill 进入 Hub,它就从"个人聪明"变成了"组织默认聪明"。
新人入职那天,AI 就已经知道怎么帮他发版了,因为这套经验已经在 Skill Hub 里。
没有 Skill Hub,会发生什么
很多公司觉得"我们先用着,再慢慢治理"。
我观察过几家这样的公司,最后基本都会进入两个状态。
状态一:Prompt 失控。
每个团队各写各的 Prompt,每个项目各接各的 MCP,每个人各调各的模型。
突然有一天 AI 输出变笨了,没人能查出哪一段 Prompt 改坏了。
调试一次至少消耗一个工程师两天。
这其实和早年没做日志规范、没做监控规范的项目最后会变成"线上一出问题查不出来"是一回事。
状态二:能力孤岛。
A 团队的"代码评审 Agent"和 B 团队的"代码评审 Agent",各做各的,互相不知道对方踩过什么坑。
一年下来,公司层面的 AI 能力其实没有"叠加",只是"重复"。
这种情况下,公司投入了很多 AI 资源,但能力没有积累,组织效率提升非常有限。
我跟一位做平台的朋友聊,他说了一句让我印象很深的话:
"前两年我们在补的是 DevOps 课,未来两年我们要补的是 AIOps、Skill Ops 的课。AI 不像普通工具,越没规则越乱。"
我很认同。
Skill Hub 不是大公司专属
可能有人会说:你这套听起来挺重的,是不是只有大厂才需要?
我的判断是不一样的。
中小团队也很需要 Skill Hub,只是形态会更轻。
中小团队完全可以用:
也能跑得起来一个最小可用的 Skill Hub。
我觉得真正的判断标准不是"公司大不大",而是这两个问题:
- 你的 AI 能力是否需要被多人共享?
- 你是否在乎 AI 在生产环境里的稳定性?
只要这两个里有一个回答"是",就值得把 Skill 当成正经资产管。
我的判断
我现在越来越觉得,企业 AI 落地走到 2026 年这个节点,最大的瓶颈不是模型不够强,也不是工具不够多。
最大的瓶颈是:
企业还没准备好把 AI 学到的东西管起来。
模型每年都在升级,工具每月都在更新,Prompt 每天都在被人改。
如果一个组织没有"AI 能力资产"这一层,它的 AI 投入就只是"个体生产力工具",永远变不成"组织能力"。
Skill Hub 的真正意义,是给企业一个机会,把 AI 的智慧从个人脑子里、从一次次的对话里、从分散的工具配置里,沉淀成一份可见、可管、可评估、可演进的组织资产。
接下来一篇我会聊:一个真正能上线的 Skill 应该长什么样——也就是 Skill 的设计规范。这是所有治理的起点,结构没立起来,后面的版本、评估、灰度全都没法谈。
▎可进一步阅读

往期推荐